Come l'IA Comprende le Entità: Approfondimento Tecnico
Esplora come i sistemi di IA riconoscono ed elaborano le entità nei testi. Scopri i modelli NER, le architetture transformer e le applicazioni reali della comprensione delle entità.
Pubblicato il Jan 3, 2026.Ultima modifica il Jan 3, 2026 alle 3:24 am
La comprensione delle entità è diventata una capacità fondamentale nei moderni sistemi di intelligenza artificiale, consentendo alle macchine di identificare e comprendere i principali attori, luoghi e concetti all’interno di testo non strutturato. Dai motori di ricerca che comprendono l’intento degli utenti ai chatbot in grado di rispondere a domande complesse su persone e organizzazioni specifiche, il riconoscimento delle entità rappresenta la base per un’interazione significativa tra uomo e computer. Questa capacità tecnica è cruciale in molti settori: le istituzioni finanziarie la utilizzano per il monitoraggio della conformità, i sistemi sanitari per la gestione dei dati dei pazienti e le piattaforme di e-commerce per comprendere le menzioni di prodotti e il feedback dei clienti. Capire come i sistemi di IA estraggono e interpretano le entità è essenziale per chiunque sviluppi o implementi applicazioni NLP in ambienti produttivi.
Concetti Chiave: Cosa Sono le Entità?
Il riconoscimento di entità nominate (NER) è il compito NLP di identificare e classificare le entità nominate—unità specifiche e significative di informazione—nel testo in categorie predefinite. Queste entità rappresentano i soggetti concreti che portano significato semantico nel linguaggio: persone che compiono azioni, organizzazioni che prendono decisioni, luoghi in cui avvengono eventi, espressioni temporali che ancorano gli eventi nel tempo, valori monetari che quantificano le transazioni e prodotti che vengono acquistati e venduti. La classificazione delle entità è importante perché trasforma testo grezzo in conoscenza strutturata su cui le macchine possono ragionare ed agire; senza di essa, un sistema non può distinguere tra “Apple l’azienda” e “apple il frutto”, né comprendere che “John Smith” e “J. Smith” si riferiscono alla stessa persona. La capacità di classificare accuratamente le entità consente applicazioni a valle come la costruzione di grafi di conoscenza, l’estrazione di informazioni, il question answering e il rilevamento di relazioni.
I sistemi di IA moderni elaborano le entità attraverso una sofisticata pipeline multistadio che inizia con la tokenizzazione, suddividendo il testo grezzo in token discreti che fungono da unità fondamentali per l’elaborazione successiva. Ogni token viene quindi convertito in una rappresentazione numerica tramite word embedding—vettori densi che catturano il significato semantico—che vengono forniti ad architetture di reti neurali progettate per comprendere il contesto e le relazioni. I modelli basati su transformer, ormai diventati l’architettura dominante nella NLP contemporanea, elaborano intere sequenze in parallelo anziché in modo sequenziale, consentendo di cogliere dipendenze a lungo raggio e relazioni contestuali complesse, cruciali per una comprensione accurata delle entità. Il meccanismo di self-attention all’interno dei Transformer permette a ogni token di pesare dinamicamente l’importanza di tutti gli altri token nella sequenza, generando rappresentazioni contestuali ricche in cui il significato di una parola è plasmato dal contesto circostante; per questo motivo “banca” viene inteso diversamente in “banca del fiume” rispetto a “banca di risparmio”. I modelli linguistici pre-addestrati come BERT e GPT apprendono schemi linguistici generali da enormi corpora testuali prima di essere ottimizzati per i compiti di riconoscimento delle entità, consentendo loro di sfruttare rappresentazioni apprese di sintassi, semantica e conoscenza del mondo. Lo strato finale dei sistemi di riconoscimento delle entità utilizza tipicamente un approccio di sequence labeling—spesso implementato come Conditional Random Field (CRF) o come semplice classificatore—che assegna etichette di entità a ciascun token sulla base delle rappresentazioni contestuali apprese dalla rete neurale. Questa architettura permette ai sistemi di IA non solo di capire quali entità sono presenti, ma anche come sono correlate tra loro e quali ruoli svolgono nel contesto più ampio del testo.
