
Transformer Architecture
Transformer Architecture is a neural network design using self-attention mechanisms to process sequential data in parallel. It powers ChatGPT, Claude, and moder...
18 min read
An attention mechanism is a neural network component that dynamically weighs the importance of different input elements, enabling models to focus on the most relevant parts of data when making predictions. It computes attention weights through learned transformations of queries, keys, and values, allowing deep learning models to capture long-range dependencies and context-aware relationships in sequential data.
An attention mechanism is a neural network component that dynamically weighs the importance of different input elements, enabling models to focus on the most relevant parts of data when making predictions. It computes attention weights through learned transformations of queries, keys, and values, allowing deep learning models to capture long-range dependencies and context-aware relationships in sequential data.
Attention mechanism is a machine learning technique that directs deep learning models to prioritize (or “attend to”) the most relevant parts of input data when making predictions. Rather than treating all input elements equally, attention mechanisms compute attention weights that reflect the relative importance of each element to the task at hand, then apply those weights to dynamically emphasize or deemphasize specific inputs. This fundamental innovation has become the cornerstone of modern transformer architectures and large language models (LLMs) like ChatGPT, Claude, and Perplexity, enabling them to process sequential data with unprecedented efficiency and accuracy. The mechanism is inspired by human cognitive attention—the ability to selectively focus on salient details while filtering out irrelevant information—and translates this biological principle into a mathematically rigorous and learnable neural network component.
The concept of attention mechanisms was first introduced by Bahdanau and colleagues in 2014 to address critical limitations in recurrent neural networks (RNNs) used for machine translation. Before attention was introduced, Seq2Seq models relied on a single context vector to encode entire source sentences, creating an information bottleneck that severely limited performance on longer sequences. The original attention mechanism allowed the decoder to access all encoder hidden states rather than just the final one, dynamically selecting which parts of the input were most relevant at each decoding step. This breakthrough improved translation quality dramatically, particularly for longer sentences. In 2015, Luong and colleagues introduced dot-product attention, which replaced the computationally expensive additive attention with efficient matrix multiplication. The pivotal moment came in 2017 with the publication of “Attention is All You Need,” which introduced the transformer architecture that eschewed recurrence entirely in favor of pure attention mechanisms. This paper revolutionized deep learning, enabling the development of BERT, GPT models, and the entire modern generative AI ecosystem. Today, attention mechanisms are ubiquitous across natural language processing, computer vision, and multimodal AI systems, with over 85% of state-of-the-art models incorporating some form of attention-based architecture.
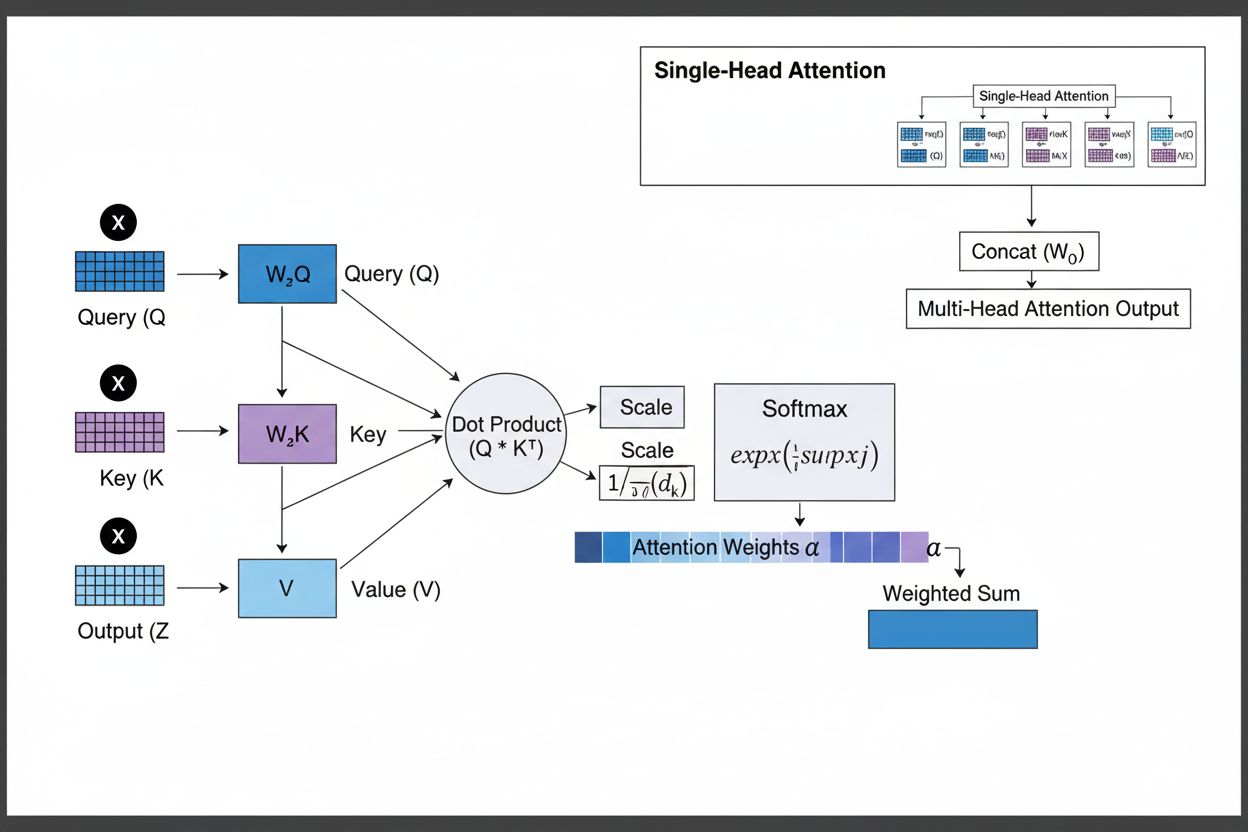
