
What is a Knowledge Graph and Why Does It Matter? | AI Monitoring FAQ
Discover what knowledge graphs are, how they work, and why they're essential for modern data management, AI applications, and business intelligence.
8 min read
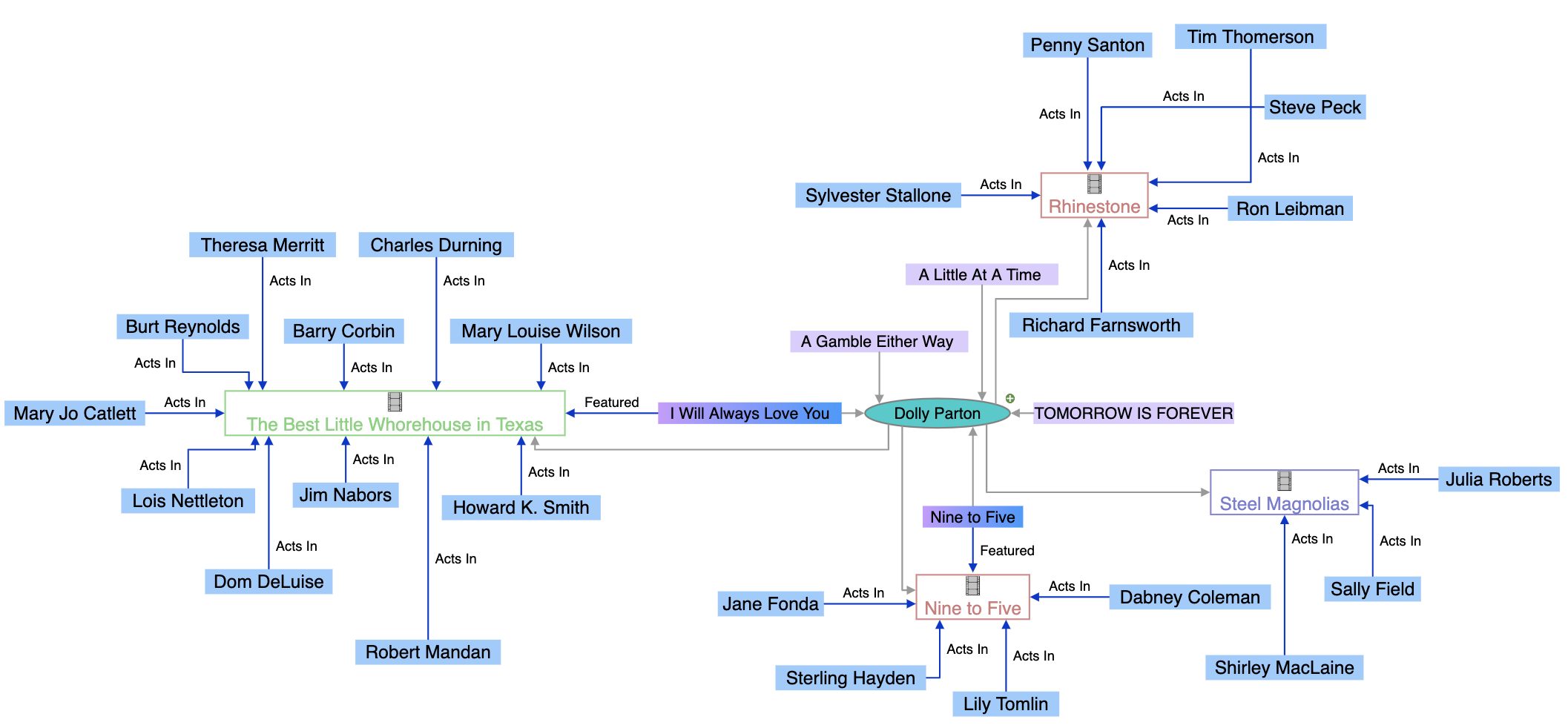
A knowledge graph is a database of interconnected information that represents real-world entities—such as people, places, organizations, and concepts—and illustrates the semantic relationships between them. Search engines like Google use knowledge graphs to understand user intent, deliver more relevant results, and power AI-driven features like knowledge panels and AI Overviews.
A knowledge graph is a database of interconnected information that represents real-world entities—such as people, places, organizations, and concepts—and illustrates the semantic relationships between them. Search engines like Google use knowledge graphs to understand user intent, deliver more relevant results, and power AI-driven features like knowledge panels and AI Overviews.
