
Model Parameters
Model parameters are learnable variables in AI models that determine behavior. Understand weights, biases, and how parameters impact AI model performance and tr...
11 min read
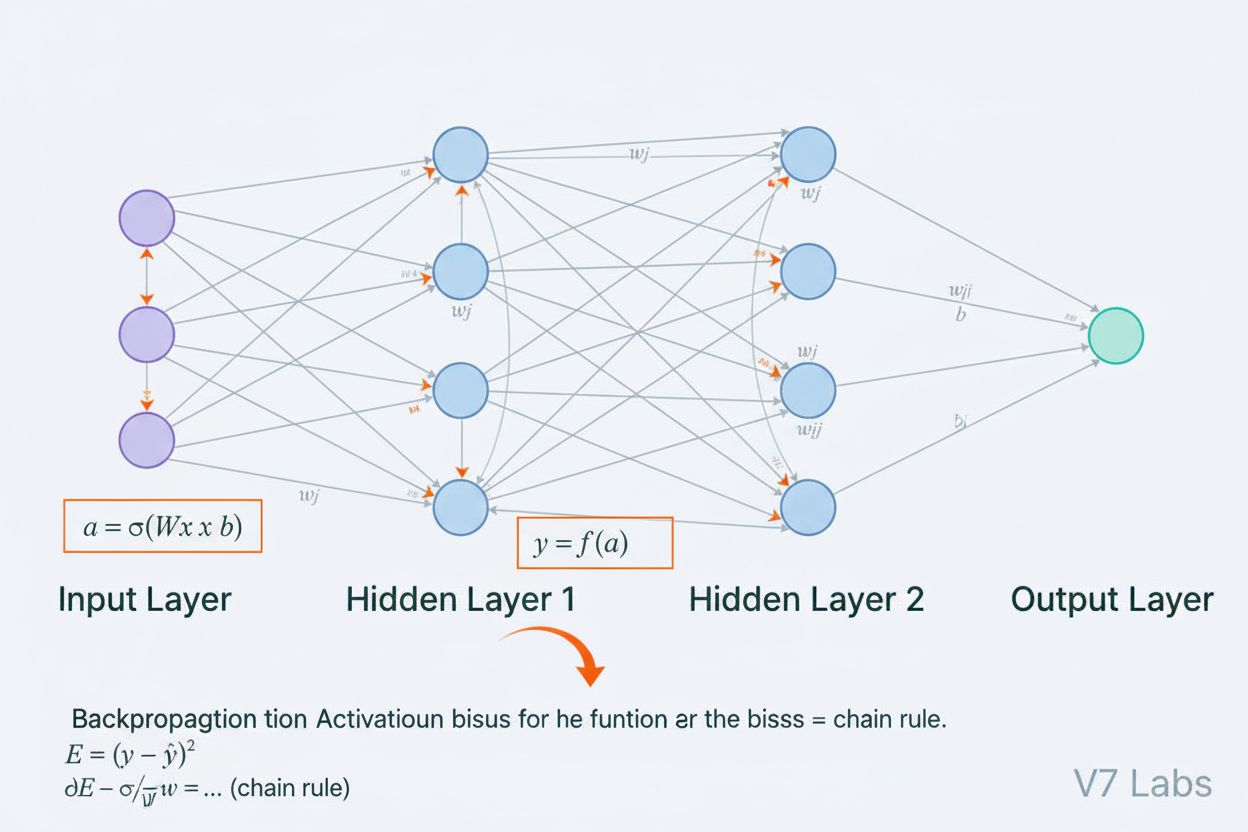
A neural network is a computing system inspired by biological neural networks that consists of interconnected artificial neurons organized in layers, capable of learning patterns from data through a process called backpropagation. These systems form the foundation of modern artificial intelligence and deep learning, powering applications from natural language processing to computer vision.
A neural network is a computing system inspired by biological neural networks that consists of interconnected artificial neurons organized in layers, capable of learning patterns from data through a process called backpropagation. These systems form the foundation of modern artificial intelligence and deep learning, powering applications from natural language processing to computer vision.
A neural network is a computing system fundamentally inspired by the structure and function of biological neural networks found in animal brains. It consists of interconnected artificial neurons organized into layers—typically an input layer, one or more hidden layers, and an output layer—that work together to process data, recognize patterns, and make predictions. Each neuron receives inputs, applies mathematical transformations through weights and biases, and passes the result through an activation function to produce an output. The defining characteristic of neural networks is their ability to learn from data through an iterative process called backpropagation, where the network adjusts its internal parameters to minimize prediction errors. This learning capability, combined with their capacity to model complex non-linear relationships, has made neural networks the foundational technology powering modern artificial intelligence systems, from large language models to computer vision applications.
