Federated AI Search is a system that queries multiple independent data sources simultaneously using a single search query and aggregates results in real-time without moving or duplicating data. It enables organizations to access distributed information across databases, APIs, and cloud services while maintaining data security and compliance. Unlike traditional centralized search engines, federated systems preserve data autonomy while providing unified information discovery. This approach is particularly valuable for enterprises managing diverse data sources across different departments, geographies, or organizations.
Federated AI Search
Federated AI Search is a system that queries multiple independent data sources simultaneously using a single search query and aggregates results in real-time without moving or duplicating data. It enables organizations to access distributed information across databases, APIs, and cloud services while maintaining data security and compliance. Unlike traditional centralized search engines, federated systems preserve data autonomy while providing unified information discovery. This approach is particularly valuable for enterprises managing diverse data sources across different departments, geographies, or organizations.
Core Definition & Key Characteristics
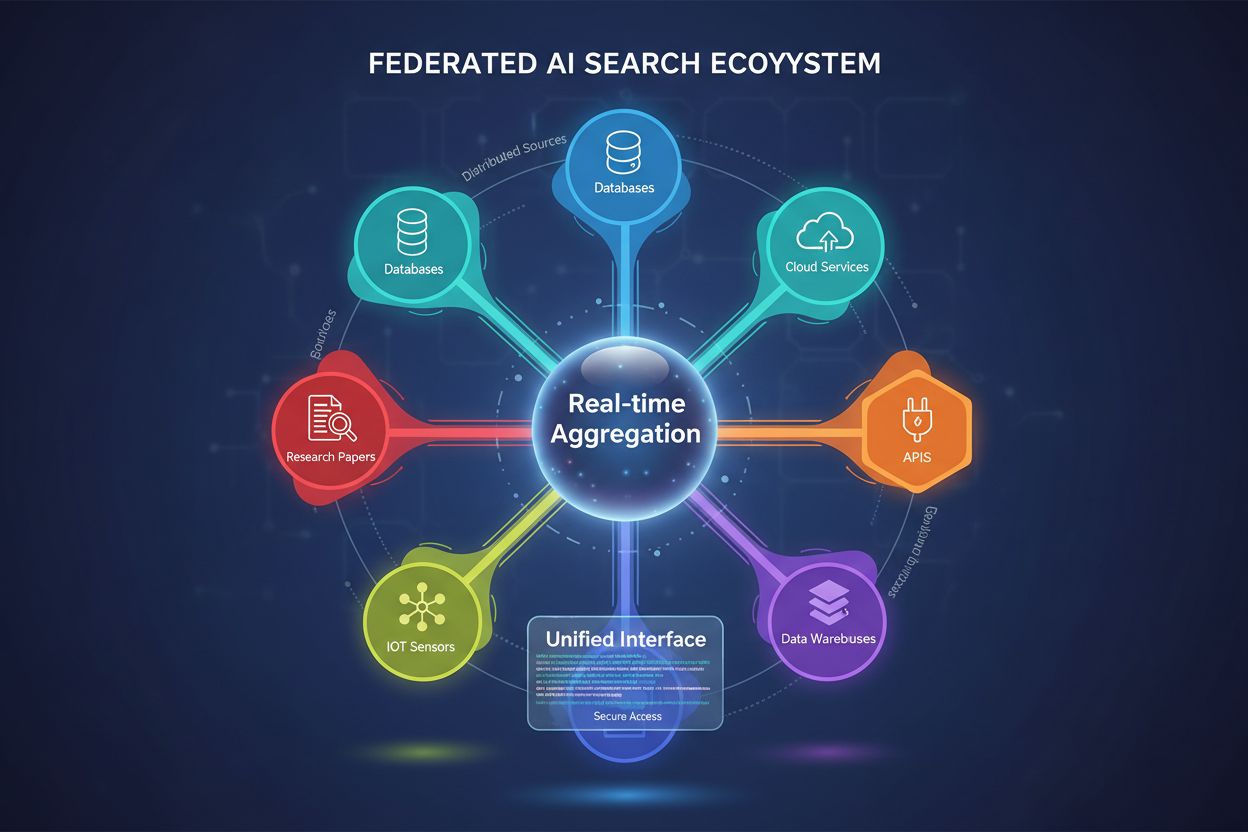
Federated AI Search is a distributed information retrieval system that simultaneously queries multiple heterogeneous data sources and intelligently aggregates results using artificial intelligence techniques. Unlike traditional centralized search engines that maintain a single indexed repository, federated AI search operates across decentralized networks of independent databases, knowledge bases, and information systems without requiring data consolidation or centralized indexing.
