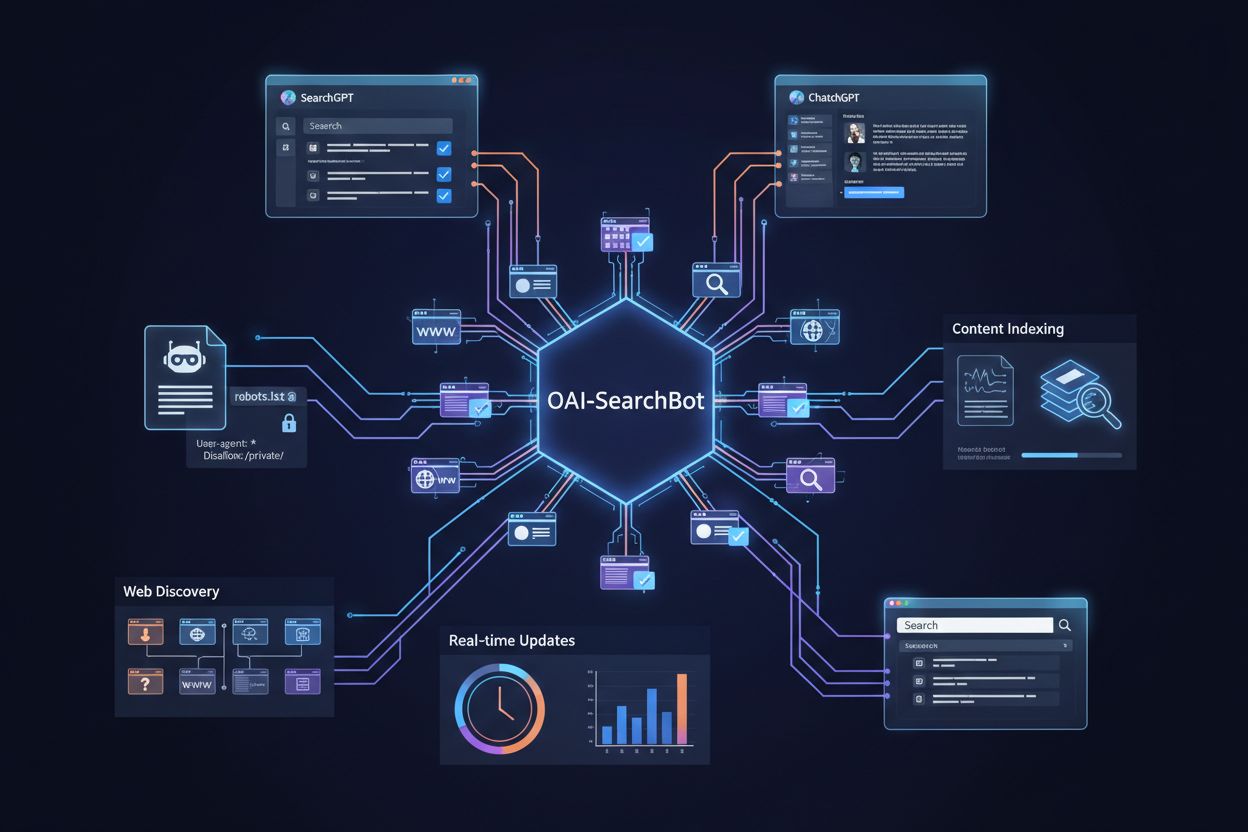
OpenAI’s official web crawler that collects training data for AI models like ChatGPT and GPT-4. Website owners can control access via robots.txt using ‘User-agent: GPTBot’ directives. The crawler respects standard web protocols and only indexes publicly accessible content.
GPTBot
OpenAI's official web crawler that collects training data for AI models like ChatGPT and GPT-4. Website owners can control access via robots.txt using 'User-agent: GPTBot' directives. The crawler respects standard web protocols and only indexes publicly accessible content.
What is GPTBot?
GPTBot is OpenAI’s official web crawler, designed to index publicly available content from across the internet for training and improving AI models like ChatGPT and GPT-4. Unlike general-purpose search engine crawlers such as Googlebot, GPTBot operates with a specific mission: to gather data that helps OpenAI enhance its language models and provide better AI-powered responses to users. Website owners can identify GPTBot through its distinctive user agent string (“GPTBot/1.0”), which appears in server logs and analytics platforms whenever the crawler accesses their pages. GPTBot respects the robots.txt file, meaning website owners can control whether the crawler accesses their content by adding specific directives to this file. The crawler only indexes publicly accessible content and does not attempt to bypass authentication or access restricted areas of websites. Understanding GPTBot’s purpose and behavior is essential for website owners who want to make informed decisions about whether to allow or block this crawler from accessing their digital properties.
