
AI Index Coverage
Learn what AI Index Coverage is and why it matters for your brand's visibility in ChatGPT, Google AI Overviews, and Perplexity. Discover technical factors, best...
8 min read

Index coverage refers to the percentage and status of website pages that have been discovered, crawled, and included in a search engine’s index. It measures which pages are eligible to appear in search results and identifies technical issues preventing indexation.
Index coverage refers to the percentage and status of website pages that have been discovered, crawled, and included in a search engine's index. It measures which pages are eligible to appear in search results and identifies technical issues preventing indexation.
Index coverage is the measure of how many pages from your website have been discovered, crawled, and included in a search engine’s index. It represents the percentage of your site’s pages that are eligible to appear in search results and identifies which pages are experiencing technical issues that prevent indexation. In essence, index coverage answers the critical question: “How much of my website can search engines actually find and rank?” This metric is fundamental to understanding your website’s visibility in search engines and is tracked through tools like Google Search Console, which provides detailed reports on indexed pages, excluded pages, and pages with errors. Without proper index coverage, even the most optimized content remains invisible to both search engines and users searching for your information.
Index coverage is not simply about quantity—it’s about ensuring the right pages are indexed. A website might have thousands of pages, but if many of them are duplicates, thin content, or pages blocked by robots.txt, the actual index coverage could be significantly lower than expected. This distinction between total pages and indexed pages is critical for developing an effective SEO strategy. Organizations that monitor index coverage regularly can identify and fix technical issues before they impact organic traffic, making it one of the most actionable metrics in technical SEO.
The concept of index coverage emerged as search engines evolved from simple crawlers to sophisticated systems capable of processing millions of pages daily. In the early days of SEO, webmasters had limited visibility into how search engines interacted with their sites. Google Search Console, originally launched as Google Webmaster Tools in 2006, revolutionized this transparency by providing direct feedback on crawling and indexing status. The Index Coverage Report (formerly called the “Page Indexing” report) became the primary tool for understanding which pages Google had indexed and why others were excluded.
As websites grew more complex with dynamic content, parameters, and duplicate pages, index coverage issues became increasingly common. Research indicates that approximately 40-60% of websites have significant index coverage problems, with many pages remaining undiscovered or deliberately excluded from the index. The rise of JavaScript-heavy websites and single-page applications further complicated indexation, as search engines needed to render content before determining indexability. Today, index coverage monitoring is considered essential for any organization relying on organic search traffic, with industry experts recommending monthly audits at minimum.
The relationship between index coverage and crawl budget has become increasingly important as websites scale. Crawl budget refers to the number of pages Googlebot will crawl on your site within a given timeframe. Large websites with poor site architecture or excessive duplicate content can waste crawl budget on low-value pages, leaving important content undiscovered. Studies show that over 78% of enterprises use some form of content monitoring tools to track their visibility across search engines and AI platforms, recognizing that index coverage is foundational to any visibility strategy.
| Concept | Definition | Primary Control | Tools Used | Impact on Rankings |
|---|---|---|---|---|
| Index Coverage | Percentage of pages indexed by search engines | Meta tags, robots.txt, content quality | Google Search Console, Bing Webmaster Tools | Direct—only indexed pages can rank |
| Crawlability | Ability of bots to access and navigate pages | robots.txt, site structure, internal links | Screaming Frog, ZentroAudit, server logs | Indirect—pages must be crawlable to be indexed |
| Indexability | Ability of crawled pages to be added to index | Noindex directives, canonical tags, content | Google Search Console, URL Inspection Tool | Direct—determines if pages appear in results |
| Crawl Budget | Number of pages Googlebot crawls per timeframe | Site authority, page quality, crawl errors | Google Search Console, server logs | Indirect—affects which pages get crawled |
| Duplicate Content | Multiple pages with identical or similar content | Canonical tags, 301 redirects, noindex | SEO audit tools, manual review | Negative—dilutes ranking potential |
Index coverage operates through a three-stage process: discovery, crawling, and indexing. In the discovery phase, search engines find URLs through various means including XML sitemaps, internal links, external backlinks, and direct submissions via Google Search Console. Once discovered, URLs are queued for crawling, where Googlebot requests the page and analyzes its content. Finally, during indexing, Google processes the page’s content, determines its relevance and quality, and decides whether to include it in the searchable index.