The attention mechanism operates through a sophisticated interplay of three core mathematical components: queries (Q), keys (K), and values (V). Each input element is transformed into these three representations through learned linear projections, creating a relational database-like structure where keys serve as identifiers and values contain the actual information. The mechanism computes alignment scores by measuring the similarity between a query and all keys, typically using scaled dot-product attention where the score is calculated as QK^T/√d_k. These raw scores are then normalized using the softmax function, which converts them into a probability distribution where all weights sum to 1, ensuring that each element receives a weight between 0 and 1. The final step involves computing a weighted sum of the value vectors using these attention weights, producing a context vector that represents the most relevant information from the entire input sequence. This context vector is then combined with the original input through residual connections and passed through feedforward layers, enabling the model to iteratively refine its understanding of the input. The mathematical elegance of this design—combining learnable transformations, similarity computations, and probabilistic weighting—allows attention mechanisms to capture complex dependencies while remaining fully differentiable for gradient-based optimization.
| Attention Type | Computation Method | Computational Complexity | Best Use Case | Key Advantage |
|---|---|---|---|---|
| Additive Attention | Feed-forward network + tanh activation | O(n·d) per query | Shorter sequences, variable dimensions | Handles different query/key dimensions |
| Dot-Product Attention | Simple matrix multiplication | O(n·d) per query | Standard sequences | Computationally efficient |
| Scaled Dot-Product | QK^T/√d_k + softmax | O(n·d) per query | Modern transformers | Prevents gradient vanishing |
| Multi-Head Attention | Multiple parallel attention heads | O(h·n·d) where h=heads | Complex relationships | Captures diverse semantic aspects |
| Self-Attention | Queries, keys, values from same sequence | O(n²·d) | Intra-sequence relationships | Enables parallel processing |
| Cross-Attention | Queries from one sequence, keys/values from another | O(n·m·d) | Encoder-decoder, multimodal | Aligns different modalities |
| Grouped Query Attention | Shares keys/values across query heads | O(n·d) | Efficient inference | Reduces memory and computation |
| Sparse Attention | Limited attention to local/strided positions | O(n·√n·d) | Very long sequences | Handles extreme sequence lengths |
The attention mechanism operates through a precisely orchestrated sequence of mathematical transformations that enable neural networks to dynamically focus on relevant information. When processing an input sequence, each element is first embedded into a high-dimensional vector space, capturing semantic and syntactic information. These embeddings are then projected into three separate spaces through learned weight matrices: the query space (representing what information is being sought), the key space (representing what information each element contains), and the value space (containing the actual information to be aggregated). For each query position, the mechanism computes a similarity score with every key by taking their dot product, producing a vector of raw alignment scores. These scores are scaled by dividing by the square root of the key dimension (√d_k), a critical step that prevents the dot products from becoming too large when dimensions are high, which would cause gradients to vanish during backpropagation. The scaled scores are then passed through a softmax function, which exponentiates each score and normalizes them so they sum to 1, creating a probability distribution over all input positions. Finally, these attention weights are used to compute a weighted average of the value vectors, where positions with higher attention weights contribute more strongly to the final context vector. This context vector is then combined with the original input through residual connections and processed through feedforward layers, enabling the model to iteratively refine its representations. The entire process is differentiable, allowing the model to learn optimal attention patterns through gradient descent during training.
