Attention Mechanism
Attention mechanism is a machine learning technique that directs deep learning models to prioritize relevant input data parts. Learn how it powers transformers,...
10 min read

A neural network architecture based on multi-head self-attention mechanisms that processes sequential data in parallel, enabling the development of modern large language models like ChatGPT, Claude, and Perplexity. Introduced in the 2017 paper ‘Attention is All You Need,’ transformers have become the foundational technology underlying virtually all state-of-the-art AI systems.
A neural network architecture based on multi-head self-attention mechanisms that processes sequential data in parallel, enabling the development of modern large language models like ChatGPT, Claude, and Perplexity. Introduced in the 2017 paper 'Attention is All You Need,' transformers have become the foundational technology underlying virtually all state-of-the-art AI systems.
Transformer Architecture is a revolutionary neural network design introduced in the 2017 paper “Attention is All You Need” by researchers at Google. It is fundamentally based on multi-head self-attention mechanisms that enable models to process entire sequences of data in parallel, rather than sequentially. The architecture consists of stacked encoder and decoder layers, each containing self-attention sublayers and feed-forward neural networks, connected through residual connections and layer normalization. Transformer Architecture has become the foundational technology underlying virtually all modern large language models (LLMs), including ChatGPT, Claude, Perplexity, and Google AI Overviews, making it arguably the most important neural network innovation of the past decade.
The significance of Transformer Architecture extends far beyond its technical elegance. The 2017 “Attention is All You Need” paper has been cited over 208,000 times, making it one of the most influential research papers in machine learning history. This architecture fundamentally changed how AI systems process and understand language, enabling the development of models with billions of parameters that can engage in sophisticated reasoning, creative writing, and complex problem-solving. The enterprise LLM market, built almost entirely on transformer technology, was valued at $6.7 billion in 2024 and is projected to grow at a 26.1% compound annual growth rate through 2034, demonstrating the architecture’s critical importance to modern AI infrastructure.
The development of Transformer Architecture represents a pivotal moment in deep learning history, emerging from decades of research into neural networks for sequential data processing. Before transformers, recurrent neural networks (RNNs) and their variants, particularly long short-term memory (LSTM) networks, dominated natural language processing tasks. However, these architectures had fundamental limitations: they processed sequences sequentially, one element at a time, which made them slow to train and struggled to capture dependencies between distant elements in long sequences. The vanishing gradient problem further limited RNNs’ ability to learn from long-range relationships, as gradients would become exponentially smaller as they propagated backward through many layers.
The introduction of attention mechanisms in 2014 by Bahdanau and colleagues provided a breakthrough, allowing models to focus on relevant parts of input sequences regardless of distance. However, attention was initially used as an enhancement to RNNs rather than as a replacement. The 2017 Transformer paper took this concept further, proposing that attention is all you need—that is, an entire neural network architecture could be built using only attention mechanisms and feed-forward layers, eliminating recurrence entirely. This insight proved transformative. By removing sequential processing, transformers enabled massive parallelization, allowing researchers to train on unprecedented amounts of data using GPUs and TPUs. The largest transformer model in the original paper, trained on 8 GPUs for 3.5 days, demonstrated that scale and parallelization could lead to dramatically improved performance.
Following the original transformer paper, the architecture evolved rapidly. BERT (Bidirectional Encoder Representations from Transformers), released by Google in 2019, demonstrated that transformer encoders could be pre-trained on massive text corpora and fine-tuned for diverse downstream tasks. BERT’s largest model contained 345 million parameters and was trained on 64 specialized TPUs for four days at an estimated cost of $7,000, yet it achieved state-of-the-art results across numerous language understanding benchmarks. Simultaneously, OpenAI’s GPT series pursued a different path, using decoder-only transformer architectures trained on language modeling tasks. GPT-2 with 1.5 billion parameters surprised the research community by demonstrating that language modeling alone could produce remarkably capable systems. GPT-3, with 175 billion parameters, showed emergent capabilities—abilities that appeared only at scale, including few-shot learning and complex reasoning—that fundamentally changed expectations about what AI systems could accomplish.
Transformer Architecture comprises several interconnected technical components that work together to enable efficient parallel processing and sophisticated context understanding. The input embedding layer converts discrete tokens (words or subword units) into continuous vector representations, typically of dimension 512 or higher. These embeddings are then augmented with positional encoding, which adds information about each token’s position in the sequence using sine and cosine functions at different frequencies. This positional information is essential because, unlike RNNs that inherently preserve sequence order through their recurrent structure, transformers process all tokens simultaneously and need explicit position signals to understand word order and relative distances.