The concept of artificial neural networks emerged from early attempts to mathematically model how biological neurons communicate and process information. In 1943, Warren McCulloch and Walter Pitts proposed the first mathematical model of a neuron, demonstrating that simple computational units could perform logical operations. This theoretical foundation was followed by Frank Rosenblatt’s introduction of the perceptron in 1958, an algorithm designed for pattern recognition that became the historical ancestor of today’s sophisticated neural network architectures. The perceptron was essentially a linear model with constrained output, capable of learning simple decision boundaries. However, the field experienced significant setbacks in the 1970s when researchers discovered that single-layer perceptrons could not solve non-linear problems like the XOR function, leading to what became known as the “AI winter.” The breakthrough came in the 1980s with the rediscovery and refinement of backpropagation, an algorithm that enabled training of multi-layer networks. This resurgence accelerated dramatically in the 2010s with the availability of massive datasets, powerful GPUs, and refined training techniques, leading to the deep learning revolution that transformed artificial intelligence.
A neural network’s architecture comprises several essential components working in concert. The input layer receives raw data features from external sources, with each neuron in this layer corresponding to one feature. Hidden layers perform the computational heavy lifting, transforming inputs into increasingly abstract representations through weighted combinations and non-linear activation functions. The number and size of hidden layers determine the network’s capacity to learn complex patterns—deeper networks can capture more sophisticated relationships but require more data and computational resources. The output layer produces the final predictions, with its structure depending on the task: a single neuron for regression, multiple neurons for multi-class classification, or specialized architectures for other applications. Each connection between neurons carries a weight that determines the strength of influence, while each neuron has a bias that shifts its activation threshold. These weights and biases are the learnable parameters that the network adjusts during training. The activation function applied at each neuron introduces crucial non-linearity, enabling the network to learn complex decision boundaries and patterns that linear models cannot capture.
Neural networks learn through a two-phase iterative process. During forward propagation, input data flows through the network from the input layer to the output layer. At each neuron, the weighted sum of inputs plus bias is calculated (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), then passed through an activation function to produce the neuron’s output. This process repeats through each hidden layer until reaching the output layer, which produces the network’s prediction. The network then calculates the error between its prediction and the true label using a loss function, which quantifies how far the prediction is from the correct answer. In backpropagation, this error is propagated backward through the network using the chain rule of calculus. At each neuron, the algorithm calculates the gradient of the loss with respect to each weight and bias, determining how much each parameter contributed to the overall error. These gradients guide the parameter updates: weights and biases are adjusted in the direction opposite to the gradient, scaled by a learning rate that controls the step size. This process repeats over many iterations through the training dataset, gradually reducing the loss and improving the network’s predictions. The combination of forward propagation, loss calculation, backpropagation, and parameter updates forms the complete training cycle that enables neural networks to learn from data.
| Architecture Type | Primary Use Case | Key Characteristic | Strengths | Limitations |
|---|---|---|---|---|
| Feedforward Networks | Classification, regression on structured data | Information flows in one direction only | Simple, fast training, interpretable | Cannot handle sequential or spatial data well |
| Convolutional Neural Networks (CNNs) | Image recognition, computer vision | Convolutional layers detect spatial features | Excellent at capturing local patterns, parameter efficient | Requires large labeled image datasets |
| Recurrent Neural Networks (RNNs) | Sequential data, time series, NLP | Hidden state maintains memory across time steps | Can process variable-length sequences | Suffers from vanishing/exploding gradients |
| Long Short-Term Memory (LSTM) | Long-range dependencies in sequences | Memory cells with input/forget/output gates | Handles long-term dependencies effectively | More complex, slower training than RNNs |
| Transformer Networks | Natural language processing, large language models | Multi-head attention mechanism, parallel processing | Highly parallelizable, captures long-range dependencies | Requires massive computational resources |
| Generative Adversarial Networks (GANs) | Image generation, synthetic data creation | Generator and discriminator networks compete | Can generate realistic synthetic data | Difficult to train, mode collapse issues |
The introduction of activation functions represents one of the most critical innovations in neural network design. Without activation functions, a neural network would be mathematically equivalent to a single linear transformation, regardless of how many layers it contains. This is because the composition of linear functions is itself linear, severely limiting the network’s ability to learn complex patterns. Activation functions solve this problem by introducing non-linearity at each neuron. The ReLU (Rectified Linear Unit) function, defined as f(x) = max(0, x), has become the most popular choice in modern deep learning due to its computational efficiency and effectiveness in training deep networks. The sigmoid function, f(x) = 1/(1 + e^(-x)), squashes outputs to a range between 0 and 1, making it useful for binary classification tasks. The tanh function, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), produces outputs between -1 and 1 and often performs better than sigmoid in hidden layers. The choice of activation function significantly impacts the network’s learning dynamics, convergence speed, and final performance. Modern architectures often use ReLU in hidden layers for its computational efficiency and use sigmoid or softmax in output layers for probability estimation. The non-linearity introduced by activation functions enables neural networks to approximate any continuous function, a property known as the universal approximation theorem, which explains their remarkable versatility across diverse applications.
