Audit di Accesso dei Crawler AI: I Bot Giusti Vedono i Tuoi Contenuti?
Scopri come eseguire un audit dell’accesso dei crawler AI al tuo sito web. Scopri quali bot possono vedere i tuoi contenuti e risolvi i blocchi che impediscono la visibilità AI in ChatGPT, Perplexity e altri motori di ricerca AI.
Pubblicato il Jan 3, 2026.Ultima modifica il Jan 3, 2026 alle 3:24 am
Il panorama della ricerca e della scoperta dei contenuti sta cambiando radicalmente. Con strumenti di ricerca alimentati dall’AI come ChatGPT, Perplexity e Google AI Overviews in rapida crescita, la visibilità dei tuoi contenuti ai crawler AI è diventata importante quanto la tradizionale ottimizzazione per i motori di ricerca. Se i bot AI non possono accedere ai tuoi contenuti, il tuo sito diventa invisibile per milioni di utenti che si affidano a queste piattaforme per trovare risposte. La posta in gioco non è mai stata così alta: mentre Google potrebbe tornare a visitare il tuo sito se qualcosa va storto, i crawler AI operano secondo un paradigma diverso—e perdere quel primo crawl critico può significare mesi di visibilità persa e opportunità mancate di citazioni, traffico e autorevolezza del brand.
Come i Crawler AI Si Differenziano dai Bot Tradizionali
I crawler AI operano secondo regole fondamentalmente diverse rispetto ai bot Google e Bing per i quali hai ottimizzato negli anni. La differenza più importante: i crawler AI non eseguono il rendering di JavaScript, quindi i contenuti dinamici caricati tramite script lato client sono per loro invisibili—un netto contrasto rispetto alle capacità avanzate di rendering di Google. Inoltre, i crawler AI visitano i siti con una frequenza molto più alta, a volte 100 volte superiore rispetto ai motori di ricerca tradizionali, creando sia opportunità che sfide per le risorse del server. A differenza del modello di indicizzazione di Google, i crawler AI non mantengono un indice persistente che viene aggiornato; eseguono invece il crawl su richiesta, quando gli utenti interrogano i loro sistemi. Questo significa che non esiste una coda di reindicizzazione, nessuna Search Console per richiedere una nuova scansione e nessuna seconda possibilità se il tuo sito fallisce quella prima impressione. Comprendere queste differenze è essenziale per ottimizzare la tua strategia di contenuto.
Caratteristica
Crawler AI
Bot Tradizionali
Rendering JavaScript
No (solo HTML statico)
Sì (rendering completo)
Frequenza di Crawl
Molto alta (100x+ più frequente)
Moderata (settimanale/mensile)
Capacità di Reindicizzazione
Nessuna (solo su richiesta)
Sì (aggiornamenti continui)
Requisiti di Contenuto
HTML semplice, schema markup
Flessibile (gestisce contenuti dinamici)
Blocco User-Agent
Specifico per bot (GPTBot, ClaudeBot, ecc.)
Generico (Googlebot, Bingbot)
Strategia di Caching
Snapshot a breve termine
Manutenzione indice a lungo termine
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
I tuoi contenuti potrebbero essere invisibili ai crawler AI per motivi a cui non hai mai pensato. Ecco i principali ostacoli che impediscono ai bot AI di accedere e comprendere i tuoi contenuti:
Contenuti fortemente basati su JavaScript: se il tuo sito si affida a JavaScript lato client per visualizzare testo, immagini o dati strutturati, i crawler AI non lo vedranno—elaborano solo HTML statico
Assenza di schema markup: senza dati strutturati adeguati (JSON-LD, microdati), i crawler AI faticano a comprendere contesto, autore, data di pubblicazione e relazioni tra contenuti
Problemi di infrastruttura tecnica: tempi di risposta del server lenti, errori 5xx, catene di reindirizzamenti e scarsi Core Web Vitals possono indurre i crawler ad abbandonare il sito a metà scansione
Contenuti protetti o a pagamento: contenuti dietro login, paywall o CAPTCHA sono completamente inaccessibili ai crawler AI
Regole robots.txt troppo restrittive: bloccare intere directory o user-agent impedisce ai crawler di accedere a contenuti che invece vuoi siano visibili
Blocchi di firewall e sicurezza: regole WAF (Web Application Firewall), blocco IP o rate-limiting possono erroneamente classificare i crawler AI come minacce e bloccarli del tutto
Comprendere robots.txt e le Regole User-Agent
Il tuo file robots.txt è il principale meccanismo per controllare quali bot AI possono accedere ai tuoi contenuti, e opera tramite regole User-Agent specifiche che mirano a singoli crawler. Ogni piattaforma AI utilizza stringhe user-agent distinte—GPTBot di OpenAI, ClaudeBot di Anthropic, PerplexityBot di Perplexity—e puoi consentire o negare ciascuno in modo indipendente. Questo controllo granulare ti permette di decidere quali sistemi AI possono addestrarsi o citare i tuoi contenuti, fondamentale per proteggere informazioni proprietarie o gestire considerazioni competitive. Tuttavia, molti siti bloccano inconsapevolmente i crawler AI tramite regole troppo generiche pensate per bot più vecchi, o non implementano affatto regole adeguate.
