
How Semantic Understanding Affects AI Citations
Learn how semantic understanding impacts AI citation accuracy, source attribution, and trustworthiness in AI-generated content. Discover the role of context ana...
9 min read

Semantic similarity is a computational metric that measures the meaning-based relatedness between texts by analyzing their conceptual content rather than exact word matches. It uses vector embeddings and mathematical distance metrics to quantify how closely two pieces of text convey similar meanings, enabling AI systems to understand contextual relationships beyond surface-level keyword matching.
Semantic similarity is a computational metric that measures the meaning-based relatedness between texts by analyzing their conceptual content rather than exact word matches. It uses vector embeddings and mathematical distance metrics to quantify how closely two pieces of text convey similar meanings, enabling AI systems to understand contextual relationships beyond surface-level keyword matching.
Semantic similarity is a computational measure that quantifies the meaning-based relatedness between two or more pieces of text by analyzing their conceptual content, contextual relationships, and underlying semantic meaning rather than relying on exact word matches or surface-level keyword overlap. Unlike traditional keyword-based approaches that only identify texts sharing identical vocabulary, semantic similarity uses advanced mathematical models and vector embeddings to understand whether different texts convey equivalent or related meanings, even when expressed using entirely different words or phrasing. This capability has become fundamental to modern artificial intelligence systems, enabling machines to comprehend human language with nuance and contextual awareness. The measurement of semantic similarity typically ranges from -1 to 1 (or 0 to 1 depending on the metric), where higher values indicate greater semantic relatedness between the compared texts.
The concept of measuring semantic relationships in text emerged from early computational linguistics research in the 1960s and 1970s, but practical implementations remained limited until the advent of word embeddings in the 2010s. The introduction of Word2Vec by Google researchers in 2013 revolutionized the field by demonstrating that words could be represented as dense vectors in multidimensional space, where semantic relationships manifested as geometric proximity. This breakthrough enabled researchers to move beyond symbolic representations and leverage the power of neural networks to capture semantic meaning. The subsequent development of GloVe (Global Vectors for Word Representation) by Stanford researchers provided an alternative approach using co-occurrence statistics, while FastText extended these concepts to handle morphologically rich languages and out-of-vocabulary words. The real transformation occurred with the introduction of BERT (Bidirectional Encoder Representations from Transformers) in 2018, which generated contextualized embeddings that understood word meaning based on surrounding context. Today, over 78% of enterprises have adopted AI-driven solutions, with semantic similarity serving as a critical component in content monitoring, brand tracking, and AI response analysis across platforms like ChatGPT, Perplexity, Google AI Overviews, and Claude.
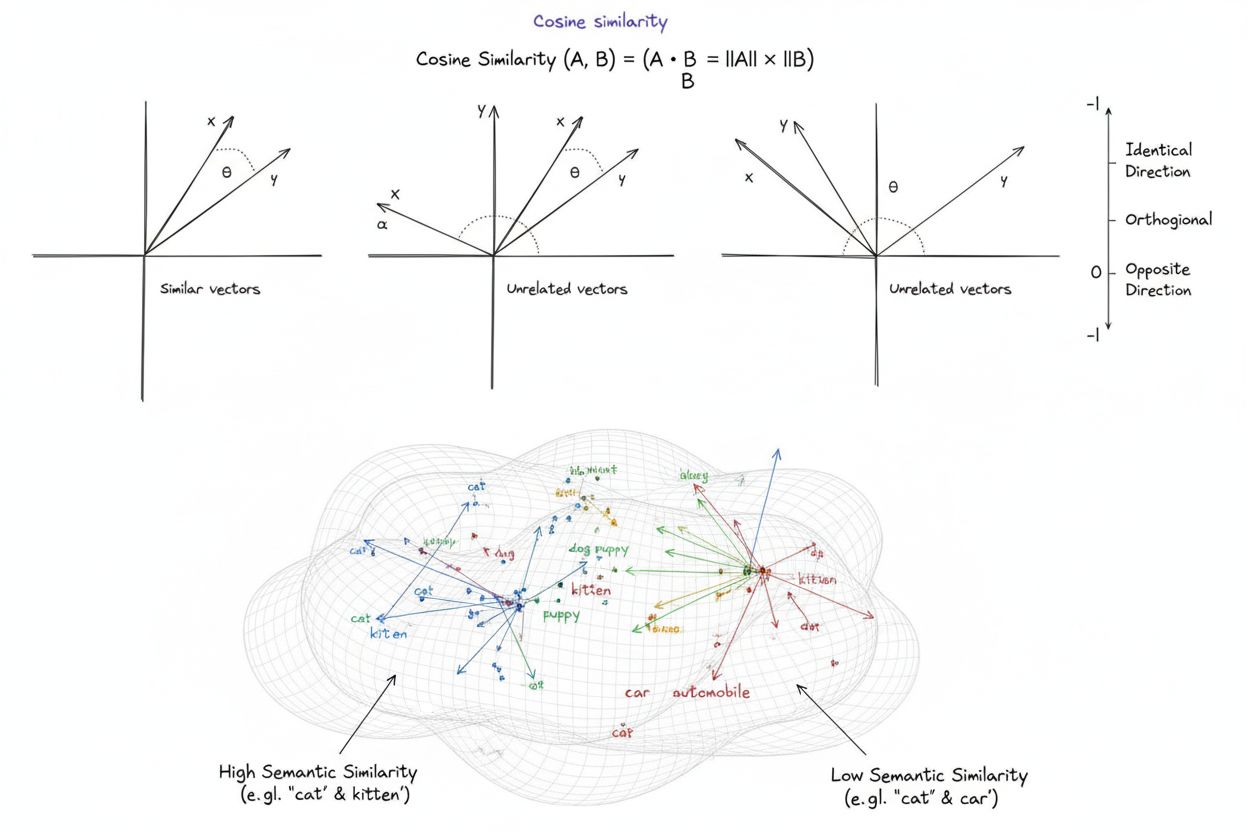