The neural network market has experienced explosive growth, reflecting the technology’s central role in modern artificial intelligence. According to recent market research, the global neural network software market was valued at approximately $34.76 billion in 2025 and is projected to reach $139.86 billion by 2030, representing a compound annual growth rate (CAGR) of 32.10%. The broader neural network market shows even more dramatic expansion, with estimates suggesting growth from $34.05 billion in 2024 to $385.29 billion by 2033, at a CAGR of 31.4%. This explosive growth is driven by multiple factors: the increasing availability of large datasets, the development of more efficient training algorithms, the proliferation of GPU and specialized AI hardware, and the widespread adoption of neural networks across industries. According to Stanford’s 2025 AI Index Report, 78% of organizations reported using AI in 2024, up from 55% the previous year, with neural networks forming the backbone of most enterprise AI implementations. The adoption spans healthcare, finance, manufacturing, retail, and virtually every other sector, as organizations recognize the competitive advantage provided by neural network-based systems for pattern recognition, prediction, and decision-making.
Neural networks power the most advanced AI systems currently deployed, including ChatGPT, Perplexity, Google AI Overviews, and Claude. These large language models are built on transformer-based neural network architectures that use attention mechanisms to process and generate human language with remarkable sophistication. The transformer architecture, introduced in 2017, revolutionized natural language processing by enabling parallel processing of entire sequences rather than sequential processing, dramatically improving training efficiency and model performance. In the context of brand monitoring and AI citation tracking, understanding neural networks is crucial because these systems use neural networks to understand context, retrieve relevant information, and generate responses that may reference or cite your brand, domain, or content. AmICited leverages knowledge of how neural networks process and retrieve information to monitor where your brand appears in AI-generated responses across multiple platforms. As neural networks continue to improve in their ability to understand semantic meaning and retrieve relevant information, the importance of monitoring your brand’s presence in AI responses becomes increasingly critical for maintaining brand visibility and managing your online reputation in the age of AI-driven search and content generation.
Training neural networks effectively presents several significant challenges that researchers and practitioners must address. Overfitting occurs when a network learns the training data too well, including its noise and peculiarities, resulting in poor performance on new, unseen data. This is particularly problematic with deep networks that have many parameters relative to the training data size. Underfitting represents the opposite problem, where the network lacks sufficient capacity or training to capture the underlying patterns in the data. The vanishing gradient problem occurs in very deep networks where gradients become exponentially smaller as they propagate backward, causing weights in early layers to update extremely slowly or not at all. The exploding gradient problem is the opposite, where gradients become exponentially larger, causing unstable training. Modern solutions include batch normalization, which normalizes layer inputs to maintain stable gradient flow; residual connections (skip connections), which allow gradients to flow directly through layers; and gradient clipping, which limits the magnitude of gradients. Regularization techniques like L1 and L2 regularization add penalties for large weights, encouraging simpler models that generalize better. Dropout randomly deactivates neurons during training, preventing co-adaptation and improving generalization. The choice of optimizer (such as Adam, SGD, or RMSprop) and learning rate significantly impacts training efficiency and final model performance. Practitioners must carefully balance model complexity, training data size, regularization strength, and optimization parameters to achieve networks that learn effectively without overfitting.
The evolution of neural network architectures has followed a clear trajectory toward increasingly sophisticated mechanisms for processing information. Early feedforward networks were limited to fixed-size inputs and could not capture temporal or sequential dependencies. Recurrent neural networks (RNNs) introduced feedback loops allowing information to persist across time steps, enabling processing of variable-length sequences. However, RNNs suffered from gradient flow problems and were inherently sequential, preventing parallelization on modern hardware. Long Short-Term Memory (LSTM) networks addressed some of these issues through memory cells and gating mechanisms, but remained fundamentally sequential. The breakthrough came with transformer networks, which replaced recurrence entirely with attention mechanisms. The attention mechanism allows the network to dynamically focus on different parts of the input, computing weighted combinations of all input elements in parallel. This enables transformers to capture long-range dependencies efficiently while maintaining full parallelizability across GPU clusters. The transformer architecture, combined with massive scale (modern large language models contain billions to trillions of parameters), has proven remarkably effective for natural language processing, computer vision, and multimodal tasks. The success of transformers has led to their adoption as the standard architecture for state-of-the-art AI systems, including all major large language models. This evolution demonstrates how architectural innovations, combined with increased computational resources and larger datasets, continue to push the boundaries of what neural networks can achieve.
