
What is MUM and how does it affect AI search?
Learn about Google's Multitask Unified Model (MUM) and its impact on AI search results. Understand how MUM processes complex queries across multiple formats and...
8 min read
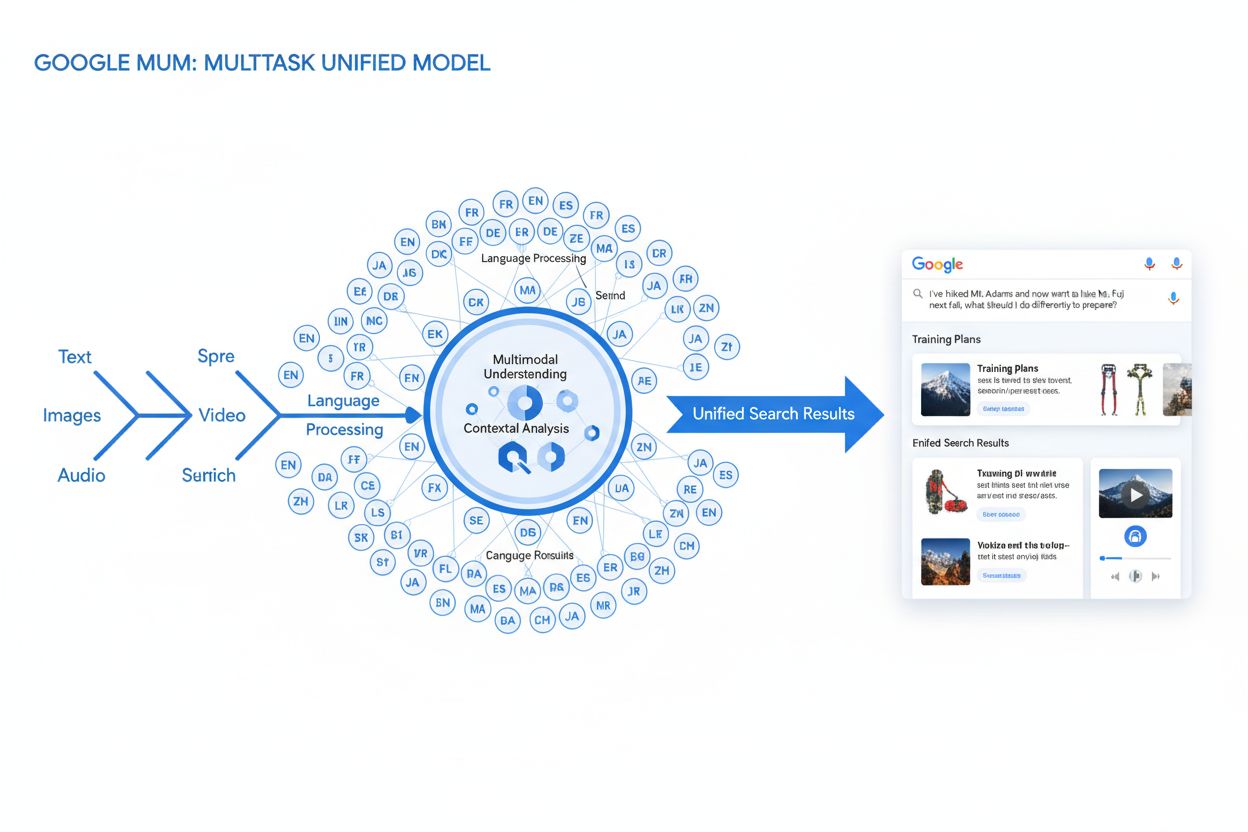
MUM (Multitask Unified Model) is Google’s advanced multimodal AI model that processes text, images, video, and audio simultaneously across 75+ languages to deliver more comprehensive, contextual search results. Launched in 2021, MUM is 1,000 times more powerful than BERT and represents a fundamental shift in how search engines understand and respond to complex user queries.
MUM (Multitask Unified Model) is Google's advanced multimodal AI model that processes text, images, video, and audio simultaneously across 75+ languages to deliver more comprehensive, contextual search results. Launched in 2021, MUM is 1,000 times more powerful than BERT and represents a fundamental shift in how search engines understand and respond to complex user queries.
