
How Retrieval-Augmented Generation Works: Architecture and Process
Learn how RAG combines LLMs with external data sources to generate accurate AI responses. Understand the five-stage process, components, and why it matters for ...
10 min read

A Retrieval-Augmented Generation (RAG) pipeline is a workflow that enables AI systems to find, rank, and cite external sources when generating responses. It combines document retrieval, semantic ranking, and LLM generation to provide accurate, contextually relevant answers grounded in real data. RAG systems reduce hallucinations by consulting external knowledge bases before producing responses, making them essential for applications requiring factual accuracy and source attribution.
A Retrieval-Augmented Generation (RAG) pipeline is a workflow that enables AI systems to find, rank, and cite external sources when generating responses. It combines document retrieval, semantic ranking, and LLM generation to provide accurate, contextually relevant answers grounded in real data. RAG systems reduce hallucinations by consulting external knowledge bases before producing responses, making them essential for applications requiring factual accuracy and source attribution.
A Retrieval-Augmented Generation (RAG) pipeline is an AI architecture that combines information retrieval with large language model (LLM) generation to produce more accurate, contextually relevant, and verifiable responses. Rather than relying solely on an LLM’s training data, RAG systems dynamically fetch relevant documents or data from external knowledge bases before generating answers, significantly reducing hallucinations and improving factual accuracy. The pipeline acts as a bridge between static training data and real-time information, enabling AI systems to reference current, domain-specific, or proprietary content. This approach has become essential for organizations requiring citation-backed answers, compliance with accuracy standards, and transparency in AI-generated content. RAG pipelines are particularly valuable in monitoring AI systems where traceability and source attribution are critical requirements.
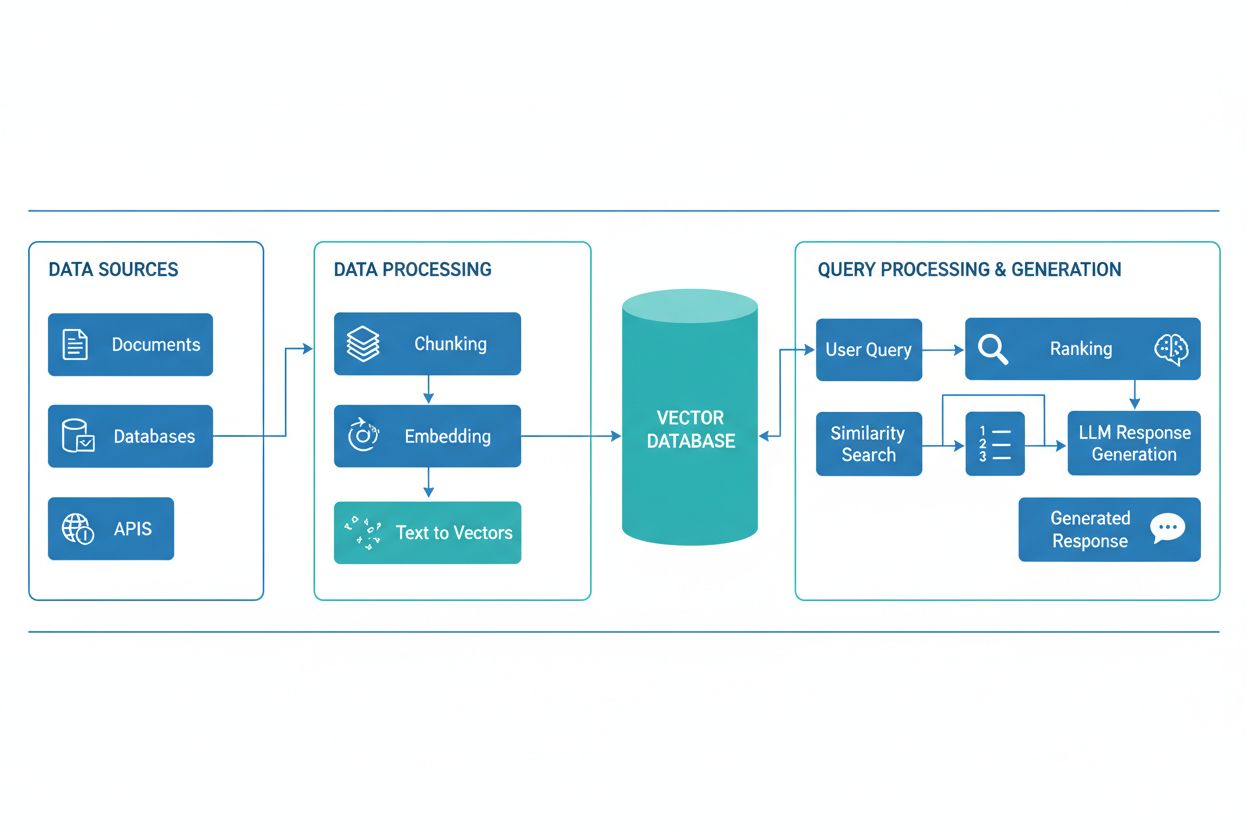
A RAG pipeline consists of several interconnected components that work together to retrieve relevant information and generate grounded responses. The architecture typically includes a document ingestion layer that processes and prepares raw data, a vector database or knowledge base that stores embeddings and indexed content, a retrieval mechanism that identifies relevant documents based on user queries, a