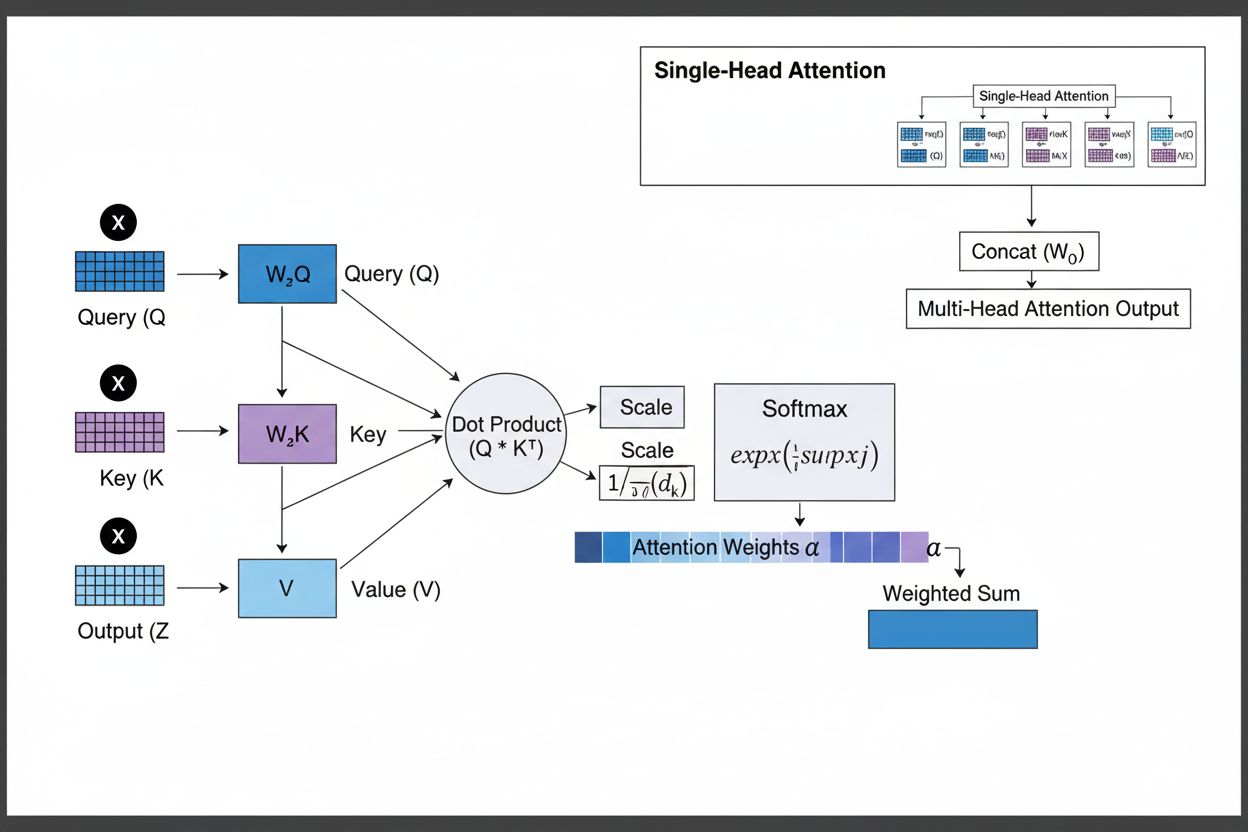
The self-attention mechanism is the architectural innovation that distinguishes transformers from all previous neural network designs. For each token in the input sequence, the model computes three vectors: a Query vector (representing what information the token is seeking), Key vectors (representing what information each token contains), and Value vectors (representing the actual information to be passed along). The attention mechanism computes a similarity score between each token’s Query and all tokens’ Keys using dot products, normalizes these scores using softmax to create attention weights between 0 and 1, and then uses these weights to create a weighted sum of Value vectors. This process allows each token to selectively focus on other relevant tokens, enabling the model to understand context and relationships.
Multi-head attention extends this concept by running multiple parallel attention mechanisms simultaneously, typically 8, 12, or 16 heads. Each head operates on different linear projections of the Query, Key, and Value vectors, allowing the model to attend to different types of relationships and patterns in different representation subspaces. For example, one attention head might focus on syntactic relationships between words, while another focuses on semantic relationships or long-range dependencies. The outputs from all heads are concatenated and linearly transformed, providing the model with rich, multifaceted contextual information. This approach has proven remarkably effective, with research showing that different heads learn to specialize in different linguistic phenomena.
