
Building Your Brand Entity for AI Recognition
Learn how to build and optimize your brand entity for AI recognition. Implement schema markup, entity linking, and structured data to improve visibility in LLM ...
16 min read

Entity disambiguation is the process of determining which specific entity a particular mention refers to when multiple entities share the same name. It helps AI systems accurately understand and cite content by resolving ambiguity in named entity references, ensuring that mentions of ‘Apple’ correctly identify whether the reference is to Apple Inc., the fruit, or another entity with the same name.
Entity disambiguation is the process of determining which specific entity a particular mention refers to when multiple entities share the same name. It helps AI systems accurately understand and cite content by resolving ambiguity in named entity references, ensuring that mentions of 'Apple' correctly identify whether the reference is to Apple Inc., the fruit, or another entity with the same name.
Entity disambiguation is the process of determining which specific entity a particular mention refers to when multiple entities share the same name or similar references. In the context of artificial intelligence and natural language processing (NLP), entity disambiguation ensures that when an AI system encounters a named entity in text, it correctly identifies which real-world object, person, organization, or location is being referenced. This is fundamentally different from named entity recognition (NER), which simply identifies that an entity exists and classifies it into a category like “person,” “organization,” or “location.” While NER answers the question “Is there an entity here?”, entity disambiguation answers “Which specific entity is this?” For example, when processing the sentence “Apple was the brain-child of Steve Jobs,” NER identifies “Apple” as an organization, but entity disambiguation determines whether this refers to Apple Inc., the technology company, or potentially another entity with the same name. This distinction is critical for AI systems that need to accurately understand and cite content, which is why AmICited.com monitors how AI systems like ChatGPT, Perplexity, and Google AI Overviews handle entity disambiguation when generating responses about brands and organizations.
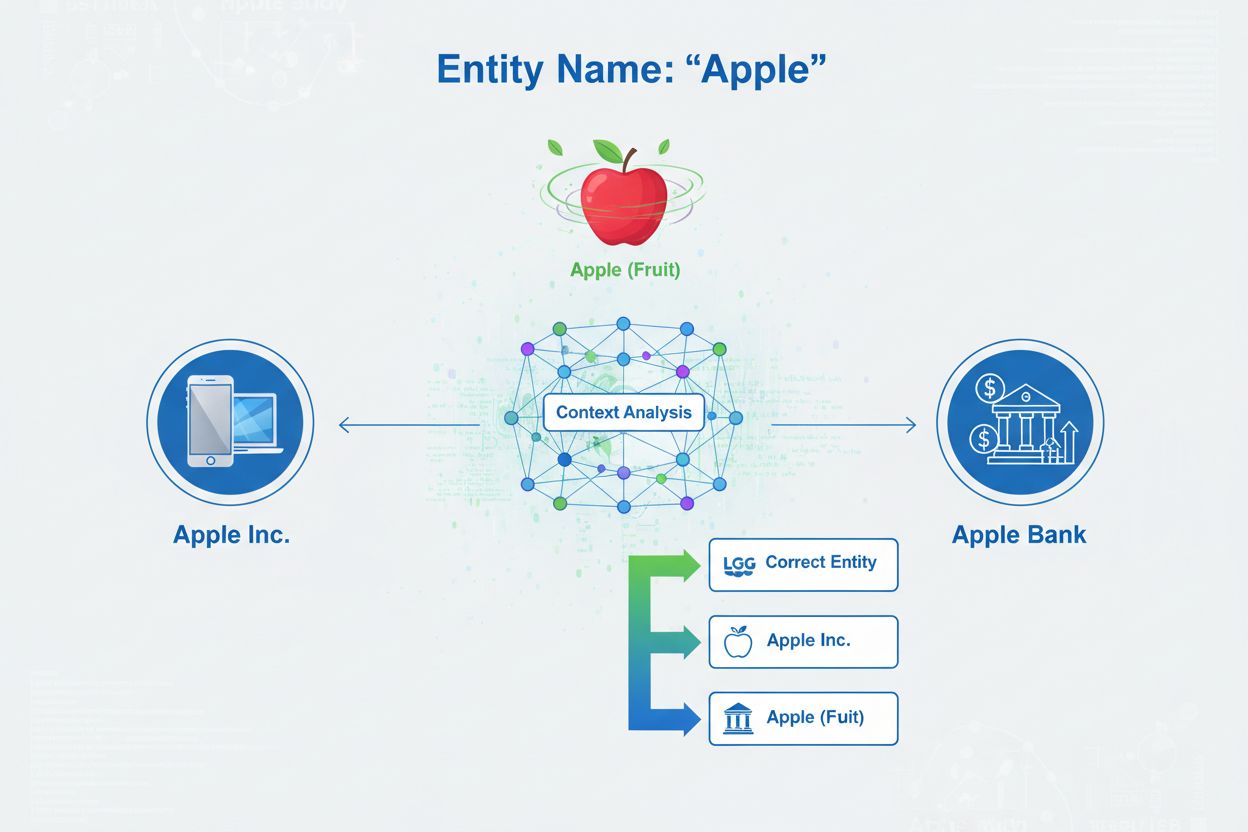
