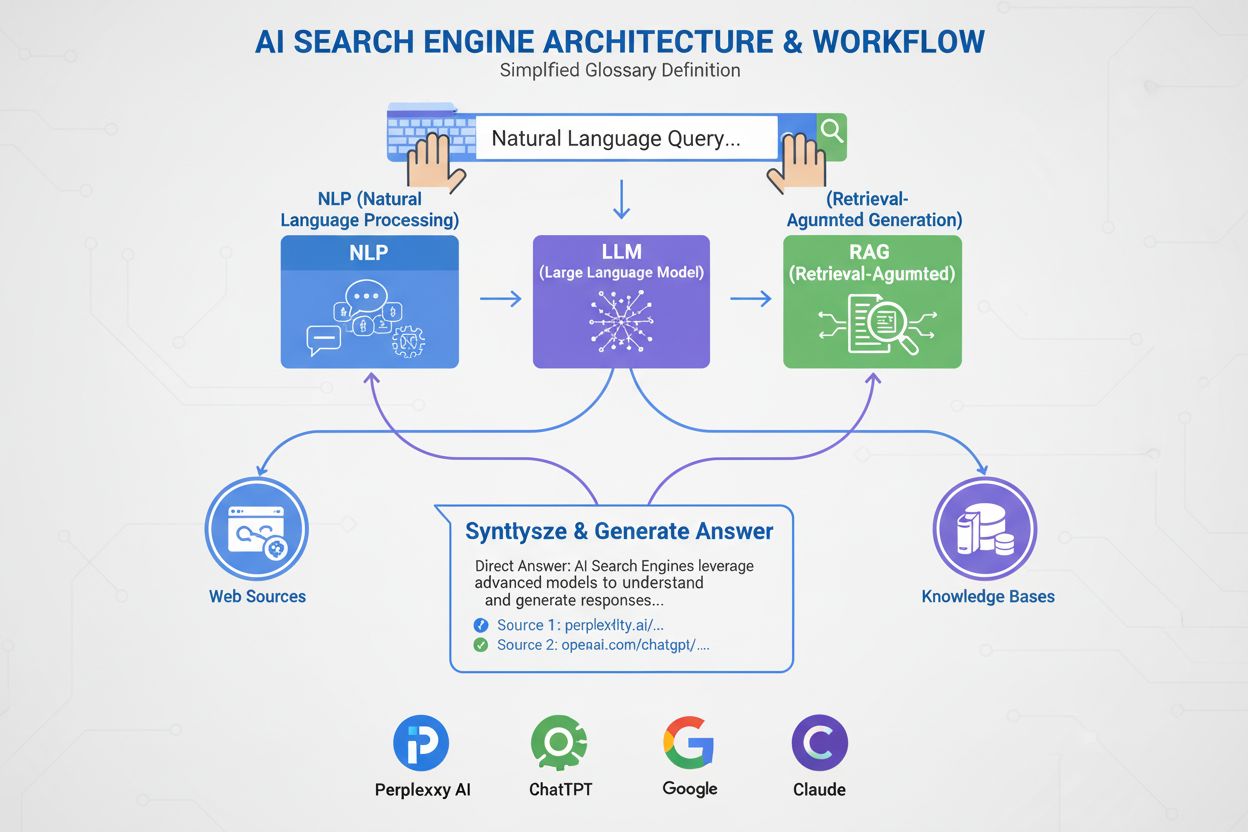
Definition of Natural Language Processing (NLP)
Natural Language Processing (NLP) is a subfield of artificial intelligence and computer science that enables computers to understand, interpret, manipulate, and generate human language in meaningful ways. NLP combines computational linguistics (the rule-based modeling of human language), machine learning algorithms, and deep learning neural networks to process both text and speech data. The technology allows machines to comprehend the semantic meaning of language, recognize patterns in human communication, and generate coherent responses that mimic human language understanding. NLP is fundamental to modern AI applications, powering everything from search engines and chatbots to voice assistants and AI monitoring systems that track brand mentions across platforms like ChatGPT, Perplexity, and Google AI Overviews.