The encoder-decoder structure organizes these attention mechanisms into a hierarchical processing pipeline. The encoder consists of multiple stacked layers (typically 6 or more), each containing a multi-head self-attention sublayer followed by a position-wise feed-forward network. Residual connections around each sublayer allow gradients to flow directly through the network during training, improving stability and enabling deeper architectures. Layer normalization is applied after each sublayer, normalizing activations to maintain consistent scales throughout the network. The decoder has a similar structure but includes an additional encoder-decoder attention layer that allows the decoder to attend to the encoder’s output, enabling the model to focus on relevant parts of the input when generating each output token. In decoder-only architectures like GPT, the decoder generates output tokens autoregressively, with each new token conditioned on all previously generated tokens.
| Aspect | Transformer Architecture | RNN/LSTM | Convolutional Neural Networks (CNN) |
|---|---|---|---|
| Processing Method | Parallel processing of entire sequences using attention | Sequential processing, one element at a time | Local convolution operations on fixed-size windows |
| Long-Range Dependencies | Excellent; attention can directly connect distant tokens | Poor; limited by vanishing gradients and sequential bottleneck | Limited; local receptive field requires many layers |
| Training Speed | Very fast; massive parallelization on GPUs/TPUs | Slow; sequential processing prevents parallelization | Fast for fixed-size inputs; less suitable for variable sequences |
| Memory Requirements | High; quadratic in sequence length due to attention | Lower; linear in sequence length | Moderate; depends on kernel size and depth |
| Scalability | Excellent; scales to billions of parameters | Limited; difficult to train very large models | Good for images; less suitable for sequences |
| Typical Applications | Language modeling, machine translation, text generation | Time series, sequential prediction (less common now) | Image classification, object detection, computer vision |
| Gradient Flow | Stable; residual connections enable deep networks | Problematic; vanishing/exploding gradients | Generally stable; local connections help gradient flow |
| Position Information | Explicit positional encoding required | Implicit through sequential processing | Implicit through spatial structure |
| State-of-the-Art LLMs | GPT, Claude, Llama, Granite, Perplexity | Rarely used in modern LLMs | Not used for language modeling |
The relationship between Transformer Architecture and modern large language models is fundamental and inseparable. Every major LLM released in the past five years—including OpenAI’s GPT-4, Anthropic’s Claude, Meta’s Llama, Google’s Gemini, IBM’s Granite, and Perplexity’s AI models—is built on transformer architecture. The architecture’s ability to scale efficiently with both model size and training data has proven essential for achieving the capabilities that define modern AI systems. When researchers increased model size from millions to billions to hundreds of billions of parameters, transformer architecture’s parallelization and attention mechanisms enabled this scaling without proportional increases in training time.
The autoregressive decoding process used by most modern LLMs is a direct application of transformer decoder architecture. When generating text, these models process the input prompt through the encoder (or in decoder-only models, through the full decoder), then generate output tokens one at a time. Each new token is generated by computing probability distributions over the entire vocabulary using softmax, with the model selecting the highest-probability token (or sampling from the distribution according to temperature settings). This process, repeated hundreds or thousands of times, produces coherent, contextually appropriate text. The self-attention mechanism enables the model to maintain context across the entire generated sequence, allowing it to produce long, coherent passages that maintain consistent themes, characters, and logical flow.
The emergent capabilities observed in large transformer models—abilities that appear only at sufficient scale, such as few-shot learning, chain-of-thought reasoning, and in-context learning—are direct consequences of transformer architecture’s design. The multi-head attention mechanism’s ability to capture diverse relationships, combined with the model’s massive parameter count and training on diverse data, enables these systems to perform tasks they were never explicitly trained on. For example, GPT-3 could perform arithmetic, write code, and answer trivia questions despite being trained only on language modeling. These emergent properties have made transformer-based LLMs the foundation of the modern AI revolution, with applications ranging from conversational AI and content generation to code synthesis and scientific research assistance.
The self-attention mechanism is the architectural innovation that fundamentally distinguishes transformers and explains their superior performance compared to previous approaches. To understand self-attention, consider the challenge of interpreting ambiguous pronouns in language. In the sentence “The trophy doesn’t fit in the suitcase because it is too large,” the pronoun “it” could refer to either the trophy or the suitcase, but context makes clear it refers to the trophy. In the sentence “The trophy doesn’t fit in the suitcase because it is too small,” the same pronoun now refers to the suitcase. A transformer model must learn to resolve such ambiguities by understanding relationships between words.
