
Quality Rater Guidelines
Learn about Google's Quality Rater Guidelines, the evaluation framework used by 16,000+ raters to assess search quality, E-E-A-T signals, and how they influence...
11 min read
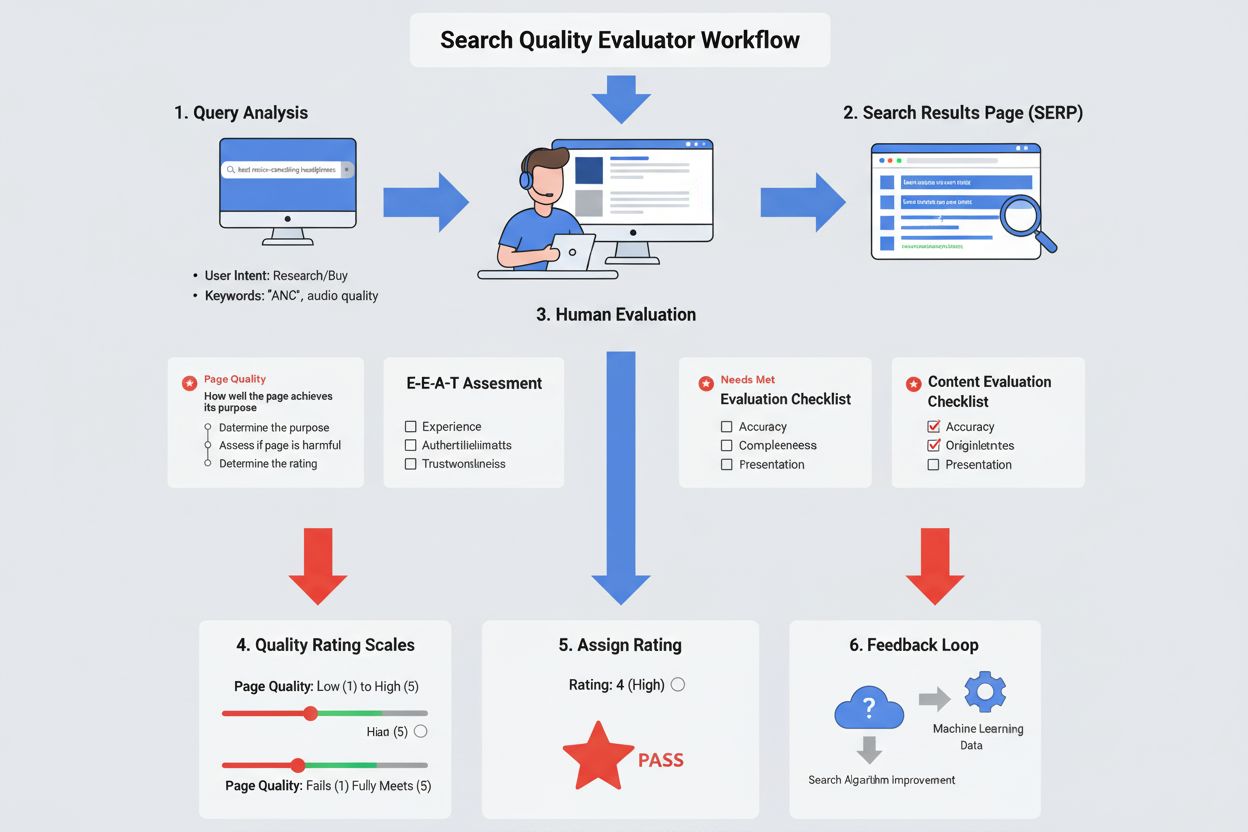
A Search Quality Evaluator is a human reviewer employed by Google (typically through third-party contractors) who assesses the quality and relevance of search results based on established guidelines. These evaluators rate search results on criteria including E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), content quality, and user intent satisfaction to help Google measure and improve its search algorithm performance.
A Search Quality Evaluator is a human reviewer employed by Google (typically through third-party contractors) who assesses the quality and relevance of search results based on established guidelines. These evaluators rate search results on criteria including E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness), content quality, and user intent satisfaction to help Google measure and improve its search algorithm performance.