A knowledge graph is a database of interconnected information that represents real-world entities—such as people, places, organizations, and concepts—and illustrates the semantic relationships between them. Unlike traditional databases that organize information in rigid, tabular formats, knowledge graphs structure data as networks of nodes (entities) and edges (relationships), enabling systems to understand meaning and context rather than simply matching keywords. Google’s Knowledge Graph, launched in 2012, revolutionized search by introducing entity-based understanding, allowing the search engine to answer factual questions like “How tall is the Eiffel Tower?” or “Where were the 2016 Summer Olympics held?” by understanding what users are actually looking for, not just the words they use. As of May 2024, Google’s Knowledge Graph contains over 1.6 trillion facts about 54 billion entities, representing a massive expansion from 500 billion facts on 5 billion entities in 2020. This growth reflects the increasing importance of structured, semantic knowledge in powering modern search, AI systems, and intelligent applications across industries.
The concept of knowledge graphs emerged from decades of research in artificial intelligence, semantic web technologies, and knowledge representation. However, the term gained widespread recognition when Google introduced its Knowledge Graph in 2012, fundamentally changing how search engines deliver results. Before the Knowledge Graph, search engines primarily used keyword matching—if you searched for “seal,” Google would return results for all possible meanings of the word without understanding which entity you actually wanted to learn about. The Knowledge Graph changed this paradigm by applying principles of ontology—a formal framework for defining entities, their attributes, and relationships—at massive scale. This shift from “strings to things” represented a fundamental advancement in search technology, enabling algorithms to understand that “seal” could refer to a marine mammal, a recording artist, a military unit, or a security device, and to determine which meaning was most relevant based on context. The global knowledge graph market reflects this importance, with projections showing growth from $1.49 billion in 2024 to $6.94 billion by 2030, representing a compound annual growth rate of approximately 35%. This explosive growth is driven by enterprise adoption across finance, healthcare, retail, and supply chain management, where organizations increasingly recognize that understanding entity relationships is critical for decision-making, fraud detection, and operational efficiency.
Knowledge graphs operate through a sophisticated combination of data structures, semantic technologies, and machine learning algorithms. At their core, knowledge graphs use a graph-structured data model consisting of three fundamental components: nodes (representing entities like people, organizations, or concepts), edges (representing relationships between entities), and labels (describing the nature of those relationships). For example, in a simple knowledge graph, “Seal” might be a node, “is-a” might be an edge label, and “Recording Artist” might be another node, creating the semantic relationship “Seal is-a Recording Artist.” This structure is fundamentally different from relational databases, which force data into rows and columns with predefined schemas. Knowledge graphs are built using either labeled property graphs (which store properties directly on nodes and edges) or RDF (Resource Description Framework) triple stores (which represent all information as subject-predicate-object triples). The power of knowledge graphs emerges from their ability to integrate data from multiple sources with different structures and formats. When data is ingested into a knowledge graph, semantic enrichment processes use natural language processing (NLP) and machine learning to identify entities, extract relationships, and understand context. This allows knowledge graphs to automatically recognize that “IBM,” “International Business Machines,” and “Big Blue” all refer to the same entity, and to understand how that entity relates to other entities like “Watson,” “Cloud Computing,” and “Artificial Intelligence.” The resulting interconnected structure enables sophisticated queries and reasoning that would be impossible in traditional databases, allowing systems to answer complex questions by traversing relationships and inferring new knowledge from existing connections.