Ecco un esempio di configurazione del tuo robots.txt per diversi bot AI:
# Consenti GPTBot di OpenAI
User-agent: GPTBot
Allow: /
# Blocca ClaudeBot di Anthropic
User-agent: ClaudeBot
Disallow: /
# Consenti Perplexity ma limita alcune directory
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# Regola predefinita per tutti gli altri bot
User-agent: *
Allow: /
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
La Prima Impressione è Critica
A differenza di Google, che esegue costantemente crawl e reindicizzazione del tuo sito, i crawler AI operano su base “one-shot”—visitano quando un utente interroga il loro sistema, e se i tuoi contenuti non sono accessibili in quel momento, hai perso l’opportunità. Questa differenza fondamentale significa che il tuo sito deve essere tecnicamente pronto fin dal primo giorno; non c’è periodo di tolleranza, nessuna seconda possibilità per correggere i problemi prima che la visibilità ne risenta. Una cattiva esperienza di primo crawl—dovuta a errori di rendering JavaScript, assenza di schema markup o errori server—può escludere i tuoi contenuti dalle risposte AI per settimane o mesi. Non esiste un’opzione manuale di reindicizzazione, nessun pulsante “Richiedi indicizzazione” in una console, il che rende il monitoraggio e l’ottimizzazione proattivi imprescindibili. La pressione per fare tutto bene al primo tentativo non è mai stata così alta.
Monitoraggio in Tempo Reale vs. Crawl Programmati
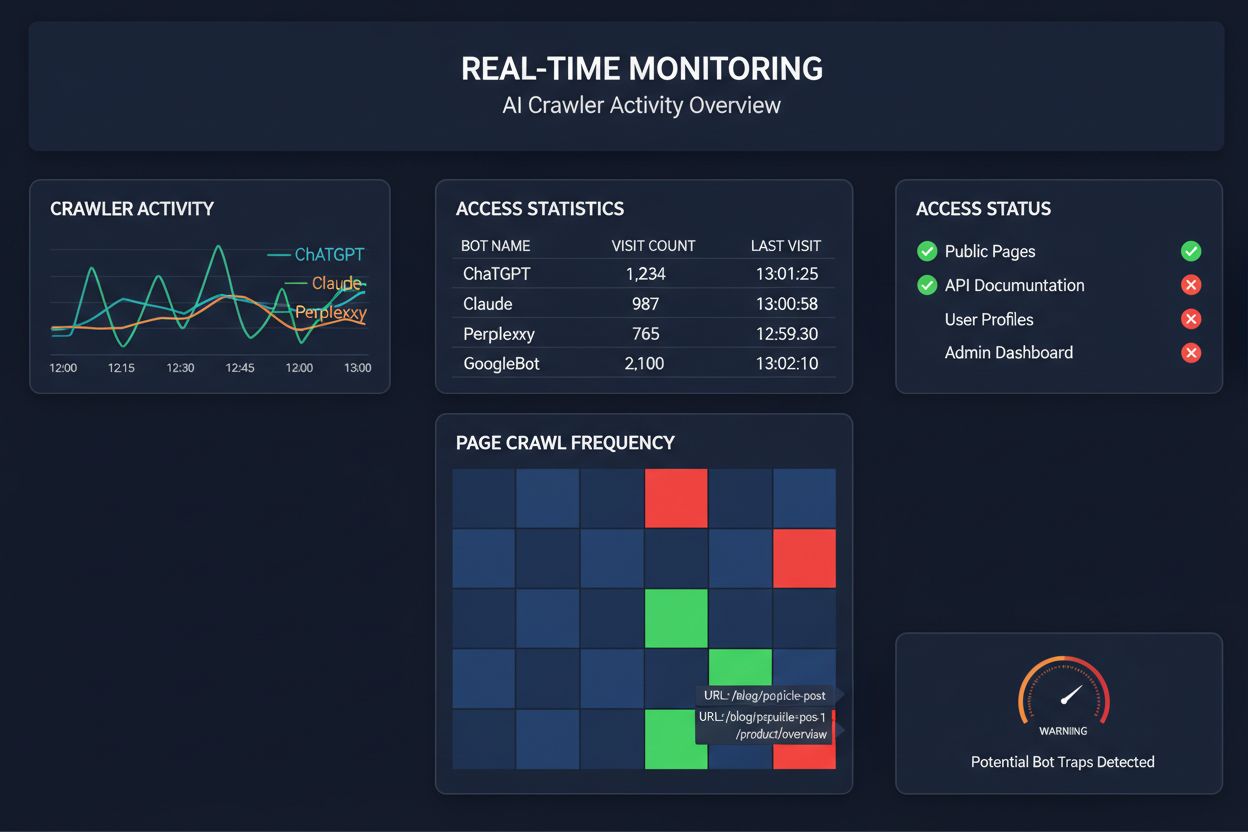
Affidarsi a crawl programmati per monitorare l’accesso dei crawler AI è come controllare la propria casa per gli incendi una volta al mese—perderai i momenti critici in cui si verificano i problemi. Il monitoraggio in tempo reale rileva i problemi non appena si presentano, consentendoti di intervenire prima che i tuoi contenuti diventino invisibili per i sistemi AI. Gli audit programmati, di solito settimanali o mensili, creano pericolosi punti ciechi in cui il tuo sito potrebbe non essere accessibile ai crawler AI per giorni senza che tu lo sappia. Le soluzioni in tempo reale tracciano il comportamento dei crawler in modo continuo, avvisandoti di errori di rendering JavaScript, problemi di schema markup, blocchi firewall o errori server appena si verificano. Questo approccio proattivo trasforma l’audit da un controllo di conformità reattivo a una vera strategia gestionale della visibilità. Con un traffico dei crawler AI potenzialmente 100 volte superiore rispetto ai motori di ricerca tradizionali, il costo di perdere anche solo poche ore di accessibilità può essere significativo.