The fundamental problem that entity disambiguation solves is ambiguity—the reality that many entity names can refer to multiple different real-world objects. This ambiguity creates significant challenges for AI systems attempting to understand and generate accurate content. According to the Stanford AI Index 2024, over 18% of LLM outputs involving brand entities contain either hallucinations or entity misattributions, meaning AI systems frequently confuse one entity for another or generate false information about entities. This error rate has serious implications for brand representation and content accuracy. When an AI system misidentifies an entity, it can provide incorrect information, attribute statements to the wrong organization, or fail to cite the correct source for information.
| Entity Name | Possible Meanings | AI Confusion Rate |
|---|---|---|
| Apple | Tech Company / Fruit / Bank | High |
| Delta | Airlines / Faucet Company / Greek Letter | High |
| Jaguar | Car Manufacturer / Animal Species | Medium |
| Amazon | E-commerce Company / Rainforest / River | High |
| Orange | Color / Fruit / Telecom Company | Medium |
The consequences of poor entity disambiguation extend beyond simple factual errors. For content creators and brands, misidentification in AI-generated responses can lead to lost visibility, incorrect attribution, and damage to brand reputation. When a user asks an AI system about “Delta,” they might be seeking information about Delta Airlines, but if the system confuses it with Delta Faucet Company, the user receives irrelevant information. This is precisely why AmICited.com monitors how AI systems disambiguate entities—to help brands understand whether they’re being correctly identified and cited in AI-generated content across multiple platforms.
Entity disambiguation operates through a systematic process that combines multiple NLP techniques to resolve ambiguity and correctly identify entities. Understanding this process reveals why some AI systems perform better than others at maintaining citation accuracy.
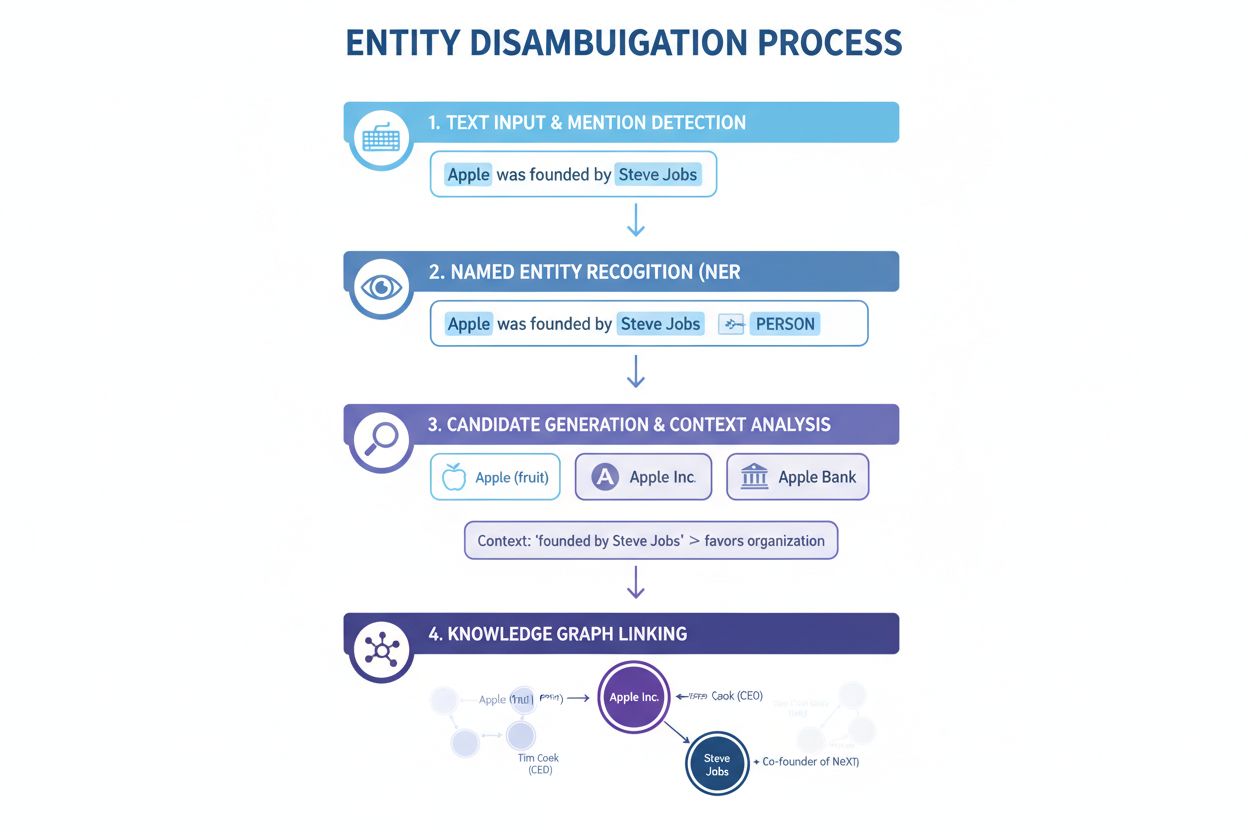
Named Entity Recognition (NER): The first step involves identifying and classifying named entities within text. NER systems scan through text data and locate mentions of entities, assigning them to predefined categories such as person, organization, location, product, or date. For example, in the sentence “Apple was the brain-child of Steve Jobs,” NER identifies both “Apple” and “Steve Jobs” as entities and classifies them as organization and person, respectively. This foundational step is essential because disambiguation cannot occur without first identifying what entities are present in the text.
