
What is Semantic Search for AI? How It Works and Why It Matters
Learn how semantic search uses AI to understand user intent and context. Discover how it differs from keyword search and why it's essential for modern AI system...
12 min read

Semantic search is an AI-powered search technique that understands the meaning and context of a query rather than relying solely on keyword matching. It uses natural language processing and machine learning to interpret user intent and deliver results based on conceptual relevance rather than exact word matches.
Semantic search is an AI-powered search technique that understands the meaning and context of a query rather than relying solely on keyword matching. It uses natural language processing and machine learning to interpret user intent and deliver results based on conceptual relevance rather than exact word matches.
Semantic search is an AI-powered search technique that interprets the meaning and context of a query rather than relying solely on keyword matching. Unlike traditional search engines that return results based on exact word matches, semantic search uses natural language processing (NLP) and machine learning to understand what users are actually looking for, delivering results based on conceptual relevance and user intent. This fundamental shift from lexical matching to semantic understanding represents one of the most significant advances in information retrieval technology, enabling search systems to bridge the gap between how humans think and how computers process information. The technology has become increasingly critical in the AI era, as platforms like ChatGPT, Perplexity, Google AI Overviews, and Claude all rely on semantic search to retrieve and synthesize relevant information from vast knowledge bases.
The concept of semantic understanding in search has evolved significantly over the past two decades. Early search engines relied entirely on keyword matching and inverted indexes, which worked reasonably well for simple queries but failed when users employed synonyms or when documents used different terminology to express the same concepts. The introduction of natural language processing techniques in the early 2000s began to change this landscape, but true semantic search emerged with the development of word embeddings like Word2Vec in 2013 and later transformer models like BERT in 2018. These breakthroughs enabled computers to understand not just individual words, but the relationships between concepts and the context in which words appear. Today, semantic search has become the foundation of modern AI systems and large language models (LLMs), with the global enterprise semantic search software market valued at USD 1.2 billion in 2024 and projected to reach USD 3.5 billion by 2033, representing a CAGR of approximately 11.5%. This explosive growth reflects the recognition by enterprises worldwide that semantic understanding is essential for delivering relevant search experiences in an increasingly complex digital landscape.
