
What is Burstiness in AI Content and How Does It Affect Detection
Learn what burstiness means in AI-generated content, how it differs from human writing patterns, and why it matters for AI detection and content authenticity.
8 min read
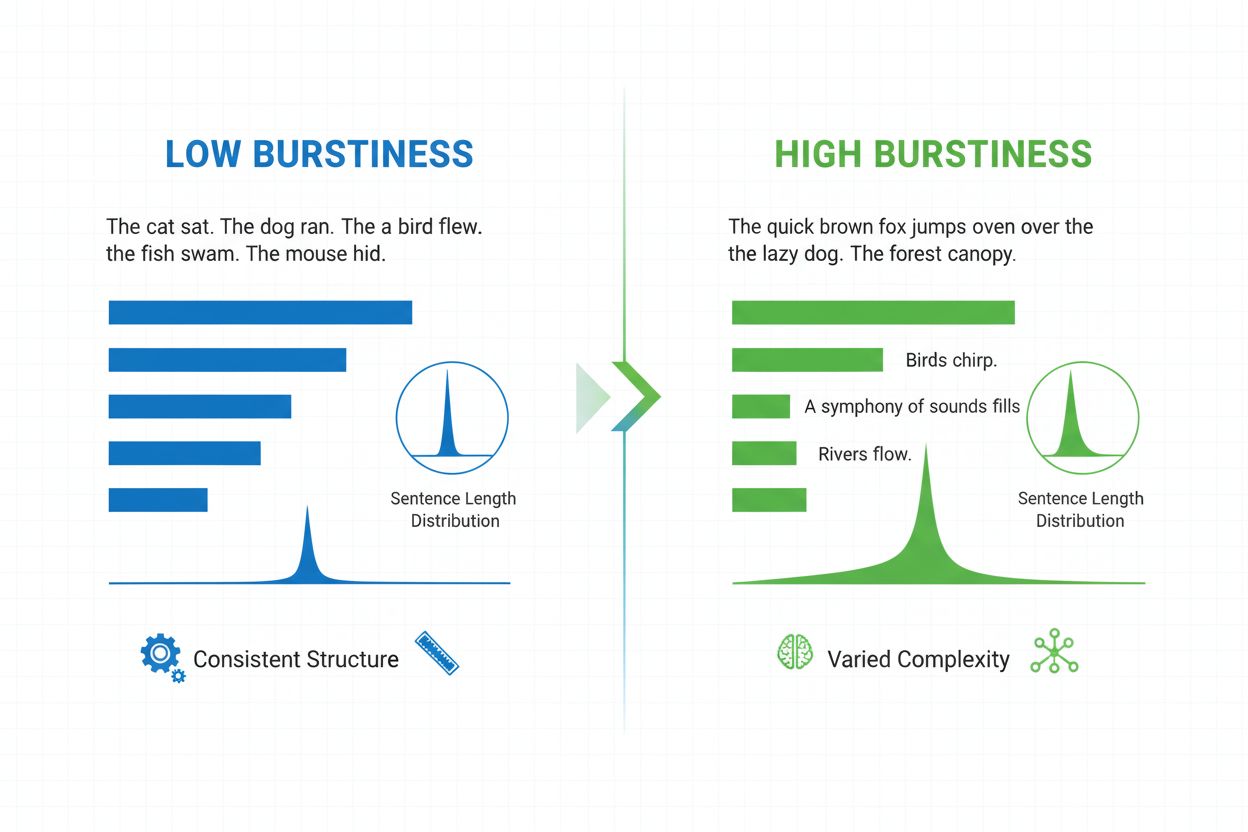
Burstiness is a linguistic metric that measures the variability of sentence length, structure, and complexity throughout a document. It quantifies how much a writer alternates between short, punchy sentences and longer, more complex ones, serving as a key indicator in AI-generated content detection and natural language analysis.
Burstiness is a linguistic metric that measures the variability of sentence length, structure, and complexity throughout a document. It quantifies how much a writer alternates between short, punchy sentences and longer, more complex ones, serving as a key indicator in AI-generated content detection and natural language analysis.
Burstiness is a quantifiable linguistic metric that measures the variability and fluctuation of sentence length, structure, and complexity throughout a written document or text passage. The term originates from the concept of “bursts” of varying sentence patterns—alternating between short, concise sentences and longer, more intricate ones. In the context of natural language processing and AI content detection, burstiness serves as a critical indicator of whether text was written by a human or generated by an artificial intelligence system. Human writers naturally produce text with high burstiness because they instinctively vary their sentence construction based on emphasis, pacing, and stylistic intent. Conversely, AI-generated text typically exhibits low burstiness because language models are trained on statistical patterns that favor consistency and predictability. Understanding burstiness is essential for content creators, educators, researchers, and organizations monitoring AI-generated content across platforms like ChatGPT, Perplexity, Google AI Overviews, and Claude.