A Search Quality Evaluator is a human reviewer employed by Google (typically through third-party contracting companies) who systematically assesses the quality, relevance, and usefulness of search results. These evaluators, numbering approximately 16,000 worldwide, apply standardized guidelines to rate search results on multiple dimensions including content quality, user intent satisfaction, and adherence to E-E-A-T principles (Experience, Expertise, Authoritativeness, and Trustworthiness). Their primary function is not to determine rankings directly, but rather to provide human feedback that helps Google measure how effectively its search algorithms are delivering useful, authoritative, and trustworthy information to users across different locales and languages. Search Quality Evaluators represent a critical bridge between human judgment and machine learning, ensuring that Google’s automated systems align with real user needs and expectations.
Google launched its Search Quality Rating Program in 2005, initially with a small team of evaluators. Over nearly two decades, the program has evolved into a sophisticated quality assurance mechanism involving thousands of human reviewers. In August 2022, Google officially acknowledged the existence and scope of this program by publishing the first comprehensive public document explaining who these evaluators are and how they work. This transparency marked a significant shift, as the program had previously operated with considerable secrecy. The program has continuously expanded and refined its guidelines, with major updates occurring in November 2023 and January 2025, reflecting Google’s evolving priorities around content quality, AI-generated content, spam detection, and user satisfaction. According to Google’s official statements, the company conducted over 719,326 search quality tests in 2023 alone, demonstrating the scale and importance of this evaluation process in maintaining search quality standards.
Search Quality Evaluators perform a diverse range of assessment tasks that directly inform Google’s understanding of search quality. Their primary responsibilities include rating page quality by evaluating whether pages achieve their stated purpose, assessing needs met by determining how well search results satisfy user intent, and conducting side-by-side experiments where they compare two different versions of search results to indicate which performs better. Evaluators examine multiple aspects of each page including the main content quality, the reputation of websites and content creators, the presence and prominence of advertisements, and the overall user experience. They also conduct reputation research on websites and creators by searching for independent reviews, news articles, and expert opinions. Additionally, evaluators identify and flag problematic content such as spam, harmful information, deceptive practices, and AI-generated content created with minimal effort. Each evaluation task requires careful analysis of the query, understanding of user intent, assessment of content accuracy, and judgment about whether the result truly serves the user’s needs.
| Aspect | Search Quality Evaluator | SEO Professional | Content Moderator | Algorithm Engineer |
|---|---|---|---|---|
| Primary Function | Assess search result quality and user satisfaction | Optimize website visibility in search results | Review content for policy violations | Design and improve ranking algorithms |
| Employment Type | Third-party contractors (temporary/short-term) | Website owner/agency employee | Platform employee (full-time) | Google employee (full-time) |
| Decision Authority | Provides ratings and feedback; no direct ranking control | Influences rankings through optimization | Removes/flags violating content | Controls algorithmic ranking factors |
| Scope of Work | Evaluates sample queries and results | Optimizes specific websites/pages | Monitors user-generated content | Develops system-wide improvements |
| Impact on Rankings | Indirect (aggregate feedback improves algorithms) | Direct (optimization affects visibility) | Indirect (removes harmful content) | Direct (algorithms determine rankings) |
| Key Metrics | Page Quality, Needs Met, E-E-A-T ratings | Keyword rankings, organic traffic | Content violations, user reports | Algorithm performance, relevance scores |
| Training Requirements | Guidelines test, locale expertise | SEO knowledge, industry experience | Policy training, content guidelines | Computer science, machine learning |
| Typical Workload | 50-100+ evaluations per day | Ongoing optimization projects | Continuous content review | Algorithm development cycles |
The E-E-A-T framework represents the cornerstone of how Search Quality Evaluators assess content credibility and quality. Experience refers to the first-hand or lived experience of content creators—for example, a product review from someone who has actually used the product carries more weight than speculation. Expertise encompasses the knowledge, skills, and formal training relevant to the topic; medical advice should come from healthcare professionals, while financial guidance should come from credentialed financial experts. Authoritativeness evaluates whether the creator or website is recognized as a go-to source for the topic—official government websites are authoritative for government information, and established news organizations are authoritative for journalism. Trustworthiness is perhaps the most critical dimension, assessing whether the page is accurate, honest, safe, and reliable. Importantly, Trust is the most important member of the E-E-A-T family, as an untrustworthy page has low E-E-A-T regardless of how experienced, expert, or authoritative it may appear. For YMYL topics (Your Money or Your Life) such as health, finance, legal matters, and civic information, evaluators apply significantly higher E-E-A-T standards because inaccurate information could directly harm users’ health, financial security, or safety.