MUM (Multitask Unified Model) is Google’s advanced multimodal artificial intelligence model designed to revolutionize how search engines understand and respond to complex user queries. Announced in May 2021 by Pandu Nayak, Google Fellow and Vice President of Search, MUM represents a fundamental shift in information retrieval technology. Built on the T5 text-to-text framework and comprising approximately 110 billion parameters, MUM is 1,000 times more powerful than BERT, Google’s previous breakthrough natural language processing model. Unlike traditional search algorithms that process text in isolation, MUM simultaneously processes text, images, video, and audio while understanding information across 75+ languages natively. This multimodal and multilingual capability enables MUM to comprehend complex queries that previously required users to conduct multiple searches, transforming search from a simple keyword-matching exercise into an intelligent, context-aware information retrieval system. MUM not only understands language but also generates it, making it capable of synthesizing information from diverse sources and formats to provide comprehensive, nuanced answers that address the full scope of user intent.
Google’s journey toward MUM represents years of incremental innovation in natural language processing and machine learning. The evolution began with Hummingbird (2013), which introduced semantic understanding to interpret the meaning behind search queries rather than just matching keywords. This was followed by RankBrain (2015), which used machine learning to understand long-tail keywords and novel search patterns. Neural Matching (2018) advanced this further by using neural networks to match queries with relevant content at a deeper semantic level. BERT (Bidirectional Encoder Representations from Transformers), launched in 2019, marked a major milestone by understanding context within sentences and paragraphs, improving Google’s ability to interpret nuanced language. However, BERT had significant limitations—it processed only text, had limited multilingual support, and couldn’t handle the complexity of queries requiring information synthesis across multiple formats. According to Google’s research, users issue an average of eight separate queries to answer complex questions, such as comparing two hiking destinations or evaluating product options. This statistic highlighted a critical gap in search technology that MUM was specifically designed to address. The Helpful Content Update (2022) and E-E-A-T framework (2023) further refined how Google prioritizes authoritative, trustworthy content. MUM builds upon all these innovations while introducing capabilities that transcend previous limitations, representing not just an incremental improvement but a paradigm shift in how search engines process and deliver information.
MUM’s technical foundation rests on the Transformer architecture, specifically the T5 (Text-to-Text Transfer Transformer) framework that Google developed earlier. The T5 framework treats all natural language processing tasks as text-to-text problems, converting inputs and outputs into unified text representations. MUM extends this approach by incorporating multimodal processing capabilities, enabling it to handle text, images, video, and audio simultaneously within a single unified model. This architectural choice is significant because it allows MUM to understand relationships and context across different media types in ways that previous models could not. For instance, when processing a query about hiking Mt. Fuji combined with an image of specific hiking boots, MUM doesn’t analyze the text and image separately—it processes them together, understanding how the boot’s characteristics relate to the query’s context. The model’s 110 billion parameters provide it with the capacity to store and process vast amounts of knowledge about language, visual concepts, and their relationships. MUM is trained across 75 different languages and many different tasks simultaneously, which enables it to develop a more comprehensive understanding of information and world knowledge than models trained on single languages or tasks. This multitask learning approach means MUM learns to recognize patterns and relationships that transfer across languages and domains, making it more robust and generalizable than previous models. The simultaneous processing of multiple languages during training allows MUM to perform knowledge transfer across languages, meaning it can understand information written in one language and apply that understanding to queries in another language, effectively breaking down language barriers that previously limited search results.
| Attribute | MUM (2021) | BERT (2019) | RankBrain (2015) | T5 Framework |
|---|---|---|---|---|
| Primary Function | Multimodal query understanding and answer synthesis | Text-based contextual understanding | Long-tail keyword interpretation | Text-to-text transfer learning |
| Input Modalities | Text, images, video, audio | Text only | Text only | Text only |
| Language Support | 75+ languages natively | Limited multilingual support | Primarily English | Primarily English |
| Model Parameters | ~110 billion | ~340 million | Not disclosed | ~220 million |
| Power Comparison | 1,000x more powerful than BERT | Baseline | Predecessor to BERT | Foundation for MUM |
| Capabilities | Understanding + generation | Understanding only | Pattern recognition | Text transformation |
| SERP Impact | Multiformat enriched results | Better snippets and context | Improved relevance | Foundational technology |
| Query Complexity Handling | Complex multi-step queries | Single-query context | Long-tail variations | Text transformation tasks |
| Knowledge Transfer | Cross-language and cross-modal | Within-language only | Limited transfer | Cross-task transfer |
| Real-World Application | Google Search, AI Overviews | Google Search ranking | Google Search ranking | MUM’s technical foundation |