Semantic similarity operates through a multi-stage process that begins with text representation and culminates in numerical similarity scoring. The first stage involves tokenization, where input text is broken into manageable units (words, subwords, or characters) that can be processed by neural networks. These tokens are then converted into embeddings—high-dimensional numerical vectors typically ranging from 300 to 1,536 dimensions—through pre-trained language models. Models like Sentence Transformers and SimCSE (Simple Contrastive Learning of Sentence Embeddings) are specifically designed to generate embeddings where semantic similarity directly correlates with geometric proximity in vector space. Once embeddings are generated, similarity metrics quantify the relationship between vectors. Cosine similarity, the most widely used metric in NLP applications, calculates the angle between two vectors using the formula: cos(θ) = (A · B) / (||A|| × ||B||), where the result ranges from -1 to 1. Euclidean distance measures the straight-line distance between vectors in multidimensional space, while dot product similarity considers both vector direction and magnitude. The choice of metric depends on how the embedding model was trained—using the same metric that trained the model ensures optimal performance. For instance, Sentence Transformers models trained with cosine similarity should use cosine similarity for inference, while models trained with dot product should use dot product scoring.
| Approach/Metric | Dimensionality | Training Method | Best Use Case | Computational Cost | Contextual Awareness |
|---|---|---|---|---|---|
| Word2Vec | 300-600 | Skip-gram/CBOW | Word-level similarity, basic NLP | Low | Limited (static embeddings) |
| GloVe | 300-600 | Co-occurrence matrix factorization | General word embeddings, semantic relationships | Medium | Limited (static embeddings) |
| FastText | 300-600 | Subword n-grams | Morphologically rich languages, OOV words | Low-Medium | Limited (static embeddings) |
| BERT | 768-1024 | Masked language modeling, bidirectional | Token-level tasks, classification | High | High (context-dependent) |
| Sentence Transformers (SBERT) | 384-768 | Siamese networks, triplet loss | Sentence similarity, semantic search | Medium | High (sentence-level) |
| SimCSE | 768 | Contrastive learning | Paraphrase detection, clustering | Medium | High (contrastive) |
| Universal Sentence Encoder | 512 | Multi-task learning | Cross-lingual similarity, quick deployment | Medium | High (sentence-level) |
| Cosine Similarity Metric | N/A | Angle-based | NLP tasks, normalized embeddings | Very Low | N/A (metric only) |
| Euclidean Distance | N/A | Distance-based | Magnitude-sensitive tasks, pixel data | Very Low | N/A (metric only) |
| Dot Product Similarity | N/A | Magnitude & direction | LLM-trained models, ranking tasks | Very Low | N/A (metric only) |
The foundation of semantic similarity rests on the concept of vector embeddings, which transform text into numerical representations that preserve semantic meaning through geometric relationships. When a language model generates embeddings for a collection of texts, semantically similar texts naturally cluster together in the resulting vector space, while dissimilar texts remain distant. This phenomenon, known as semantic clustering, emerges from the training process where models learn to position vectors such that similar meanings occupy nearby regions. Sentence Transformers, for example, generate 384 to 768-dimensional embeddings optimized specifically for sentence-level similarity tasks, enabling them to process over 40,000 sentences per second while maintaining high accuracy. The quality of embeddings directly impacts semantic similarity performance—models trained on diverse, large-scale datasets produce more robust embeddings that generalize well across different domains and text types. The anisotropy problem in BERT’s embeddings (where sentence embeddings collapse into narrow cones, making cosine similarity poorly discriminative) was solved by Sentence Transformers, which fine-tune transformer models using contrastive and triplet losses that explicitly optimize for semantic similarity. This reshaping of vector space ensures that paraphrases cluster tightly (similarity scores above 0.9) while unrelated sentences separate clearly (similarity scores below 0.3), making the embeddings reliable for practical applications.