The Index Coverage Report in Google Search Console categorizes pages into four primary statuses: Valid (indexed pages), Valid with warnings (indexed but with issues), Excluded (intentionally not indexed), and Error (pages that couldn’t be indexed). Within each status are specific issue types that provide granular insight into why pages are or aren’t indexed. For example, pages might be excluded because they contain a noindex meta tag, are blocked by robots.txt, are duplicates without proper canonical tags, or return 4xx or 5xx HTTP status codes.
Understanding the technical mechanisms behind index coverage requires knowledge of several key components. The robots.txt file is a text file in your site’s root directory that instructs search engine crawlers which directories and files they can or cannot access. Misconfiguring robots.txt is one of the most common causes of index coverage problems—accidentally blocking important directories prevents Google from even discovering those pages. The meta robots tag, placed in a page’s HTML head section, provides page-level instructions using directives like index, noindex, follow, and nofollow. The canonical tag (rel=“canonical”) tells search engines which version of a page is the preferred version when duplicates exist, preventing index bloat and consolidating ranking signals.
For businesses relying on organic search traffic, index coverage directly impacts revenue and visibility. When important pages aren’t indexed, they can’t appear in search results, meaning potential customers can’t find them through Google. E-commerce sites with poor index coverage might have product pages stuck in “Discovered – currently not indexed” status, resulting in lost sales. Content marketing platforms with thousands of articles need robust index coverage to ensure their content reaches audiences. SaaS companies depend on indexed documentation and blog posts to drive organic leads.
The practical implications extend beyond traditional search. With the rise of generative AI platforms like ChatGPT, Perplexity, and Google AI Overviews, index coverage has become relevant to AI visibility as well. These systems often rely on indexed web content for training data and citation sources. If your pages aren’t properly indexed by Google, they’re less likely to be included in AI training datasets or cited in AI-generated responses. This creates a compounding visibility problem: poor index coverage affects both traditional search rankings and AI-generated content visibility.
Organizations that proactively monitor index coverage see measurable improvements in organic traffic. A typical scenario involves discovering that 30-40% of submitted URLs are excluded due to noindex tags, duplicate content, or crawl errors. After remediation—removing unnecessary noindex tags, implementing proper canonicalization, and fixing crawl errors—indexed page counts often increase by 20-50%, directly correlating with improved organic visibility. The cost of inaction is significant: every month a page remains unindexed is a month of lost potential traffic and conversions.
Google Search Console remains the primary tool for monitoring index coverage, providing the most authoritative data on Google’s indexing decisions. The Index Coverage Report shows indexed pages, pages with warnings, excluded pages, and error pages, with detailed breakdowns of specific issue types. Google also provides the URL Inspection Tool, which allows you to check the indexing status of individual pages and request indexing for new or updated content. This tool is invaluable for troubleshooting specific pages and understanding why Google hasn’t indexed them.
Bing Webmaster Tools offers similar functionality through its Index Explorer and URL Submission features. While Bing’s market share is smaller than Google’s, it’s still important for reaching users who prefer Bing search. Bing’s index coverage data sometimes differs from Google’s, revealing issues specific to Bing’s crawling or indexing algorithms. Organizations managing large websites should monitor both platforms to ensure comprehensive coverage.
For AI monitoring and brand visibility, platforms like AmICited track how your brand and domain appear across ChatGPT, Perplexity, Google AI Overviews, and Claude. These platforms correlate traditional index coverage with AI visibility, helping organizations understand how their indexed content translates to mentions in AI-generated responses. This integration is crucial for modern SEO strategy, as visibility in AI systems increasingly influences brand awareness and traffic.
Third-party SEO audit tools like Ahrefs, SEMrush, and Screaming Frog provide additional index coverage insights by crawling your site independently and comparing their findings to Google’s reported index coverage. Discrepancies between your crawl and Google’s can reveal issues like JavaScript rendering problems, server-side issues, or crawl budget constraints. These tools also identify orphaned pages (pages with no internal links), which often struggle with index coverage.
Improving index coverage requires a systematic approach addressing both technical and strategic issues. First, audit your current state using Google Search Console’s Index Coverage Report. Identify the primary issue types affecting your site—whether they’re noindex tags, robots.txt blocks, duplicate content, or crawl errors. Prioritize issues by impact: pages that should be indexed but aren’t are higher priority than pages that are correctly excluded.
Second, fix robots.txt misconfigurations by reviewing your robots.txt file and ensuring you’re not accidentally blocking important directories. A common mistake is blocking /admin/, /staging/, or /temp/ directories that should be blocked, but also accidentally blocking /blog/, /products/, or other public content. Use Google Search Console’s robots.txt tester to verify that important pages aren’t blocked.