ranking system that prioritizes the most relevant results, and a generation module powered by an LLM that synthesizes retrieved information into coherent answers. Additional components include query processing and preprocessing modules that normalize user input, embedding models that convert text into numerical representations, and a feedback loop that continuously improves retrieval accuracy. The orchestration of these components determines the overall effectiveness and efficiency of the RAG system.
| Component | Function | Key Technologies |
|---|---|---|
| Document Ingestion | Processing and preparing raw data | Apache Kafka, LangChain, Unstructured |
| Vector Database | Storing embeddings and indexed content | Pinecone, Weaviate, Milvus, Qdrant |
| Retrieval Engine | Identifying relevant documents | BM25, Dense Passage Retrieval (DPR) |
| Ranking System | Prioritizing search results | Cross-encoders, LLM-based reranking |
| Generation Module | Synthesizing answers from context | GPT-4, Claude, Llama, Mistral |
| Query Processor | Normalizing and understanding user input | BERT, T5, custom NLP pipelines |
The RAG pipeline operates through two distinct phases: the retrieval phase and the generation phase. During the retrieval phase, the system converts the user’s query into an embedding using the same embedding model that processed the knowledge base documents, then searches the vector database to identify the most semantically similar documents or passages. This phase typically returns a ranked list of candidate documents, which may be further refined through reranking algorithms that use cross-encoders or LLM-based scoring to ensure relevance. In the generation phase, the top-ranked retrieved documents are formatted into a context window and passed to the LLM along with the original query, enabling the model to generate responses grounded in actual source material. This two-phase approach ensures that answers are both contextually appropriate and traceable to specific sources, making it ideal for applications requiring citation and accountability. The quality of the final output depends critically on both the relevance of retrieved documents and the LLM’s ability to synthesize information coherently.
The RAG ecosystem encompasses a diverse range of specialized tools and frameworks designed to simplify pipeline construction and deployment. Modern RAG implementations leverage several categories of technology:
These tools can be combined modularly, allowing organizations to build RAG systems tailored to their specific requirements and infrastructure constraints.