Search Quality Evaluators use a five-point Page Quality rating scale ranging from Lowest to Highest quality, with intermediate ratings of Low, Medium, and High. The Lowest rating is assigned to pages with harmful purposes, deceptive content, untrustworthy information, or spam characteristics. Pages receive a Low rating when they lack adequate E-E-A-T, contain low-effort content, have misleading titles, or feature distracting advertisements. Medium quality pages achieve their purpose adequately but lack distinguishing characteristics that would warrant a higher rating—these represent the majority of pages on the internet. High quality pages demonstrate significant effort, originality, talent, or skill, have positive reputation, and exhibit high E-E-A-T appropriate to their topic. Highest quality pages represent exceptional content with very high E-E-A-T, very positive reputation, and demonstrate outstanding effort and originality. The assessment process requires evaluators to first understand the page’s purpose, then assess whether the purpose is harmful or deceptive, and finally assign a rating based on how well the page achieves its purpose while meeting quality standards. This three-step process ensures consistent, principled evaluation across thousands of evaluators worldwide.
Beyond assessing page quality, Search Quality Evaluators also rate how well search results satisfy user intent through the Needs Met (NM) rating scale. This scale includes five primary ratings: Fully Meets (FullyM) for results that completely satisfy specific, unambiguous queries (typically navigational queries like searching for a specific website); Highly Meets (HM) for very helpful results that satisfy dominant, common, or reasonable minor interpretations of user intent; Moderately Meets (MM) for helpful results that fit the query but are less satisfying than Highly Meets results; Slightly Meets (SM) for results that provide minimal help or address unlikely interpretations; and Fails to Meet (FailsM) for results that completely fail to address user needs or are off-topic. Evaluators must first determine the user’s intent by analyzing the query, considering the user’s location when relevant, and identifying possible query interpretations. They then assess whether the result actually satisfies that intent, considering factors such as freshness (whether information is current), accuracy (whether claims are factually correct), and relevance (whether the result directly addresses the query). This dual-rating system—combining Page Quality assessment with Needs Met evaluation—provides Google with comprehensive feedback about both the intrinsic quality of pages and their practical usefulness for specific search queries.
Search Quality Evaluators assess multiple dimensions when evaluating content quality and relevance. They examine the main content (MC) to determine if it directly helps the page achieve its purpose, evaluating the effort, originality, talent, and skill invested in creating it. They identify supplementary content (SC) that enhances user experience without directly serving the page’s purpose, such as navigation links. They assess the presence and prominence of advertisements and monetization, noting that while ads are acceptable and necessary for many websites, they should not obscure or obstruct the main content. Evaluators research the reputation of websites and content creators by searching for independent reviews, news articles, expert opinions, and customer feedback. They verify author credentials and expertise by checking educational background, professional experience, and previous publications. They assess content accuracy by fact-checking claims against authoritative sources, particularly for YMYL topics. They evaluate page design and user experience, noting whether content is easy to access or buried beneath ads and filler. They also identify problematic content patterns such as copied or paraphrased material with minimal added value, AI-generated content created with little effort, misleading titles, deceptive design, and content that contradicts well-established expert consensus.
As of the January 2025 update to Google’s Search Quality Rater Guidelines, evaluators now specifically assess whether content is created using automated or generative AI tools. Pages with main content that is “auto or AI generated” with “little to no effort, little to no originality, and little to no added value” receive a Lowest quality rating. Evaluators look for indicators of AI generation including paraphrased content with minimal changes, generic language patterns, commonly known information without original insights, high overlap with existing sources like Wikipedia, and telltale phrases such as “As an AI language model.” However, the guidelines clarify that generative AI itself is not inherently problematic—it can be a helpful tool for content creation when used with significant human effort, original additions, and genuine value creation. The distinction is between AI as a tool that enhances human creativity and AI as a shortcut to generate low-effort, low-value content at scale. This reflects Google’s broader focus on scaled content abuse, where large volumes of low-quality content are generated with minimal human curation or editing, regardless of the creation method.
