Definition of Google Gemini
Google Gemini is a family of multimodal large language models (LLMs) developed by Google DeepMind, representing the successor to earlier models like LaMDA and PaLM 2. Unlike traditional language models that process only text, Gemini is fundamentally designed to handle multiple data modalities simultaneously, including text, images, audio, video, and software code. The model powers the Gemini AI chatbot (formerly known as Bard) and is increasingly integrated throughout Google’s ecosystem of products and services. Gemini’s multimodal architecture enables it to understand complex relationships between different types of information, making it capable of tasks ranging from image analysis and code generation to real-time translation and document understanding. The term “Gemini” itself derives from Latin meaning “twins,” referencing the collaboration between Google DeepMind and Google Brain teams, and was also inspired by NASA’s Project Gemini spacecraft program.
Historical Context and Development Timeline
Google’s journey toward creating Gemini reflects years of foundational research in large language models and neural network architecture. In 2017, Google researchers introduced the transformer architecture, a breakthrough neural network design that became the foundation for most modern LLMs. The company subsequently developed Meena (2020), a conversational AI with 2.6 billion parameters, followed by LaMDA (Language Model for Dialogue Applications) in 2021, which specialized in dialogue tasks. The release of PaLM (Pathways Language Model) in 2022 brought enhanced coding, multilingual, and reasoning capabilities. Google then launched Bard in early 2023, initially powered by a lightweight LaMDA variant, before upgrading it to PaLM 2 in mid-2023. The company officially announced Gemini 1.0 in December 2023, marking a significant leap in multimodal capabilities. In 2024, Google rebranded Bard as Gemini and released Gemini 1.5, introducing a revolutionary 2 million token context window. Most recently, Gemini 2.0 and Gemini 2.5 (released in December 2024) introduced agentic AI capabilities, enabling the model to take autonomous actions and reason across extended contexts. This evolution demonstrates Google’s commitment to advancing AI capabilities while maintaining focus on practical, real-world applications.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Technical Architecture and Core Components
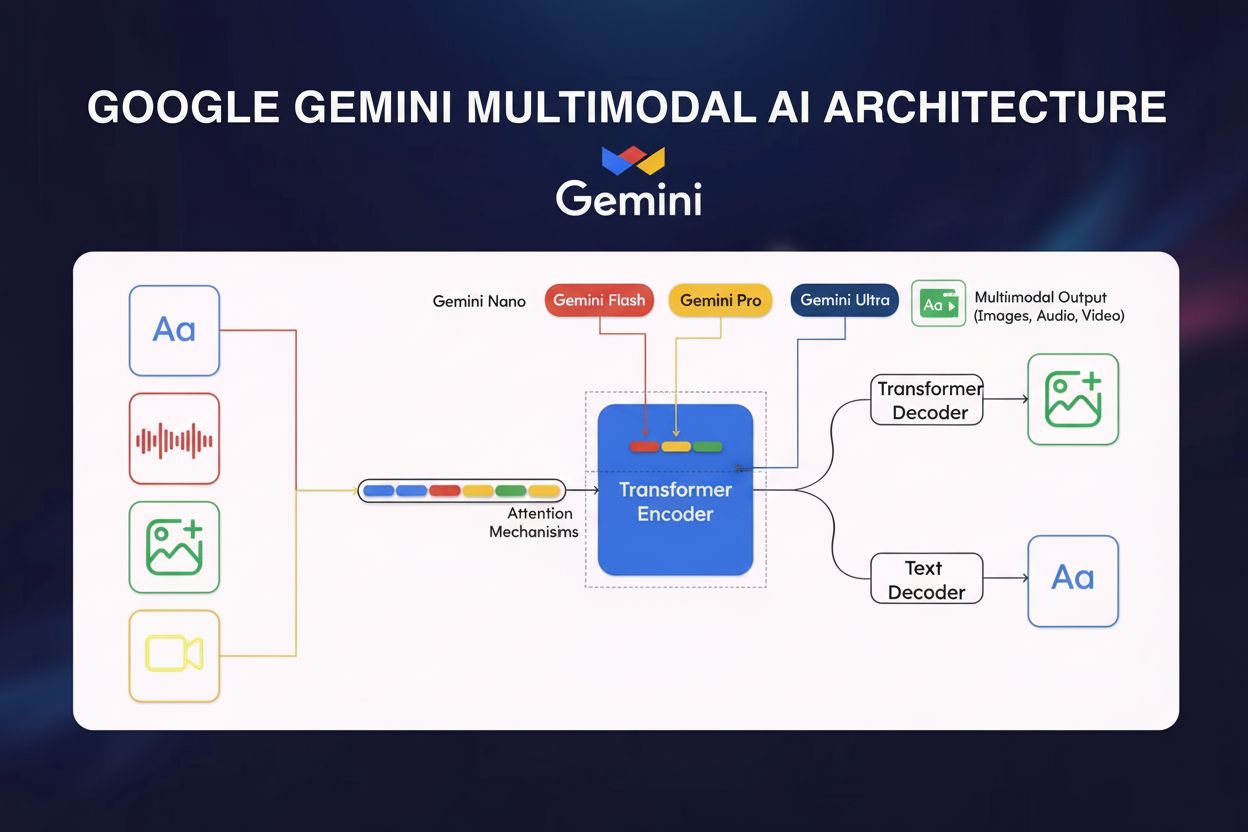
The technical foundation of Google Gemini rests on several sophisticated architectural innovations that distinguish it from competing models. At its core, Gemini employs a transformer-based neural network architecture optimized with Cloud TPU v5p (Tensor Processing Units) for high-performance training and inference. The model’s multimodal encoder integrates visual data, speech, and text through specialized processing pathways that converge into a unified representation space. A critical innovation is the cross-modal attention mechanism, which enables the model to establish meaningful connections between different data types—for example, linking visual elements in an image to textual descriptions or understanding how audio content relates to visual context. Gemini 1.5 Pro introduced the Mixture of Experts (MoE) architecture, which represents a paradigm shift in model efficiency. Rather than activating all neural network parameters for every input, MoE splits the model into smaller expert networks, each specializing in particular domains or data types. The model learns to selectively activate only the most relevant experts based on input characteristics, dramatically