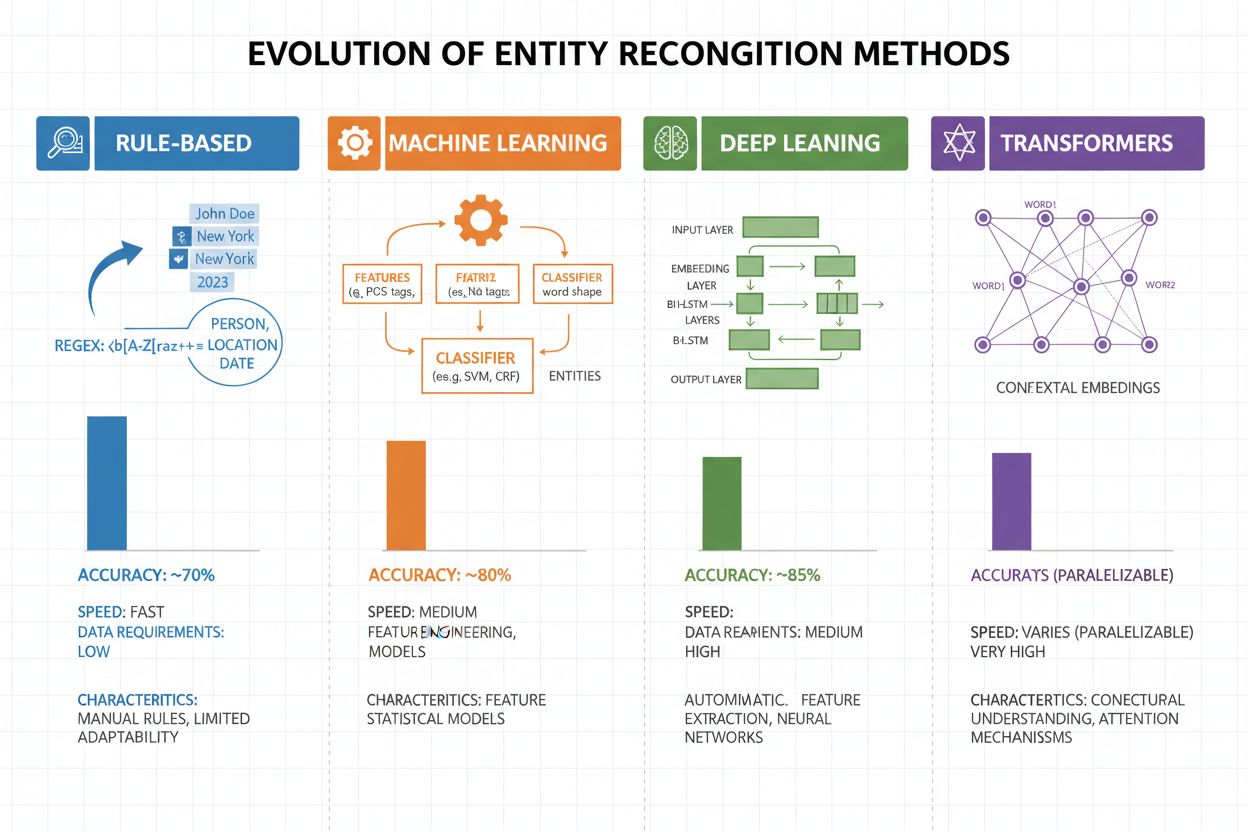
Evoluzione dei Metodi di Riconoscimento delle Entità
Il riconoscimento delle entità si è evoluto drasticamente negli ultimi due decenni, passando da semplici approcci basati su regole ad architetture neurali sofisticate. I primi sistemi si basavano su regole e dizionari creati a mano, utilizzando espressioni regolari e pattern matching per identificare le entità—metodi interpretabili e che richiedevano pochi dati di addestramento, ma con scarsa generalizzazione e alto costo di manutenzione. L’avvento del machine learning ha introdotto approcci supervisionati come Support Vector Machines (SVM) e Conditional Random Fields (CRF), che apprendevano da dati etichettati tramite feature engineering e miglioravano significativamente l’accuratezza, pur richiedendo esperti di dominio per progettare le caratteristiche rilevanti. I metodi di deep learning, in particolare LSTM e BiLSTM, hanno automatizzato l’estrazione delle caratteristiche apprendendo rappresentazioni direttamente dal testo grezzo, raggiungendo un’accuratezza molto superiore senza feature engineering manuale ma richiedendo dataset etichettati più grandi. I modelli basati su transformer come BERT e RoBERTa hanno rivoluzionato il settore sfruttando i meccanismi di self-attention per cogliere dipendenze a lungo raggio e sfumature contestuali, raggiungendo risultati all’avanguardia (BERT ha raggiunto il 90,9% di F1 su CoNLL-2003) e abilitando il transfer learning da modelli pre-addestrati su larga scala. Il compromesso tra complessità e accuratezza si è spostato notevolmente: mentre i sistemi basati su regole sono ancora utili in ambienti con risorse limitate e domini altamente specializzati, i modelli transformer ora dominano quando sono disponibili sufficienti risorse computazionali e dati etichettati, con alternative più leggere come DistilBERT che offrono un compromesso per sistemi produttivi con vincoli di latenza.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Modelli Transformer e Approcci Moderni