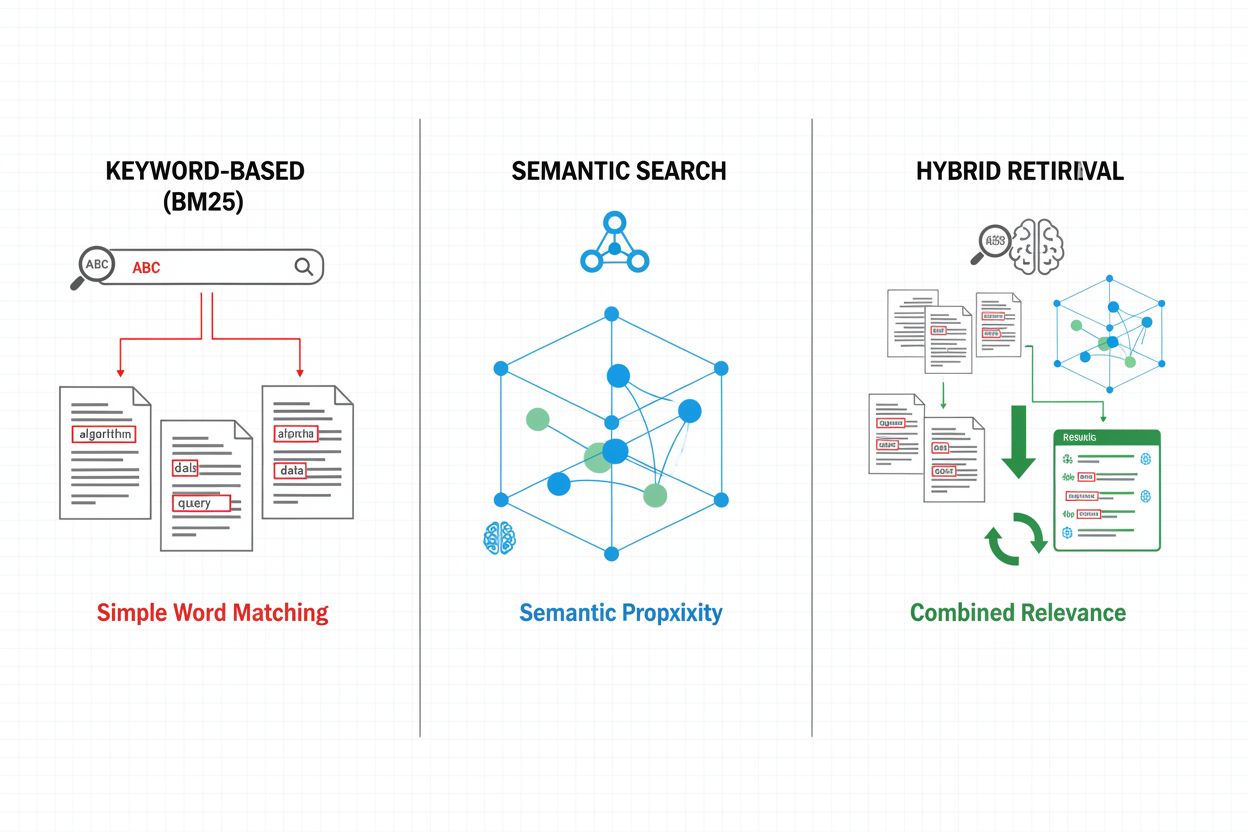
Retrieval mechanisms form the foundation of RAG pipeline effectiveness, evolving from simple keyword-based approaches to sophisticated semantic search methods. Traditional keyword-based retrieval using BM25 algorithms remains computationally efficient and effective for exact-match scenarios, but struggles with semantic understanding and synonymy. Dense Passage Retrieval (DPR) and other neural retrieval methods address these limitations by encoding both queries and documents into dense vector embeddings, enabling semantic similarity matching that captures meaning beyond surface-level keywords. Hybrid retrieval approaches combine keyword-based and semantic search, leveraging the strengths of both methods to improve recall and precision across diverse query types. Advanced retrieval mechanisms incorporate query expansion, where the original query is augmented with related terms or reformulations to capture more relevant documents. Reranking layers further refine results by applying more computationally expensive models that score candidate documents based on deeper semantic understanding or task-specific relevance criteria. The choice of retrieval mechanism significantly impacts both the accuracy of retrieved context and the computational cost of the RAG pipeline, requiring careful consideration of trade-offs between speed and quality.