The core principle underlying federated AI search is source-agnostic querying, where a single user query is intelligently routed to relevant data sources, processed independently by each source, and then synthesized into a unified result set. This approach preserves data autonomy while enabling comprehensive information discovery across organizational and technical boundaries.
Key characteristics of federated AI search systems include:
Distributed Architecture: Data remains in its original location across multiple repositories, eliminating the need for data migration or centralized storage. Each source maintains its own indexing, access controls, and update mechanisms independently.
Intelligent Query Routing: AI algorithms analyze incoming queries to determine which sources are most likely to contain relevant information, optimizing search efficiency and reducing unnecessary queries to irrelevant databases.
Result Aggregation and Ranking: Machine learning models synthesize results from multiple sources, applying sophisticated ranking algorithms that consider source credibility, result relevance, freshness, and user context.
Heterogeneous Source Support: Federated systems accommodate diverse data formats, schemas, query languages, and access protocols, including relational databases, document stores, knowledge graphs, APIs, and unstructured text repositories.
Real-time Integration: Unlike batch-based data warehousing approaches, federated search provides near-real-time access to current information across all connected sources, ensuring result freshness and accuracy.
Semantic Understanding: Modern federated AI search leverages natural language processing and semantic analysis to understand query intent beyond keyword matching, enabling more accurate source selection and result interpretation.
How Federated AI Search Works
The operational workflow of federated AI search involves multiple coordinated stages, each enhanced by artificial intelligence to optimize performance and result quality.
Stage
Process
AI Component
Output
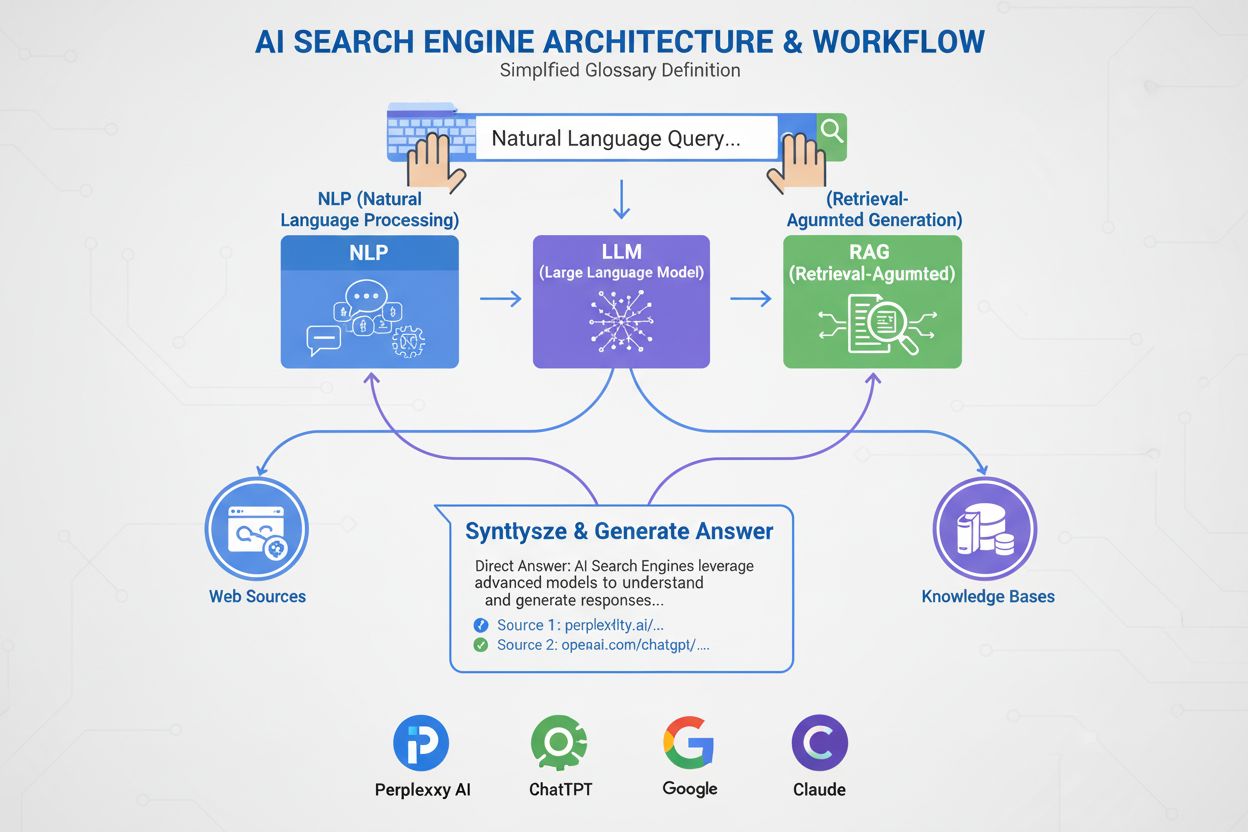
Query Analysis
User query is parsed and analyzed for intent, entities, and context
NLP, Named Entity Recognition, Intent Classification
Results are customized based on user profile and preferences
Collaborative Filtering, User Modeling, Context Awareness
Personalized result ordering
Presentation
Results are formatted for user consumption
Natural Language Generation, Result Summarization
User-facing result display
The workflow operates with parallel execution at its core, where multiple sources are queried simultaneously rather than sequentially. This parallelization dramatically reduces overall query latency despite the overhead of coordinating multiple sources. Advanced federated systems implement adaptive query planning, where the system learns from historical query patterns to optimize source selection and execution strategies over time.
Timeout and Fallback Mechanisms are critical components ensuring system reliability. When a source responds slowly or fails, the system can either wait with adaptive timeouts or proceed with results from available sources, gracefully degrading result completeness rather than failing entirely.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Federated AI search systems can be categorized across multiple dimensions:
By Architecture Model:
Centralized Federated Search: A central coordinator manages query routing and result aggregation, maintaining metadata about all sources. This approach simplifies coordination but creates a potential single point of failure.
Decentralized Federated Search: Peer-to-peer architecture where any node can initiate searches and coordinate results without central authority. This provides resilience but increases coordination complexity.
Hybrid Federated Search: Combines centralized coordination for core functions with decentralized capabilities for redundancy and scalability.
By Data Source Type:
Structured Data Federation: Integrates relational databases, data warehouses, and structured repositories with well-defined schemas.
Unstructured Data Federation: Searches across document repositories, text collections, and content management systems without rigid schema constraints.
Knowledge Graph Federation: Queries distributed knowledge graphs and semantic networks, leveraging ontologies for intelligent integration.
API-Based Federation: Aggregates results from multiple web services and REST APIs, handling diverse response formats and protocols.
Hybrid Content Federation: Combines multiple data types within a single federated search system.
By Scope and Scale:
Enterprise Federated Search: Integrates data sources within organizational boundaries, typically with controlled access and known source characteristics.
Web-Scale Federated Search: Operates across internet-accessible sources with unknown or variable characteristics, requiring robust handling of unreliable sources.
Domain-Specific Federation: Focuses on particular industries or knowledge domains with specialized source types and domain-specific ranking criteria.
By Intelligence Level:
Basic Federation: Simple query routing and result merging without sophisticated AI components.
Intelligent Federation: Incorporates machine learning for source selection, ranking, and result quality optimization.
Semantic Federation: Leverages knowledge graphs, ontologies, and semantic understanding for deep integration across heterogeneous sources.
Autonomous Federation: Self-optimizing systems that continuously learn and adapt source selection and ranking strategies.
Key Benefits & Advantages
Data Autonomy and Governance: Organizations maintain control over their data, eliminating the need to transfer sensitive information to centralized repositories. This preserves data governance policies, compliance requirements, and security controls at the source level.
Scalability Without Consolidation: Federated systems scale by adding new sources without requiring data migration or warehouse restructuring. This enables organizations to integrate new data sources incrementally as business needs evolve.
Real-Time Information Access: By querying sources directly, federated search provides access to current information without the latency inherent in batch-based data warehousing. This is particularly valuable for time-sensitive applications requiring up-to-date information.
Cost Efficiency: Eliminates the substantial infrastructure and operational costs associated with building and maintaining centralized data warehouses. Organizations avoid data duplication, redundant storage, and complex ETL processes.