I modelli basati su transformer hanno trasformato radicalmente il riconoscimento delle entità, sostituendo l’elaborazione sequenziale con meccanismi di self-attention parallela che considerano simultaneamente tutti i token di una frase, permettendo una comprensione contestuale più ricca rispetto alle architetture precedenti. BERT e le sue varianti (RoBERTa, DistilBERT, ALBERT) sfruttano il pre-addestramento bidirezionale su enormi corpora non etichettati, apprendendo rappresentazioni linguistiche universali che catturano sia informazioni sintattiche sia semantiche, prima di essere ottimizzati per i task NER con dataset etichettati relativamente piccoli. Il paradigma pre-addestramento e fine-tuning è particolarmente potente per il riconoscimento delle entità: i modelli pre-addestrati su miliardi di token sviluppano rappresentazioni robuste della struttura linguistica e dei pattern delle entità, che possono poi essere adattate a domini specifici con poche migliaia di esempi etichettati, riducendo drasticamente la necessità di dati rispetto all’addestramento da zero. I transformer eccellono nella comprensione delle entità grazie al loro meccanismo di multi-head attention, che permette a differenti teste di attenzione di specializzarsi su diversi tipi di relazioni tra entità: alcune si concentrano sui confini sintattici, altre sulle associazioni semantiche tra entità e contesto. Il riconoscimento di entità multilingue è stato rivoluzionato da modelli come mBERT e XLM-RoBERTa, pre-addestrati su oltre 100 lingue, abilitando il transfer zero-shot e few-shot su lingue a bassa risorsa e il linking tra entità cross-lingua. Modelli emergenti come GLiNER (Generalist Language Model for Instruction-based Named Entity Recognition) spingono oltre i limiti consentendo il riconoscimento di entità basato su istruzioni, in cui i modelli possono identificare tipi di entità arbitrari specificati in prompt in linguaggio naturale senza fine-tuning specifico del task, rappresentando un passaggio verso sistemi di comprensione delle entità più flessibili e generalizzabili.