RAG pipelines deliver substantial advantages over traditional LLM-only approaches, particularly for applications requiring accuracy, currency, and traceability. By grounding responses in retrieved documents, RAG systems dramatically reduce hallucinations—instances where LLMs generate plausible-sounding but factually incorrect information—making them suitable for high-stakes domains like healthcare, legal, and financial services. The ability to reference external knowledge bases enables RAG systems to provide current information without retraining models, allowing organizations to maintain up-to-date responses as new information becomes available. RAG pipelines support domain-specific customization by incorporating proprietary documents, internal knowledge bases, and specialized terminology, enabling more relevant and contextually appropriate responses. The retrieval component provides transparency and auditability by explicitly showing which sources informed each answer, critical for compliance requirements and user trust. Cost efficiency improves through the use of smaller, more efficient LLMs that can generate high-quality responses when provided with relevant context, reducing computational overhead compared to larger models. These benefits make RAG particularly valuable for organizations implementing AI monitoring systems where citation accuracy and content visibility are paramount.
Despite their advantages, RAG pipelines face several technical and operational challenges that require careful management. The quality of retrieved documents directly determines answer quality, making retrieval errors difficult to recover from—a phenomenon known as “garbage in, garbage out” where irrelevant or outdated documents in the knowledge base propagate through to final answers. Embedding models may struggle with domain-specific terminology, rare languages, or highly technical content, leading to poor semantic matching and missed relevant documents. The computational cost of retrieval, embedding generation, and reranking can be substantial at scale, particularly when processing large knowledge bases or handling high query volumes. Context window limitations in LLMs constrain the amount of retrieved information that can be incorporated into prompts, requiring careful selection and summarization of relevant passages. Maintaining knowledge base freshness and consistency presents operational challenges, particularly in dynamic environments where information changes frequently or comes from multiple sources. Evaluating RAG system performance requires comprehensive metrics beyond traditional accuracy measures, including retrieval precision, answer relevance, and citation correctness, which can be difficult to assess automatically.
RAG represents one approach among several strategies for improving LLM accuracy and relevance, each with distinct trade-offs. Fine-tuning involves retraining LLMs on domain-specific data, providing deep model customization but requiring substantial computational resources, labeled training data, and ongoing maintenance as information changes. Prompt engineering optimizes instructions and context provided to LLMs without modifying model weights, offering flexibility and low cost but limited by the model’s training data and context window size. In-context learning leverages few-shot examples within prompts to guide model behavior, providing quick adaptation but consuming valuable context tokens and requiring careful example selection. Compared to these approaches, RAG offers a middle ground: it provides dynamic access to current information without retraining, maintains transparency through explicit source attribution, and scales efficiently across diverse knowledge domains. However, RAG introduces additional complexity through retrieval infrastructure and potential retrieval errors, whereas fine-tuning provides tighter integration of domain knowledge into model behavior. The optimal approach often involves combining multiple strategies—for example, using RAG with fine-tuned models and carefully engineered prompts—to maximize accuracy and relevance for specific use cases.
Implementing a production RAG pipeline requires systematic planning across data preparation, architecture design, and operational considerations. The process begins with knowledge base preparation: collecting relevant documents, cleaning and standardizing formats, and breaking content into appropriately-sized chunks that balance context preservation with retrieval precision. Next, organizations select embedding models and vector databases based on performance requirements, latency constraints, and scalability needs, considering factors like embedding dimensionality, query throughput, and storage capacity. The retrieval system is then configured, including decisions about retrieval algorithms (keyword, semantic, or hybrid), reranking strategies, and result filtering criteria. Integration with LLM providers follows, establishing connections to generation models and defining prompt templates that incorporate retrieved context effectively. Testing and evaluation are critical, requiring metrics for retrieval quality (precision, recall, MRR), generation quality (relevance, coherence, factuality), and end-to-end system performance. Deployment considerations include setting up monitoring for retrieval accuracy and generation quality, implementing feedback loops to identify and address failure modes, and establishing processes for knowledge base updates and maintenance. Finally, continuous optimization involves analyzing user interactions, identifying common failure patterns, and iteratively improving retrieval mechanisms, reranking strategies, and prompt engineering to enhance overall system performance.