Historical Context and Evolution of NLP
The field of Natural Language Processing emerged in the 1950s when researchers first attempted machine translation, with the landmark Georgetown-IBM experiment in 1954 successfully translating 60 Russian sentences into English. However, early NLP systems were severely limited, relying on rigid, rule-based approaches that could only respond to specific preprogrammed prompts. The 1990s and early 2000s saw significant progress with the development of statistical NLP methods, which introduced machine learning to language processing, enabling applications like spam filtering, document classification, and basic chatbots. The true revolution came in the 2010s with the rise of deep learning models and neural networks, which could analyze larger blocks of text and discover complex patterns in language data. Today, the NLP market is experiencing explosive growth, with projections showing the global NLP market expanding from $59.70 billion in 2024 to $439.85 billion by 2030, representing a compound annual growth rate (CAGR) of 38.7%. This growth reflects the increasing importance of NLP in enterprise solutions, AI-powered automation, and brand monitoring applications.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Core NLP Techniques and Methods
Natural Language Processing employs several fundamental techniques to break down and analyze human language. Tokenization is the process of splitting text into smaller units like words, sentences, or phrases, making complex text manageable for machine learning models. Stemming and lemmatization reduce words to their root forms (for example, “running,” “runs,” and “ran” all become “run”), allowing systems to recognize different forms of the same word. Named Entity Recognition (NER) identifies and extracts specific entities from text such as people’s names, locations, organizations, dates, and monetary values—a critical capability for brand monitoring systems that need to detect when a company name appears in AI-generated content. Sentiment analysis determines the emotional tone or opinion expressed in text, classifying content as positive, negative, or neutral, which is essential for understanding how brands are portrayed in AI responses. Part-of-speech tagging identifies the grammatical role of each word in a sentence (noun, verb, adjective, etc.), helping systems understand sentence structure and meaning. Text classification categorizes documents or passages into predefined categories, enabling systems to organize and filter information. These techniques work in concert within NLP pipelines to transform raw, unstructured text into structured, analyzable data that AI systems can process and learn from.
Comparison of NLP Approaches and Technologies
| NLP Approach | Description | Use Cases | Advantages | Limitations |
|---|
| Rules-Based NLP | Uses preprogrammed if-then decision trees and grammar rules | Simple chatbots, basic text filtering | Predictable, transparent, no training data needed | Not scalable, cannot handle language variations, limited flexibility |
| Statistical NLP | Uses machine learning to extract patterns from labeled data | Spam detection, document classification, part-of-speech tagging | More flexible than rules-based, learns from data | Requires labeled training data, struggles with context and nuance |
| Deep Learning NLP | Uses neural networks and transformer models on massive unstructured datasets | Chatbots, machine translation, content generation, brand monitoring | Highly accurate, handles complex language patterns, learns context | Requires enormous computational resources, prone to bias in training data |
| Transformer Models (BERT, GPT) | Uses self-attention mechanisms to process entire sequences simultaneously | Language understanding, text generation, sentiment analysis, NER | State-of-the-art performance, efficient training, contextual understanding | Computationally expensive, requires large datasets, black-box interpretability issues |
| Supervised Learning | Trains on labeled input-output pairs | Sentiment classification, named entity recognition, text categorization | High accuracy for specific tasks, predictable performance | Requires extensive labeled data, time-consuming annotation process |
| Unsupervised Learning | Discovers patterns in unlabeled data | Topic modeling, clustering, anomaly detection | No labeling required, discovers hidden patterns | Less accurate, harder to interpret results, requires domain expertise |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
How Natural Language Processing Works: The Complete Pipeline
Natural Language Processing operates through a systematic pipeline that transforms raw human language into machine-readable insights. The process begins with text preprocessing, where raw input is cleaned and standardized. Tokenization breaks text into individual words or phrases, lowercasing converts all characters to lowercase so “Apple” and “apple” are treated identically, and stop word removal filters out common words like “the” and “is” that don’t contribute meaningful information. Stemming and lemmatization reduce words to their root forms, and text cleaning removes punctuation, special characters, and irrelevant elements. Following preprocessing, the system performs feature extraction, converting text into numerical representations that machine learning models can process. Techniques like Bag of Words and TF-IDF quantify word importance, while word embeddings like Word2Vec and GloVe represent words as dense vectors in continuous space, capturing semantic relationships. More advanced contextual embeddings consider surrounding words to create richer representations. The next stage involves text analysis, where systems apply techniques like named entity recognition to identify specific entities, sentiment analysis to determine emotional tone, dependency parsing to understand grammatical relationships, and topic modeling to identify underlying themes. Finally, model training uses processed data to train machine learning models that learn patterns and relationships, with the trained model then deployed to make predictions on new, unseen data. This entire pipeline enables systems like AmICited to detect and analyze brand mentions in AI-generated responses across platforms like ChatGPT, Perplexity, and Google AI Overviews.