Reduced Data Redundancy: Unlike data warehousing approaches that duplicate data across systems, federated search maintains single sources of truth, reducing storage overhead and ensuring consistency.
Flexibility and Adaptability: New sources can be integrated without modifying existing infrastructure or reindexing centralized repositories. This flexibility enables rapid response to changing business requirements.
Improved Data Quality: By querying authoritative sources directly, federated search reduces data staleness and inconsistency issues that arise from periodic data synchronization in warehousing approaches.
Enhanced Security: Sensitive data never leaves its original location, reducing exposure to unauthorized access or breaches. Access controls remain under source-level management rather than centralized systems.
Heterogeneous Source Support: Federated systems accommodate diverse technologies, formats, and protocols without requiring standardization or migration to common platforms.
Intelligent Result Synthesis: AI-powered ranking and aggregation produce higher-quality results than simple merging approaches, considering source credibility, result relevance, and user context.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Technical Architecture & Components
Modern federated AI search systems comprise several interconnected technical components working in concert to deliver integrated search capabilities.
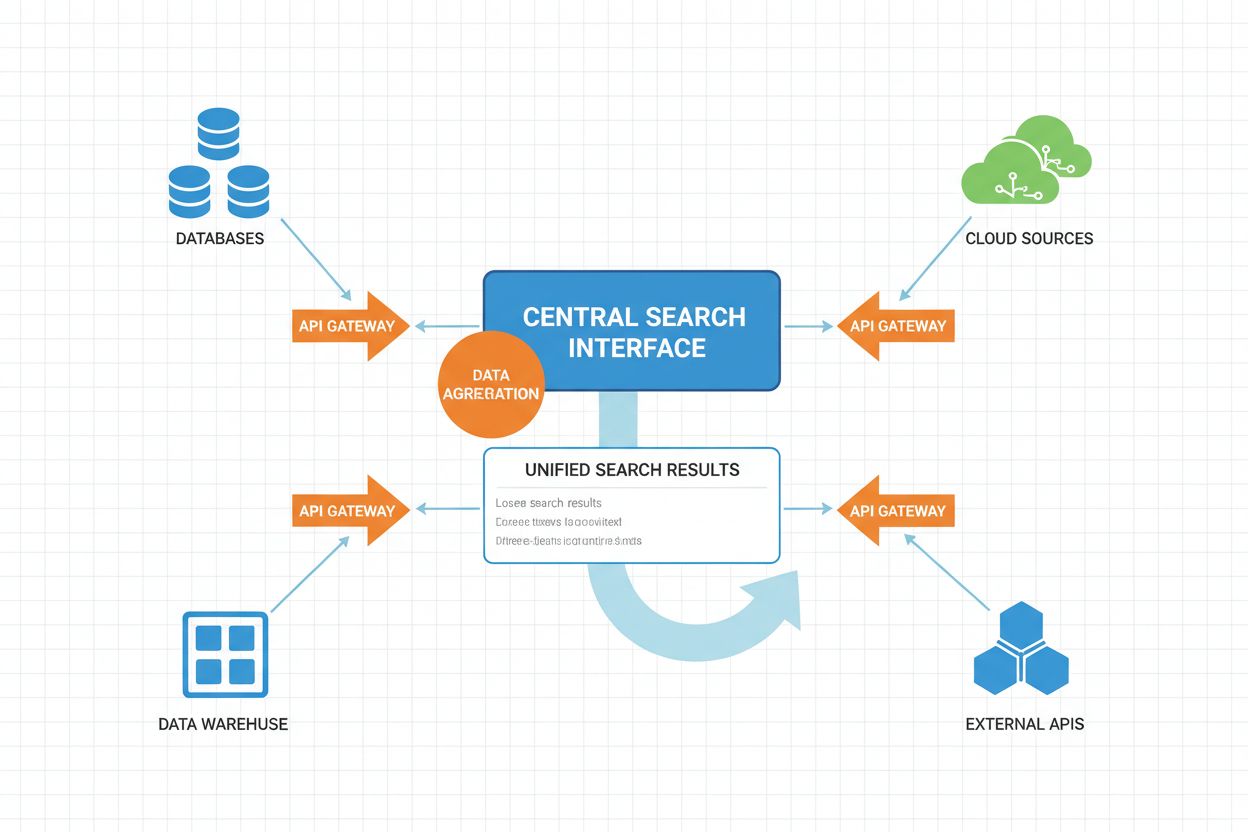
Query Processing Engine: The central component that receives user queries and orchestrates the federated search workflow. This engine includes query parsing, semantic analysis, and intent recognition modules. Advanced implementations use transformer-based language models to understand complex query semantics and implicit user intent.