Strumenti e Soluzioni per Audit dei Crawler AI
Diverse piattaforme offrono ora strumenti specializzati per monitorare e ottimizzare l’accesso dei crawler AI. Cloudflare AI Crawl Control fornisce una gestione a livello di infrastruttura del traffico dei bot AI, consentendo di impostare limiti di frequenza e politiche di accesso. Conductor offre dashboard di monitoraggio complete che tracciano come diversi crawler AI interagiscono con i tuoi contenuti. Elementive si concentra sugli audit SEO tecnici con particolare attenzione alle esigenze dei crawler AI. AdAmigo e MRS Digital offrono consulenza e servizi di monitoraggio specializzati per la visibilità AI. Tuttavia, per il monitoraggio continuo e in tempo reale pensato specificamente per tracciare i pattern di accesso dei crawler AI e segnalare i problemi prima che impattino la visibilità, AmICited si distingue come una soluzione dedicata. AmICited è specializzato nel monitorare quali sistemi AI stanno accedendo ai tuoi contenuti, con quale frequenza effettuano il crawl e se incontrano barriere tecniche. Questa attenzione specifica al comportamento dei crawler AI—piuttosto che ai classici parametri SEO—lo rende uno strumento essenziale per le organizzazioni che puntano seriamente alla visibilità AI.
Processo di Audit Passo-Passo
Effettuare un audit completo dei crawler AI richiede un approccio sistematico. Passo 1: Stabilisci un punto di partenza controllando l’attuale file robots.txt e identificando quali bot AI stai attualmente consentendo o bloccando. Passo 2: Audita la tua infrastruttura tecnica testando l’accessibilità del sito per crawler senza JavaScript, verificando i tempi di risposta del server e assicurandoti che i contenuti critici siano serviti in HTML statico. Passo 3: Implementa e valida lo schema markup su tutti i contenuti, assicurando che autore, date di pubblicazione, tipo di contenuto e altri metadati siano strutturati correttamente in formato JSON-LD. Passo 4: Monitora il comportamento dei crawler utilizzando strumenti come AmICited per tracciare quali bot AI accedono al tuo sito, con quale frequenza e se incontrano errori. Passo 5: Analizza i risultati esaminando i log di crawling, identificando pattern di fallimento e dando priorità alle correzioni in base all’impatto. Passo 6: Implementa le correzioni a partire dai problemi di maggiore impatto come errori di rendering JavaScript o assenza di schema, passando poi alle ottimizzazioni secondarie. Passo 7: Stabilisci un monitoraggio continuo per intercettare nuovi problemi prima che influiscano sulla visibilità, impostando alert per errori di crawl o blocchi di accesso.