While Search Quality Evaluators do not directly control rankings, their work has significant indirect impact on how Google’s algorithms evolve and improve. Google uses aggregate ratings from thousands of evaluators to measure the effectiveness of its ranking systems and to identify areas where algorithms may be failing to deliver quality results. When evaluators consistently rate certain types of results as low quality, this signals to Google’s engineering teams that the algorithm needs adjustment. Evaluators also provide positive and negative examples that help train Google’s machine learning systems to better recognize quality signals. In 2023 alone, Google conducted over 719,326 search quality tests and implemented over 4,000 improvements to Search based partly on evaluator feedback. The company also ran 16,871 live traffic experiments and 124,942 side-by-side experiments involving quality raters. This data-driven approach ensures that algorithm improvements are grounded in human judgment about what actually constitutes quality and usefulness. The feedback loop between human evaluators and machine learning systems creates a continuous cycle of improvement, where algorithms learn to recognize patterns associated with high-quality content as identified by human experts.
Search Quality Evaluators are recruited through a network of third-party contracting companies rather than being directly hired by Google. Recruitment is selective, with Google identifying candidates who demonstrate strong familiarity with their task language and locale, comfort using search engines, and ability to represent local users’ needs and cultural standards. Potential evaluators must pass a comprehensive test on Google’s Search Quality Rater Guidelines before beginning work. These guidelines, now exceeding 160 pages, cover detailed criteria for assessing page quality, understanding user intent, evaluating E-E-A-T, identifying spam and harmful content, and rating search result relevance. The guidelines include extensive examples and case studies to ensure consistent interpretation across evaluators. Evaluators work on short-term contracts that can be renewed but typically do not last indefinitely, which helps prevent potential conflicts of interest or attempts to manipulate the evaluation system. Evaluators are explicitly instructed that their ratings must not be based on personal opinions, preferences, religious beliefs, or political views, but rather on objective application of the guidelines and representation of their locale’s cultural standards. This emphasis on objectivity and adherence to guidelines ensures that evaluations reflect genuine quality assessment rather than individual bias.
Several misconceptions surround the role of Search Quality Evaluators. First misconception: Evaluators directly determine rankings or assign penalties. Reality: Evaluators provide feedback that helps Google measure algorithm effectiveness, but individual ratings do not directly affect specific page rankings. Second misconception: High Page Quality ratings guarantee high search visibility. Reality: Page Quality is one of many factors Google considers; even high-quality pages may not rank well if they don’t match user intent or if other pages are more relevant. Third misconception: E-E-A-T is a ranking factor. Reality: E-E-A-T is a framework evaluators use to assess content credibility, and while Google’s algorithms may align with E-E-A-T principles, E-E-A-T itself is not a direct ranking signal. Fourth misconception: Evaluators can be influenced or manipulated. Reality: The short-term contract structure, comprehensive guidelines, and quality assurance processes make the evaluation system resistant to manipulation. Fifth misconception: All AI-generated content receives lowest ratings. Reality: AI tools used with significant human effort, original additions, and genuine value creation may not receive lowest ratings; the issue is low-effort, low-value AI generation at scale.
The role of Search Quality Evaluators continues to evolve as Google faces new challenges in maintaining search quality. The increasing prevalence of AI-generated content has prompted Google to explicitly address AI in its guidelines and train evaluators to identify low-effort AI generation. The rise of AI-powered search interfaces like Google AI Overviews and competition from AI chatbots like ChatGPT and Claude has intensified Google’s focus on demonstrating that human evaluation ensures quality. Future developments may include more sophisticated AI detection methods, expanded evaluation of multimodal content (images, videos, audio), and greater emphasis on local and cultural relevance. For content creators and website owners, understanding how Search Quality Evaluators assess content is increasingly important. The emphasis on E-E-A-T, original content, user-focused design, and authentic expertise suggests that sustainable SEO success requires genuine quality rather than shortcuts. The explicit warnings against low-effort AI generation, copied content, and deceptive practices indicate that Google is committed to rewarding authentic, valuable content creation. Organizations should focus on demonstrating expertise through original research, building genuine authority through quality content and positive reputation, and ensuring trustworthiness through transparency and accuracy.