Semantic similarity has become indispensable for AI monitoring platforms that track brand mentions, content attribution, and URL appearances across multiple AI systems including ChatGPT, Perplexity, Google AI Overviews, and Claude. Traditional keyword-based monitoring fails to detect paraphrased references, contextually related mentions, or meaning-equivalent citations—gaps that semantic similarity fills perfectly. When a user queries an AI system about a topic related to your brand, the AI may generate responses that reference your content, competitors, or industry insights without using exact brand names or URLs. Semantic similarity algorithms enable monitoring platforms to identify these implicit references by comparing the semantic content of AI responses against your brand’s known content, messaging, and positioning. For example, if your brand is known for “sustainable technology solutions,” semantic similarity can detect when an AI response discusses “eco-friendly tech innovations” or “environmentally conscious computing,” recognizing these as semantically equivalent to your brand positioning. This capability extends to duplicate content detection, where semantic similarity identifies near-duplicates and paraphrased versions of your content across AI platforms, helping enforce content attribution and intellectual property protection. Enterprise adoption of semantic similarity-based monitoring has accelerated significantly, with vector database technology (which underpins semantic similarity at scale) experiencing 377% growth in production deployments in 2024 alone.
Semantic similarity has revolutionized plagiarism detection and duplicate content identification by moving beyond surface-level text matching to analyze underlying meaning. Traditional plagiarism detection systems rely on string matching or n-gram analysis, which fail when content is paraphrased, restructured, or translated. Semantic similarity-based approaches overcome these limitations by comparing the conceptual content of documents, enabling detection of plagiarism even when the original text has been substantially reworded. Systems using Word2Vec embeddings can identify semantically similar passages by converting documents into vector representations and computing similarity scores across all document pairs. More advanced systems leverage Sentence Transformers or SimCSE to perform fine-grained similarity analysis at the sentence or paragraph level, identifying which specific sections of a document are plagiarized or duplicated. Research demonstrates that semantic similarity-based plagiarism detection achieves significantly higher accuracy than keyword-based methods, particularly for detecting sophisticated plagiarism involving paraphrasing, synonym substitution, and structural reorganization. In the context of AI monitoring, semantic similarity enables detection of content that has been paraphrased or summarized by AI systems, helping brands identify when their intellectual property is being cited or referenced without proper attribution. The ability to detect semantic equivalence rather than exact matches is particularly valuable in identifying near-duplicate content across multiple AI platforms, where the same information may be expressed differently depending on the AI system’s training data and generation process.