Azioni Veloci per Migliorare la Crawlabilità AI
Non serve una revisione totale per migliorare l’accesso ai crawler AI—alcuni cambiamenti ad alto impatto possono essere implementati rapidamente. Servi i contenuti critici in HTML semplice invece di affidarti al rendering JavaScript; se devi usare JavaScript, assicurati che le informazioni importanti e i metadati siano disponibili anche nell’HTML iniziale. Aggiungi uno schema markup completo in formato JSON-LD, inclusi schema articolo, informazioni sull’autore, date di pubblicazione e relazioni tra contenuti—questo aiuta i crawler AI a comprendere il contesto e attribuire correttamente i contenuti. Assicura informazioni chiare sull’autore tramite schema markup e byline, poiché i sistemi AI danno sempre più importanza alle fonti autorevoli. Monitora e ottimizza i Core Web Vitals (Largest Contentful Paint, First Input Delay, Cumulative Layout Shift) dato che pagine lente possono essere abbandonate dai crawler prima che finiscano l’elaborazione. Rivedi e aggiorna il tuo robots.txt per assicurarti di non bloccare accidentalmente bot AI che vuoi far accedere ai tuoi contenuti. Risolve problemi tecnici come catene di reindirizzamento, link rotti ed errori server che potrebbero indurre i crawler ad abbandonare il sito a metà scansione.
Monitorare i Diversi Bot AI
Non tutti i crawler AI hanno lo stesso scopo, e comprendere queste differenze ti aiuta a prendere decisioni informate sul controllo degli accessi. GPTBot (OpenAI) è utilizzato principalmente per la raccolta dati di training e il miglioramento delle capacità del modello, quindi è rilevante se vuoi che i tuoi contenuti contribuiscano alle risposte di ChatGPT. OAI-SearchBot (OpenAI) esegue il crawl specificamente per scopi di citazione nei risultati di ricerca, cioè è il bot responsabile dell’inclusione dei tuoi contenuti nelle risposte integrate di ChatGPT. ClaudeBot (Anthropic) svolge funzioni simili per Claude, l’assistente AI di Anthropic. PerplexityBot (Perplexity) effettua il crawl per la citazione nel motore di ricerca AI di Perplexity, che è diventato una fonte di traffico significativa per molti editori. Ogni bot ha pattern di crawl, frequenza e finalità diverse—alcuni sono focalizzati sulla raccolta dati, altri sulle citazioni in tempo reale nella ricerca. Decidere quali bot consentire o bloccare dovrebbe essere allineato con la tua strategia di contenuto: se desideri citazioni nei risultati di ricerca AI, consenti i bot dedicati alla ricerca; se ti preoccupa l’uso per il training dati, puoi bloccare i bot per la raccolta dati consentendo quelli per la ricerca. Questo approccio sfaccettato alla gestione dei bot è molto più sofisticato rispetto al tradizionale “consenti tutto” o “blocca tutto”.
Domande frequenti
Che cos’è un audit dei crawler AI?
Un audit dei crawler AI è una valutazione completa dell’accessibilità del tuo sito web ai bot AI come ChatGPT, Claude e Perplexity. Identifica blocchi tecnici, problemi di rendering JavaScript, assenza di markup schema e altri fattori che impediscono ai crawler AI di accedere e comprendere i tuoi contenuti. L’audit fornisce raccomandazioni operative per migliorare la tua visibilità nei motori di ricerca e risposte alimentati dall’AI.
Con quale frequenza dovrei effettuare un audit dell’accesso dei crawler AI al mio sito?
Raccomandiamo di effettuare un audit completo almeno ogni trimestre, o ogni volta che apporti modifiche significative all’infrastruttura tecnica del sito, alla struttura dei contenuti o al file robots.txt. Tuttavia, il monitoraggio continuo in tempo reale è l’ideale per intercettare immediatamente eventuali problemi. Molte organizzazioni utilizzano strumenti automatici di monitoraggio che segnalano in tempo reale eventuali errori di crawling, integrati da audit approfonditi trimestrali.