reducing computational overhead while maintaining or improving performance. This architecture enables Gemini 1.5 Flash to achieve comparable performance to Gemini 1.0 Ultra while being significantly more efficient, achieved through knowledge distillation—a machine learning technique where insights from the larger Pro model are transferred to the more compact Flash variant. The context window—the number of tokens a model can process simultaneously—has expanded dramatically: from 32,000 tokens in Gemini 1.0 to 1 million tokens in Gemini 1.5 Flash and 2 million tokens in Gemini 1.5 Pro, enabling processing of entire books, lengthy video content, or thousands of lines of code in single interactions.
Gemini Model Variants and Their Applications
| Model Variant | Size/Tier | Context Window | Primary Use Cases | Deployment | Key Advantage |
|---|
| Gemini 1.0 Nano | Smallest | 32,000 tokens | Mobile tasks, on-device processing, image description, chat replies | Android devices (Pixel 8 Pro+), Chrome desktop | Runs without internet connection |
| Gemini 1.0 Ultra | Largest | 32,000 tokens | Complex reasoning, advanced coding, mathematical analysis, multimodal reasoning | Cloud-based, enterprise | Highest accuracy on benchmarks |
| Gemini 1.5 Pro | Mid-sized | 2 million tokens | Document analysis, code repositories, long-form content, enterprise applications | Google Cloud, API access | Longest context window, balanced performance |
| Gemini 1.5 Flash | Lightweight | 1 million tokens | Fast responses, cost-effective processing, real-time applications | Cloud, mobile, edge | Speed and efficiency optimization |
| Gemini 2.0/2.5 | Next-generation | Variable | Agentic AI, autonomous task execution, advanced reasoning, real-time interactions | Cloud, integrated services | Agentic capabilities, improved reasoning |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Multimodal Processing and Cross-Modal Understanding
The multimodal nature of Google Gemini represents a fundamental departure from earlier AI models that operated primarily within single modalities. Gemini’s ability to process interleaved sequences of audio, image, text, and video as both inputs and outputs enables sophisticated reasoning tasks that would be impossible for single-modality models. For instance, Gemini can analyze a video, extract relevant text from frames, understand spoken dialogue, and generate comprehensive summaries that synthesize information across all modalities. This capability has profound implications for real-world applications: in medical diagnostics, Gemini can analyze patient records (text), medical imaging (visual), and patient interviews (audio) simultaneously to provide comprehensive assessments. In customer service, it can process customer inquiries (text), analyze product images, review video demonstrations, and generate contextually appropriate responses. The cross-modal attention mechanism that enables this integration works by creating shared representations where information from different modalities can influence each other’s processing. When analyzing an image with accompanying text, for example, the text context helps the visual processing pathway focus on relevant image regions, while visual information helps disambiguate textual references. This bidirectional influence creates a more holistic understanding than would be possible by processing modalities independently. The practical implications for AI monitoring and brand tracking are significant: when Gemini generates responses that include images, text, and potentially audio, monitoring systems must track how brands appear across all these modalities, not just in text-based responses.