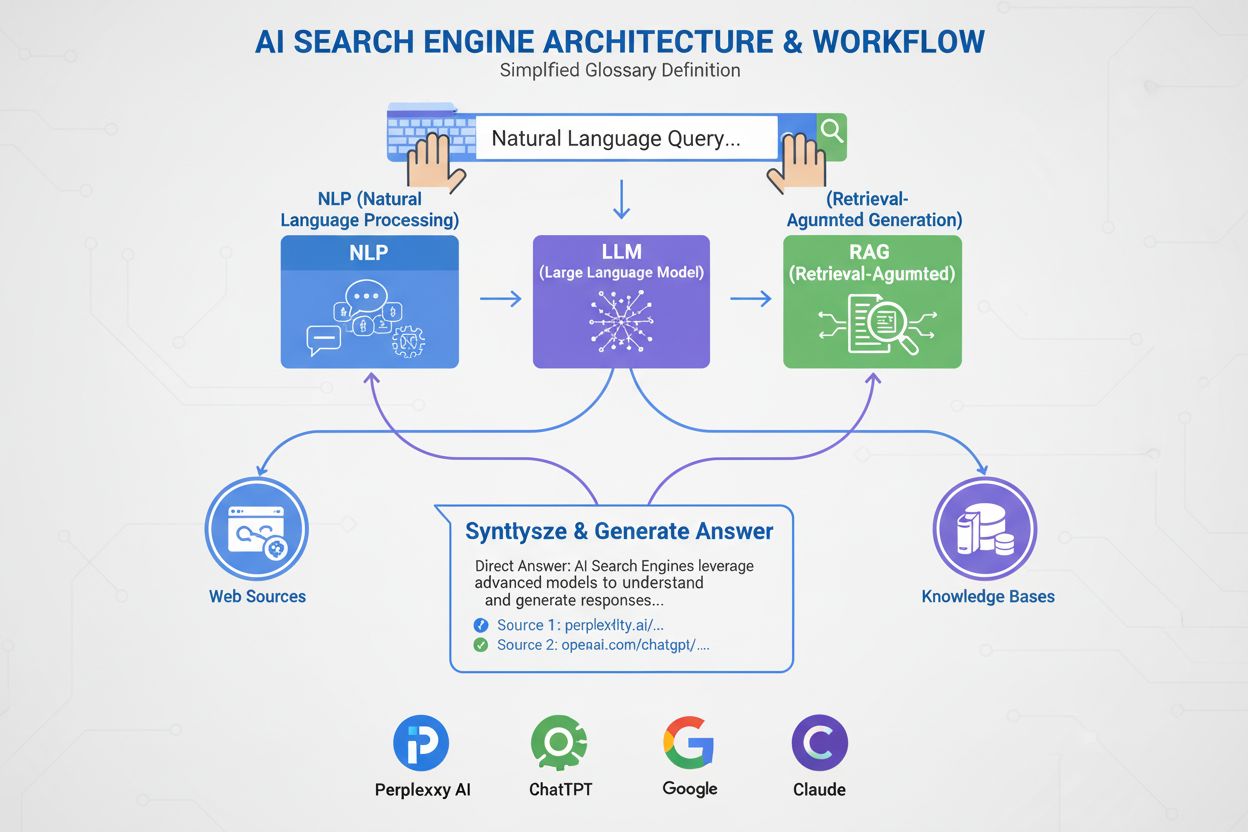
Semantic search operates through a sophisticated multi-step process that transforms both queries and documents into mathematical representations that capture meaning. The process begins when a user submits a search query, which is then analyzed to extract intent and context. The system uses NLP models to understand what the user is actually seeking, not just the literal words they typed. Next, the query is converted into vector embeddings—numerical representations in multi-dimensional space that capture semantic meaning. Simultaneously, documents in the search index have already been converted into embeddings using the same model, ensuring consistency in how meaning is represented. The system then employs the k-nearest neighbor (kNN) algorithm to find documents whose embeddings are mathematically closest to the query embedding. This distance measurement, typically using cosine similarity, identifies content that is conceptually related to the query. Finally, a reranking algorithm evaluates these initial results using additional relevance factors such as user context, search history, and engagement metrics to produce the final ranked list of results presented to the user. This entire process happens in milliseconds, enabling real-time search experiences that feel natural and intuitive.
At the heart of semantic search lies the concept of vector embeddings, which are numerical representations that encode semantic meaning into multi-dimensional space. When a transformer model like BERT or GPT processes text, it generates embeddings—typically vectors with hundreds or thousands of dimensions—where each dimension captures some aspect of the text’s meaning. For example, the sentence-transformers library produces embeddings with 384 dimensions, though production models often use 768 or 1024 dimensions for richer semantic representation. The remarkable property of these embeddings is that semantically similar content produces mathematically similar vectors. If you embed the phrase “heart attack” and the phrase “myocardial infarction,” their vectors will be positioned close together in embedding space, even though they share no common words. This clustering of similar meanings in multi-dimensional space is what enables semantic search to work. When visualized using dimensionality reduction techniques like Principal Component Analysis (PCA), embeddings naturally organize into clusters where documents on similar topics group together. This property allows search systems to find relevant content based on meaning rather than exact keyword matches, fundamentally changing how users interact with information retrieval systems.