MUM’s query processing involves multiple sophisticated steps that work together to deliver comprehensive, contextual answers. When a user submits a search query, MUM begins by performing language-agnostic pre-processing, understanding the query in any of its 75+ supported languages without requiring translation. This native language understanding preserves linguistic nuance and regional context that might be lost in translation. Next, MUM employs sequence-to-sequence matching, analyzing the entire query as a sequence of meaning rather than isolated keywords. This approach allows MUM to understand relationships between concepts—for example, recognizing that a query about “preparing for Mt. Fuji after climbing Mt. Adams” involves comparison, preparation, and contextual adaptation. Simultaneously, MUM performs multimodal input analysis, processing any images, videos, or other media included with the query. The model then engages in simultaneous query processing, evaluating multiple possible user intents in parallel rather than narrowing to a single interpretation. This means MUM might recognize that a query about hiking Mt. Fuji could relate to physical preparation, gear selection, cultural experiences, or travel logistics—and it surfaces relevant information for all these interpretations. Vector-based semantic understanding converts the query and indexed content into high-dimensional vectors representing semantic meaning, enabling retrieval based on conceptual similarity rather than keyword matching. MUM then applies content filtering via knowledge transfer, using machine learning trained on search logs, browsing data, and user behavior patterns to prioritize high-quality, authoritative sources. Finally, MUM generates a multimedia enriched SERP composition, combining text snippets, images, videos, related questions, and interactive elements into a single, visually layered search experience. This entire process happens in milliseconds, enabling MUM to deliver results that address not just the explicit query but also anticipated follow-up questions and related information needs.
MUM’s multimodal capabilities represent a fundamental departure from text-only search systems. The model can simultaneously process and understand information from text, images, video, and audio, extracting meaning from each modality and synthesizing it into coherent answers. This capability is particularly powerful for queries that benefit from visual context. For example, if a user asks “Can I use these hiking boots for Mt. Fuji?” while showing an image of their boots, MUM understands the boot’s characteristics from the image—material, tread pattern, height, color—and connects that visual understanding with knowledge about Mt. Fuji’s terrain, climate, and hiking requirements to provide a contextual answer. The multilingual dimension of MUM is equally transformative. With native support for 75+ languages, MUM can perform knowledge transfer across languages, meaning it learns from sources in one language and applies that knowledge to queries in another. This breaks down a significant barrier that previously limited search results to content in the user’s native language. If comprehensive information about Mt. Fuji exists primarily in Japanese sources—including local hiking guides, seasonal weather patterns, and cultural insights—MUM can understand this Japanese-language content and surface relevant information to English-speaking users. According to Google’s testing, MUM was able to list 800 variations of COVID-19 vaccines in more than 50 languages within seconds, demonstrating the scale and speed of its multilingual processing capabilities. This multilingual understanding is particularly valuable for users in non-English speaking markets and for queries about topics with rich information in multiple languages. The combination of multimodal and multilingual processing means MUM can surface the most relevant information regardless of the format it’s presented in or the language it was originally published in, creating a truly global search experience.
MUM fundamentally transforms how search results are displayed and experienced by users. Rather than the traditional list of blue links that dominated search for decades, MUM creates enriched, interactive SERPs that combine multiple content formats on a single page. Users can now see text snippets, high-resolution images, video carousels, related questions, and interactive elements all without leaving the search results page. This shift has profound implications for how users interact with search. Instead of conducting multiple searches to gather information about a complex topic, users can explore different angles and subtopics directly within the SERP. For instance, a query about “preparing for Mt. Fuji in fall” might surface elevation comparisons, weather forecasts, gear recommendations, video guides, and user reviews—all organized contextually on one page. Google Lens integration powered by MUM allows users to search using images instead of keywords, turning visual elements within photos into interactive discovery tools. “Things to Know” panels break down complex queries into digestible subtopics, guiding users through different aspects of a topic with relevant snippets for each. Zoomable, high-resolution images appear directly in search results, enabling visual comparison and reducing friction in early decision-making stages. The “Refine and Broaden” functionality suggests related concepts to help users either dig deeper into specific aspects or explore adjacent topics. These changes represent a shift from search as a simple retrieval mechanism to search as an interactive, exploratory experience that anticipates user needs and provides comprehensive information within the search interface itself. Research indicates that this richer SERP experience reduces the average number of searches needed to answer complex questions, though it also means users may consume information directly in search results rather than clicking through to websites.