Third, implement proper canonicalization for duplicate content. If you have multiple URLs serving similar content (e.g., product pages accessible via different category paths), implement self-referencing canonical tags on each page or use 301 redirects to consolidate to a single version. This prevents index bloat and consolidates ranking signals on the preferred version.
Fourth, remove unnecessary noindex tags from pages you want indexed. Audit your site for noindex directives, particularly on staging environments that may have been accidentally deployed to production. Use the URL Inspection Tool to verify that important pages don’t have noindex tags.
Fifth, submit an XML sitemap to Google Search Console containing only indexable URLs. Keep your sitemap clean by excluding pages with noindex tags, redirects, or 404 errors. For large sites, consider splitting sitemaps by content type or section to maintain better organization and receive more granular error reporting.
Sixth, fix crawl errors including broken links (404s), server errors (5xx), and redirect chains. Use Google Search Console to identify affected pages, then systematically address each issue. For 404 errors on important pages, either restore the content or implement 301 redirects to relevant alternatives.
The future of index coverage is evolving alongside changes in search technology and the emergence of generative AI systems. As Google continues to refine its Core Web Vitals requirements and E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) standards, index coverage will increasingly depend on content quality and user experience metrics. Pages with poor Core Web Vitals or thin content may face indexation challenges even if technically crawlable.
The rise of AI-generated search results and answer engines is reshaping how index coverage matters. Traditional search rankings depend on indexed pages, but AI systems may cite indexed content differently or prioritize certain sources over others. Organizations will need to monitor not just whether pages are indexed by Google, but also whether they’re being cited and referenced by AI platforms. This dual-visibility requirement means index coverage monitoring must expand beyond Google Search Console to include AI monitoring platforms that track brand mentions across ChatGPT, Perplexity, and other generative AI systems.
JavaScript rendering and dynamic content will continue to complicate index coverage. As more websites adopt JavaScript frameworks and single-page applications, search engines must render JavaScript to understand page content. Google has improved its JavaScript rendering capabilities, but issues remain. Future best practices will likely emphasize server-side rendering or dynamic rendering to ensure content is immediately accessible to crawlers without requiring JavaScript execution.
The integration of structured data and schema markup will become increasingly important for index coverage. Search engines use structured data to better understand page content and context, potentially improving indexation decisions. Organizations implementing comprehensive schema markup for their content types—articles, products, events, FAQs—may see improved index coverage and enhanced visibility in rich results.
Finally, the concept of index coverage will expand beyond pages to include entities and topics. Rather than simply tracking whether pages are indexed, future monitoring will focus on whether your brand, products, and topics are properly represented in search engine knowledge graphs and AI training data. This represents a fundamental shift from page-level indexing to entity-level visibility, requiring new monitoring approaches and strategies.
+++
Crawlability refers to whether search engine bots can access and navigate your website pages, controlled by factors like robots.txt and site structure. Indexability, however, determines whether crawled pages are actually added to the search engine's index, controlled by meta robots tags, canonical tags, and content quality. A page must be crawlable to be indexable, but being crawlable doesn't guarantee indexation.
For most websites, checking index coverage monthly is sufficient to catch major issues. However, if you make significant changes to your site structure, publish new content regularly, or conduct migrations, monitor the report weekly or bi-weekly. Google sends email notifications about pressing issues, but these are often delayed, so proactive monitoring is essential for maintaining optimal visibility.
This status indicates that Google has found a URL (typically through sitemaps or internal links) but hasn't crawled it yet. This can occur due to crawl budget limitations, where Google prioritizes other pages on your site. If important pages remain in this status for extended periods, it may signal crawl budget issues or low site authority that needs addressing.
Yes, submitting an XML sitemap to Google Search Console helps search engines discover and prioritize your pages for crawling and indexing. A well-maintained sitemap containing only indexable URLs can significantly improve index coverage by directing Google's crawl budget toward your most important content and reducing the time needed for discovery.
Common issues include pages blocked by robots.txt, noindex meta tags on important pages, duplicate content without proper canonicalization, server errors (5xx), redirect chains, and thin content. Additionally, 404 errors, soft 404s, and pages with authorization requirements (401/403 errors) frequently appear in index coverage reports and require remediation to improve visibility.
Index coverage directly impacts whether your content appears in AI-generated responses from platforms like ChatGPT, Perplexity, and Google AI Overviews. If your pages aren't properly indexed by Google, they're less likely to be included in training data or cited by AI systems. Monitoring index coverage ensures your brand content is discoverable and citable across both traditional search and generative AI platforms.