| Aspect | Semantic Search | Keyword Search |
|---|---|---|
| Matching Method | Matches meaning and context using vector similarity | Matches exact words or phrases using inverted indexes |
| Technology Foundation | Machine learning models, embeddings, neural networks | Statistical methods like TF-IDF, term frequency analysis |
| Synonym Handling | Automatically understands synonyms and related concepts | Requires explicit synonym mapping or query expansion |
| Ambiguity Resolution | Interprets context to disambiguate homonyms and polysemy | Struggles with ambiguous terms without additional rules |
| Query Flexibility | Handles vague, conversational, and natural language queries | Requires precise keyword formulation for best results |
| Computational Cost | Higher (requires embedding generation and similarity calculations) | Lower (simple index lookups and ranking) |
| Accuracy for Complex Queries | Superior (understands intent and nuance) | Limited (literal word matching only) |
| User Experience | More intuitive, feels like human conversation | Requires users to think like the search engine |
| Implementation Complexity | Complex (requires ML models and vector databases) | Simple (traditional database indexes) |
| Real-World Example | Searching “how to cool a room without AC” returns results about fans, ventilation, and thermal curtains | Returns only pages containing all four words, missing relevant alternatives |
Natural language processing (NLP) is the foundational technology that enables semantic search to understand human language. NLP encompasses multiple techniques that work together to extract meaning from text: tokenization breaks text into smaller units, normalization standardizes text format, and part-of-speech tagging identifies grammatical roles. More importantly, modern NLP uses transformer architectures that can understand context by examining relationships between all words in a sentence simultaneously, rather than processing words sequentially. This contextual understanding is crucial for semantic search because it allows the system to recognize that “bank” means something different in “river bank” versus “savings bank.” The attention mechanism in transformer models enables them to focus on the most relevant parts of text when generating embeddings, ensuring that important semantic information is captured. When a user searches for “best running shoes,” NLP helps the system understand that the user’s intent is to find recommendations and reviews, not just a list of shoes. This semantic understanding of intent is what distinguishes modern search systems from their keyword-based predecessors and is why ChatGPT, Perplexity, and other AI platforms can provide such relevant and contextually appropriate responses to user queries.
The major AI platforms have implemented semantic search in ways that reflect their unique architectures and capabilities. ChatGPT uses semantic search to retrieve relevant information from its training data and from external sources when using plugins, understanding user queries at a deep semantic level to provide contextually appropriate responses. Perplexity has built its entire search paradigm around semantic understanding, using embeddings to find relevant sources and synthesize information in a way that directly addresses user intent. Google AI Overviews (formerly SGE) incorporates semantic search to understand query intent and retrieve the most relevant passages from indexed web content, moving beyond traditional keyword-based ranking. Claude similarly uses semantic understanding to interpret user requests and retrieve relevant context from its knowledge base. These platforms demonstrate that semantic similarity in responses—as measured by research comparing Perplexity and ChatGPT—indicates sophisticated semantic search implementations. The fact that search users convert at rates 2-3x higher than non-search visitors in most industries, with fashion retailers seeing conversion rates as high as 4.2%, demonstrates the real-world impact of semantic search on user satisfaction and business outcomes. For organizations monitoring their presence in these AI systems, understanding how semantic search works is essential for optimizing content visibility.
Semantic search has become transformative in enterprise and eCommerce environments where understanding user intent directly impacts business outcomes. In eCommerce, semantic search enables customers to find products using natural language descriptions rather than exact product names. A customer searching for “comfortable shoes for standing all day” will find relevant results even if the product database uses different terminology like “ergonomic footwear” or “supportive shoes for prolonged standing.” This capability has driven significant improvements in conversion rates and customer satisfaction. In enterprise search, semantic search helps employees find relevant documents, knowledge base articles, and internal resources without needing to know exact terminology or document titles. A legal professional searching for “contract termination clauses” will find relevant documents about “contract dissolution,” “agreement cancellation,” and “termination provisions,” even though these use different vocabulary. Amazon has integrated semantic search across its eCommerce platforms globally, recognizing that understanding customer intent is crucial for driving sales. Other major companies including Microsoft (Bing), IBM’s watsonx, OpenAI, and Anthropic have all invested heavily in semantic search capabilities. Even Elon Musk has expressed interest in adding semantic search functionality to X (formerly Twitter), indicating the technology’s growing importance across diverse platforms and use cases.