Google Gemini Ultra has demonstrated exceptional performance across multiple standardized AI benchmarks, establishing itself as a highly capable model in the competitive landscape of large language models. On the MMLU benchmark (Massive Multitask Language Understanding), which tests natural language understanding across 57 diverse subjects, Gemini Ultra exceeded even human expert performance—a significant milestone in AI development. For mathematical reasoning (GSM8K benchmark), Gemini Ultra outperformed competing models including Claude 2, GPT-4, and Llama 2. In code generation (HumanEval benchmark), Gemini demonstrated superior capabilities, enabling advanced programming assistance and code analysis. However, performance varies across different evaluation metrics: while Gemini Ultra excels in document understanding, image understanding, and automatic speech recognition benchmarks, it shows more modest improvements in areas like common sense reasoning (HellaSwag benchmark), where GPT-4 still maintains an edge. The Gemini 1.5 series has proven particularly impressive, with both Flash and Pro variants matching or exceeding Gemini 1.0 Ultra performance while offering dramatically improved efficiency and expanded context windows. This performance trajectory is especially relevant for AI citation monitoring: as Gemini’s capabilities improve and its user base expands to 350 million monthly active users, the accuracy and comprehensiveness of its responses directly impact how brands and domains are represented in AI-generated content. Organizations using platforms like AmICited can track whether Gemini’s responses about their brand are factually accurate and appropriately contextualized.
Integration Across Google’s Ecosystem
The strategic integration of Google Gemini throughout Google’s product ecosystem represents one of the most comprehensive deployments of an AI model across a technology company’s offerings. Gemini is now the default AI assistant on Google Pixel 9 and Pixel 9 Pro smartphones, replacing the previous Google Assistant, making it the primary AI interface for millions of users. Within Google Workspace, Gemini appears in the Docs side panel to assist with writing and editing, in Gmail to help draft messages and suggest responses, and across other productivity applications. Google Maps leverages Gemini’s capabilities to provide intelligent summaries of places and areas, enhancing the user experience with contextual information. Google Search has integrated Gemini through AI Overviews, which generate comprehensive answers to user queries by synthesizing information from multiple sources. The Gemini API is available through Google AI Studio and Google Cloud Vertex AI, enabling developers to integrate Gemini capabilities into custom applications. This ecosystem integration has profound implications for brand monitoring and AI citation tracking. When a user searches for information about a company or product on Google Search, Gemini may generate an AI Overview that includes or excludes mentions of that brand. When someone uses Gmail with Gemini, the model might reference company information in suggested responses. When developers build applications using the Gemini API, they’re creating new touchpoints where brands can appear in AI-generated content. This widespread integration makes comprehensive monitoring across all these platforms essential for maintaining brand integrity and ensuring accurate representation in AI responses.
Key Capabilities and Use Cases
- Advanced Code Generation and Analysis: Gemini can understand, explain, and generate code across multiple programming languages (C++, Java, Python, etc.), with fine-tuned versions powering AlphaCode2 for solving competitive programming problems
- Image and Text Understanding: Extract text from images without OCR tools, caption images, analyze charts and diagrams, and perform complex visual reasoning tasks
- Multilingual Translation: Leverage multimodal capabilities for real-time translation across languages, integrated into services like Google Meet with translated captions
- Malware Analysis: Both Gemini 1.5 Pro and Flash can analyze code snippets and files to determine maliciousness and generate detailed security reports
- Personalized AI Experts (Gems): Create customized AI assistants for specific tasks or topics, with premade options including learning coaches, brainstorming partners, and writing editors
- Universal AI Agents: Through Project Astra, Gemini processes, remembers, and understands multimodal information in real-time, enabling AI assistants that can explain objects, recognize locations, and recall previous interactions
- Voice Conversations: Gemini Live enables natural, conversational dialogue that adapts to individual speaking styles and preferences
- Deep Research: Analyze hundreds of websites, synthesize findings, and generate comprehensive reports on complex topics
Gemini’s Role in AI Monitoring and Brand Representation
The emergence of Google Gemini as a major AI platform with 350 million monthly active users has created new imperatives for brand monitoring and AI citation tracking. Unlike traditional search engines where brands appear in ranked lists of results, Gemini generates synthesized responses that may or may not mention specific companies, products, or domains. When a user asks Gemini about a particular industry or topic, the model decides which sources to reference, which information to highlight, and how to contextualize brand mentions. This represents a significant shift from traditional SEO, where visibility depends on ranking position, to what might be called “AI citation optimization”—ensuring that brands appear accurately and appropriately in AI-generated responses. The multimodal nature of Gemini adds complexity to monitoring: brands may appear not just in text responses but also in images, audio transcriptions, or video references that Gemini generates. The integration of Gemini across Google’s ecosystem means that brand mentions can occur in multiple contexts: in Google Search AI Overviews, in Gmail suggestions, in Google Maps summaries, and in custom applications built with the Gemini API. Organizations need to understand how Gemini represents their brand across these different contexts and whether the information provided is accurate, complete, and appropriately contextualized. Platforms like AmICited address this need by monitoring how brands appear in Gemini responses alongside other AI platforms like ChatGPT, Perplexity, Claude, and Google AI Overviews, providing comprehensive visibility into AI-generated brand representation.