Crawl budget is the number of pages Googlebot will crawl on your site within a given timeframe. Sites with poor crawl budget efficiency may have many pages stuck in 'Discovered – currently not indexed' status. Optimizing crawl budget by fixing crawl errors, removing duplicate URLs, and using robots.txt strategically ensures Google focuses on indexing your most valuable content.
No, not all pages should be indexed. Pages like staging environments, duplicate product variations, internal search results, and privacy policy archives are typically better excluded from the index using noindex tags or robots.txt. The goal is to index only high-value, unique content that serves user intent and contributes to your site's overall SEO performance.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Learn what AI Index Coverage is and why it matters for your brand's visibility in ChatGPT, Google AI Overviews, and Perplexity. Discover technical factors, best...

Indexability is the ability of search engines to include pages in their index. Learn how crawlability, technical factors, and content quality affect whether you...
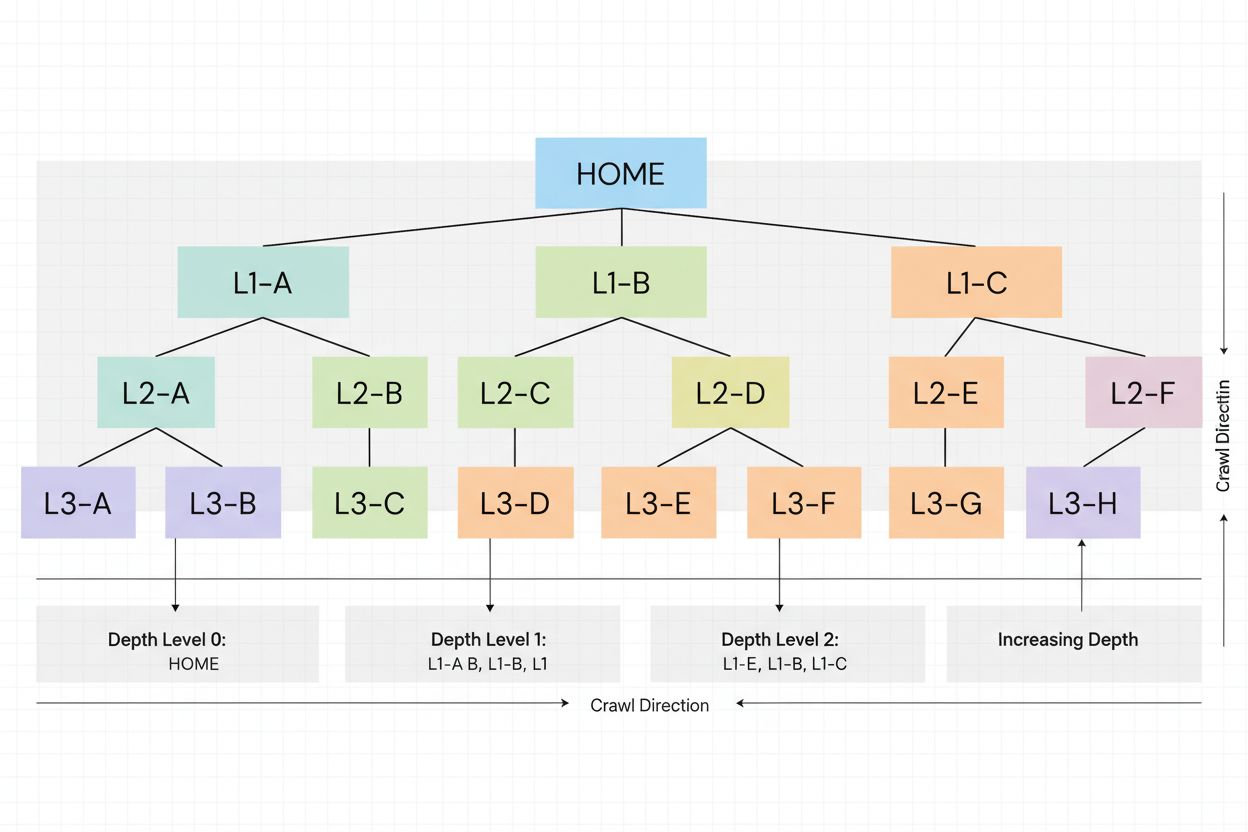
Crawl depth is how deep search engine bots navigate your site structure. Learn why it matters for SEO, how it affects indexation, and strategies to optimize cra...