Self-attention accomplishes this through a mathematically elegant process. For each token in the input sequence, the model computes a Query vector by multiplying the token’s embedding by a learned weight matrix WQ. Similarly, it computes Key vectors (using WK) and Value vectors (using WV) for all tokens. The attention score between a token’s Query and another token’s Key is computed as the dot product of these vectors, normalized by the square root of the key dimension (typically √64 ≈ 8). These raw scores are then passed through a softmax function, which converts them into normalized attention weights that sum to 1. Finally, the output for each token is computed as a weighted sum of all Value vectors, where the weights are the attention scores. This process allows each token to selectively aggregate information from all other tokens, with the weights learned during training to capture meaningful relationships.
The mathematical elegance of self-attention enables efficient computation. The entire process can be expressed as matrix operations: Attention(Q, K, V) = softmax(QK^T / √d_k)V, where Q, K, and V are matrices containing all query, key, and value vectors respectively. This matrix formulation enables GPU acceleration, allowing transformers to process entire sequences in parallel rather than sequentially. A sequence of 512 tokens can be processed in roughly the same time as a single token in an RNN, making transformers orders of magnitude faster to train. This computational efficiency, combined with the attention mechanism’s ability to capture long-range dependencies, explains why transformers have become the dominant architecture for language modeling.
Multi-head attention extends the self-attention mechanism by running multiple parallel attention operations, each learning different aspects of token relationships. In a typical transformer with 8 attention heads, the input embeddings are linearly projected into 8 different representation subspaces, each with its own Query, Key, and Value weight matrices. Each head independently computes attention weights and produces output vectors. These outputs are then concatenated and linearly transformed through a final weight matrix, producing the final multi-head attention output. This architecture allows the model to simultaneously attend to information from different representation subspaces at different positions.
Research analyzing trained transformer models has revealed that different attention heads specialize in different linguistic phenomena. Some heads focus on syntactic relationships, learning to attend to grammatically related words (e.g., verbs attending to their subjects and objects). Other heads focus on semantic relationships, learning to attend to words with related meanings. Still others capture long-range dependencies, attending to words that are far apart in the sequence but semantically related. Some heads even learn to attend primarily to the current token itself, effectively acting as identity operations. This specialization emerges naturally during training without explicit supervision, demonstrating the power of the multi-head architecture to learn diverse, complementary representations.
The number of attention heads is a key architectural hyperparameter. Larger models typically use more heads (16, 32, or even more), allowing them to capture more diverse relationships. However, the total dimensionality of the attention computation is typically held constant, so more heads means lower dimensionality per head. This design choice balances the benefits of multiple representation subspaces against computational efficiency. The multi-head approach has proven so effective that it has become standard in virtually all modern transformer implementations, from BERT and GPT to specialized architectures for vision, audio, and multimodal tasks.
The original transformer architecture, as described in the “Attention is All You Need” paper, uses an encoder-decoder structure optimized for sequence-to-sequence tasks like machine translation. The encoder processes the input sequence and produces a sequence of context-rich representations. Each encoder layer contains two main components: a multi-head self-attention sublayer that allows tokens to attend to other tokens in the input, and a position-wise feed-forward network that applies the same non-linear transformation to each position independently. These sublayers are connected through residual connections (also called skip connections), which add the input to the output of each sublayer. This design choice, inspired by residual networks in computer vision, enables training of very deep networks by allowing gradients to flow directly through the network.
The decoder generates the output sequence one token at a time, using information from both the encoder and previously generated tokens. Each decoder layer contains three main components: a masked self-attention sublayer that allows each token to attend only to previous tokens (preventing the model from “cheating” by looking at future tokens during training), an encoder-decoder attention sublayer that allows decoder tokens to attend to encoder outputs, and a position-wise feed-forward network. The masking in the self-attention sublayer is crucial: it prevents information from flowing from future positions to past positions, ensuring that predictions for position i depend only on known outputs at positions less than i. This autoregressive structure is essential for generating sequences one token at a time.