Search Quality Evaluators represent a crucial human element in Google’s otherwise algorithmic search system. Their work demonstrates that despite the sophistication of machine learning and artificial intelligence, human judgment remains essential for assessing quality, relevance, and trustworthiness. The approximately 16,000 evaluators worldwide, working across different languages and locales, ensure that Google’s search results reflect diverse user needs and cultural contexts. By providing systematic feedback on page quality and user satisfaction, evaluators help Google continuously improve its algorithms to deliver more useful, authoritative, and trustworthy information. For anyone seeking to understand how Google evaluates content—whether as a content creator, SEO professional, or simply a curious user—understanding the role and methodology of Search Quality Evaluators provides valuable insights into what Google considers quality and how the search engine continuously strives to serve users better. As the digital landscape evolves with AI-generated content, new search interfaces, and changing user expectations, the role of human evaluators becomes even more critical in maintaining the integrity and usefulness of search results.
No, Search Quality Evaluators do not directly determine rankings or assign penalties to websites. Instead, their ratings serve as feedback to help Google measure how well its algorithms are performing. The aggregate ratings from thousands of evaluators provide signals that help Google improve its systems, but individual ratings do not directly impact a specific page's ranking position in search results.
E-E-A-T stands for Experience, Expertise, Authoritativeness, and Trustworthiness. Search Quality Evaluators assess these four dimensions to determine if content creators and websites are reliable sources for their topics. E-E-A-T is especially critical for YMYL (Your Money or Your Life) topics like health, finance, and legal advice, where inaccurate information could harm users. Evaluators research creator credentials, website reputation, and content quality to assess E-E-A-T levels.
Google employs approximately 16,000 Search Quality Evaluators worldwide through a network of third-party contracting companies. These evaluators are distributed across different regions and locales to ensure diverse perspectives and cultural understanding. The exact number may vary based on operational needs, and evaluators typically work on short-term contracts that can be renewed but generally do not last indefinitely.
Search Quality Evaluators use two primary rating systems: Page Quality (PQ) ratings that assess how well a page achieves its purpose on a scale from Lowest to Highest quality, and Needs Met (NM) ratings that evaluate how well a result satisfies user intent on a scale from Fails to Meet to Fully Meets. These ratings help Google understand whether its search results are meeting user expectations and delivering authoritative, trustworthy content.
YMYL stands for 'Your Money or Your Life' and refers to topics that could significantly impact a person's health, financial stability, safety, or well-being. Pages on YMYL topics receive stricter quality evaluation standards because inaccurate or untrustworthy information could cause real harm. Examples include medical advice, financial guidance, legal information, and civic information. Evaluators apply higher E-E-A-T standards and require stronger evidence of expertise for YMYL content.
As of January 2025, Google's guidelines direct evaluators to rate pages with main content created using automated or generative AI tools as Lowest quality if the content lacks effort, originality, and added value. Evaluators look for indicators of AI generation such as paraphrased content with minimal changes, generic language patterns, or phrases like 'As an AI language model.' However, AI tools used with significant human effort and original additions may not receive the lowest rating.
Search Quality Evaluators must pass a comprehensive test on Google's Search Quality Rater Guidelines before they can begin work. These guidelines are over 160 pages long and cover detailed criteria for assessing page quality, understanding user intent, evaluating E-E-A-T, identifying spam and harmful content, and rating search result relevance. Evaluators must demonstrate proficiency in their task language and locale to accurately represent local users' needs and cultural standards.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Learn about Google's Quality Rater Guidelines, the evaluation framework used by 16,000+ raters to assess search quality, E-E-A-T signals, and how they influence...

Page Quality Rating is Google's assessment framework evaluating webpage quality through E-E-A-T, content originality, and user satisfaction. Learn the rating sc...
Understand E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) and its critical importance for visibility in AI search engines like ChatGPT, Per...