The emergence of deep learning has fundamentally transformed Natural Language Processing, moving beyond statistical methods to neural network architectures that can learn complex language patterns from massive datasets. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks were early deep learning approaches that could process sequential data, but they had limitations in handling long-range dependencies. The breakthrough came with transformer models, which introduced the self-attention mechanism—a revolutionary approach that allows models to simultaneously consider all words in a sequence and determine which parts are most important for understanding meaning. BERT (Bidirectional Encoder Representations from Transformers), developed by Google, became the foundation for modern search engines and language understanding tasks by processing text bidirectionally, understanding context from both directions. GPT (Generative Pre-trained Transformer) models, including the widely-used GPT-4, use autoregressive architecture to predict the next word in a sequence, enabling sophisticated text generation capabilities. These transformer-based models can be trained using self-supervised learning on massive text databases without requiring manual annotation, making them highly efficient and scalable. Foundation models like IBM’s Granite are prebuilt, curated models that can be rapidly deployed for various NLP tasks including content generation, insight extraction, and named entity recognition. The power of these models lies in their ability to capture nuanced semantic relationships, understand context across long passages, and generate coherent, contextually appropriate responses—capabilities that are essential for AI monitoring platforms tracking brand mentions in AI-generated content.
NLP Applications Across Industries and AI Monitoring
Natural Language Processing has become indispensable across virtually every industry, enabling organizations to extract actionable insights from vast amounts of unstructured text and voice data. In finance, NLP accelerates the analysis of financial statements, regulatory reports, and news releases, helping traders and analysts make faster, more informed decisions. Healthcare organizations use NLP to analyze medical records, research papers, and clinical notes, enabling faster diagnosis, treatment planning, and medical research. Insurance companies deploy NLP to analyze claims, identify patterns indicating fraud or inefficiency, and optimize claims processing workflows. Legal firms use NLP for automated document discovery, organizing vast amounts of case files and legal precedent, significantly reducing review time and costs. Customer service departments leverage NLP-powered chatbots to handle routine inquiries, freeing human agents for complex issues. Marketing and brand management teams increasingly rely on NLP for sentiment analysis and brand monitoring, tracking how their brands are mentioned and perceived across digital channels. Particularly relevant to AmICited’s mission, NLP enables AI monitoring platforms to detect and analyze brand mentions in AI-generated responses from systems like ChatGPT, Perplexity, Google AI Overviews, and Claude. These platforms use named entity recognition to identify brand names, sentiment analysis to understand the context and tone of mentions, and text classification to categorize the type of mention. This capability is increasingly critical as organizations recognize that their brand visibility in AI responses directly impacts customer discovery and brand reputation in the age of generative AI.