Source Registry and Metadata Management: Maintains comprehensive metadata about available data sources including schema information, content characteristics, update frequency, availability patterns, and performance metrics. This registry enables intelligent source selection and query optimization. Machine learning models analyze historical query patterns to predict source relevance for new queries.
Intelligent Source Selection Module: Uses machine learning classifiers to determine which sources are most likely to contain relevant information for a given query. This module considers multiple factors including source content coverage, historical query success rates, source availability, and estimated response times. Advanced systems employ reinforcement learning to continuously optimize source selection strategies based on query outcomes.
Query Translation and Adaptation Layer: Converts user queries into source-specific formats and query languages. This includes SQL generation for relational databases, SPARQL for knowledge graphs, REST API calls for web services, and natural language queries for unstructured text systems. Semantic mapping ensures that query intent is preserved across different query languages and data models.
Distributed Execution Coordinator: Manages parallel query execution across multiple sources, handling timeout management, load balancing, and failure recovery. This component implements adaptive timeout strategies that adjust based on source response patterns and system load.
Result Normalization Engine: Converts results from heterogeneous sources into a common format for aggregation and ranking. This includes schema alignment, data type conversion, and format standardization. The engine handles missing fields, conflicting data types, and structural differences across sources.
Semantic Enrichment Module: Enhances results with additional context and semantic information. This includes entity linking to knowledge bases, semantic tagging based on ontologies, and relationship extraction from unstructured text. These enrichments improve ranking accuracy and result comprehensibility.
Learning-to-Rank Model: A machine learning model trained on historical query-result pairs to predict result relevance. This model considers hundreds of features including source credibility, content freshness, user profile alignment, and semantic similarity between query and result. Modern implementations use gradient boosting or neural network-based ranking models.
Deduplication Engine: Identifies and removes duplicate or near-duplicate results from different sources. This uses similarity metrics including exact matching, fuzzy string matching, and semantic similarity based on embeddings.
Personalization Engine: Customizes result ordering based on user profiles, historical preferences, and contextual information. This component implements collaborative filtering and content-based recommendation techniques to improve result relevance for individual users.
Caching and Optimization Layer: Implements intelligent caching strategies to reduce redundant queries to sources. This includes query result caching, source metadata caching, and learned query patterns that predict future information needs.
Monitoring and Analytics Module: Tracks system performance, source reliability, query patterns, and result quality metrics. This data feeds back into optimization components, enabling continuous system improvement.
Use Cases Across Industries
Healthcare and Medical Research: Federated search integrates patient records across hospital systems, research databases, clinical trial registries, and medical literature repositories. Physicians can query comprehensive patient histories across multiple healthcare providers without centralizing sensitive medical data. Researchers access distributed clinical data for epidemiological studies while maintaining HIPAA compliance and patient privacy.
Financial Services: Banks and investment firms use federated search to query trading data, market information, regulatory databases, and internal transaction records simultaneously. This enables real-time risk assessment, compliance monitoring, and market analysis without consolidating sensitive financial data in centralized repositories.
Legal and Compliance: Law firms and corporate legal departments search across case law databases, regulatory repositories, internal document management systems, and contract databases. Federated search enables comprehensive legal research while maintaining attorney-client privilege and document confidentiality.
E-Commerce and Retail: Online retailers integrate product catalogs across multiple warehouses, supplier systems, and marketplace platforms. Federated search provides unified product discovery while allowing suppliers to maintain independent inventory systems and pricing strategies.
Government and Public Administration: Government agencies search across distributed databases including census data, tax records, permit systems, and public records without centralizing sensitive citizen information. This enables comprehensive public services while maintaining data security and privacy.
Manufacturing and Supply Chain: Manufacturers integrate supplier databases, inventory systems, production records, and logistics platforms. Federated search provides supply chain visibility while allowing partners to maintain independent systems and proprietary information.