The field of neural networks continues to evolve rapidly with several promising directions emerging. Neuromorphic computing aims to create hardware that more closely mimics biological neural networks, potentially achieving greater energy efficiency and computational power. Few-shot and zero-shot learning research focuses on enabling neural networks to learn from minimal examples, more closely matching human learning capabilities. Explainability and interpretability have become increasingly important, with researchers developing techniques to understand and visualize what neural networks learn, crucial for high-stakes applications in healthcare, finance, and criminal justice. Federated learning enables training neural networks on distributed data without centralizing sensitive information, addressing privacy concerns. Quantum neural networks represent a frontier where quantum computing principles are combined with neural network architectures, potentially offering exponential speedups for certain problems. Multimodal neural networks that seamlessly integrate text, images, audio, and video are becoming increasingly sophisticated, enabling more comprehensive AI systems. Energy-efficient neural networks are being developed to reduce the computational and environmental costs of training and deploying large models. As neural networks continue to advance, their integration into AI monitoring systems like AmICited becomes increasingly important for organizations seeking to understand and manage their brand presence in AI-generated content and responses across platforms like ChatGPT, Perplexity, Google AI Overviews, and Claude.
Neural networks are inspired by the structure and function of biological neurons in the human brain. In the brain, neurons communicate through electrical signals via synapses, which can be strengthened or weakened based on experience. Artificial neural networks mimic this behavior by using mathematical models of neurons connected through weighted links, allowing the system to learn and adapt from data in a manner analogous to how biological brains process information and form memories.
Backpropagation is the primary algorithm that enables neural networks to learn. During forward propagation, data flows through the network layers producing predictions. The network then calculates the error between predicted and actual outputs using a loss function. In the backward pass, this error is propagated back through the network using the chain rule of calculus, calculating how much each weight and bias contributed to the error. Weights are then adjusted in the direction that minimizes error, typically using gradient descent optimization.
The primary neural network architectures include feedforward networks (data flows in one direction), convolutional neural networks or CNNs (optimized for image processing), recurrent neural networks or RNNs (designed for sequential data), long short-term memory networks or LSTMs (improved RNNs with memory cells), and transformer networks (using attention mechanisms for parallel processing). Each architecture is specialized for different types of data and tasks, from image recognition to natural language processing.
Modern AI systems like ChatGPT, Perplexity, and Claude are built on transformer-based neural networks, which use attention mechanisms to process language efficiently. These neural networks enable these systems to understand context, generate coherent text, and perform complex reasoning tasks. The ability of neural networks to learn from massive datasets and capture intricate patterns in language makes them essential for building conversational AI that can understand and respond to human queries with remarkable accuracy.
Weights in neural networks control the strength of connections between neurons, determining how much influence each input has on the output. Biases are additional parameters that shift the activation threshold of neurons, allowing them to activate even when inputs are weak. Together, weights and biases form the learnable parameters of the network that are adjusted during training to minimize prediction errors and enable the network to learn complex patterns from data.
Activation functions introduce non-linearity into neural networks, enabling them to learn complex, non-linear relationships in data. Without activation functions, stacking multiple layers would still result in linear transformations, severely limiting the network's learning capacity. Common activation functions include ReLU (Rectified Linear Unit), sigmoid, and tanh, each introducing different types of non-linearity that help the network capture intricate patterns and make more sophisticated predictions.
Hidden layers are intermediate layers between input and output layers where the network performs most of its computational work. These layers extract and transform features from raw input data into increasingly abstract representations. The depth and width of hidden layers determine the network's capacity to learn complex patterns. Deeper networks with more hidden layers can capture more sophisticated relationships in data, though they require more computational resources and careful training to avoid overfitting.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Model parameters are learnable variables in AI models that determine behavior. Understand weights, biases, and how parameters impact AI model performance and tr...

Learn what Natural Language Processing (NLP) is, how it works, and its critical role in AI systems. Explore NLP techniques, applications, and challenges in AI m...

Transformer Architecture is a neural network design using self-attention mechanisms to process sequential data in parallel. It powers ChatGPT, Claude, and moder...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.