For organizations tracking their presence across AI systems, MUM represents a critical evolution in how information is discovered and surfaced. As MUM becomes increasingly integrated into Google Search and influences other AI systems, understanding how brands and domains appear in MUM-powered results becomes essential for maintaining visibility. MUM’s multimodal processing means brands must optimize across multiple content formats, not just text. A brand that previously relied on ranking for specific keywords now needs to ensure its content is discoverable through images, videos, and structured data. The model’s ability to synthesize information from diverse sources means a brand’s visibility depends not just on its own website but on how its information appears across the broader web ecosystem. MUM’s multilingual capabilities create new opportunities and challenges for global brands. Content published in one language can now be discovered by users searching in different languages, expanding potential reach. However, this also means brands must ensure their information is accurate and consistent across languages, as MUM may surface information from multiple language sources for a single query. For AI monitoring platforms like AmICited, tracking MUM’s impact is crucial because it represents how modern AI systems retrieve and present information. When monitoring where a brand appears in AI responses—whether in Google AI Overviews, Perplexity, ChatGPT, or Claude—understanding MUM’s underlying technology helps explain why certain content is surfaced and how to optimize for visibility. The shift toward multimodal, multilingual search means brands need comprehensive monitoring that tracks their presence across different content formats and languages, not just traditional keyword rankings. Organizations that understand MUM’s capabilities can better optimize their content strategy to ensure visibility in this new search landscape.
While MUM represents a significant advancement, it also introduces new challenges and limitations that organizations must navigate. Lower click-through rates represent a major concern for publishers and content creators, as users can now consume comprehensive information directly within search results without clicking through to websites. This shift means traditional traffic metrics become less reliable indicators of content success. Increased technical SEO requirements mean that to be properly understood by MUM, content must be well-structured with appropriate schema markup, semantic HTML, and clear entity relationships. Content that lacks this technical foundation may not be properly indexed or understood by MUM’s multimodal processing. SERP saturation creates challenges for visibility, as more content formats compete for attention on a single page. Even strong content may earn fewer or zero clicks if users find sufficient information within the SERP itself. Potential for misleading results exists when MUM surfaces information from multiple sources that may contradict each other or when context is lost in synthesis. Dependency on structured data means that unstructured or poorly formatted content may not be properly understood or surfaced by MUM. Language and cultural nuance challenges can arise when MUM transfers knowledge across languages, potentially missing cultural context or regional variations in meaning. Computational resource requirements for running MUM at scale are substantial, though Google has invested in efficiency improvements to reduce carbon footprint. Bias and fairness concerns require ongoing attention to ensure MUM doesn’t perpetuate biases present in training data or disadvantage certain perspectives or communities.
The emergence of MUM requires fundamental changes to how organizations approach SEO and content strategy. Traditional keyword-focused optimization becomes less effective when MUM can understand intent and context beyond exact keyword matches. Topic-based content strategy becomes more important than keyword-based strategy, with organizations needing to create comprehensive content clusters that address topics from multiple angles. Multimedia content creation is no longer optional—organizations must invest in creating high-quality images, videos, and interactive content that complements text-based content. Structured data implementation becomes critical, as schema markup helps MUM understand content structure and relationships. Entity building and semantic optimization help establish topical authority and improve how MUM understands content relationships. Multilingual content strategy gains importance as MUM’s language transfer capabilities mean content can be discovered across language markets. User intent mapping becomes more sophisticated, requiring organizations to understand not just primary intent but also related questions and subtopics users might explore. Content freshness and accuracy become more important as MUM synthesizes information from multiple sources—outdated or inaccurate content may be deprioritized. Cross-platform optimization extends beyond Google Search to include optimization for how content appears in AI systems like Google AI Overviews, Perplexity, and other AI-powered search interfaces. E-E-A-T signals (Experience, Expertise, Authoritativeness, Trustworthiness) become increasingly important as MUM prioritizes content from authoritative sources. Organizations that adapt their strategies to align with MUM’s capabilities—focusing on comprehensive, multimodal, well-structured content that demonstrates expertise and authority—will maintain visibility in this evolving search landscape.