The concept of burstiness emerged from research in computational linguistics and information theory, where scientists sought to quantify the statistical properties of natural language. Early work in stylometry—the statistical analysis of writing style—identified that human writing exhibits distinctive patterns of variation that differ fundamentally from machine-generated text. As large language models (LLMs) became increasingly sophisticated in the early 2020s, researchers recognized that burstiness, combined with perplexity (a measure of word predictability), could serve as a reliable indicator of AI-generated content. According to research from QuillBot and academic institutions, approximately 78% of enterprises now use AI-driven content monitoring tools that incorporate burstiness analysis as part of their detection algorithms. The Stanford University 2023 study on TOEFL essays demonstrated that burstiness-based detection methods, while useful, have significant limitations—particularly regarding false positives in non-native English writing. This research has driven the development of more sophisticated, multi-layered AI detection systems that consider burstiness alongside other linguistic markers, semantic coherence, and contextual appropriateness.
Burstiness is calculated by analyzing the statistical distribution of sentence lengths and structural patterns within a text. The metric quantifies variance—essentially measuring how much individual sentences deviate from the average sentence length in a document. A document with high burstiness contains sentences that vary significantly in length; for example, a writer might follow a three-word sentence (“See?”) with a twenty-five-word sentence containing multiple clauses and subordinate phrases. Conversely, low burstiness indicates that most sentences cluster around a similar length, typically between twelve and eighteen words, creating a monotonous rhythm. The calculation involves several steps: first, the system measures the length of each sentence in words; second, it computes the mean (average) sentence length; third, it calculates the standard deviation to determine how much individual sentences deviate from that mean. A higher standard deviation indicates greater variation and thus higher burstiness. Modern AI detectors like Winston AI and Pangram employ sophisticated algorithms that don’t merely count words but also analyze syntactic complexity—the structural arrangement of clauses, phrases, and grammatical elements. This deeper analysis reveals that human writers employ diverse sentence structures (simple, compound, complex, and compound-complex sentences) in unpredictable patterns, whereas AI models tend to favor particular structural templates that appear frequently in their training data.
| Metric | Burstiness | Perplexity | Measurement Focus |
|---|---|---|---|
| Definition | Variation in sentence length and structure | Predictability of individual words | Sentence-level vs. word-level |
| Human Writing | High (varied structures) | High (unpredictable words) | Natural rhythm and vocabulary |
| AI-Generated Text | Low (uniform structures) | Low (predictable words) | Statistical consistency |
| Detection Application | Identifies structural monotony | Identifies word choice patterns | Complementary detection methods |
| False Positive Risk | Higher for ESL writers | Higher for technical/academic writing | Both have limitations |
| Calculation Method | Standard deviation of sentence lengths | Probability distribution analysis | Different mathematical approaches |
| Reliability Alone | Insufficient for definitive detection | Insufficient for definitive detection | Most effective when combined |
Large language models like ChatGPT, Claude, and Google Gemini are trained through a process called next-token prediction, where the model learns to predict the most statistically probable word that should follow a given sequence. During training, these models are explicitly optimized to minimize perplexity on their training datasets, which inadvertently creates low burstiness as a byproduct. When a model encounters a particular sentence structure repeatedly in its training data, it learns to reproduce that structure with high probability, resulting in consistent, predictable sentence lengths. Research from Netus AI and Winston AI reveals that AI models exhibit a distinctive stylometric fingerprint characterized by uniform sentence construction, overuse of transitional phrases (such as “Furthermore,” “Therefore,” “Additionally”), and a preference for passive voice over active voice. The models’ reliance on probability distributions means they gravitate toward the most common patterns in their training data rather than exploring the full spectrum of possible sentence constructions. This creates a paradoxical situation: the more data a model is trained on, the more it learns to reproduce common patterns, and thus the lower its burstiness becomes. Additionally, AI models lack the spontaneity and emotional variation that characterize human writing—they don’t write differently when excited, frustrated, or emphasizing a particular point. Instead, they maintain a consistent stylistic baseline that reflects the statistical center of their training distribution.