The encoder-decoder architecture has proven particularly effective for tasks where the input and output have different structures or lengths, such as machine translation (translating from one language to another), summarization (condensing long documents), and question answering (generating answers based on context). However, modern LLMs like GPT use decoder-only architectures, where a single stack of decoder layers processes both the input prompt and generates the output. This simplification reduces model complexity and has proven equally or more effective for language modeling tasks, likely because the model can learn to use self-attention to process input and generate output in a unified manner.
A critical challenge in transformer architecture is representing the order of tokens in a sequence. Unlike RNNs, which inherently preserve sequence order through their recurrent structure, transformers process all tokens in parallel and have no built-in notion of position. Without explicit position information, a transformer would treat the sequence “The cat sat on the mat” identically to “mat the on sat cat The,” which would be catastrophic for language understanding. The solution is positional encoding, which adds position-dependent vectors to token embeddings before processing.
The original transformer paper uses sinusoidal positional encodings, where the position vector for position pos and dimension i is computed as:
These sinusoidal functions create a unique pattern for each position, with different frequencies for different dimensions. The lower frequencies (smaller i) vary slowly with position, capturing long-range positional information, while higher frequencies vary rapidly, capturing fine-grained position details. This design has several advantages: it naturally generalizes to sequences longer than those seen during training, it provides smooth position transitions, and it allows the model to learn relative position relationships. The positional encoding vectors are simply added to the token embeddings before the first attention layer, and the model learns to use this positional information during training.
Alternative positional encoding schemes have been proposed and studied, including relative position representations (which encode distances between tokens rather than absolute positions) and rotary position embeddings (RoPE) (which rotate embedding vectors based on position). These alternatives have shown improvements in certain scenarios, particularly for very long sequences or when fine-tuning on sequences longer than training sequences. The choice of positional encoding can significantly impact model performance, and this remains an active area of research in transformer architecture optimization.
Understanding Transformer Architecture is essential for comprehending how modern AI systems generate responses that appear in platforms like ChatGPT, Claude, Perplexity, and Google AI Overviews. These systems, all built on transformer technology, process user queries through multiple layers of self-attention, enabling them to understand context and generate coherent, relevant responses. When a user asks a question about a brand, product, or domain, the transformer model’s attention mechanisms determine which parts of its training data are most relevant, and the decoder generates a response that may mention or reference that brand.
For organizations using AI monitoring platforms like AmICited, understanding transformer architecture provides crucial context for interpreting how and why brands appear in AI-generated content. The self-attention mechanism’s ability to capture relationships between concepts means that brands mentioned in training data may be associated with specific topics, industries, or use cases. When a user queries an AI system about those topics, the attention mechanism may activate connections to your brand, resulting in mentions in the generated response. The multi-head attention structure means that different aspects of your brand’s presence in training data may be captured by different attention heads, affecting how comprehensively the model understands and represents your brand.
The transformer architecture’s reliance on training data also explains why brand visibility in AI outputs depends heavily on the quality and quantity of your online presence. Models trained on internet text will have richer representations of brands with extensive, high-quality web content, frequent mentions in reputable sources, and strong semantic associations with relevant topics. Organizations seeking to improve their visibility in AI-generated responses should understand that they’re essentially optimizing for inclusion in the training data that future transformer models will learn from. This understanding bridges the gap between traditional SEO (optimizing for search engines) and what might be called “GEO” (Generative Engine Optimization)—optimizing for visibility in AI systems.
Transformer Architecture continues to evolve rapidly, with researchers exploring numerous improvements and variants. Efficient transformers address the quadratic memory complexity of standard attention (which scales with sequence length squared) through techniques like sparse attention, local attention windows, and linear attention approximations. These innovations enable transformers to process much longer sequences, from thousands to millions of tokens, opening possibilities for processing entire documents, codebases, or knowledge bases in a single forward pass. Mixture of Experts (MoE) architectures, used in models like Google’s Switch Transformer, replace dense feed-forward networks with sparse networks where only a subset of parameters are activated for each token, dramatically increasing model capacity without proportional increases in computation.
Multimodal transformers extend the architecture to process and generate multiple data types simultaneously. Vision Transformers (ViTs) apply transformer architecture to images by dividing them into patches and treating patches as tokens, achieving state-of-the-art results on image classification and detection tasks. Multimodal models like GPT-4V and Claude 3 process both text and images using unified transformer architectures, enabling capabilities like image understanding and visual question answering. Audio transformers process speech and music, while video transformers handle temporal sequences of frames. This multimodal capability suggests that transformers may become the universal architecture for all AI tasks, regardless of data modality.