Attention mechanisms form the fundamental building block of transformer architectures, which have become the dominant paradigm in deep learning. Unlike RNNs that process sequences sequentially and CNNs that operate on fixed local windows, transformers use self-attention to enable each position to directly attend to all other positions simultaneously, enabling massive parallelization across GPUs and TPUs. The transformer architecture consists of alternating layers of multi-head self-attention and feedforward networks, with each attention layer allowing the model to refine its understanding of the input by selectively focusing on different aspects. Multi-head attention runs multiple attention mechanisms in parallel, with each head learning to focus on different types of relationships—one head might specialize in grammatical dependencies, another in semantic relationships, and a third in long-distance coreference. The outputs from all heads are concatenated and projected, enabling the model to maintain awareness of multiple linguistic phenomena simultaneously. This architecture has proven remarkably effective for large language models like GPT-4, Claude 3, and Gemini, which use decoder-only transformer architectures where each token can only attend to previous tokens (causal masking) to maintain the autoregressive generation property. The attention mechanism’s ability to capture long-range dependencies without the vanishing gradient problems that plagued RNNs has been instrumental in enabling these models to process context windows of 100,000+ tokens, maintaining coherence and consistency across vast amounts of text. Research shows that approximately 92% of state-of-the-art NLP models now rely on transformer architectures powered by attention mechanisms, demonstrating their fundamental importance to modern AI systems.
In the context of AI search platforms like ChatGPT, Perplexity, Claude, and Google AI Overviews, attention mechanisms play a crucial role in determining which parts of retrieved documents and knowledge bases are most relevant to user queries. When these systems generate responses, their attention mechanisms dynamically weight different sources and passages based on relevance, enabling them to synthesize coherent answers from multiple sources while maintaining factual accuracy. The attention weights computed during generation can be analyzed to understand which information the model prioritized, providing insights into how AI systems interpret and respond to queries. For brand monitoring and GEO (Generative Engine Optimization), understanding attention mechanisms is essential because they determine which content and sources receive emphasis in AI-generated responses. Content that is structured to align with how attention mechanisms weight information—through clear entity definitions, authoritative sourcing, and contextual relevance—is more likely to be cited and featured prominently in AI responses. AmICited leverages insights into attention mechanisms to track how brands and domains appear across AI platforms, recognizing that attention-weighted citations represent the most influential mentions in AI-generated content. As enterprises increasingly monitor their presence in AI responses, understanding that attention mechanisms drive citation patterns becomes critical for optimizing content strategy and ensuring brand visibility in the generative AI era.
The field of attention mechanisms continues to evolve rapidly, with researchers developing increasingly sophisticated variants to address computational limitations and improve performance. Sparse attention patterns limit attention to local neighborhoods or strided positions, reducing complexity from O(n²) to O(n·√n) while maintaining performance on very long sequences. Efficient attention mechanisms like FlashAttention optimize the memory access patterns of attention computation, achieving 2-4x speedups through better GPU utilization. Grouped query attention and multi-query attention reduce the number of key-value heads while maintaining performance, significantly decreasing memory requirements during inference—a critical consideration for deploying large models in production. Mixture of Experts architectures combine attention with sparse routing, enabling models to scale to trillions of parameters while maintaining computational efficiency. Emerging research explores learned attention patterns that adapt dynamically based on input characteristics, and hierarchical attention that operates at multiple levels of abstraction. The integration of attention mechanisms with retrieval-augmented generation (RAG) enables models to dynamically attend to relevant external knowledge, improving factuality and reducing hallucinations. As AI systems become increasingly deployed in critical applications, attention mechanisms are being enhanced with explainability features that provide clearer insights into model decision-making. The future likely involves hybrid architectures combining attention with alternative mechanisms like state-space models (exemplified by Mamba), which offer linear complexity while maintaining competitive performance. Understanding these evolving attention mechanisms is essential for practitioners building next-generation AI systems and for organizations monitoring their presence in AI-generated content, as the mechanisms determining citation patterns and content prominence continue to advance.