AI detection platforms have incorporated burstiness analysis as a core component of their detection algorithms, though with varying degrees of sophistication. Early detection systems relied heavily on burstiness and perplexity as primary metrics, but research has revealed significant limitations with this approach. According to Pangram Labs, perplexity and burstiness-based detectors produce false positives when analyzing text from the training datasets of language models—most notably, the Declaration of Independence is frequently flagged as AI-generated because it appears so frequently in training data that the model assigns it uniformly low perplexity. Modern detection systems like Winston AI and Pangram now employ hybrid approaches that combine burstiness analysis with deep learning models trained on diverse human and AI-generated text samples. These systems analyze multiple linguistic dimensions simultaneously: sentence structure variation, lexical diversity (vocabulary richness), punctuation patterns, contextual coherence, and semantic alignment. The integration of burstiness into broader detection frameworks has improved accuracy significantly—Winston AI reports 99.98% accuracy in distinguishing AI-generated from human-written content by analyzing multiple markers rather than relying on burstiness alone. However, the metric remains valuable as one component of a comprehensive detection strategy, particularly when combined with analysis of perplexity, stylometric patterns, and semantic consistency.
The relationship between burstiness and readability is well-established in linguistic research. The Flesch Reading Ease and Flesch-Kincaid Grade Level scores, which measure text accessibility, correlate strongly with burstiness patterns. Text with higher burstiness tends to achieve better readability scores because varied sentence length prevents cognitive fatigue and maintains reader attention. When readers encounter a consistent rhythm of similarly-sized sentences, their brains adapt to a predictable pattern, which can lead to disengagement and reduced comprehension. Conversely, high burstiness creates an ebb-and-flow effect that keeps readers mentally engaged by varying the cognitive load—short sentences provide quick, digestible information, while longer sentences allow for complex idea development and nuance. Research from Metrics Masters indicates that high burstiness generates approximately 15-20% better memory retention compared to low-burstiness text, as the varied rhythm helps encode information more effectively in long-term memory. This principle applies across content types: blog posts, academic papers, marketing copy, and technical documentation all benefit from strategic burstiness. However, the relationship is not linear—excessive burstiness that prioritizes variation over clarity can make text choppy and difficult to follow. The optimal approach involves purposeful variation where sentence structure choices serve the content’s meaning and the writer’s communicative intent rather than existing solely to increase a metric.
Despite its widespread adoption in AI detection systems, burstiness-based detection has significant limitations that researchers and practitioners must understand. Pangram Labs published comprehensive research demonstrating five major shortcomings: first, text from AI training datasets is falsely classified as AI-generated because models are optimized to minimize perplexity on training data; second, burstiness values are relative to specific language models, so different models produce different perplexity profiles; third, closed-source commercial models like ChatGPT don’t expose token probabilities, making perplexity calculation impossible; fourth, non-native English speakers are disproportionately flagged as AI-generated due to their more uniform sentence structures; and fifth, burstiness-based detectors cannot iteratively self-improve with additional data. The Stanford 2023 study on TOEFL essays found that approximately 26% of non-native English writing was incorrectly flagged as AI-generated by perplexity and burstiness-based detectors, compared to only 2% false positive rates on native English text. This bias raises serious ethical concerns in educational settings where AI detection is used to evaluate student work. Additionally, template-driven content in marketing, academic writing, and technical documentation naturally exhibits lower burstiness due to style guide requirements and structural conventions, leading to false positives in these domains. These limitations have prompted the development of more sophisticated detection approaches that treat burstiness as one signal among many rather than a definitive indicator of AI generation.
Burstiness patterns vary significantly across different writing genres and contexts, reflecting the distinct communicative purposes and audience expectations of each domain. Academic writing, particularly in STEM fields, tends to exhibit lower burstiness because authors follow strict style guides and employ consistent structural templates for clarity and precision. Legal documents, technical specifications, and scientific papers all prioritize consistency and predictability over stylistic variation, resulting in naturally lower burstiness scores. Conversely, creative writing, journalism, and marketing copy typically demonstrate high burstiness because these genres prioritize reader engagement and emotional impact through varied pacing and rhythm. Literary fiction, in particular, employs dramatic shifts in sentence length to create emphasis, build tension, and control narrative pacing. Business communication occupies a middle ground—professional emails and reports maintain moderate burstiness to balance clarity with engagement. The Flesch-Kincaid Grade Level metric reveals that academic writing intended for college-educated audiences often employs longer, more complex sentences, which might appear to reduce burstiness; however, the variation in clause structure and subordination patterns still creates meaningful burstiness. Understanding these contextual variations is crucial for AI detection systems, as they must account for genre-specific writing conventions to avoid false positives. A technical manual with uniformly long sentences should not be flagged as AI-generated simply because it exhibits low burstiness—the low burstiness reflects appropriate stylistic choices for the genre rather than evidence of machine generation.