The selection of an appropriate similarity metric is crucial for semantic similarity applications, as different metrics emphasize different aspects of vector relationships. Cosine similarity, calculated as the cosine of the angle between two vectors, is the dominant metric in NLP applications because it measures directional similarity independent of vector magnitude. This property makes cosine similarity ideal for comparing normalized embeddings, where the magnitude carries no semantic information. Cosine similarity values range from -1 (opposite directions) to 1 (identical directions), with 0 indicating orthogonal vectors. In practice, cosine similarity scores above 0.7 typically indicate strong semantic similarity, while scores below 0.3 suggest minimal semantic relationship. Euclidean distance, the straight-line distance between vectors in multidimensional space, is more appropriate when vector magnitude carries semantic significance—for example, in recommendation systems where the magnitude of a user preference vector indicates intensity of interest. Dot product similarity combines both direction and magnitude, making it suitable for models trained with dot product loss functions, particularly large language models. The Manhattan distance (sum of absolute differences) provides a computationally efficient alternative to Euclidean distance, though it’s less commonly used in semantic similarity tasks. Research shows that matching the similarity metric to the training method of the embedding model is critical—using cosine similarity with a model trained on dot product loss, or vice versa, significantly degrades performance. This principle is so fundamental that it’s encoded in the configuration files of pre-trained models, ensuring users apply the correct metric automatically.
Semantic similarity powers modern recommendation systems by enabling algorithms to identify items with similar semantic content, user preferences, or contextual relevance. Unlike collaborative filtering approaches that rely on user behavior patterns, semantic similarity-based recommendations analyze the actual content of items—product descriptions, article text, user reviews—to identify semantically related recommendations. For instance, a news recommendation system using semantic similarity can suggest articles with similar themes, perspectives, or topics, even if they don’t share keywords or categories. This approach significantly improves recommendation quality and enables cold-start recommendations for new items that lack user interaction history. In information retrieval, semantic similarity enables semantic search, where search engines understand the meaning of user queries and retrieve documents based on conceptual relevance rather than keyword matching. A user searching for “best places to visit in summer” receives results about popular summer destinations, not just documents containing those exact words. Semantic search has become increasingly important as AI systems like Perplexity and Google AI Overviews prioritize meaning-based retrieval over keyword matching. The implementation of semantic search typically involves encoding all documents in a corpus into embeddings (a one-time preprocessing step), then encoding user queries and computing similarity scores against the document embeddings. This approach enables fast, scalable retrieval even across millions of documents, making semantic similarity practical for large-scale applications. Vector databases like Pinecone, Weaviate, and Milvus have emerged to optimize storage and retrieval of embeddings at scale, with the vector database market projected to reach $17.91 billion by 2034.
Implementing semantic similarity at enterprise scale requires careful consideration of model selection, infrastructure, and evaluation methodology. Organizations must choose between pre-trained models (which offer quick deployment but may not capture domain-specific semantics) and fine-tuned models (which require labeled data but achieve superior performance on specific tasks). Sentence Transformers provides an extensive library of pre-trained models optimized for different use cases—semantic similarity, semantic search, paraphrase detection, and clustering—enabling organizations to select models matched to their specific requirements. For AI monitoring and brand tracking, organizations typically employ specialized models trained on large, diverse corpora to ensure robust detection of paraphrased content and contextually related mentions across different AI platforms. The infrastructure for semantic similarity at scale involves vector databases that efficiently store and query high-dimensional embeddings, enabling similarity searches across millions or billions of documents in milliseconds. Organizations must also establish evaluation frameworks that measure semantic similarity model performance on domain-specific tasks. For brand monitoring applications, this involves creating test sets of known brand mentions (exact, paraphrased, and contextually related) and measuring the model’s ability to detect them while minimizing false positives. Batch processing pipelines that regularly re-encode documents and update similarity indices ensure that semantic similarity systems remain current as new content is published. Additionally, organizations should implement monitoring and alerting systems that track semantic similarity scores over time, identifying anomalies or shifts in how their brand is discussed across AI platforms.