| Aspect | Knowledge Graph | Traditional Relational Database | Graph Database |
|---|---|---|---|
| Data Structure | Nodes, edges, and labels representing entities and relationships | Tables, rows, and columns with predefined schemas | Nodes and edges optimized for relationship traversal |
| Schema Flexibility | Highly flexible; evolves as new information is discovered | Rigid; requires schema definition before data entry | Flexible; supports dynamic schema evolution |
| Relationship Handling | Native support for complex, multi-hop relationships | Requires joins across multiple tables; computationally expensive | Optimized for efficient relationship queries |
| Query Language | SPARQL (for RDF), Cypher (for property graphs), or custom APIs | SQL | Cypher, Gremlin, or SPARQL |
| Semantic Understanding | Emphasizes meaning and context through ontologies | Focuses on data storage and retrieval | Focuses on efficient traversal and pattern matching |
| Use Cases | Semantic search, knowledge discovery, AI systems, entity resolution | Business transactions, reporting, OLTP systems | Recommendation engines, fraud detection, network analysis |
| Data Integration | Excels at integrating heterogeneous data from multiple sources | Requires significant ETL and data transformation | Good for connected data but less semantic focus |
| Scalability | Scales to billions of entities and trillions of facts | Scales well for structured, transactional data | Scales well for relationship-heavy queries |
| Inference Capabilities | Advanced reasoning and knowledge derivation through ontologies | Limited; requires explicit programming | Limited; focuses on pattern matching |
Knowledge graphs have become central to modern SEO and AI visibility strategies because they fundamentally determine how information appears in search results and AI-generated responses. When Google processes a search query, one of its primary tasks is identifying the entity the user is searching for, then retrieving relevant information from the Knowledge Graph to populate SERP features. This entity-based approach has led to the emergence of semantic search—Google’s ability to understand the meaning and context of queries rather than just matching keywords. The Knowledge Graph powers multiple high-visibility SERP features that directly impact click-through rates and brand visibility. Knowledge panels appear prominently on desktop and mobile results, displaying curated facts about the searched entity sourced from the Knowledge Graph. AI Overviews (formerly Search Generative Experience) synthesize information from multiple sources identified through Knowledge Graph relationships, providing comprehensive answers that often push traditional organic listings further down the page. People Also Ask boxes leverage entity relationships to suggest related searches and topics. Understanding these features is critical for brands because they represent prime real estate in search results, often appearing above traditional organic listings. For organizations monitoring their presence in AI systems like Perplexity, ChatGPT, Claude, and Google AI Overviews, knowledge graph optimization becomes essential. These AI systems increasingly rely on structured entity information and semantic relationships to generate accurate, contextual responses. A brand that has properly optimized its entity presence in knowledge graphs—through structured data markup, claimed knowledge panels, and consistent information across sources—is more likely to appear in AI-generated responses about relevant topics. Conversely, brands with incomplete or inconsistent entity information may be overlooked or misrepresented in AI systems, directly impacting their visibility and reputation.
Google’s Knowledge Graph draws from a diverse ecosystem of data sources, each contributing different types of information and serving different purposes. Open data and community projects like Wikipedia and Wikidata form the foundation of much Knowledge Graph content. Wikipedia provides narrative descriptions and summary information that often appear in knowledge panels, while Wikidata—a structured knowledge base supporting Wikipedia—provides machine-readable entity data and relationships. Google previously used Freebase, its own community-edited database, but transitioned to Wikidata after shutting down Freebase in 2016. Government data sources contribute authoritative information, particularly for factual queries. The CIA World Factbook provides information about countries, geographical areas, and organizations. Data Commons, Google’s structured public data project, aggregates data from governmental and multi-governmental organizations like the United Nations and European Union, providing statistics and demographic information. Weather and air quality data come from national and international meteorological agencies, enabling Google’s “nowcast” weather features. Licensed private data supplements the Knowledge Graph with information that changes frequently or requires specialized expertise. Google licenses financial market data from providers like Morningstar, S&P Global, and Intercontinental Exchange to power stock price and market information features. Sports data comes from partnerships with leagues, teams, and aggregators like Stats Perform, providing real-time scores and historical statistics. Structured data from websites contributes significantly to Knowledge Graph enrichment. When websites implement Schema.org markup, they provide explicit semantic information that Google can extract and incorporate. This is why implementing proper structured data—Organization schema, LocalBusiness schema, FAQPage schema, and other relevant markup—is critical for brands wanting to influence their Knowledge Graph representation. Google Books data from over 40 million scanned and digitized books provides historical context, biographical information, and detailed descriptions that enhance entity knowledge. User feedback and claimed knowledge panels allow individuals and organizations to directly influence Knowledge Graph information. When users submit feedback about knowledge panels or when authorized representatives claim and update panels, this information is processed and can lead to Knowledge Graph updates. This human-in-the-loop approach ensures that the Knowledge Graph remains accurate and representative, though Google’s automated systems make the final determination about what information appears.
Google has explicitly stated that it prioritizes information from sources demonstrating high E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) when building and updating the Knowledge Graph. This connection between E-E-A-T and Knowledge Graph inclusion is not coincidental—it reflects Google’s broader commitment to surfacing reliable, authoritative information. If your website’s content is being pulled into SERP features powered by the Knowledge Graph, it’s often a strong signal that Google recognizes your site as authoritative on that topic. Conversely, if your content isn’t appearing in Knowledge Graph-powered features, it may indicate E-E-A-T issues that need addressing. Building E-E-A-T for Knowledge Graph visibility requires a multifaceted approach. Experience means demonstrating that you or your contributors have real-world experience with the topic. For a healthcare website, this might mean featuring content from licensed medical professionals with years of clinical experience. For a technology company, it means showcasing the expertise of engineers and researchers who have built the products you’re discussing. Expertise involves creating deeply knowledgeable content that covers topics comprehensively and accurately. This goes beyond surface-level explanations to demonstrate genuine understanding of nuances, edge cases, and advanced concepts. Authoritativeness requires building recognition within your field. This can come from awards, certifications, media mentions, speaking engagements, and being cited by other authoritative sources. For organizations, it means establishing your brand as a recognized leader in your industry. Trustworthiness builds on the other three elements and is demonstrated through transparency, accuracy, proper citations, clear authorship, and responsive customer service. Organizations that excel at E-E-A-T signals are more likely to have their information included in the Knowledge Graph and to appear in AI-generated responses, creating a virtuous cycle where authority leads to visibility, which further reinforces authority.