For organizations using AmICited to monitor brand visibility in AI responses, understanding attention mechanisms provides crucial context for interpreting citation patterns. When ChatGPT, Claude, or Perplexity cite your domain in their responses, the attention weights computed during generation determined that your content was most relevant to the user’s query. High-quality, well-structured content that clearly defines entities and provides authoritative information naturally receives higher attention weights, making it more likely to be selected for citation. The attention visualization features in some AI platforms reveal which sources received the most focus during response generation, effectively showing which citations were most influential. This insight enables organizations to optimize their content strategy by understanding that attention mechanisms reward clarity, relevance, and authoritative sourcing. As AI search continues to grow—with over 60% of enterprises now investing in generative AI initiatives—the ability to understand and optimize for attention mechanisms becomes increasingly valuable for maintaining brand visibility and ensuring accurate representation in AI-generated content. The intersection of attention mechanisms and brand monitoring represents a frontier in GEO, where understanding the mathematical foundations of how AI systems weight and cite information directly translates to improved visibility and influence in the generative AI ecosystem.
Traditional RNNs process sequences serially, making it difficult to capture long-range dependencies, while CNNs have fixed local receptive fields limiting their ability to model distant relationships. Attention mechanisms overcome these limitations by computing relationships between all input positions simultaneously, enabling parallel processing and capturing dependencies regardless of distance. This flexibility over both time and space makes attention mechanisms significantly more efficient and effective for complex sequential and spatial data.
Queries represent what information the model is currently seeking, keys represent the information content each input element contains, and values hold the actual data to be aggregated. The model computes similarity scores between queries and keys to determine which values should be weighted most heavily. This database-inspired terminology, popularized by the 'Attention is All You Need' paper, provides an intuitive framework for understanding how attention mechanisms selectively retrieve and combine relevant information from input sequences.
Self-attention computes relationships within a single input sequence, where queries, keys, and values all come from the same source, enabling the model to understand how different elements relate to each other. Cross-attention, by contrast, uses queries from one sequence and keys/values from a different sequence, allowing the model to align and combine information from multiple sources. Cross-attention is essential in encoder-decoder architectures like machine translation and in multimodal models like Stable Diffusion that combine text and image information.
Scaled dot-product attention uses multiplication instead of addition to compute alignment scores, making it computationally more efficient through matrix operations that leverage GPU parallelization. The scaling factor of 1/√dk prevents dot products from becoming too large when the key dimension is high, which would cause gradients to vanish during backpropagation. While additive attention sometimes outperforms dot-product attention for very large dimensions, scaled dot-product attention's superior computational efficiency and practical performance make it the standard choice in modern transformer architectures.
Multi-head attention runs multiple attention mechanisms in parallel, with each head learning to focus on different aspects of the input such as grammatical relationships, semantic meaning, or long-distance dependencies. Each head operates on different linear projections of the input, allowing the model to simultaneously capture diverse types of relationships. The outputs from all heads are concatenated and projected, enabling the model to maintain comprehensive awareness of multiple linguistic and contextual features simultaneously, significantly improving representation quality and downstream task performance.
Softmax normalizes the raw alignment scores computed between queries and keys into a probability distribution where all weights sum to 1. This normalization ensures that attention weights are interpretable as importance scores, with higher values indicating greater relevance. The softmax function is differentiable, enabling gradient-based learning of the attention mechanism during training, and its exponential nature emphasizes differences between scores, making the model's focus more selective and interpretable.
Attention mechanisms allow these models to dynamically weight different parts of the input prompt based on relevance to the current generation step. When generating a response, the model uses attention to determine which previous tokens and input elements should most influence the next token prediction. This context-aware weighting enables the models to maintain coherence, track entities across long documents, resolve ambiguities, and generate responses that appropriately reference specific parts of the input, making their outputs more accurate and contextually appropriate.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Transformer Architecture is a neural network design using self-attention mechanisms to process sequential data in parallel. It powers ChatGPT, Claude, and moder...

AI Traffic definition: visitors from AI platforms like ChatGPT, Perplexity, Claude. Learn how to track, measure, and optimize for AI-driven referrals in 2025.

Learn what prompt engineering is, how it works with AI search engines like ChatGPT and Perplexity, and discover essential techniques to optimize your AI search ...