How GPTBot Works
GPTBot operates by systematically crawling web pages, analyzing their content, and sending data back to OpenAI’s servers for processing and model training. The crawler first checks a website’s robots.txt file to determine which pages it’s permitted to access, respecting the directives specified by website owners before proceeding with any indexing activity. Once GPTBot identifies itself through its user agent string, it downloads and processes page content, extracting text, metadata, and structural information that contributes to training datasets. The crawler can generate significant bandwidth consumption, with some websites reporting 30TB or more in monthly crawler traffic across all bots combined, though GPTBot’s individual impact varies based on site size and content relevance.
Crawler Name
Purpose
Respects robots.txt
Impact on SEO
Data Usage
GPTBot
AI model training
Yes
Indirect (AI visibility)
Training datasets
Googlebot
Search indexing
Yes
Direct (rankings)
Search results
Bingbot
Search indexing
Yes
Direct (rankings)
Search results
ClaudeBot
AI model training
Yes
Indirect (AI visibility)
Training datasets
Website owners can monitor GPTBot activity through server logs by searching for the specific user agent string, allowing them to track crawl frequency and identify potential performance impacts. The crawler’s behavior is designed to be respectful of server resources, but high-traffic websites may still experience noticeable bandwidth usage when multiple AI crawlers operate simultaneously.
Why Website Owners Block GPTBot
Many website owners choose to block GPTBot due to concerns about content usage without compensation, as OpenAI uses crawled content to train commercial AI models while providing no direct benefit or payment to content creators. Server load represents another significant concern, particularly for smaller websites or those with limited bandwidth, as AI crawlers can consume substantial resources—some sites report 30TB+ monthly crawler traffic across all bots, with GPTBot contributing meaningfully to this total. Data exposure and security risks worry content creators who fear their proprietary information, trade secrets, or sensitive data could be inadvertently indexed and used in AI training, potentially compromising competitive advantages or violating confidentiality agreements. The legal landscape surrounding AI training data remains uncertain, with unresolved questions about GDPR compliance, CCPA obligations, and copyright infringement creating liability concerns for both OpenAI and websites that allow unrestricted crawling. Statistics reveal that approximately 3.5% of websites actively block GPTBot, while more than 30 major publications in the top 100 websites block the crawler, including The New York Times, CNN, Associated Press, and Reuters—indicating that high-authority content creators recognize significant risks. The combination of these factors has made GPTBot blocking an increasingly common practice among publishers, media companies, and content-heavy websites seeking to protect their intellectual property and maintain control over how their content is used.
Why Website Owners Allow GPTBot
Website owners who permit GPTBot access recognize the strategic value of ChatGPT visibility, given that the platform serves approximately 800 million weekly users who regularly interact with AI-generated responses that may reference or summarize indexed content. When GPTBot crawls a website, it increases the likelihood that the site’s content will be cited, summarized, or referenced in ChatGPT responses, providing brand representation within AI interfaces and reaching users who increasingly turn to AI tools instead of traditional search engines. Research demonstrates that AI search traffic converts 23x better than traditional organic search traffic, meaning users who discover content through AI summaries and recommendations show significantly higher engagement and conversion rates compared to standard search engine visitors. Allowing GPTBot access represents a form of future-proofing, as AI-powered search and content discovery become increasingly dominant in how users find information online, making early adoption of AI visibility strategies a competitive advantage. Website owners who embrace GPTBot positioning also benefit from Generative Engine Optimization (GEO), a emerging discipline focused on optimizing content for AI systems rather than traditional search algorithms, which can drive substantial long-term traffic growth. By allowing GPTBot access, forward-thinking publishers and businesses position themselves to capture traffic from the rapidly growing segment of users who rely on AI tools for information discovery and decision-making.
How to Block GPTBot
Blocking GPTBot is straightforward and requires only modifications to your website’s robots.txt file, which is located in your root directory and controls crawler access across your entire domain. The simplest approach is to add a complete block for all OpenAI crawlers:
User-agent: GPTBot
Disallow: /
If you want to block GPTBot from specific directories while allowing access to others, use targeted directives:
Beyond robots.txt modifications, website owners can implement alternative blocking methods including IP-based blocking through firewalls, Web Application Firewalls (WAF) that filter requests by user agent, and rate limiting that restricts crawler bandwidth consumption. For maximum control, some sites combine multiple approaches—using robots.txt as the primary mechanism while implementing IP blocking as a secondary safeguard against crawlers that ignore robots.txt directives. After implementing any blocking strategy, verify effectiveness by checking your server logs for GPTBot user agent strings to confirm the crawler is no longer accessing your content.