The emergence of large language models (LLMs) and generative AI has created new importance for knowledge graphs in the AI ecosystem. While LLMs like ChatGPT, Claude, and Perplexity are not directly trained on Google’s proprietary Knowledge Graph, they increasingly rely on similar structured knowledge and semantic understanding. Many AI systems employ retrieval-augmented generation (RAG) approaches, where the model queries knowledge graphs or structured databases at inference time to ground responses in factual information and reduce hallucinations. Publicly available knowledge graphs like Wikidata are used to fine-tune models or inject structured knowledge, improving their ability to understand entity relationships and provide accurate information. For brands and organizations, this means that knowledge graph optimization has implications beyond traditional Google Search. When users query AI systems about your industry, products, or organization, the AI system’s ability to provide accurate information depends partly on how well your entity is represented in structured knowledge sources. An organization with a well-maintained Wikidata entry, claimed Google knowledge panel, and consistent structured data across its website is more likely to be accurately represented in AI-generated responses. Conversely, organizations with incomplete or conflicting information across sources may find themselves misrepresented or overlooked in AI responses. This creates a new dimension of AI visibility monitoring—tracking not just how your brand appears in traditional search results, but how it’s represented in AI-generated responses across multiple platforms. Tools and platforms that monitor brand presence in AI systems increasingly focus on understanding entity relationships and knowledge graph representation, recognizing that these factors directly influence AI visibility.
Organizations seeking to optimize their presence in knowledge graphs should follow a systematic approach that builds on SEO fundamentals while adding entity-specific strategies. The first step is implementing structured data markup using Schema.org vocabulary. This means adding JSON-LD, Microdata, or RDFa markup to your website that explicitly describes your organization, products, people, and other relevant entities. Key schema types include Organization (for company information), LocalBusiness (for location-specific information), Person (for individual profiles), Product (for product information), and FAQPage (for frequently asked questions). After implementing schema, it’s essential to test and validate your markup using Google’s Structured Data Testing Tool to ensure it’s correctly formatted and recognized. The second step involves auditing and optimizing Wikidata and Wikipedia information. If your organization or key entities have Wikipedia pages, ensure they’re accurate, comprehensive, and properly sourced. For Wikidata, verify that your entity exists and that its properties and relationships are correctly represented. However, editing Wikipedia or Wikidata requires careful attention to their policies and community norms—direct self-promotion or undisclosed conflicts of interest can result in edits being reverted and damage to your reputation. The third step is claiming and optimizing your Google Business Profile (for local businesses) and knowledge panels (for people and organizations). A claimed knowledge panel gives you greater control over how your entity appears in search results and allows you to suggest edits more quickly. The fourth step involves ensuring consistency across all properties—your website, Google Business Profile, social media profiles, and third-party business directories. Conflicting information across sources confuses Google’s systems and can prevent accurate Knowledge Graph representation. The fifth step is creating entity-focused content rather than traditional keyword-focused content. Instead of writing articles around keywords, organize your content strategy around entities and their relationships. For example, instead of writing separate articles about “best CRM software,” “Salesforce features,” and “HubSpot pricing,” create a comprehensive content cluster that establishes clear entity relationships: Salesforce is a CRM platform, it competes with HubSpot, it integrates with Slack, etc. This entity-based approach helps knowledge graphs understand your content’s semantic meaning and relationships.