Modern semantic search relies on sophisticated machine learning models that have been trained on vast amounts of text data to understand language patterns and semantic relationships. BERT (Bidirectional Encoder Representations from Transformers), released by Google in 2018, revolutionized semantic search by introducing bidirectional context understanding—the model examines words in both directions to understand meaning. GPT models from OpenAI take this further with generative capabilities that enable not just understanding but also reasoning about semantic relationships. The sentence-transformers library provides pre-trained models specifically optimized for semantic similarity tasks, with models like ‘all-MiniLM-L6-v2’ offering a balance between speed and accuracy. These models are trained using contrastive learning, where the system learns to pull semantically similar texts closer together in embedding space while pushing dissimilar texts apart. The training process involves millions of text pairs, allowing the model to learn which words and concepts naturally associate together. Once trained, these models can be applied to new text without additional training, making them practical for real-world applications. The quality of embeddings directly impacts search quality, which is why organizations often experiment with different models to find the best balance between accuracy, speed, and computational cost for their specific use cases.
Vector databases have emerged as essential infrastructure for implementing semantic search at scale. Unlike traditional relational databases optimized for exact matches, vector databases are specifically designed to store and query high-dimensional embeddings efficiently. Milvus, an open-source vector database, offers multiple indexing algorithms including HNSW (Hierarchical Navigable Small World) and FAISS (Facebook AI Similarity Search), enabling fast similarity searches across millions or billions of embeddings. Pinecone provides a managed vector database service that handles the operational complexity of maintaining semantic search infrastructure. Zilliz Cloud, built on Milvus technology, offers enterprise-grade features including disaster recovery, load balancing, and multi-tenant support. Traditional databases have also adapted to support semantic search: PostgreSQL added the pgvector extension for vector operations, and Elasticsearch expanded beyond keyword search to incorporate vector search capabilities. These vector databases enable organizations to implement hybrid search approaches that combine semantic similarity with traditional keyword matching, leveraging the strengths of both methods. The ability to efficiently query embeddings is what makes semantic search practical for production systems handling real-world data volumes and user traffic.
The future of semantic search is being shaped by several emerging trends and technological developments. Multimodal embeddings that can represent text, images, audio, and video in the same embedding space are enabling cross-modal search capabilities—finding images based on text descriptions or vice versa. Instruction-tuned embeddings are being fine-tuned for specific domains and use cases, improving accuracy for specialized applications like legal document search or medical literature retrieval. Quantization techniques are reducing the computational and storage requirements of embeddings, making semantic search more accessible to organizations with limited infrastructure. The integration of semantic search with retrieval-augmented generation (RAG) is enabling AI systems to ground their responses in specific documents and knowledge bases, improving accuracy and reducing hallucinations. As large language models continue to evolve, their semantic understanding capabilities will become increasingly sophisticated, enabling more nuanced interpretation of user intent. For organizations monitoring their presence in AI systems, the evolution of semantic search has profound implications. As AI platforms become more sophisticated in understanding semantic meaning, traditional keyword-based SEO strategies become less effective. Instead, organizations need to focus on creating content that genuinely addresses user intent and provides semantic value. The rise of semantic search also means that content visibility in AI systems like ChatGPT, Perplexity, and Google AI Overviews depends less on keyword optimization and more on content quality, relevance, and semantic alignment with user queries. This represents a fundamental shift in how organizations should approach content strategy and digital visibility in the AI era.