Qual è la differenza tra bloccare e consentire i crawler AI?
Consentire i crawler AI significa che i tuoi contenuti possono essere accessibili, analizzati e potenzialmente citati dai sistemi AI, aumentando la tua visibilità nelle risposte e raccomandazioni generate dall’AI. Bloccare i crawler AI impedisce loro di accedere ai tuoi contenuti, proteggendo le informazioni proprietarie ma potenzialmente riducendo la tua visibilità nei risultati di ricerca AI. La scelta giusta dipende dai tuoi obiettivi di business, dalla sensibilità dei contenuti e dal posizionamento competitivo.
Posso bloccare specifici bot AI consentendo l’accesso ad altri?
Sì, assolutamente. Il tuo file robots.txt consente un controllo granulare tramite regole User-Agent. Puoi bloccare GPTBot consentendo PerplexityBot, oppure permettere solo i bot focalizzati sulla ricerca (come OAI-SearchBot) bloccando quelli per la raccolta dati (come GPTBot). Questo approccio ti permette di ottimizzare la strategia dei contenuti in base alle piattaforme AI più rilevanti per il tuo business.
Cosa significa se i crawler AI non possono accedere ai miei contenuti?
Se i crawler AI non possono accedere ai tuoi contenuti, il tuo sito è di fatto invisibile ai motori di ricerca e alle piattaforme di risposta alimentate dall’AI. I tuoi contenuti non saranno citati, raccomandati o inclusi nelle risposte generate dall’AI, anche se sono altamente pertinenti. Questo può comportare perdita di traffico, riduzione della visibilità del brand e mancate opportunità di affermare l’autorità nei risultati di ricerca AI.
Come faccio a sapere quali bot AI visitano il mio sito?
Puoi controllare i log del server per le stringhe User-Agent dei crawler AI noti (GPTBot, ClaudeBot, PerplexityBot, ecc.), oppure utilizzare strumenti specializzati di monitoraggio come AmICited che tracciano in tempo reale l’attività dei crawler AI. Questi strumenti mostrano quali bot stanno accedendo al sito, con quale frequenza effettuano il crawl, quali pagine visitano e se incontrano errori o blocchi.
Dovrei bloccare i crawler AI dal mio sito web?
Dipende dalla tua situazione specifica. Se i tuoi contenuti sono proprietari, sensibili o hai preoccupazioni sull’uso per il training dei dati, il blocco può essere appropriato. Tuttavia, se desideri visibilità nei risultati di ricerca AI e citazioni dai sistemi AI, consentire i crawler è essenziale. Molte organizzazioni adottano un approccio intermedio: consentire i bot focalizzati sulla ricerca che generano citazioni, bloccando quelli per la raccolta dati.
Qual è l’impatto di JavaScript sull’accesso dei crawler AI?
I crawler AI non eseguono il rendering di JavaScript, il che significa che qualsiasi contenuto caricato dinamicamente tramite script lato client è per loro invisibile. Se il tuo sito fa largo uso di JavaScript per contenuti critici, navigazione o dati strutturati, i crawler AI vedranno solo l’HTML grezzo e perderanno informazioni importanti. Questo può influenzare notevolmente come i tuoi contenuti vengono compresi e rappresentati nelle risposte AI. Servire i contenuti critici in HTML statico è essenziale per la crawlabilità AI.
Monitora l’Accesso dei Crawler AI con AmICited
Ottieni informazioni in tempo reale su quali bot AI stanno accedendo ai tuoi contenuti e su come vedono il tuo sito web. Inizia oggi il tuo audit gratuito e assicurati che il tuo brand sia visibile su tutte le piattaforme di ricerca AI.
Audit dei Contenuti per la Visibilità AI: Dare Priorità agli Aggiornamenti
Scopri come esaminare i tuoi contenuti per la visibilità AI e dare priorità agli aggiornamenti. Framework completo per ChatGPT, Perplexity e Google AI Overviews...
Monitora l'Attività dei Crawler AI: Guida Completa al Monitoraggio
Scopri come tracciare e monitorare l'attività dei crawler AI sul tuo sito utilizzando i log del server, strumenti e best practice. Identifica GPTBot, ClaudeBot ...
Scopri come identificare e monitorare i crawler AI come GPTBot, ClaudeBot e PerplexityBot nei log del tuo server. Guida completa con stringhe user-agent, verifi...
9 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.