Entity Categorization: Once entities are identified, they must be categorized more precisely. This involves not just broad classification but understanding the specific type and context of each entity. The system analyzes surrounding text to understand whether “Apple” appears in a technology context (suggesting Apple Inc.), a food context (suggesting the fruit), or a financial context (suggesting Apple Bank). This contextual analysis helps narrow down the possibilities before the actual disambiguation step.
Disambiguation: This is the core step where the system determines which specific entity is being referenced. The system evaluates multiple candidate entities that match the identified name and uses various signals—including context, entity descriptions, semantic relationships, and knowledge graph information—to select the most likely correct entity. For “Apple was the brain-child of Steve Jobs,” the system recognizes that Steve Jobs is strongly associated with Apple Inc., making that the correct disambiguation choice.
Knowledge Base Linking: The final step involves linking the disambiguated entity to a unique identifier in an external knowledge base or knowledge graph, such as Wikidata, Wikipedia, or a proprietary database. This linking confirms the entity’s identity and enriches the text with semantic information that can be used for further processing and analysis. The entity is assigned a unique URI (Uniform Resource Identifier) that serves as a definitive reference point.
Different approaches to entity disambiguation have evolved over time, each with distinct advantages and limitations. Understanding these approaches helps explain why modern AI systems vary in their disambiguation accuracy.
Rule-Based Approaches: These systems use predefined linguistic rules and heuristic patterns to disambiguate entities. They might apply rules like “if ‘Apple’ appears near ‘iPhone’ or ‘MacBook,’ it refers to Apple Inc.” or “if ‘Delta’ appears near ‘airline’ or ‘flight,’ it refers to Delta Airlines.” While rule-based systems are interpretable and don’t require large training datasets, they struggle with novel contexts and cannot adapt to new entity meanings without manual rule updates.
Machine Learning Approaches: Supervised machine learning models learn from annotated training data to predict the correct entity based on contextual features. These systems extract features from surrounding text and use algorithms like Support Vector Machines or Random Forests to classify which entity is most likely. Machine learning approaches are more flexible than rule-based systems but require substantial labeled training data and may not generalize well to entities not seen during training.