The strategic implications of transformer architecture’s dominance are profound. Organizations building AI systems must understand transformer capabilities and limitations to make informed decisions about model selection, fine-tuning, and deployment. The architecture’s data-hungry nature means that training data quality and diversity are critical competitive advantages. The attention mechanism’s interpretability (compared to other deep learning approaches) creates opportunities for explainable AI and bias detection, though attention weights alone don’t fully explain model behavior. The architecture’s efficiency at scale suggests that larger models will continue to dominate, at least until fundamental breakthroughs in alternative architectures emerge. For brand monitoring and AI visibility, the transformer architecture’s reliance on training data means that long-term brand building and content strategy remain essential for maintaining visibility in AI-generated responses.
The global LLM market, built almost entirely on transformer architecture, is projected to grow from $8.07 billion in 2025 to $84.25 billion by 2033, representing a compound annual growth rate exceeding 30%. This explosive growth reflects the transformative impact of transformer architecture on AI capabilities and applications. As transformers continue to improve and new variants emerge, their role as the foundational technology of modern AI will only deepen, making understanding this architecture essential for anyone working in AI, data science, or digital strategy.
Transformer Architecture processes entire sequences in parallel using self-attention, while RNNs and LSTMs process sequences sequentially, one element at a time. This parallelization makes transformers significantly faster to train and better at capturing long-range dependencies between distant words or tokens. Transformers also avoid the vanishing gradient problem that plagued RNNs, enabling them to learn from much longer sequences effectively.
Self-attention computes three vectors (Query, Key, and Value) for each token in the input sequence. The Query vector from one token is compared against Key vectors of all tokens to determine relevance scores, which are normalized using softmax. These attention weights are then applied to Value vectors to create context-aware representations. This mechanism allows each token to 'attend to' or focus on other relevant tokens in the sequence, enabling the model to understand context and relationships.
The main components include: (1) Input Embeddings and Positional Encoding to represent tokens and their positions, (2) Multi-Head Self-Attention layers that compute attention across multiple representation subspaces, (3) Feed-Forward Neural Networks applied to each position independently, (4) Encoder stack that processes input sequences, (5) Decoder stack that generates output sequences, and (6) Residual connections and Layer Normalization for training stability. These components work together to enable efficient parallel processing and context understanding.
Transformer Architecture excels for LLMs because it enables parallel processing of entire sequences, dramatically reducing training time compared to sequential RNNs. It captures long-range dependencies more effectively through self-attention, allowing models to understand context across entire documents. The architecture also scales efficiently with larger datasets and more parameters, which has proven essential for training models with billions of parameters that demonstrate emergent capabilities.
Multi-head attention runs multiple parallel attention mechanisms (typically 8 or 16 heads) simultaneously, each operating on different representation subspaces. Each head learns to focus on different types of relationships and patterns in the data. The outputs from all heads are concatenated and linearly transformed, allowing the model to capture diverse contextual information. This approach significantly improves the model's ability to understand complex relationships and improves overall performance.
Positional encoding adds information about token positions to input embeddings using sine and cosine functions at different frequencies. Since transformers process all tokens in parallel (unlike sequential RNNs), they need explicit position information to understand word order. The positional encoding vectors are added to token embeddings before processing, allowing the model to learn how position affects meaning and enabling it to generalize to sequences longer than those seen during training.
The encoder processes the input sequence and creates rich contextual representations through multiple layers of self-attention and feed-forward networks. The decoder generates the output sequence one token at a time, using encoder-decoder attention to focus on relevant parts of the input. This structure is particularly useful for sequence-to-sequence tasks like machine translation, but modern LLMs often use decoder-only architectures for text generation tasks.
Transformer Architecture powers the AI systems that generate responses in platforms like ChatGPT, Claude, Perplexity, and Google AI Overviews. Understanding how transformers process and generate text is crucial for AI monitoring platforms like AmICited, which track where brands and domains appear in AI-generated responses. The architecture's ability to understand context and generate coherent text directly affects how brands are mentioned and represented in AI outputs.
Start tracking how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms. Get actionable insights to improve your AI presence.
Attention mechanism is a machine learning technique that directs deep learning models to prioritize relevant input data parts. Learn how it powers transformers,...

GPT-4 is OpenAI's advanced multimodal LLM combining text and image processing. Learn its capabilities, architecture, and impact on AI monitoring and content cit...
Learn about BERT, its architecture, applications, and current relevance. Understand how BERT compares to modern alternatives and why it remains essential for NL...
Cookie Consent
We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.