Industries That Should Consider Blocking
Certain industries face particular risks from unrestricted AI crawler access and should carefully evaluate whether blocking GPTBot aligns with their business interests and content protection strategies:
Publishing & Media Companies (newspapers, magazines, news agencies) - Original journalism represents significant investment and competitive advantage; publications like The New York Times, Associated Press, and Reuters block GPTBot to protect exclusive reporting
E-commerce Platforms (Amazon, retail sites) - Product descriptions, pricing strategies, and customer reviews represent proprietary business data that competitors could leverage through AI training
User-Generated Content Platforms (social media, forums, review sites) - Content created by users may be used without consent or compensation, raising ethical and legal concerns about user rights
High-Authority Data Sites (research institutions, academic databases, specialized knowledge repositories) - Proprietary research, datasets, and specialized knowledge have significant commercial value and should remain under creator control
Legal and Financial Services - Sensitive client information, legal strategies, and financial advice require strict confidentiality and cannot be exposed through AI training datasets
Healthcare and Medical Content - Patient data, medical records, and clinical information must comply with HIPAA and other regulations that prohibit unauthorized data usage
These industries should implement blocking strategies to maintain competitive advantages, protect proprietary information, and ensure compliance with data protection regulations.
Monitoring and Detection
Website owners should regularly monitor their server logs to identify GPTBot activity and track crawling patterns, which provides visibility into how AI systems are accessing and potentially using their content. GPTBot identification is straightforward—the crawler identifies itself through the user agent string “GPTBot/1.0” in HTTP request headers, making it easily distinguishable from other crawlers in server logs and analytics platforms. Most modern analytics tools and SEO monitoring software (including Google Analytics, Semrush, Ahrefs, and specialized bot monitoring platforms) automatically categorize and report GPTBot activity, allowing website owners to track crawl frequency, bandwidth consumption, and accessed pages without manual log analysis. Examining server logs directly reveals detailed information about GPTBot requests, including timestamps, accessed URLs, response codes, and bandwidth usage, providing granular insights into crawler behavior. Regular monitoring is essential because crawler behavior can change over time, new AI crawlers may emerge, and blocking effectiveness requires periodic verification to ensure directives are functioning as intended. Website owners should establish baseline metrics for normal crawler traffic and investigate significant deviations that might indicate increased AI crawler activity or potential security issues requiring attention.
OpenAI’s Safety Standards
OpenAI has made public commitments to responsible AI development and data handling, including explicit statements that GPTBot respects website owners’ preferences as expressed through robots.txt files and other technical directives. The company emphasizes data privacy and responsible AI practices, acknowledging that content creators have legitimate interests in controlling how their work is used and compensated, though OpenAI’s current approach does not provide direct compensation to crawled content creators. OpenAI’s documented policy confirms that GPTBot respects robots.txt directives, meaning the company has built compliance mechanisms into its crawler infrastructure and expects website owners to use standard technical tools to control access. The company has also indicated willingness to engage with publishers and content creators regarding data usage concerns, though formal licensing agreements and compensation frameworks remain limited. OpenAI’s policies continue to evolve in response to legal challenges, regulatory pressure, and industry feedback, suggesting that future versions of GPTBot may include additional safeguards, transparency measures, or compensation mechanisms. Website owners should monitor OpenAI’s official communications and policy updates to understand how the company’s approach to content crawling and data usage may change over time.
GPTBot vs Other AI Crawlers
OpenAI operates three distinct crawler types for different purposes: GPTBot (general web crawling for model training), ChatGPT-User (crawling links shared by ChatGPT users), and ChatGPT-Plugins (accessing content through plugin integrations)—each with different user agent strings and access patterns. Beyond OpenAI’s crawlers, the AI landscape includes numerous other crawlers operated by competing companies: Google-Extended (Google’s AI training crawler), CCBot (Commoncrawl), Perplexity (AI search engine), Claude (Anthropic’s AI model), and emerging crawlers from other AI companies, each with distinct purposes and data usage patterns. Website owners face a strategic choice between selective blocking (targeting specific crawlers like GPTBot while allowing others) and comprehensive blocking (restricting all AI crawlers to maintain complete control over content usage). The proliferation of AI crawlers means that blocking GPTBot alone may not fully protect content from AI training, as other crawlers may still access and index the same material through alternative mechanisms. Some website owners implement tiered strategies, blocking the most aggressive or commercially significant crawlers while allowing smaller or research-focused crawlers to access content. Understanding the differences between these crawlers helps website owners make informed decisions about which crawlers to block based on their specific concerns about data usage, competitive impact, and business objectives.