Sfide nella Comprensione delle Entità
Nonostante i notevoli progressi, i sistemi di riconoscimento delle entità affrontano sfide reali che ne limitano l’adozione pratica, con ambiguità e sensibilità al contesto tra le più difficili: la parola “Apple” richiede di capire se si riferisce al frutto o all’azienda tecnologica in base al contesto, e anche i modelli all’avanguardia faticano con questa disambiguazione semantica in testi rumorosi o ambigui. Le entità fuori vocabolario (OOV) rappresentano un’altra sfida fondamentale: modelli addestrati su dataset standard possono non incontrare mai entità rare, nomi propri di domini emergenti o varianti errate, portandoli a classificare erroneamente o non riconoscere affatto tali entità. L’adattamento al dominio resta problematico perché i modelli addestrati su corpora di notizie (come CoNLL-2003) spesso hanno scarse prestazioni su testi biomedici, legali o social media, dove la distribuzione delle entità e i pattern linguistici differiscono drasticamente, richiedendo costose ri-annotazioni e fine-tuning per ogni nuovo dominio. Gli errori di rilevamento dei confini—in cui i sistemi individuano correttamente l’esistenza di un’entità ma ne sbagliano l’inizio o la fine—sono particolarmente comuni con entità multi-parola e strutture annidate, come distinguere “New York City” da “New York” o gestire entità come “Amministratore Delegato di Apple Inc.” Le complessità multilingue aggravano queste sfide, poiché lingue diverse hanno convenzioni di capitalizzazione, strutture morfologiche e pattern di denominazione delle entità differenti, rendendo i modelli addestrati sull’inglese spesso inefficaci su lingue con proprietà linguistiche differenti. La scarsità di dati per domini specializzati come nomi di malattie rare, tecnologie emergenti o terminologie aziendali proprietarie costituisce un collo di bottiglia, dove il costo della manual annotation è proibitivo, costringendo a scegliere tra una minore accuratezza o investimenti elevati nella raccolta di dati specifici di dominio.
Applicazioni Reali e Casi d’Uso
La comprensione delle entità è diventata indispensabile in molti settori, trasformando il modo in cui le organizzazioni estraggono valore dal testo non strutturato. Nell’estrazione di informazioni e costruzione di grafi di conoscenza, il riconoscimento delle entità consente la popolazione automatica di database strutturati da documenti, alimentando motori di ricerca e sistemi di raccomandazione che comprendono le relazioni tra persone, luoghi e concetti. Le organizzazioni sanitarie sfruttano la comprensione delle entità per identificare nomi di farmaci, dosaggi, sintomi e dati demografici dei pazienti dalle note cliniche, migliorando il supporto alle decisioni cliniche e abilitando sistemi di farmacovigilanza per rilevare interazioni avverse su larga scala. Le istituzioni finanziarie utilizzano il riconoscimento delle entità per estrarre simboli di borsa, valori monetari ed eventi di mercato da notizie e report finanziari, consentendo a sistemi di trading algoritmico e piattaforme di risk management di reagire in tempo reale alle informazioni rilevanti. Le società di tecnologia legale applicano la comprensione delle entità per identificare automaticamente parti, date, obblighi e clausole di responsabilità nei contratti, riducendo il tempo di revisione dei documenti da settimane a ore. Le piattaforme di assistenza clienti e chatbot usano il riconoscimento delle entità per estrarre intenzioni e contesto rilevante—come numeri d’ordine, nomi di prodotti e tipi di problemi—abilitando un instradamento più accurato e risoluzioni più rapide. Le piattaforme di e-commerce impiegano la comprensione delle entità per identificare nomi di prodotto, brand, caratteristiche e specifiche nelle recensioni dei clienti e nelle query di ricerca, migliorando la scoperta dei prodotti e la personalizzazione. I sistemi di raccomandazione dei contenuti usano il riconoscimento delle entità per capire con quali entità interagiscono gli utenti, abilitando filtraggi collaborativi e raccomandazioni basate sui contenuti più sofisticate che incrementano coinvolgimento e ricavi.