The field of semantic similarity is rapidly evolving, with several emerging trends reshaping how meaning-based relatedness is measured and applied. Multimodal semantic similarity, which extends semantic similarity beyond text to include images, audio, and video, is gaining prominence as AI systems increasingly process diverse content types. Models like CLIP (Contrastive Language-Image Pre-training) enable semantic similarity comparisons between text and images, opening new possibilities for cross-modal search and content matching. Domain-specific embeddings are becoming increasingly important, as general-purpose models may not capture specialized terminology or concepts in fields like medicine, law, or finance. Organizations are fine-tuning embedding models on domain-specific corpora to improve semantic similarity performance on specialized tasks. Efficient embeddings represent another frontier, with research focused on reducing embedding dimensionality without sacrificing semantic quality—enabling faster inference and lower storage costs. Matryoshka embeddings, which generate embeddings that maintain semantic quality across different dimensionalities, exemplify this trend. In the context of AI monitoring, semantic similarity is evolving to handle increasingly sophisticated content variations, including translations, summarizations, and AI-generated paraphrases. As AI systems become more prevalent in generating and distributing content, the ability to detect semantic equivalence becomes critical for content attribution, intellectual property protection, and brand monitoring. The integration of semantic similarity with knowledge graphs and entity recognition is enabling more sophisticated understanding of semantic relationships that go beyond surface-level text similarity. Furthermore, explainability in semantic similarity is becoming increasingly important, with research focused on making similarity decisions interpretable—helping users understand why two texts are considered semantically similar and identifying which specific semantic features drive the similarity score. These advances promise to make semantic similarity more powerful, efficient, and trustworthy for enterprise applications.
Semantic similarity has become essential for analyzing and monitoring AI-generated responses across platforms like ChatGPT, Perplexity, Google AI Overviews, and Claude. When these systems generate answers to user queries, they often paraphrase, summarize, or recontextualize information from their training data or retrieved sources. Semantic similarity algorithms enable platforms to identify which source documents or concepts influenced specific AI responses, even when the AI has substantially reworded the content. This capability is particularly valuable for content attribution tracking, where organizations need to understand how their content is being cited or referenced in AI-generated answers. By comparing the semantic content of AI responses against a corpus of known sources, monitoring systems can identify which sources were likely used, estimate the degree of paraphrasing or summarization, and track how frequently specific content appears in AI responses. This information is crucial for brand visibility monitoring, competitive intelligence, and intellectual property protection. Additionally, semantic similarity enables detection of hallucinations in AI responses—cases where the AI generates plausible-sounding but factually incorrect information. By comparing AI responses against verified source documents using semantic similarity, systems can identify responses that diverge significantly from known facts or sources. The sophistication of semantic similarity analysis in AI monitoring continues to advance, with systems now capable of detecting subtle variations in how information is presented, identifying when AI systems combine information from multiple sources, and tracking how concepts evolve as they’re discussed across different AI platforms.
Meaning-Based Understanding: Captures conceptual relationships between texts regardless of vocabulary differences, enabling detection of paraphrased content, synonymous expressions, and contextually equivalent meanings that keyword matching cannot identify.
Scalable Content Matching: Enables efficient comparison of texts at scale through vector embeddings and optimized similarity metrics, making it practical to monitor brand mentions across millions of AI-generated responses in real-time.
Paraphrase and Duplicate Detection: Identifies near-duplicate content, plagiarized passages, and paraphrased references with high accuracy, protecting intellectual property and ensuring proper content attribution across AI platforms.
Cross-Platform Brand Monitoring: Detects how brands, products, and content are referenced across ChatGPT, Perplexity, Google AI Overviews, and Claude, even when mentions are paraphrased or contextually embedded rather than explicitly named.
Improved Search and Retrieval: Powers semantic search engines that understand user intent and retrieve results based on meaning rather than keywords, significantly improving relevance and user satisfaction.
Recommendation System Enhancement: Enables personalized recommendations by identifying semantically similar items, improving engagement and conversion rates in e-commerce, content, and media applications.
Contextual AI Analysis: Facilitates understanding of how AI systems interpret and respond to queries by analyzing semantic relationships between user inputs and AI outputs, enabling better prompt engineering and response evaluation.
Reduced False Positives: Semantic similarity-based monitoring achieves higher precision than keyword-based approaches by understanding context and meaning, reducing alert fatigue from irrelevant matches.
Language and Domain Flexibility: Works across different languages and specialized domains through multilingual and domain-specific embedding models, enabling global brand monitoring and industry-specific content tracking.
Continuous Learning and Adaptation: Embedding models can be fine-tuned on domain-specific data to improve semantic similarity performance on specialized tasks, enabling organizations to customize semantic understanding for their specific needs.