The future of burstiness analysis in AI detection is evolving toward more sophisticated, context-aware approaches that recognize the metric’s limitations while leveraging its insights. As large language models become increasingly advanced, they are beginning to incorporate burstiness variation into their outputs, making detection based solely on this metric less reliable. Researchers are developing adaptive detection systems that analyze burstiness in conjunction with semantic coherence, factual accuracy, and contextual appropriateness. The emergence of AI humanization tools that deliberately increase burstiness and other human-like characteristics represents an ongoing arms race between detection and evasion technologies. However, experts predict that truly reliable AI detection will ultimately depend on cryptographic verification methods and provenance tracking rather than linguistic analysis alone. For content creators and organizations, the strategic implication is clear: rather than viewing burstiness as a metric to game or exploit, writers should focus on developing authentic, varied writing styles that naturally reflect human communication patterns. AmICited’s monitoring platform represents a new frontier in this space, tracking how brands appear across AI-generated responses and analyzing the linguistic characteristics of those appearances. As AI systems become more prevalent in content generation and distribution, understanding burstiness and related metrics becomes increasingly important for maintaining brand authenticity, ensuring academic integrity, and preserving the distinction between human-authored and machine-generated content. The evolution toward multi-signal detection approaches suggests that burstiness will remain relevant as one component of comprehensive AI monitoring systems, even as its role becomes more nuanced and context-dependent.
Burstiness and perplexity are complementary metrics used in AI detection. Perplexity measures how predictable individual words are within a text, while burstiness measures the variation in sentence structure and length across an entire document. Human writing typically exhibits higher perplexity (more unpredictable word choices) and higher burstiness (more varied sentence structures), whereas AI-generated text tends to show lower values for both metrics due to its reliance on statistical patterns from training data.
High burstiness creates a rhythmic flow that enhances reader engagement and comprehension. When writers alternate between short, impactful sentences and longer, complex ones, it maintains reader interest and prevents monotony. Research shows that varied sentence structure improves memory retention and makes content feel more authentic and conversational. Low burstiness, characterized by uniform sentence lengths, can make text feel robotic and difficult to follow, reducing both readability scores and audience engagement.
While burstiness can be intentionally increased through deliberate sentence structure variation, doing so artificially often produces unnatural-sounding text that may trigger other detection mechanisms. Modern AI detectors analyze multiple linguistic features beyond burstiness, including semantic coherence, contextual appropriateness, and stylometric patterns. Authentic burstiness emerges naturally from genuine human writing and reflects the writer's unique voice, whereas forced variation typically lacks the organic quality that characterizes truly human-written content.
Non-native English speakers frequently exhibit lower burstiness scores because their writing patterns reflect a more limited vocabulary and simpler sentence construction strategies. Language learners typically employ more uniform, predictable sentence structures as they develop proficiency, avoiding complex clauses and varied syntactic patterns. This creates a stylometric profile similar to AI-generated text, leading to false positives in AI detection systems. Research from Stanford University's 2023 study on TOEFL essays confirmed this bias, highlighting a critical limitation of burstiness-based detection methods.
Large language models are trained on massive datasets where they learn to predict the next word based on statistical patterns. During training, these models are optimized to minimize perplexity on their training data, which inadvertently produces uniform sentence structures and predictable word sequences. This results in consistently low burstiness because the models generate text by selecting statistically probable word combinations rather than employing the varied, spontaneous sentence construction that characterizes human writing. The models' reliance on probability distributions creates a homogeneous stylistic signature.
AmICited tracks how brands and domains appear in AI-generated responses across platforms like ChatGPT, Perplexity, and Google AI Overviews. Understanding burstiness helps AmICited's monitoring system distinguish between authentic human-written citations and AI-generated content that mentions your brand. By analyzing burstiness patterns alongside other linguistic markers, AmICited can provide more accurate insights into whether your brand is being cited in genuinely human-authored content or in AI-generated responses, enabling better brand reputation management.
Writers can improve burstiness organically by consciously varying their sentence construction while maintaining clarity and purpose. Techniques include alternating between simple declarative sentences and complex sentences with multiple clauses, using rhetorical devices like fragments and em dashes for emphasis, and varying paragraph lengths. The key is ensuring that variation serves the content's meaning rather than existing for its own sake. Reading aloud, studying diverse writing styles, and revising with attention to rhythm naturally develops the ability to produce high-burstiness text that sounds authentic and engaging.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Learn what burstiness means in AI-generated content, how it differs from human writing patterns, and why it matters for AI detection and content authenticity.
Community discussion on burstiness in AI content detection - what it means, how it affects AI visibility, and whether content creators should optimize for it.

Learn how Citation Velocity measures the rate of change in AI citations over time. Discover why it's a leading indicator of visibility momentum, how to calculat...