Education and Research: Universities search across institutional repositories, library systems, research databases, and open-access publications. Federated search enables comprehensive academic discovery while respecting institutional autonomy and intellectual property rights.
Telecommunications: Telecom providers search across customer databases, network infrastructure records, billing systems, and service catalogs. Federated search enables unified customer service while maintaining separate systems for different service lines and geographic regions.
Energy and Utilities: Energy companies search across generation facilities, distribution networks, customer databases, and regulatory compliance systems. Federated search provides operational visibility while allowing regional operators to maintain independent systems.
Media and Publishing: Media organizations search across content repositories, archives, rights management systems, and distribution platforms. Federated search enables comprehensive content discovery while preserving content ownership and licensing restrictions.
Challenges & Limitations
Source Heterogeneity and Integration Complexity: Integrating diverse data sources with different schemas, query languages, and access protocols requires substantial engineering effort. Schema mapping and semantic alignment remain challenging, particularly when sources use different representations for the same concepts.
Query Latency and Performance: Federated search inherently involves querying multiple sources, introducing latency compared to centralized systems. Slow or unresponsive sources can degrade overall query performance. Timeout management requires careful tuning to balance completeness and responsiveness.
Source Reliability and Availability: Federated systems depend on external sources remaining available and responsive. Network failures, source downtime, or performance degradation directly impact search quality. Graceful degradation becomes necessary when sources fail.
Result Quality and Ranking Accuracy: Aggregating results from sources with different quality levels, coverage, and relevance criteria is challenging. Ranking models must account for source credibility variations and avoid biasing results toward particular sources.
Data Freshness and Consistency: Federated systems access current source data, but sources may have different update frequencies and consistency guarantees. Reconciling conflicting information from different sources requires sophisticated conflict resolution strategies.
Scalability Limitations: As the number of sources increases, query coordination overhead grows. Selecting relevant sources from thousands of available options becomes computationally expensive. Parallel execution across many sources requires robust infrastructure.
Security and Access Control: Federated systems must enforce source-level access controls while providing unified search interfaces. Ensuring that users only access information they’re authorized to see across multiple sources is complex, particularly in multi-tenant environments.
Privacy and Data Protection: Federated search must comply with privacy regulations including GDPR, CCPA, and industry-specific requirements. Ensuring that sensitive data doesn’t leak through result aggregation or metadata analysis requires careful system design.
Source Discovery and Management: Identifying and cataloging available sources, maintaining accurate metadata, and managing source lifecycle (addition, removal, updates) requires ongoing operational effort.
Semantic Interoperability: Achieving true semantic interoperability across sources with different ontologies and data models remains challenging. Automated schema mapping and entity resolution techniques have limitations.
Cost of Coordination: While federated search eliminates data consolidation costs, it introduces coordination overhead. Managing distributed execution, handling failures, and optimizing query routing requires sophisticated infrastructure.
Limited Standardization: Lack of universal standards for federated search protocols and interfaces makes system integration more difficult and vendor lock-in more likely.
Federated AI Search vs. Related Technologies
Federated AI Search vs. Data Warehousing: Data warehousing consolidates data from multiple sources into a centralized repository, enabling fast queries but requiring significant ETL effort and introducing data latency. Federated search queries sources directly, providing real-time access but with higher query latency. Warehousing suits historical analysis and reporting, while federated search excels at current information discovery.
Federated AI Search vs. Data Lakes: Data lakes store raw data from multiple sources in a centralized location with minimal transformation. They provide flexibility but require significant storage and governance overhead. Federated search avoids data consolidation entirely, preserving source autonomy but requiring more sophisticated query processing.
Federated AI Search vs. APIs and Microservices: APIs provide programmatic access to individual services but require explicit knowledge of each service’s interface. Federated search abstracts away source-specific details, enabling unified querying across services. APIs suit application-to-application integration, while federated search enables cross-service information discovery.
Federated AI Search vs. Knowledge Graphs: Knowledge graphs represent information as interconnected entities and relationships, enabling semantic reasoning. Federated search can query distributed knowledge graphs but doesn’t require centralized graph construction. Knowledge graphs provide deeper semantic understanding, while federated search emphasizes source autonomy.
Federated AI Search vs. Search Engines: Traditional search engines maintain centralized indexes of crawled content. Federated search queries sources directly without pre-indexing. Search engines provide comprehensive coverage of public content, while federated search excels at integrating private, proprietary, or specialized sources.