Semantic similarity has evolved from a theoretical concept in computational linguistics to a practical, essential technology powering modern AI systems and enterprise applications. By measuring meaning-based relatedness between texts through vector embeddings and mathematical distance metrics, semantic similarity enables machines to understand human language with unprecedented nuance and contextual awareness. The technology’s applications span from AI monitoring and brand tracking to plagiarism detection, recommendation systems, and semantic search—each leveraging the fundamental principle that semantically related texts cluster together in high-dimensional vector space. As enterprises increasingly rely on AI platforms like ChatGPT, Perplexity, Google AI Overviews, and Claude, the ability to monitor and understand how content appears in AI-generated responses becomes critical. Semantic similarity provides the technical foundation for this monitoring, enabling organizations to track brand visibility, protect intellectual property, and understand competitive positioning in the AI era. The rapid advancement of embedding models, the emergence of specialized vector databases, and the growing adoption of semantic similarity across industries signal that this technology will remain central to AI development and enterprise intelligence for years to come. Understanding semantic similarity is no longer optional for organizations seeking to leverage AI effectively—it’s a fundamental requirement for navigating the AI-driven information landscape.
Keyword matching identifies texts that share the same words, while semantic similarity understands meaning regardless of vocabulary differences. For example, 'I love programming' and 'Coding is my passion' have zero keyword overlap but high semantic similarity. Semantic similarity uses embeddings to capture contextual meaning, making it far more effective for understanding intent in AI monitoring, content matching, and brand tracking applications where paraphrased content must be detected.
Vector embeddings convert text into high-dimensional numerical arrays where semantically similar texts cluster together in vector space. Models like BERT and Sentence Transformers generate these embeddings through neural networks trained on large text corpora. The proximity of vectors in this space directly correlates with semantic similarity, allowing algorithms to compute similarity scores using distance metrics like cosine similarity, which measures the angle between vectors rather than their magnitude.
The three primary metrics are cosine similarity (measures angle between vectors, range -1 to 1), Euclidean distance (straight-line distance in multidimensional space), and dot product similarity (considers both direction and magnitude). Cosine similarity is most popular for NLP tasks because it's scale-invariant and focuses on direction rather than magnitude. The choice of metric depends on how the embedding model was trained—matching the training metric ensures optimal performance in applications like AI content monitoring and duplicate detection.
AI monitoring platforms use semantic similarity to detect when brand mentions, content, or URLs appear in AI-generated responses across ChatGPT, Perplexity, Google AI Overviews, and Claude. Rather than searching for exact brand names, semantic similarity identifies paraphrased references, contextually related content, and meaning-equivalent mentions. This enables brands to track how their content is cited, discover competitive positioning in AI responses, and monitor content attribution across multiple AI platforms with high accuracy.
Transformer models like BERT generate contextualized embeddings that understand word meaning based on surrounding context, not just isolated definitions. BERT processes text bidirectionally, capturing nuanced semantic relationships. However, BERT's sentence-level embeddings suffer from anisotropy (clustering into narrow cones), making Sentence Transformers and specialized models like SimCSE more effective for sentence-level similarity tasks. These fine-tuned models explicitly optimize for semantic similarity, producing embeddings where cosine similarity reliably reflects true semantic relationships.
Semantic similarity powers recommendation systems (suggesting similar products or content), plagiarism detection (identifying paraphrased content), duplicate detection (finding near-duplicate documents), semantic search (retrieving results by meaning not keywords), question-answering systems (matching queries to relevant answers), and clustering (grouping similar documents). In enterprise contexts, it enables content governance, compliance monitoring, and intelligent information retrieval. The global vector database market, which underpins semantic similarity applications, is projected to reach $17.91 billion by 2034, growing at 24% CAGR.
Semantic similarity models are evaluated using benchmark datasets like STS Benchmark, SICK, and SemEval, which contain sentence pairs with human-annotated similarity scores. Evaluation metrics include Spearman correlation (comparing model scores to human judgments), Pearson correlation, and task-specific metrics like Mean Reciprocal Rank for retrieval tasks. Enterprise AI monitoring platforms evaluate models on their ability to detect paraphrased brand mentions, identify content variations, and maintain low false-positive rates when tracking domain appearances across multiple AI systems.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Learn how semantic understanding impacts AI citation accuracy, source attribution, and trustworthiness in AI-generated content. Discover the role of context ana...
Cosine similarity is a mathematical metric measuring vector alignment by calculating the cosine of the angle between them. Essential for AI, NLP, semantic searc...
Learn how semantic clustering groups data by meaning and context using NLP and machine learning. Discover techniques, applications, and tools for AI-powered dat...