RAG pipelines are fundamental to modern AI monitoring platforms like AmICited.com, where tracking the sources and accuracy of AI-generated content is essential. By explicitly retrieving and citing source documents, RAG systems create an auditable trail that enables monitoring platforms to verify claims, assess factual accuracy, and identify potential hallucinations or misattributions. This citation capability addresses a critical gap in AI transparency: users and auditors can trace answers back to original sources, enabling independent verification and building trust in AI-generated content. For content creators and organizations using AI tools, RAG-enabled monitoring provides visibility into which sources informed specific answers, supporting compliance with attribution requirements and content governance policies. The retrieval component of RAG pipelines generates rich metadata—including relevance scores, document rankings, and retrieval confidence metrics—that monitoring systems can analyze to assess answer reliability and identify when AI systems are operating outside their knowledge domains. Integration of RAG with monitoring platforms enables detection of citation drift, where AI systems gradually shift away from authoritative sources toward less reliable ones, and supports enforcement of content policies around source quality and diversity. As AI systems become increasingly integrated into critical workflows, the combination of RAG pipelines with comprehensive monitoring creates accountability mechanisms that protect users, organizations, and the broader information ecosystem from AI-generated misinformation.
RAG and fine-tuning are complementary approaches to improving LLM performance. RAG retrieves external documents at query time without modifying the model, enabling real-time data access and easy updates. Fine-tuning retrains the model on domain-specific data, providing deeper customization but requiring significant computational resources and manual updates when information changes. Many organizations use both techniques together for optimal results.
RAG reduces hallucinations by grounding LLM responses in retrieved factual documents. Instead of relying solely on training data, the system retrieves relevant sources before generation, providing the model with concrete evidence to reference. This approach ensures answers are based on actual information rather than the model's learned patterns, significantly improving factual accuracy and reducing false or misleading claims.
Vector embeddings are numerical representations of text that capture semantic meaning in multi-dimensional space. They enable RAG systems to perform semantic search, finding documents with similar meaning even if they use different words. Embeddings are crucial because they allow RAG to move beyond keyword matching to understand conceptual relationships, improving retrieval relevance and enabling more accurate answer generation.
Yes, RAG pipelines can incorporate real-time data through continuous ingestion and indexing processes. Organizations can set up automated pipelines that regularly update the vector database with new documents, ensuring the knowledge base stays current. This capability makes RAG ideal for applications requiring up-to-date information like news analysis, pricing intelligence, and market monitoring without needing to retrain the underlying LLM.
Semantic search is a retrieval technique that finds documents based on meaning similarity using vector embeddings. RAG is a complete pipeline that combines semantic search with LLM generation to produce answers grounded in retrieved documents. While semantic search focuses on finding relevant information, RAG adds the generation component that synthesizes retrieved content into coherent responses with citations.
RAG systems use multiple mechanisms to select sources for citation. They employ retrieval algorithms to find relevant documents, reranking models to prioritize the most relevant results, and verification processes to ensure citations actually support the claims made. Some systems use 'cite-while-writing' approaches where claims are only made if supported by retrieved sources, while others verify citations after generation and remove unsupported claims.
Key challenges include maintaining knowledge base freshness and quality, optimizing retrieval accuracy across diverse content types, managing computational costs at scale, handling domain-specific terminology that embedding models may not understand well, and evaluating system performance with comprehensive metrics. Organizations must also address context window limitations in LLMs and ensure retrieved documents remain relevant as information evolves.
AmICited tracks how AI systems like ChatGPT, Perplexity, and Google AI Overviews retrieve and cite content through RAG pipelines. The platform monitors which sources are selected for citation, how frequently your brand appears in AI answers, and whether citations are accurate. This visibility helps organizations understand their presence in AI-mediated search and ensure proper attribution of their content.
Track how AI systems like ChatGPT, Perplexity, and Google AI Overviews reference your content. Get visibility into RAG citations and AI answer monitoring.
Learn how RAG combines LLMs with external data sources to generate accurate AI responses. Understand the five-stage process, components, and why it matters for ...

Learn what Retrieval-Augmented Generation (RAG) is, how it works, and why it's essential for accurate AI responses. Explore RAG architecture, benefits, and ente...
Learn what RAG (Retrieval-Augmented Generation) is in AI search. Discover how RAG improves accuracy, reduces hallucinations, and powers ChatGPT, Perplexity, and...