Risks, Limitations, and Ethical Considerations
Despite its impressive capabilities, Google Gemini faces several documented challenges that organizations must consider when relying on its outputs. AI bias emerged as a significant issue in February 2024 when Google paused Gemini’s image generation capability due to inaccurate and biased portrayals of historical figures, with the model erasing historical context around racial diversity. This incident highlighted how multimodal AI systems can perpetuate or amplify biases present in training data. Hallucinations—instances where the model generates factually incorrect information—continue to affect Gemini, particularly in AI Overviews where users may trust synthesized information without verification. Google has acknowledged ongoing issues with Gemini-backed search results occasionally producing false or misleading outputs. Intellectual property violations represent another concern: Google faced regulatory fines in France (€250 million) for training Gemini on copyrighted news content without publisher knowledge or consent, raising questions about data sourcing and fair use. These limitations have direct implications for brand monitoring: organizations cannot assume that information Gemini provides about competitors or industry topics is accurate, and they must verify how their own brand is represented. The potential for Gemini to generate misleading information about a company’s products, history, or market position creates risks that traditional search engine monitoring alone cannot address. Additionally, the model’s tendency to synthesize information from multiple sources without always clearly attributing claims means that brand mentions in Gemini responses may lack proper context or source attribution.
Future Evolution and Strategic Outlook
The trajectory of Google Gemini’s development suggests continued expansion in capabilities, efficiency, and integration across Google’s ecosystem and beyond. Gemini 2.0 and 2.5 introduced agentic AI capabilities, enabling the model to take autonomous actions, plan multi-step tasks, and reason across extended contexts—a significant evolution from earlier versions that primarily responded to user queries. Future versions are expected to further refine reasoning capabilities, handle even larger context windows, and improve performance on specialized tasks. Project Astra, Google’s initiative to build universal AI agents, represents the long-term vision for Gemini: AI systems that can process, remember, and understand multimodal information in real-time, enabling more natural and capable interactions. Project Mariner and other research initiatives suggest Google is exploring how Gemini can assist with complex knowledge work, potentially automating research, analysis, and decision-making tasks. The integration of Gemini into more Google products and services will likely continue, expanding the touchpoints where brands appear in AI-generated responses. On-device efficiency improvements will make Gemini more accessible on mobile devices and edge computing platforms, potentially increasing its user base beyond the current 350 million monthly active users. The competitive landscape will also influence Gemini’s evolution: as other AI platforms like ChatGPT, Claude, and Perplexity continue advancing, Google will need to maintain Gemini’s competitive advantages in multimodal processing, integration with Google services, and real-time knowledge access. For organizations focused on AI monitoring and brand representation, this evolution means that tracking how brands appear in Gemini responses will become increasingly important as the platform’s capabilities expand and its user base grows. The shift toward agentic AI also raises new questions about how autonomous AI systems will represent and reference brands when making decisions or taking actions on behalf of users.
Conclusion: Gemini’s Impact on AI-Driven Brand Monitoring
Google Gemini represents a fundamental shift in how AI systems process information and generate responses, with profound implications for brand monitoring and AI citation tracking. As a multimodal AI model with 350 million monthly active users, integrated across Google’s ecosystem, and continuously evolving toward more capable agentic systems, Gemini has become a critical platform for organizations to monitor. Unlike traditional search engines where visibility depends on ranking position, Gemini’s synthesized responses create new dynamics where brands may or may not be mentioned, and when mentioned, may be represented accurately or inaccurately. The model’s documented limitations—including bias, hallucinations, and intellectual property concerns—underscore the importance of active monitoring rather than passive trust in AI-generated information. Organizations seeking to maintain brand integrity and ensure accurate representation in AI responses must adopt comprehensive monitoring strategies that track how their brand appears across Gemini and other major AI platforms. This represents a new frontier in digital marketing and brand management, where success depends not just on traditional SEO and search visibility, but on understanding and optimizing how AI systems represent and reference brands in their generated responses.