
Training Data
Training data is the dataset used to teach ML models patterns and relationships. Learn how quality training data impacts AI model performance, accuracy, and rea...
11 min read

Synthetic data training is the process of training AI models using artificially generated data rather than real-world human-created information. This approach addresses data scarcity, accelerates model development, and preserves privacy while introducing challenges like model collapse and hallucinations that require careful management and validation.
Synthetic data training is the process of training AI models using artificially generated data rather than real-world human-created information. This approach addresses data scarcity, accelerates model development, and preserves privacy while introducing challenges like model collapse and hallucinations that require careful management and validation.
Synthetic data training refers to the process of training artificial intelligence models using artificially generated data rather than real-world human-created information. Unlike traditional AI training that relies on authentic datasets collected from surveys, observations, or web mining, synthetic data is created through algorithms and computational methods that learn statistical patterns from existing data or generate entirely new data from scratch. This fundamental shift in training methodology addresses a critical challenge in modern AI development: the exponential growth in computational demands has outpaced humanity’s ability to generate sufficient real data, with research indicating that human-generated training data could be exhausted within the next several years. Synthetic data training offers a scalable, cost-effective alternative that can be generated infinitely without the time-consuming processes of data collection, labeling, and cleaning that consume up to 80% of traditional AI development timelines.
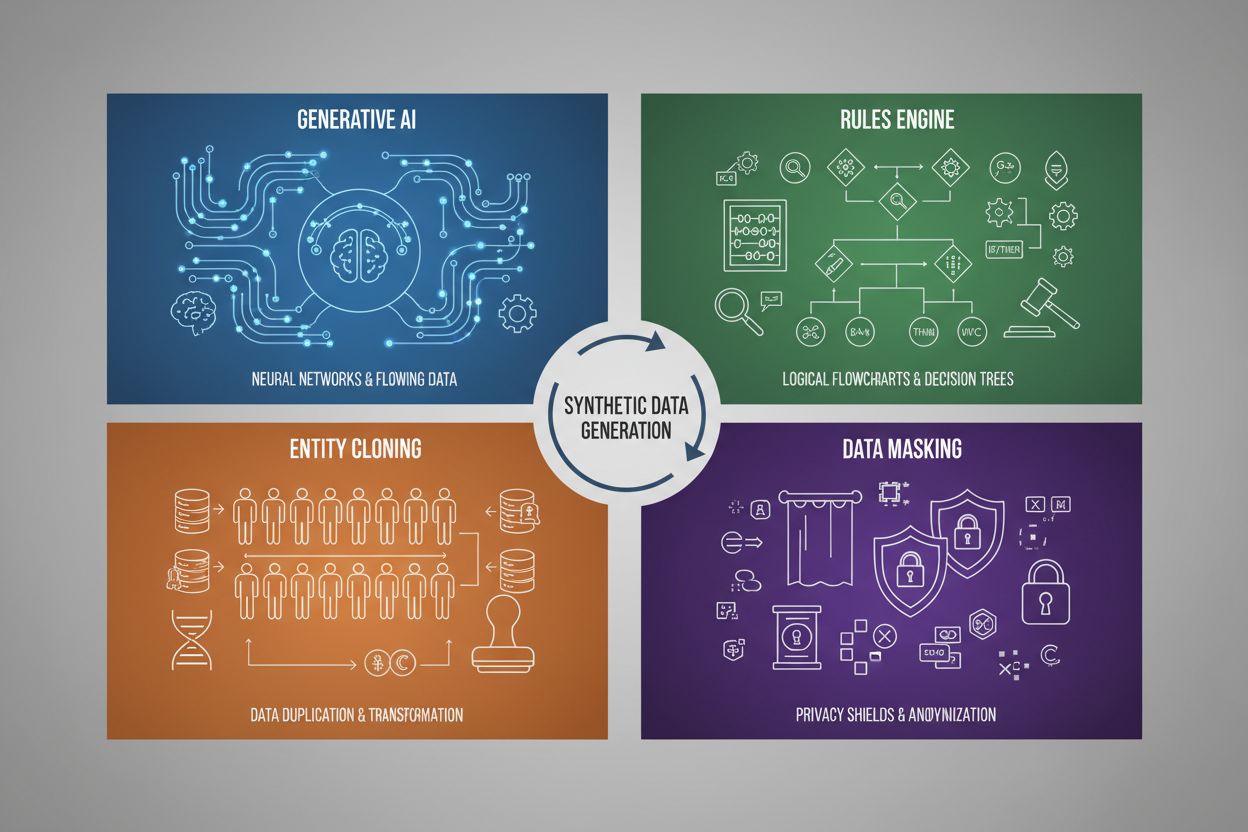
Synthetic data generation employs four primary techniques, each with distinct mechanisms and applications:
| Technique | How It Works | Use Case |
|---|---|---|
| Generative AI (GANs, VAEs, GPT) | Uses deep learning models to learn statistical patterns and distributions from real data, then generates new synthetic samples that maintain the same statistical properties and relationships. GANs employ adversarial networks where a generator creates fake data while a discriminator evaluates authenticity, creating increasingly realistic outputs. | Training large language models like ChatGPT, generating synthetic images with DALL-E, creating diverse text datasets for natural language processing tasks |
| Rules Engine | Applies predefined logical rules and constraints to generate data that follows specific business logic, domain knowledge, or regulatory requirements. This deterministic approach ensures generated data adheres to known patterns and relationships without requiring machine learning. | Financial transaction data, healthcare records with specific compliance requirements, manufacturing sensor data with known operational parameters |