Deep Learning and Transformer-Based Models: Modern entity disambiguation increasingly relies on transformer-based architectures like BERT, RoBERTa, and specialized models such as GENRE and BLINK. These models use neural networks to understand context at a deeper level, capturing semantic relationships and nuanced linguistic patterns. Transformer models achieve superior performance on standard benchmarks and can better handle complex disambiguation scenarios. For instance, Ontotext’s CEEL (Common English Entity Linking) system uses transformer-based architecture optimized for CPU efficiency while maintaining high accuracy, achieving 96% entity recognition accuracy and 76% entity linking accuracy on standard benchmarks.
Knowledge Graph Integration: Modern systems increasingly combine machine learning with knowledge graphs—structured databases that represent entities and their relationships. Knowledge graphs provide rich contextual information about entities, their properties, and how they relate to other entities. By querying knowledge graphs during disambiguation, systems can access metadata, descriptions, and relationship information that helps resolve ambiguity more accurately.
Entity disambiguation has become essential across numerous industries and applications, each benefiting from accurate entity identification and citation.
Search Engines: Google, Bing, and other search engines rely heavily on entity disambiguation to return relevant results. When a user searches for “Apple,” the search engine must determine whether the user is interested in Apple Inc., the fruit, or another entity with that name. Search engines use query context, user history, and knowledge graphs to disambiguate and return the most relevant results. This is why search results for “Apple” typically show the technology company first—the system has learned that this is the most commonly intended entity.
Media and Publishing: News organizations and content platforms use entity disambiguation to enhance content discoverability and link related articles. When a news article mentions “Apple,” the system can automatically link to Apple Inc.’s knowledge base entry, providing readers with additional context and related articles. This improves user engagement and helps readers understand the broader context of news stories.
Healthcare: Medical institutions use entity disambiguation to accurately identify drugs, diseases, and medical procedures in patient records and clinical literature. Disambiguating drug names is particularly critical—“aspirin” might refer to the generic drug, a specific brand name, or a dosage variant. Accurate disambiguation ensures that medical professionals access the correct information and that patient records are properly organized.
Financial Services: Investment firms and financial analysts use entity disambiguation to track company mentions across news, earnings reports, and market data. When analyzing market exposure, a firm needs to accurately identify all mentions of a specific company across diverse data sources. Entity disambiguation ensures that “Apple” references are correctly attributed to Apple Inc. rather than other entities, enabling accurate risk assessment and portfolio analysis.
E-commerce: Online retailers use entity disambiguation to match product mentions to actual products in their catalogs. When a customer searches for “Apple laptop,” the system must disambiguate “Apple” as the company and match it to relevant products. This improves search accuracy and helps customers find what they’re looking for more efficiently.
AmICited.com applies entity disambiguation principles to monitor how AI systems like ChatGPT, Perplexity, and Google AI Overviews handle brand mentions. By tracking whether these systems correctly disambiguate brand entities and cite them accurately, AmICited helps brands understand their visibility and representation in AI-generated content.
Knowledge graphs have become fundamental to modern entity disambiguation systems, providing structured representations of entities and their relationships. A knowledge graph is essentially a database of entities (represented as nodes) and the relationships between them (represented as edges). Each entity node contains metadata such as the entity’s name, description, type, and properties. For example, in a knowledge graph, the entity “Apple Inc.” might have properties like “founded in 1976,” “headquarters in Cupertino,” “industry: technology,” and relationships like “founded by Steve Jobs” and “produces iPhone.”
When an entity disambiguation system encounters an ambiguous entity mention, it can query the knowledge graph to access rich contextual information about candidate entities. This information helps the system make more informed disambiguation decisions. For instance, if the system is trying to disambiguate “Apple” and finds that the surrounding text mentions “Steve Jobs,” it can query the knowledge graph to discover that Steve Jobs is strongly associated with Apple Inc., making that the most likely correct entity. Knowledge graphs like Wikidata and Wikipedia provide publicly available entity information that many AI systems use during inference. Proprietary knowledge graphs built by organizations like Google, Microsoft, and others provide additional domain-specific entity information. The integration of knowledge graphs with machine learning models has significantly improved entity disambiguation accuracy, as systems can now combine learned patterns with structured factual information.
Despite significant advances, entity disambiguation systems face several persistent challenges that limit their accuracy and applicability.