Federated AI Search vs. Master Data Management (MDM): MDM systems create authoritative master records by consolidating data from multiple sources. Federated search queries sources independently without creating master records. MDM suits data governance and consistency, while federated search emphasizes source autonomy and real-time access.
Federated AI Search vs. Enterprise Search: Enterprise search typically indexes internal documents and databases into a centralized index. Federated search queries sources directly without centralized indexing. Enterprise search provides fast full-text search, while federated search accommodates diverse source types and real-time updates.
Federated AI Search vs. Blockchain and Distributed Ledgers: Blockchain systems maintain distributed consensus across nodes, ensuring data integrity and immutability. Federated search coordinates queries across independent sources without requiring consensus. Blockchain suits trust and verification, while federated search emphasizes information discovery.
Implementation Best Practices
Comprehensive Source Assessment: Before integrating sources, conduct thorough assessment of source characteristics including data quality, update frequency, availability patterns, schema complexity, and access protocols. This assessment informs source selection algorithms and helps set realistic performance expectations.
Incremental Integration: Begin with a small number of well-understood sources and gradually expand the federated system. This approach allows teams to develop expertise, identify integration challenges early, and refine processes before scaling.
Robust Metadata Management: Invest in comprehensive source metadata including schema information, content coverage, quality metrics, and performance characteristics. Maintain metadata accuracy through automated monitoring and periodic validation.
Intelligent Source Selection: Implement machine learning-based source selection that learns from query outcomes. Track which sources provide relevant results for different query types and continuously optimize source selection strategies.
Adaptive Timeout Management: Implement adaptive timeout strategies that adjust based on source response patterns and system load. Avoid fixed timeouts that either wait too long for slow sources or prematurely abandon responsive sources.
Result Quality Assurance: Establish metrics for result quality including relevance, freshness, and completeness. Implement feedback mechanisms allowing users to rate result quality, feeding this data into ranking model training.
Comprehensive Monitoring: Monitor source availability, response times, result quality, and user satisfaction. Use this data to identify problematic sources, optimize query routing, and improve system performance.
Security and Access Control: Implement source-level access controls that enforce authorization policies across the federated system. Ensure that users only access information they’re authorized to see, even when querying multiple sources.
Caching Strategies: Implement intelligent caching at multiple levels including query results, source metadata, and learned query patterns. Balance cache freshness with performance benefits.
User Experience Optimization: Design interfaces that clearly communicate result sources, confidence levels, and freshness. Provide transparency about which sources were queried and why certain results were ranked higher.
Performance Optimization: Profile query execution to identify bottlenecks. Optimize source selection algorithms, query translation, and result aggregation. Consider pre-computing common query patterns.
Continuous Learning: Implement feedback loops that capture user interactions with results. Use this data to continuously improve source selection, ranking models, and result presentation.
Documentation and Governance: Maintain comprehensive documentation of source characteristics, integration approaches, and system architecture. Establish governance policies for source addition, removal, and modification.
Testing and Validation: Implement comprehensive testing including unit tests for individual components, integration tests for source interactions, and end-to-end tests for complete query workflows. Validate result quality against known ground truth.
Future Trends & AI Integration
Advanced Natural Language Understanding: Future federated systems will leverage large language models and advanced NLP techniques to understand complex, multi-faceted queries with implicit context and nuanced intent. This enables more accurate source selection and result interpretation.
Autonomous Source Discovery: Machine learning systems will automatically discover and catalog available data sources, assess their relevance and quality, and integrate them into federated systems with minimal human intervention. This addresses the current challenge of manual source management.
Semantic Web Integration: As semantic web technologies mature, federated systems will leverage ontologies and linked data standards for deeper semantic interoperability. This enables more sophisticated reasoning across sources and better handling of heterogeneous data models.
Explainable AI and Transparency: Future systems will provide detailed explanations for ranking decisions, source selection, and result aggregation. This transparency builds user trust and enables better understanding of system behavior.
Federated Learning Integration: Federated learning techniques will enable training machine learning models across distributed sources without centralizing data. This combines federated search’s data autonomy with machine learning’s predictive power.
Real-Time Streaming Integration: Federated systems will increasingly integrate real-time data streams alongside traditional databases. This enables search over continuously updating information sources.