| Entity Cloning | Duplicates and modifies existing real data records by applying transformations, perturbations, or variations to create new instances while preserving core statistical properties and relationships. This technique maintains data authenticity while expanding dataset size. | Expanding limited datasets in regulated industries, creating training data for rare disease diagnosis, augmenting datasets with insufficient minority class examples |
| Data Masking & Anonymization | Obscures sensitive personally identifiable information (PII) while preserving data structure and statistical relationships through techniques like tokenization, encryption, or value substitution. This creates privacy-preserving synthetic versions of real data. | Healthcare and financial datasets, customer behavioral data, personally sensitive information in research contexts |
Synthetic data training delivers substantial cost reductions by eliminating expensive data collection, annotation, and cleaning processes that traditionally consume significant resources and time. Organizations can generate unlimited training samples on-demand, dramatically accelerating model development cycles and enabling rapid iteration and experimentation without waiting for real-world data collection. The technique provides powerful data augmentation capabilities, allowing developers to expand limited datasets and create balanced training sets that address class imbalance problems—a critical issue where certain categories are underrepresented in real data. Synthetic data proves particularly valuable for addressing data scarcity in specialized domains such as medical imaging, rare disease diagnosis, or autonomous vehicle testing, where collecting sufficient real-world examples is prohibitively expensive or ethically challenging. Privacy preservation represents a major advantage, as synthetic data can be generated without exposing sensitive personal information, making it ideal for training models on healthcare records, financial data, or other regulated information. Additionally, synthetic data enables systematic bias reduction by allowing developers to intentionally create balanced, diverse datasets that counteract discriminatory patterns present in real-world data—for example, generating diverse demographic representations in training images to prevent AI models from perpetuating gender or racial stereotypes in hiring, lending, or criminal justice applications.
Despite its promise, synthetic data training introduces significant technical and practical challenges that can undermine model performance if not carefully managed. The most critical concern is model collapse, a phenomenon where AI models trained extensively on synthetic data experience severe degradation in output quality, accuracy, and coherence. This occurs because synthetic data, while statistically similar to real data, lacks the nuanced complexity and edge cases present in authentic human-generated information—when models train on AI-generated content, they begin amplifying errors and artifacts, creating a compounding problem where each generation of synthetic data becomes progressively lower quality.
Key challenges include:
These challenges underscore why synthetic data alone cannot replace real data—instead, it must be carefully integrated as a supplement to authentic datasets, with rigorous quality assurance and human oversight throughout the training process.