For platforms like AmICited that monitor brand and domain appearances in AI-generated responses, understanding semantic search is crucial. When ChatGPT, Perplexity, Google AI Overviews, or Claude generate responses, they use semantic search to retrieve relevant information from their knowledge bases and indexed content. A domain might appear in AI responses not because it contains exact keyword matches to the user’s query, but because semantic search identified it as semantically relevant to the user’s intent. This means that organizations need to understand how their content is being semantically indexed and retrieved by these AI systems. Content that addresses user intent comprehensively, uses natural language effectively, and demonstrates semantic expertise is more likely to be retrieved by semantic search algorithms. Monitoring semantic search visibility requires different approaches than traditional keyword-based SEO monitoring. Organizations need to track not just exact keyword matches but semantic variations and intent-based queries that might surface their content. The ability to understand which semantic concepts and topics are driving visibility in AI systems enables more strategic content optimization and helps organizations identify opportunities to improve their presence in AI-generated responses.
Semantic search interprets meaning and context using machine learning models to understand user intent, while keyword search matches exact words or phrases in documents. Keyword search uses inverted indexes and statistical methods like TF-IDF, whereas semantic search converts text into vector embeddings where similar meanings cluster together mathematically. This allows semantic search to find relevant content even when exact keywords don't match, such as finding 'myocardial infarction' when searching for 'heart attack.'
Vector embeddings are numerical representations that capture semantic meaning by converting text into multi-dimensional vectors. When both queries and documents are converted to embeddings, the system can measure similarity using distance metrics like cosine similarity. Similar concepts produce vectors that are mathematically close together in embedding space, enabling the search engine to find conceptually related content regardless of exact keyword matches.
Major AI platforms including ChatGPT, Perplexity, Google AI Overviews, and Claude all incorporate semantic search capabilities. These platforms use semantic understanding to interpret user queries and retrieve relevant information from their knowledge bases. Perplexity and ChatGPT demonstrate particularly high semantic similarity in their responses, indicating sophisticated semantic search implementations that understand user intent beyond literal keywords.
The global enterprise semantic search software market was valued at USD 1.2 billion in 2024 and is projected to reach USD 3.5 billion by 2033, representing a compound annual growth rate (CAGR) of approximately 11.5%. This growth reflects increasing enterprise adoption of AI-driven search capabilities, with organizations recognizing the value of semantic understanding for improving user experience and search accuracy across industries.
Semantic search improves user satisfaction by delivering more relevant results that match user intent rather than just keyword matches. In eCommerce, search users convert at rates 2-3x higher than non-search visitors, with fashion retailers seeing conversion rates as high as 4.2%. By understanding what users actually want rather than what they literally typed, semantic search reduces search frustration and increases the likelihood of finding desired content on the first attempt.
Semantic search is powered by transformer-based models like BERT, GPT, and sentence-transformers that generate contextual embeddings. These pre-trained models understand language nuances and relationships between concepts. The sentence-transformers library, for example, uses models like 'all-MiniLM-L6-v2' that convert text into 384-dimensional vectors capturing semantic relationships. These models are trained on millions of text pairs to learn which words and concepts naturally associate together.
Semantic search handles ambiguity by analyzing context and user intent rather than treating words in isolation. For example, when searching for 'Java applications,' the system can distinguish whether the user means the programming language or coffee-related products by examining surrounding context and user behavior patterns. This contextual understanding allows semantic search to return relevant results even when queries contain homonyms or ambiguous terminology that would confuse traditional keyword-based systems.
The k-nearest neighbor (kNN) algorithm is fundamental to semantic search implementation. After converting a query into embeddings, kNN matches the query vector against document vectors to find the k most similar documents. The algorithm measures distance between vectors in embedding space, identifying documents whose vectors are mathematically closest to the query vector. A reranker then evaluates these initial results using additional relevance factors to produce the final ranked list of results.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Learn how semantic search uses AI to understand user intent and context. Discover how it differs from keyword search and why it's essential for modern AI system...
Learn how semantic understanding impacts AI citation accuracy, source attribution, and trustworthiness in AI-generated content. Discover the role of context ana...
Learn what AI search engines are, how they differ from traditional search, and their impact on brand visibility. Explore platforms like Perplexity, ChatGPT, Goo...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.