MUM represents not a final destination but a waypoint in the evolution of AI-powered search. Google has indicated that MUM will continue to expand its capabilities, with video and audio processing becoming increasingly sophisticated. The company is actively researching how to reduce MUM’s computational footprint while maintaining or improving performance, addressing sustainability concerns around large-scale AI models. The integration of MUM with other Google technologies suggests future developments where MUM’s understanding powers not just search but also Google Assistant, Google Lens, and other products. Competitive pressure from other AI systems like OpenAI’s ChatGPT, Anthropic’s Claude, and Perplexity’s AI search engine means MUM will likely continue evolving to maintain Google’s competitive advantage. Regulatory scrutiny around AI systems may influence how MUM develops, particularly regarding bias, fairness, and transparency. User behavior adaptation will shape how MUM evolves—as users become accustomed to richer, more interactive search experiences, expectations for search quality and comprehensiveness will increase. The rise of generative AI means MUM’s capabilities for synthesizing and generating information will likely become more prominent, potentially enabling MUM to generate original content rather than just retrieving and organizing existing content. Multimodal AI becoming standard suggests that MUM’s approach of processing multiple formats simultaneously will become the norm rather than the exception across AI systems. Privacy and data considerations will influence how MUM uses user data and behavioral signals to personalize and improve results. Organizations should prepare for continued evolution by building flexible, adaptable content strategies that prioritize quality, comprehensiveness, and technical excellence rather than relying on specific tactics that may become obsolete as MUM evolves. The fundamental principle—creating content that genuinely serves user intent across multiple formats and languages—will remain relevant regardless of how MUM’s specific capabilities develop.
While BERT (2019) focused on understanding natural language within text-based queries, MUM represents a significant evolution. MUM is built on the T5 text-to-text framework and is 1,000 times more powerful than BERT. Unlike BERT's text-only processing, MUM is multimodal—it simultaneously processes text, images, video, and audio. Additionally, MUM supports 75+ languages natively, whereas BERT had limited multilingual support at launch. MUM can both understand and generate language, making it capable of handling complex, multi-step queries that BERT could not effectively address.
Multimodal refers to MUM's ability to process and understand information from multiple types of input formats simultaneously. Rather than analyzing text separately from images or video, MUM processes all these formats together in a unified way. This means when you search for something like 'hiking boots for Mt. Fuji,' MUM can understand your text query, analyze images of boots, watch video reviews, and extract audio descriptions—all at the same time. This integrated approach allows MUM to provide richer, more contextual answers that consider information across all these different media types.
MUM is trained across 75+ languages, which is a major advancement in global search accessibility. This multilingual capability means MUM can transfer knowledge across languages—if helpful information about a topic exists in Japanese, MUM can understand it and surface relevant results to English-speaking users. This breaks down language barriers that previously limited search results to content in the user's native language. For brands and content creators, this means their content has potential visibility across multiple language markets, and users worldwide can access information regardless of the language it was originally published in.
T5 (Text-to-Text Transfer Transformer) is Google's earlier transformer-based model that MUM is built upon. The T5 framework treats all NLP tasks as text-to-text problems, meaning it converts inputs and outputs into text format for unified processing. MUM extends T5's capabilities by incorporating multimodal processing (handling images, video, and audio) and scaling it to approximately 110 billion parameters. This foundation allows MUM to both understand and generate language while maintaining the efficiency and flexibility that made T5 successful.
MUM fundamentally changes how content is discovered and displayed in search results. Instead of traditional blue link lists, MUM creates enriched SERPs with multiple content formats—images, videos, text snippets, and interactive elements—all on one page. This means brands need to optimize across multiple formats, not just text. Content that previously required users to click through multiple pages can now be surfaced directly in search results. However, this also means lower click-through rates for some content, as users can consume information within the SERP itself. Brands must now focus on visibility within search results and ensure their content is structured with schema markup to be properly understood by MUM.
MUM is critical for AI monitoring platforms because it represents how modern AI systems understand and retrieve information. As MUM becomes more prevalent in Google Search and influences other AI systems, monitoring where brands and domains appear in MUM-powered results becomes essential. AmICited tracks how brands are cited and appear across AI systems including Google's MUM-enhanced search. Understanding MUM's multimodal and multilingual capabilities helps organizations optimize their presence across different content formats and languages, ensuring they're visible when AI systems like MUM retrieve and surface their information to users.
Yes, MUM can process images and video with sophisticated understanding. When you upload an image or include video in a query, MUM doesn't just recognize objects—it extracts context, meaning, and relationships. For example, if you show MUM a photo of hiking boots and ask 'can I use these for Mt. Fuji?', MUM understands the boot's characteristics from the image and connects that understanding with your question to provide a contextual answer. This multimodal comprehension is one of MUM's most powerful features, enabling it to answer questions that require visual understanding combined with textual knowledge.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Learn about Google's Multitask Unified Model (MUM) and its impact on AI search results. Understand how MUM processes complex queries across multiple formats and...
Community discussion explaining Google MUM and its impact on AI search. Experts share how this multi-modal AI model affects content optimization and visibility.

Master multimodal AI search optimization. Learn how to optimize images and voice queries for AI-powered search results, featuring strategies for GPT-4o, Gemini,...