As synthetic data becomes increasingly prevalent in AI model training, brands face a critical new challenge: ensuring accurate and favorable representation in AI-generated outputs and citations. When large language models and generative AI systems train on synthetic data, the quality and characteristics of that synthetic data directly influence how brands are described, recommended, and cited in AI search results, chatbot responses, and automated content generation. This creates a significant brand safety concern, as synthetic data that contains outdated information, competitor bias, or inaccurate brand descriptions can become embedded in AI models, leading to persistent misrepresentation across millions of user interactions. For organizations using platforms like AmICited.com to monitor their brand presence in AI systems, understanding the role of synthetic data in model training becomes essential—brands need visibility into whether AI citations and mentions originate from real training data or synthetic sources, as this affects credibility and accuracy. The transparency gap around synthetic data usage in AI training creates accountability challenges: companies cannot easily determine whether their brand information has been accurately represented in synthetic datasets used to train models that influence consumer perception. Forward-thinking brands should prioritize AI monitoring and citation tracking to detect misrepresentations early, advocate for transparency standards requiring disclosure of synthetic data usage in AI training, and work with platforms that provide insights into how their brand appears across AI systems trained on both real and synthetic data. As synthetic data becomes the dominant training paradigm by 2030, brand monitoring will shift from traditional media tracking to comprehensive AI citation intelligence, making platforms that track brand representation across generative AI systems indispensable for protecting brand integrity and ensuring accurate brand voice in the AI-driven information ecosystem.
Traditional AI training relies on real-world data collected from humans through surveys, observations, or web mining, which is time-consuming and increasingly scarce. Synthetic data training uses artificially generated data created by algorithms that learn statistical patterns from existing data or generate entirely new data from scratch. Synthetic data can be produced infinitely on-demand, dramatically reducing development time and costs while addressing privacy concerns.
The four primary techniques are: 1) Generative AI (using GANs, VAEs, or GPT models to learn and replicate data patterns), 2) Rules Engine (applying predefined business logic and constraints), 3) Entity Cloning (duplicating and modifying existing records while preserving statistical properties), and 4) Data Masking (anonymizing sensitive information while maintaining data structure). Each technique serves different use cases and has distinct advantages.
Model collapse occurs when AI models trained extensively on synthetic data experience severe degradation in output quality and accuracy. This happens because synthetic data, while statistically similar to real data, lacks the nuanced complexity and edge cases of authentic information. When models train on AI-generated content, they amplify errors and artifacts, creating a compounding problem where each generation becomes progressively lower quality, eventually producing unusable outputs.
When AI models train on synthetic data, the quality and characteristics of that synthetic data directly influence how brands are described, recommended, and cited in AI outputs. Poor-quality synthetic data containing outdated information or competitor bias can become embedded in AI models, leading to persistent brand misrepresentation across millions of user interactions. This creates a brand safety concern requiring monitoring and transparency about synthetic data usage in AI training.
No, synthetic data should supplement rather than replace real data. While synthetic data offers significant advantages in cost, speed, and privacy, it cannot fully replicate the complexity, diversity, and edge cases found in authentic human-generated data. The most effective approach combines synthetic and real data, with rigorous quality assurance and human oversight to ensure model accuracy and reliability.
Synthetic data provides superior privacy protection because it contains no actual values from original datasets and has no one-to-one relationships with real individuals. Unlike traditional data masking or anonymization techniques that can still pose re-identification risks, synthetic data is created entirely from scratch based on learned patterns. This makes it ideal for training models on sensitive information like healthcare records, financial data, or personal behavioral information without exposing real individuals' data.
Synthetic data enables systematic bias reduction by allowing developers to intentionally create balanced, diverse datasets that counteract discriminatory patterns in real-world data. For example, developers can generate diverse demographic representations in training images to prevent AI models from perpetuating gender or racial stereotypes. This capability is particularly valuable in applications like hiring, lending, and criminal justice where bias can have serious consequences.
As synthetic data becomes the dominant training paradigm by 2030, brands must understand how their information is represented in AI systems. Synthetic data quality directly affects brand citations and mentions in AI outputs. Brands should monitor their presence across AI systems, advocate for transparency standards requiring disclosure of synthetic data usage, and use platforms like AmICited.com to track brand representation and detect misrepresentations early.
Discover how your brand is represented across AI systems trained on synthetic data. Track citations, monitor accuracy, and ensure brand safety in the AI-driven information ecosystem.
Training data is the dataset used to teach ML models patterns and relationships. Learn how quality training data impacts AI model performance, accuracy, and rea...
Learn what AI-generated images are, how they're created using diffusion models and neural networks, their applications in marketing and design, and the ethical ...

Complete guide to opting out of AI training data collection across ChatGPT, Perplexity, LinkedIn, and other platforms. Learn step-by-step instructions to protec...