
ClaudeBot Explained: Anthropic's Crawler and Your Content
Learn how ClaudeBot works, how it differs from Claude-Web and Claude-SearchBot, and how to manage Anthropic's web crawlers on your website with robots.txt confi...
8 min read

ClaudeBot is Anthropic’s web crawler used for collecting training data for Claude AI models. It systematically crawls publicly accessible websites to gather content for machine learning model training. Website owners can control ClaudeBot’s access through robots.txt configuration. The crawler respects standard robots.txt directives, allowing sites to block or allow its visits.
ClaudeBot is Anthropic's web crawler used for collecting training data for Claude AI models. It systematically crawls publicly accessible websites to gather content for machine learning model training. Website owners can control ClaudeBot's access through robots.txt configuration. The crawler respects standard robots.txt directives, allowing sites to block or allow its visits.
ClaudeBot is a web crawler operated by Anthropic to download training data for its large language models (LLMs) that power AI products like Claude. This AI data scraper systematically crawls websites to collect content specifically for machine learning model training, distinguishing it from traditional search engine crawlers that index content for retrieval purposes. ClaudeBot can be identified by its user agent string and can be blocked or allowed through robots.txt configuration, giving website owners control over whether their content is used for training Anthropic’s AI models.

ClaudeBot operates through systematic web discovery methods, including following links from indexed sites, processing sitemaps, and using seed URLs from publicly available website lists. The crawler downloads website content to include in datasets used for training Claude’s language models, collecting data from publicly accessible pages without requiring authentication. Unlike search engine crawlers that prioritize indexing for retrieval, ClaudeBot’s crawling patterns are typically opaque, with Anthropic rarely disclosing specific site selection criteria, crawling frequency, or priorities for different content types.
The following table compares ClaudeBot with other Anthropic crawlers:
| Bot Name | Purpose | User Agent | Scope |
|---|---|---|---|
| ClaudeBot | Chat citation fetch and training data | ClaudeBot/1.0 | General web crawling for model training |
| anthropic-ai | Bulk model training data collection | anthropic-ai | Large-scale training dataset compilation |
| Claude-Web | Web-focused crawling for Claude features | Claude-Web | Web search and real-time information |
ClaudeBot operates similarly to other major AI training crawlers like GPTBot (OpenAI) and PerplexityBot (Perplexity), but with distinct differences in scope and methodology. While GPTBot focuses on OpenAI’s training needs and PerplexityBot serves both search and training purposes, ClaudeBot specifically targets content for Claude’s model training. According to Dark Visitors data, approximately 18% of the world’s top 1,000 websites are actively blocking ClaudeBot, indicating significant publisher concern about its data collection practices. The key distinction lies in how each company prioritizes content collection—Anthropic’s approach emphasizes systematic, broad-based crawling for training data, whereas search-focused crawlers balance indexing with referral traffic generation.
Website owners can identify ClaudeBot visits by monitoring server logs for the distinctive user agent string: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com). ClaudeBot typically originates from United States IP ranges, and visits can be tracked using server log analysis or dedicated monitoring tools. Setting up agent analytics platforms provides real-time visibility into ClaudeBot visits, allowing website owners to measure crawling frequency and patterns.
Here’s an example of how ClaudeBot appears in server logs:
203.0.113.45 - - [03/Jan/2025:09:15:32 +0000] "GET /blog/article-title HTTP/1.1" 200 5432 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)"
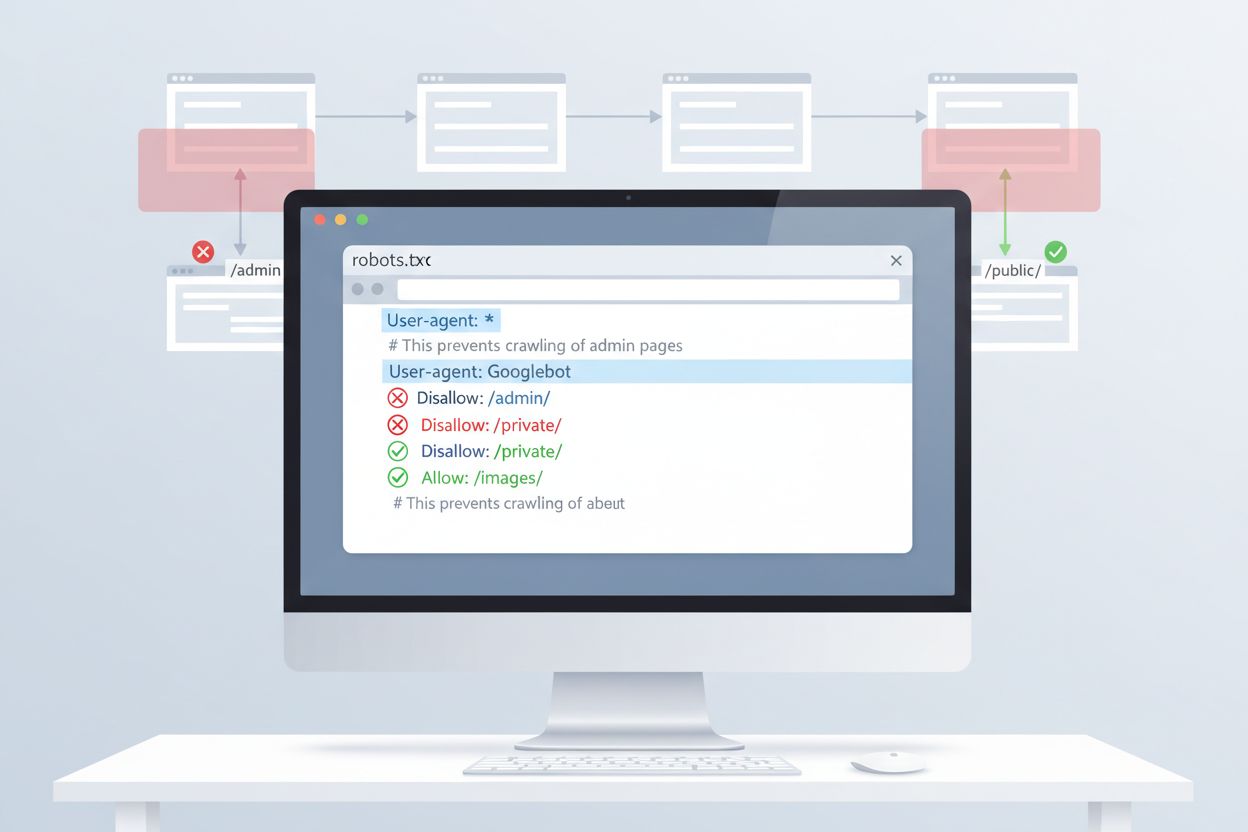
The most straightforward method to control ClaudeBot access is through robots.txt configuration in your website’s root directory. This file tells crawlers which parts of your site they can access, and Anthropic’s ClaudeBot respects these directives. To block all ClaudeBot activity, add the following rules to your robots.txt file:
User-agent: ClaudeBot
Disallow: /
For more selective blocking that prevents ClaudeBot from accessing specific directories while allowing other content to be crawled, use:
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
Allow: /public/
If you want to block all Anthropic crawlers (including anthropic-ai and Claude-Web), add separate rules for each:
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
While robots.txt provides the first line of defense, it operates on a voluntary compliance basis. For publishers requiring stronger enforcement, several additional blocking methods exist:
These methods require more technical expertise than robots.txt configuration but provide stronger enforcement for non-compliant crawlers.
Blocking ClaudeBot has minimal direct impact on traditional SEO rankings since training crawlers don’t contribute to search engine indexing—Google, Bing, and other search engines use separate crawlers (Googlebot, Bingbot) that operate independently. However, blocking ClaudeBot may reduce your content’s representation in AI-generated responses from Claude, potentially affecting future discoverability through AI search and chat interfaces. The strategic decision to block or allow ClaudeBot depends on your content monetization model: if your revenue relies on direct website traffic and ad impressions, blocking prevents your content from being absorbed into training datasets that might reduce visitor numbers. Conversely, allowing ClaudeBot may increase your visibility in Claude’s responses, potentially driving referral traffic from AI chat users.
Effective ClaudeBot management requires ongoing monitoring and testing of your configuration. Use tools like Google Search Console’s robots.txt tester, Merkle’s robots.txt testing tool, or specialized platforms like Dark Visitors to verify that your blocking rules work as intended. Regularly review your server logs to confirm whether ClaudeBot respects your robots.txt directives and monitor for any changes in crawling patterns. Since the AI crawler landscape evolves rapidly with new bots discovered regularly, quarterly reviews of your robots.txt configuration ensure you’re addressing emerging crawlers and maintaining compliance with your content protection strategy. Testing your configuration before deployment prevents accidental blocking of legitimate search engines or other important crawlers.
ClaudeBot is Anthropic's web crawler that systematically visits websites to collect training data for Claude AI models. It discovers your site through link following, sitemap processing, or public website lists. The crawler collects publicly accessible content to improve Claude's language model capabilities.
You can block ClaudeBot by adding a robots.txt rule to your website's root directory. Simply add 'User-agent: ClaudeBot' followed by 'Disallow: /' to prevent all access, or specify particular paths to block selectively. Anthropic's ClaudeBot respects robots.txt directives.
No, blocking ClaudeBot will not impact your Google or Bing search rankings. Training crawlers like ClaudeBot operate independently from traditional search engines. Only blocking Googlebot or Bingbot would affect your SEO performance.
Anthropic operates three main crawlers: ClaudeBot (chat citation fetch and general training), anthropic-ai (bulk training data collection), and Claude-Web (web-focused crawling for real-time features). Each serves different purposes in Anthropic's AI infrastructure.
Check your server logs for the ClaudeBot user agent string: 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)'. You can also use monitoring tools like Dark Visitors or set up agent analytics to track ClaudeBot visits in real-time.
Yes, ClaudeBot respects robots.txt directives according to Anthropic's official documentation. However, like all robots.txt rules, compliance is voluntary. For stronger enforcement, you can implement server-level blocking, IP filtering, or WAF rules.
ClaudeBot can consume significant bandwidth depending on your site's size and content volume. AI data scrapers may crawl more aggressively than traditional search engines. Monitoring your server logs helps you understand the impact and decide whether to block or allow the crawler.
The decision depends on your business model. Block ClaudeBot if you're concerned about content attribution, compensation, or how your work might be used in AI systems. Allow it if you want your content appearing in Claude's responses and AI search results. Consider your traffic monetization strategy when deciding.
Track ClaudeBot and other AI crawlers accessing your content. Get insights into which AI systems are citing your brand and how your content is being used in AI-generated responses.
Learn how ClaudeBot works, how it differs from Claude-Web and Claude-SearchBot, and how to manage Anthropic's web crawlers on your website with robots.txt confi...

Learn how to selectively allow or block AI crawlers based on business objectives. Implement differential crawler access to protect content while maintaining vis...
Claude is Anthropic's advanced AI assistant powered by Constitutional AI. Learn how Claude works, its key features, safety mechanisms, and how it compares to ot...