Key NLP Tasks and Capabilities
- Named Entity Recognition (NER): Identifies and extracts specific entities like people, organizations, locations, dates, and products from text, essential for brand monitoring and information extraction
- Sentiment Analysis: Determines the emotional tone and opinion expressed in text, classifying content as positive, negative, or neutral to understand brand perception
- Text Classification: Categorizes documents or passages into predefined categories, enabling automated organization and filtering of large text volumes
- Machine Translation: Converts text from one language to another while preserving meaning and context, powered by sequence-to-sequence transformer models
- Speech Recognition: Converts spoken language into text, enabling voice-based interfaces and transcription services
- Text Summarization: Automatically generates concise summaries of longer documents, saving time in information processing
- Question Answering: Enables systems to understand questions and retrieve or generate accurate answers from knowledge bases
- Coreference Resolution: Identifies when different words or phrases refer to the same entity, crucial for understanding context and relationships
- Part-of-Speech Tagging: Identifies the grammatical role of each word, helping systems understand sentence structure and meaning
- Topic Modeling: Discovers underlying themes and topics within documents or across document collections, useful for content analysis and organization
Challenges and Limitations in Natural Language Processing
Despite remarkable advances, Natural Language Processing faces significant challenges that limit its accuracy and applicability. Ambiguity is perhaps the most fundamental challenge—words and phrases often have multiple meanings depending on context, and sentences can be interpreted in different ways. For example, “I saw the man with the telescope” could mean either that the speaker used a telescope to see the man, or that the man possessed a telescope. Contextual understanding remains difficult for NLP systems, particularly when meaning depends on information from far earlier in a text or requires real-world knowledge. Sarcasm, idioms, and metaphors pose particular challenges because their literal meaning differs from their intended meaning, and systems trained on standard language patterns often misinterpret them. Tone of voice and emotional nuance are difficult to capture in text alone—the same words can convey entirely different meanings depending on delivery, emphasis, and body language. Bias in training data is a critical concern; NLP models trained on web-scraped data often inherit societal biases, leading to discriminatory or inaccurate outputs. New vocabulary and linguistic evolution constantly challenge NLP systems, as new words, slang, and grammatical conventions emerge faster than training data can be updated. Rare languages and dialects receive less training data, resulting in significantly lower performance for speakers of these languages. Grammatical errors, mumbling, background noise, and non-standard speech in real-world audio data create additional challenges for speech recognition systems. These limitations mean that even state-of-the-art NLP systems can misinterpret meaning, particularly in edge cases or when processing informal, creative, or culturally specific language.
The Future of NLP and Emerging Trends
The field of Natural Language Processing is rapidly evolving, with several emerging trends shaping its future direction. Multimodal NLP, which combines text, image, and audio processing, is enabling more sophisticated AI systems that can understand and generate content across multiple modalities simultaneously. Few-shot and zero-shot learning are reducing the need for massive labeled datasets, allowing NLP models to perform new tasks with minimal training examples. Retrieval-Augmented Generation (RAG) is improving the accuracy and reliability of AI-generated content by linking language models to external knowledge sources, reducing hallucinations and improving factual accuracy. Efficient NLP models are being developed to reduce computational requirements, making advanced NLP capabilities accessible to smaller organizations and edge devices. Explainable AI in NLP is becoming increasingly important as organizations seek to understand how models make decisions and ensure compliance with regulations. Domain-specific NLP models are being fine-tuned for specialized applications in healthcare, legal, finance, and other industries, improving accuracy for domain-specific language and terminology. Ethical AI and bias mitigation are receiving greater attention as organizations recognize the importance of fair, unbiased NLP systems. Most significantly for brand monitoring, the integration of NLP with AI monitoring platforms is becoming essential as organizations recognize that their brand visibility and perception in AI-generated responses directly impacts customer discovery and competitive positioning. As AI systems like ChatGPT, Perplexity, and Google AI Overviews become primary information sources for consumers, the ability to monitor and understand how brands appear in these systems—powered by sophisticated NLP techniques—will become a critical component of modern marketing and brand management strategies.
NLP’s Role in AI Monitoring and Brand Visibility
Natural Language Processing is the technological foundation enabling platforms like AmICited to track brand mentions across AI systems. When users query ChatGPT, Perplexity, Google AI Overviews, or Claude, these systems generate responses using large language models powered by advanced NLP techniques. AmICited uses NLP algorithms to analyze these AI-generated responses, detecting when brands are mentioned, extracting the context of those mentions, and analyzing the sentiment expressed. Named entity recognition identifies brand names and related entities, sentiment analysis determines whether mentions are positive, negative, or neutral, and text classification categorizes the type of mention (product recommendation, comparison, criticism, etc.). This capability provides organizations with crucial visibility into their AI presence—how their brand is being discovered and discussed within AI systems that increasingly serve as primary information sources for consumers. As the NLP market continues its explosive growth trajectory, with projections reaching $439.85 billion by 2030, the importance of NLP-powered brand monitoring will only increase, making it essential for organizations to understand and leverage these technologies to protect and enhance their brand reputation in the AI-driven future.