Polysemy and Ambiguity: Many entity names have multiple legitimate meanings, and context alone may not be sufficient to disambiguate them. “Bank” can refer to a financial institution or the side of a river. “Crane” can refer to a bird or a construction machine. Some entity names are so ambiguous that even humans struggle to determine the intended meaning without additional context. AI systems must learn to recognize when context is insufficient and handle such cases gracefully.
New and Emerging Entities: Knowledge bases and training datasets become outdated as new entities emerge. When a new company is founded or a new product is launched, entity disambiguation systems may not have information about it in their knowledge bases. Zero-shot entity linking—the ability to disambiguate entities not seen during training—remains a challenging problem. Systems must be able to recognize that an entity is new and handle it appropriately rather than incorrectly matching it to an existing entity with a similar name.
Name Variations and Misspellings: Entities often have multiple names, abbreviations, and variations. “United States,” “USA,” “U.S.,” and “America” all refer to the same entity. Misspellings and typos further complicate disambiguation. Systems must recognize these variations and correctly map them to the canonical entity. This is particularly challenging in user-generated content where misspellings are common.
Incomplete or Outdated Data: Knowledge bases may contain incomplete information about entities, or information may become outdated as entities evolve. A company’s headquarters might change, leadership might shift, or a company might be acquired. If the knowledge base isn’t updated promptly, disambiguation systems may use outdated information to make decisions.
Scalability and Performance: Processing large volumes of text with high-accuracy entity disambiguation requires significant computational resources. Real-time disambiguation for web-scale applications is computationally expensive. Systems must balance accuracy with speed and cost, which often means making trade-offs that reduce disambiguation quality.
For brands and content creators, understanding entity disambiguation is essential for ensuring accurate representation in AI-generated content. As AI systems become increasingly influential in how information is discovered and consumed, brands must take proactive steps to ensure they are correctly disambiguated and cited.
Pre-Disambiguation Strategies: Brands can implement strategies to make their entities easier for AI systems to disambiguate correctly. This involves creating clear, distinctive digital signals that help AI systems identify the brand unambiguously. One key strategy is implementing structured data using Schema.org markup and JSON-LD format on brand websites. This structured data explicitly tells AI systems about the brand’s identity, including its official name, description, logo, headquarters location, and other distinguishing characteristics. When AI systems encounter the brand name, they can reference this structured data to confirm the correct entity.
Knowledge Graph Optimization: Brands should ensure they have a strong presence in major knowledge graphs like Wikidata and Wikipedia. This involves creating or maintaining accurate Wikipedia articles, ensuring Wikidata entries are complete and up-to-date, and building relationships between the brand entity and related entities. The more comprehensive and accurate a brand’s knowledge graph presence, the more information AI systems have available for disambiguation.
Contextual Content Strategy: Brands can create content that provides clear context about their identity and differentiates them from other entities with similar names. Content that explicitly mentions the brand’s industry, products, founders, and unique value proposition helps AI systems understand the brand’s distinctive characteristics. This contextual content becomes part of the training data and context that AI systems use for disambiguation.
Citation Monitoring: Tools like AmICited.com enable brands to monitor how AI systems disambiguate and cite their brand across different platforms. By tracking whether ChatGPT, Perplexity, Google AI Overviews, and other systems correctly identify the brand and cite it accurately, brands can identify disambiguation failures and take corrective action. This monitoring is essential for understanding brand visibility in the age of generative AI.
Generative Engine Optimization (GEO): As entity disambiguation becomes more important for AI visibility, brands should incorporate entity optimization into their broader Generative Engine Optimization strategy. This involves ensuring that the brand entity is clearly defined, well-documented, and easily distinguishable from competing entities. GEO encompasses not just traditional SEO but also optimization for how AI systems understand and represent brands.
Entity disambiguation continues to evolve as AI technology advances and new challenges emerge. Several trends are shaping the future of this critical capability.
Multilingual Entity Disambiguation: As AI systems become more global, the ability to disambiguate entities across multiple languages is increasingly important. A person’s name might be spelled differently in different languages, and the same entity might be referred to by different names in different linguistic contexts. Advanced multilingual models are being developed to handle entity disambiguation across language boundaries, enabling truly global AI systems.