Multimodal Search: Future federated systems will search across diverse content types including text, images, video, and audio. Multimodal AI models will enable cross-modal search and result synthesis.
Personalization and Context Awareness: Advanced user modeling and context understanding will enable highly personalized federated search experiences. Systems will understand user expertise levels, information needs, and preferences to customize result presentation.
Quantum Computing Applications: As quantum computing matures, federated systems may leverage quantum algorithms for optimization problems including source selection and result ranking, potentially enabling faster query processing.
Blockchain Integration: Federated systems may integrate blockchain technologies for source verification, result provenance tracking, and decentralized coordination, particularly in trust-critical applications.
Edge Computing and Distributed Processing: Federated search will increasingly leverage edge computing to process queries closer to data sources, reducing latency and network overhead while improving privacy.
Autonomous Optimization: Self-optimizing federated systems will continuously learn from query patterns, source characteristics, and user feedback to autonomously improve performance without human intervention.
Cross-Domain Knowledge Integration: Future systems will integrate knowledge across traditionally separate domains, enabling discovery of unexpected connections and insights that emerge from combining diverse information sources.
Frequently asked questions
What is the main difference between federated AI search and traditional centralized search?
Traditional centralized search consolidates all data into a single indexed repository, requiring data migration and introducing latency. Federated AI search queries multiple independent sources directly in real-time without moving or duplicating data, preserving source autonomy while providing unified access. This makes federated search ideal for organizations with distributed data sources and strict data governance requirements.
How does federated AI search maintain security and compliance?
Federated AI search keeps data in its original location and respects each source's access controls and security policies. Users only access information they're authorized to see, and sensitive data never leaves its source system. This approach simplifies compliance with regulations like GDPR and HIPAA by eliminating the risks associated with centralizing sensitive information.
What are the main challenges of implementing federated AI search?
Key challenges include managing heterogeneous data sources with different schemas and formats, handling query latency from multiple sources, ensuring consistent result ranking across sources, and maintaining system reliability when sources are unavailable. Organizations must also invest in robust metadata management and intelligent source selection algorithms to optimize performance.
Can federated AI search scale as data sources grow?
Yes, federated AI search scales by adding new sources without requiring data migration or warehouse restructuring. However, as the number of sources increases, query coordination overhead grows. Modern systems use machine learning for intelligent source selection and implement caching strategies to maintain performance at scale.
How does federated AI search differ from data warehousing?
Data warehousing consolidates data into a centralized repository, enabling fast queries but requiring significant ETL effort and introducing data latency. Federated search queries sources directly, providing real-time access but with higher query latency. Warehousing suits historical analysis and reporting, while federated search excels at current information discovery across distributed sources.
What industries benefit most from federated AI search?
Healthcare, finance, e-commerce, government, and research organizations benefit significantly from federated search. Healthcare uses it to integrate patient records across providers, finance uses it for compliance and risk assessment, e-commerce uses it for unified product discovery, and research organizations use it to search across distributed academic databases.
How does AI enhance federated search capabilities?
AI enhances federated search through natural language processing for query understanding, machine learning for intelligent source selection, semantic analysis for better result ranking, and automated deduplication. AI models learn from query patterns to continuously optimize source selection and result aggregation, improving system performance over time.
What is the role of semantic understanding in federated AI search?
Semantic understanding enables federated systems to comprehend query intent beyond keyword matching, identify relevant sources more accurately, and rank results based on meaning rather than just keyword overlap. This includes entity recognition, relationship extraction, and knowledge graph integration, resulting in more relevant and contextually appropriate search results.
Monitor How AI References Your Brand
AmICited tracks how AI systems like ChatGPT, Perplexity, and Google AI Overviews cite and reference your brand. Understand your AI visibility and optimize your presence in AI-generated answers.
How Enterprise Companies Approach AI Search: Strategy and Implementation
Enterprise AI search strategy: integration, governance, ROI metrics. Learn how large organizations implement AI search platforms for ChatGPT, Perplexity, and in...
Learn what SearchGPT is, how it works, and its impact on search, SEO, and digital marketing. Explore features, limitations, and the future of AI-powered search.
Learn what AI search engines are, how they differ from traditional search, and their impact on brand visibility. Explore platforms like Perplexity, ChatGPT, Goo...
12 min read
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.