Knowledge graphs are evolving rapidly in response to advances in artificial intelligence, changes in search behavior, and the emergence of new platforms and technologies. One significant trend is the expansion of multimodal knowledge graphs that integrate text, images, audio, and video data. As voice search and visual search become more prevalent, knowledge graphs are adapting to understand and represent information across multiple modalities. Google’s work on multimodal search with products like Google Lens demonstrates this evolution—the system must understand not just text queries but also visual inputs, requiring knowledge graphs that can represent and connect information across different media types. Another important development is the increasing sophistication of semantic enrichment and natural language processing in knowledge graph construction. As NLP capabilities improve, knowledge graphs can extract more nuanced semantic relationships from unstructured text, reducing the reliance on manually curated or explicitly marked-up data. This means that organizations with high-quality, well-written content may see their information incorporated into knowledge graphs even without explicit structured data markup, though markup remains important for ensuring accurate representation. The integration of knowledge graphs with large language models and generative AI represents perhaps the most significant evolution. As AI systems become more central to how people discover information, the importance of knowledge graph optimization extends beyond traditional search to encompass AI visibility across multiple platforms. Organizations that understand and optimize for knowledge graphs will have advantages in both traditional search and AI-generated responses. Additionally, the rise of enterprise knowledge graphs reflects growing recognition that knowledge graph principles apply beyond public search to internal organizational knowledge management. Companies are building internal knowledge graphs to break down data silos, improve decision-making, and enable better AI applications. This trend suggests that knowledge graph literacy will become increasingly important for business leaders, data scientists, and marketing professionals. Finally, the regulatory and ethical dimensions of knowledge graphs are becoming more prominent. As knowledge graphs influence how information is presented to billions of users, questions about accuracy, bias, representation, and who controls knowledge graph information are receiving greater attention. Organizations should be aware that their entity representation in knowledge graphs has real consequences for their visibility, reputation, and business outcomes, and should approach knowledge graph optimization with the same rigor and ethics they apply to other aspects of their digital presence.
A traditional database stores data in rigid, tabular formats with predefined schemas, while a knowledge graph organizes information as interconnected nodes and edges that represent entities and their semantic relationships. Knowledge graphs are more flexible, self-describing, and better suited for understanding complex relationships between diverse data types. They enable systems to understand meaning and context, not just match keywords, making them ideal for AI and semantic search applications.
Google uses its Knowledge Graph to power multiple SERP features including knowledge panels, AI Overviews, People Also Ask boxes, and related entity suggestions. As of May 2024, Google's Knowledge Graph contains over 1.6 trillion facts about 54 billion entities. When a user searches, Google identifies the entity they're looking for and displays relevant, interconnected information from the Knowledge Graph, helping users find 'things, not strings' as Google describes it.
Knowledge graphs aggregate data from multiple sources including open-source projects like Wikipedia and Wikidata, government databases like the CIA World Factbook, licensed private data for financial and sports information, structured data markup from websites using Schema.org, Google Books data, and user feedback through knowledge panel corrections. This multi-source approach ensures comprehensive and accurate entity information across billions of facts.
Knowledge graphs directly influence how brands appear across search results and AI systems by establishing entity relationships and connections. Brands that optimize their entity presence through structured data, claimed knowledge panels, and consistent information across sources gain better visibility in AI-generated responses. Understanding knowledge graph relationships helps brands monitor their presence in AI systems like ChatGPT, Perplexity, and Claude, which increasingly rely on structured entity information.
Semantic enrichment is the process where machine learning and natural language processing (NLP) algorithms analyze data to identify individual objects and understand relationships between them. This process allows knowledge graphs to move beyond simple keyword matching to comprehend meaning and context. When data is ingested, semantic enrichment automatically recognizes entities, their attributes, and how they relate to other entities, enabling more intelligent search and question-answering capabilities.
Organizations can optimize for knowledge graphs by implementing structured data markup using Schema.org, maintaining consistent information across all properties (website, Google Business Profile, social media), claiming and updating knowledge panels, building high E-E-A-T signals through authoritative content, and ensuring data accuracy across sources. Creating entity-focused content clusters rather than traditional keyword clusters also helps establish stronger entity relationships that knowledge graphs can recognize and leverage.
Knowledge graphs provide the semantic foundation for AI Overviews by helping AI systems understand entity relationships and context. When generating search summaries, AI systems use knowledge graph data to identify relevant entities, understand their connections, and synthesize information from multiple sources. This enables more accurate, contextual responses that go beyond simple keyword matching, making knowledge graphs essential infrastructure for modern generative search experiences.
A knowledge graph is a design pattern and semantic layer that defines how entities and relationships are modeled and understood, while a graph database is the technological infrastructure used to store and query that data. Knowledge graphs focus on meaning and semantic relationships, while graph databases focus on efficient storage and retrieval. A knowledge graph can be implemented using various graph databases like Neo4j, Amazon Neptune, or RDF triple stores, but the knowledge graph itself is the conceptual model.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Discover what knowledge graphs are, how they work, and why they're essential for modern data management, AI applications, and business intelligence.
Community discussion explaining Knowledge Graphs and their importance for AI search visibility. Experts share how entities and relationships affect AI citations...
Learn what a graph is in data visualization. Discover how graphs display relationships between data using nodes and edges, and why they're essential for underst...