Real-Time Disambiguation in Large Language Models: Modern large language models like GPT-4 and Claude are increasingly incorporating real-time entity disambiguation during text generation. Rather than relying solely on training data, these models can query knowledge graphs and external databases during inference to verify entity information and ensure accurate disambiguation. This capability improves citation accuracy and reduces hallucinations.
Improved Zero-Shot Learning: Future entity disambiguation systems will likely achieve better performance on entities not seen during training. Advances in few-shot and zero-shot learning techniques will enable systems to disambiguate new entities more effectively, reducing the need for frequent retraining and making systems more adaptable to emerging entities.
Integration with Retrieval-Augmented Generation (RAG): Retrieval-augmented generation systems that combine language models with information retrieval are becoming increasingly popular. These systems can retrieve relevant entity information from knowledge bases during text generation, improving disambiguation accuracy and citation quality. This integration represents a significant step forward in ensuring AI systems cite sources accurately.
Standardization and Interoperability: As entity disambiguation becomes more critical for AI systems, industry standards for entity representation and disambiguation are likely to emerge. These standards will enable better interoperability between different systems and knowledge bases, making it easier for AI systems to access and use entity information consistently across platforms.
Entity disambiguation has evolved from a niche NLP task to a critical capability for ensuring AI systems understand and represent information accurately. As AI becomes more influential in how information is discovered and consumed, the importance of accurate entity disambiguation will only increase. For brands, content creators, and organizations, understanding and optimizing for entity disambiguation is essential for maintaining visibility and ensuring accurate representation in the age of generative AI.
Named entity recognition identifies that an entity exists in text and classifies it into categories like person, organization, or location. Entity disambiguation goes further by determining which specific entity is being referenced when multiple entities share the same name. For example, NER identifies 'Apple' as an organization, while entity disambiguation determines whether it refers to Apple Inc., Apple Bank, or another entity.
Entity disambiguation ensures that AI systems accurately understand which entity is being discussed and cite it correctly. According to the Stanford AI Index 2024, over 18% of LLM outputs involving brand entities contain hallucinations or misattributions. Accurate entity disambiguation prevents AI systems from confusing one entity for another, which is critical for maintaining brand reputation and citation accuracy.
Knowledge graphs provide structured information about entities and their relationships. When an AI system encounters an ambiguous entity mention, it can query the knowledge graph to access metadata, descriptions, and relationship information about candidate entities. This contextual information helps the system make more informed disambiguation decisions and select the correct entity.
Yes, through zero-shot entity linking approaches. Modern systems can recognize when an entity is new and handle it appropriately rather than incorrectly matching it to an existing entity. However, this remains a challenging problem, and systems perform better when new entities have clear contextual signals that distinguish them from existing entities.
Accurate entity disambiguation ensures that your brand is correctly identified and cited in AI-generated responses. When AI systems disambiguate your brand correctly, users receive accurate information about your organization, improving brand visibility and reputation. Poor disambiguation can lead to your brand being confused with competitors or other entities, reducing visibility and potentially damaging reputation.
Key challenges include polysemy (multiple meanings for the same name), new entities not in training data, name variations and misspellings, incomplete or outdated knowledge bases, and scalability issues. Additionally, some entity names are inherently ambiguous, and context alone may not be sufficient to determine the correct entity.
Brands can implement structured data using Schema.org markup, maintain accurate Wikipedia and Wikidata entries, create contextual content that clearly distinguishes their brand, and monitor how AI systems disambiguate their brand using tools like AmICited. These strategies help AI systems correctly identify and cite your brand.
Context is crucial for entity disambiguation. The surrounding text, related entities, and semantic relationships all provide signals that help AI systems determine which entity is being referenced. For example, if 'Apple' appears near 'Steve Jobs' and 'technology,' the system can use this context to correctly disambiguate it as Apple Inc. rather than the fruit.
Track entity disambiguation accuracy across AI platforms and ensure your brand is correctly identified and cited in AI-generated responses.
Learn how to build and optimize your brand entity for AI recognition. Implement schema markup, entity linking, and structured data to improve visibility in LLM ...

Learn how entity linking connects your brand across AI systems. Discover strategies to improve brand recognition in ChatGPT, Perplexity, and Google AI Overviews...

Entity Recognition is an AI NLP capability identifying and categorizing named entities in text. Learn how it works, its applications in AI monitoring, and its r...