Impact on SEO and Search Visibility
ChatGPT’s influence on search behavior is reshaping how users discover information, with 800 million weekly users increasingly turning to AI tools instead of traditional search engines, fundamentally changing the competitive landscape for content visibility. AI-generated summaries and featured snippets in ChatGPT responses now serve as alternative discovery mechanisms, meaning content that ranks well in traditional search results may be overlooked if it’s not selected for inclusion in AI-generated answers. Generative Engine Optimization (GEO) has emerged as a critical discipline for forward-thinking content creators, focusing on optimizing content structure, clarity, and authority to increase the likelihood of inclusion in AI-generated responses and summaries. The long-term visibility implications are significant: websites that block GPTBot may lose opportunities to appear in ChatGPT responses, potentially reducing traffic from the rapidly growing segment of AI-powered search users, while those that allow access position themselves for AI-driven discovery. Research indicates that 86.5% of content in Google’s top 20 search results contains partially AI-generated elements, demonstrating that AI integration is becoming standard across the search landscape rather than a niche concern. Competitive positioning increasingly depends on visibility across both traditional search engines and AI systems, making strategic decisions about GPTBot access critical to long-term SEO success and organic traffic growth. Website owners must balance content protection concerns against the risk of losing visibility in AI systems that are becoming primary discovery mechanisms for millions of users worldwide.
Frequently asked questions
What is GPTBot and how does it differ from Googlebot?
GPTBot is OpenAI's official web crawler designed to collect training data for AI models like ChatGPT and GPT-4. Unlike Googlebot, which indexes content for search engine results, GPTBot gathers data specifically to improve language models. Both crawlers respect robots.txt directives and only access publicly available content, but they serve fundamentally different purposes in the digital ecosystem.
Should I block GPTBot from my website?
The decision depends on your business goals and content strategy. Block GPTBot if you have proprietary content, operate in regulated industries, or have concerns about intellectual property. Allow GPTBot if you want visibility in ChatGPT (800M weekly users), benefit from AI search traffic (which converts 23x better than organic), or want to future-proof your digital presence for AI-driven search.
How do I block GPTBot using robots.txt?
Add these lines to your robots.txt file to block GPTBot from your entire site: User-agent: GPTBot / Disallow: /. To block specific directories, replace the forward slash with the directory path. To block all OpenAI crawlers, add separate User-agent entries for GPTBot, ChatGPT-User, and ChatGPT-Plugins. Changes take effect immediately and are easily reversible.
What is the impact of GPTBot on my server and bandwidth?
GPTBot's impact varies based on your site size and content relevance. While individual crawler impact is typically manageable, multiple AI crawlers operating simultaneously can consume significant bandwidth—some sites report 30TB+ monthly crawler traffic across all bots. Monitor your server logs to track GPTBot activity and implement rate limiting or IP blocking if bandwidth consumption becomes problematic.
Can I partially block GPTBot from certain pages?
Yes, you can use targeted robots.txt directives to block GPTBot from specific directories or pages while allowing access to others. For example, you can disallow /private/ and /admin/ directories while allowing the rest of your site. This selective approach lets you protect sensitive content while maintaining visibility in AI systems for public-facing pages.
How do I know if GPTBot is visiting my website?
Check your server logs for the user agent string 'GPTBot/1.0' in HTTP request headers. Most analytics platforms (Google Analytics, Semrush, Ahrefs) automatically categorize and report GPTBot activity. You can also use SEO monitoring tools that specifically track AI crawler activity. Regular monitoring helps you understand crawl frequency and identify any performance impacts.
What are the legal implications of blocking or allowing GPTBot?
The legal landscape is still evolving. Allowing GPTBot raises questions about GDPR compliance, CCPA obligations, and copyright infringement, though OpenAI claims to respect robots.txt directives. Blocking GPTBot is legally straightforward but may limit your visibility in AI systems. Consult with legal counsel if you operate in regulated industries or handle sensitive data to determine the best approach for your situation.
How does allowing GPTBot affect my SEO and search visibility?
Allowing GPTBot doesn't directly impact traditional Google rankings, but it increases your visibility in ChatGPT responses and other AI-powered search results. With 800M ChatGPT users and AI search traffic converting 23x better than organic, allowing GPTBot positions you for long-term visibility in AI systems. Blocking GPTBot may reduce opportunities to appear in AI-generated answers, potentially limiting traffic from the fastest-growing search segment.
Monitor Your Brand in AI Search Results
Track how your brand appears across ChatGPT, Perplexity, Google AI, and other AI platforms. Get real-time insights into AI citations and visibility with AmICited.
What is GPTBot and Should You Allow It? Complete Guide for Website Owners
Learn what GPTBot is, how it works, and whether you should allow or block OpenAI's web crawler. Understand the impact on your brand visibility in AI search engi...
GPTBot vs OAI-SearchBot: Understanding OpenAI's Different Crawlers
Learn the key differences between GPTBot and OAI-SearchBot crawlers. Understand their purposes, crawl behaviors, and how to manage them for optimal content visi...