Implementare Sistemi di Comprensione delle Entità
Implementare un sistema di comprensione delle entità a livello produttivo richiede attenzione nella preparazione dei dati, selezione del modello e valutazione. Inizia con dati annotati di alta qualità: definisci chiaramente i tipi di entità, utilizza metriche di accordo tra annotatori per garantire coerenza e punta ad almeno 500-1000 esempi etichettati per ogni tipo di entità, anche se applicazioni di dominio specifico possono richiederne di più. La selezione del modello dipende dai vincoli: i sistemi basati su regole offrono interpretabilità e bassa latenza per domini ben definiti, i modelli ML tradizionali (CRF, SVM) garantiscono buone prestazioni con dati moderati, mentre i modelli basati su transformer (BERT, RoBERTa) offrono accuratezza all’avanguardia ma richiedono più risorse computazionali e dati. Le strategie di training e fine-tuning dovrebbero includere tecniche di data augmentation per gestire lo sbilanciamento delle classi, validazione incrociata per prevenire overfitting e un’attenta ottimizzazione degli iperparametri (learning rate, batch size). Valuta il sistema con precision (entità corrette identificate), recall (entità trovate su tutte quelle effettive) e F1-score (media armonica delle due), con metriche separate per ciascun tipo di entità per individuare i punti deboli. Le considerazioni sul deployment includono requisiti di latenza (batch vs. real-time), necessità di scalabilità e integrazione con pipeline dati esistenti, mentre il monitoraggio post-deployment deve tracciare il drift delle prestazioni, i falsi positivi e il feedback degli utenti per attivare cicli di retraining.
Strumenti e Framework per il Riconoscimento delle Entità
L’ecosistema degli strumenti per la comprensione delle entità offre soluzioni per ogni scala e caso d’uso. Le librerie open-source come spaCy forniscono pipeline NER pronte per la produzione con ottime prestazioni (89,22% di F1-score su benchmark standard) e documentazione eccellente, ideali per team con competenze di machine learning; NLTK offre valore educativo e capacità NER di base; Hugging Face Transformers dà accesso a modelli pre-addestrati all’avanguardia che possono essere ottimizzati per domini specifici con poche righe di codice. I servizi cloud gestiti eliminano le preoccupazioni infrastrutturali: Google Cloud Natural Language API, AWS Comprehend e IBM Watson NLP offrono riconoscimento delle entità pre-addestrato con supporto multilingue e per diversi tipi di entità, gestendo automaticamente la scalabilità e integrandosi con pipeline cloud. I framework specializzati come Flair (basato su PyTorch con ottimo supporto sequence labeling) e DeepPavlov (modelli pre-addestrati per diverse lingue e domini) si rivolgono a ricercatori e team che necessitano di maggiore personalizzazione rispetto alle librerie generaliste. La scelta tra soluzioni custom e strumenti preconfezionati dipende dalla sensibilità dei dati (on-premise vs. cloud), dai livelli di accuratezza richiesti, dalla specificità del dominio e dalle competenze del team: usa API gestite per applicazioni generali con entità standard, sfrutta librerie open-source per personalizzazioni su dati interni e costruisci modelli custom solo se le soluzioni esistenti non soddisfano i tuoi requisiti di accuratezza o latenza.
Tendenze Future nella Comprensione delle Entità
Il futuro della comprensione delle entità è guidato da grandi modelli linguistici che portano flessibilità e prestazioni senza precedenti al task. Modelli come GPT-4 e Claude dimostrano straordinarie capacità di few-shot e zero-shot entity recognition, consentendo alle organizzazioni di identificare tipi di entità personalizzate con pochi esempi o persino semplici descrizioni in linguaggio naturale, riducendo drasticamente il carico di annotazione e accelerando il time-to-value. Sta emergendo la comprensione multimodale delle entità, che combina testo, immagini e dati strutturati per riconoscere entità in documenti, fatture e pagine web con un contesto più ricco, abilitando applicazioni come l’elaborazione automatica dei documenti e la ricerca visiva. I miglioramenti nell’elaborazione in tempo reale grazie alla distillazione dei modelli e al deployment su edge rendono possibile il riconoscimento sofisticato delle entità su dispositivi mobili e sistemi IoT, aprendo nuove applicazioni in realtà aumentata, traduzione in tempo reale e sistemi autonomi. I progressi nel fine-tuning specifico di dominio stanno creando modelli specializzati per ambiti biomedici, legali e finanziari che superano di gran lunga i modelli generalisti, con tecniche come pre-training adattivo di dominio e transfer learning sempre più accessibili. Con la maturazione di queste tecnologie, la comprensione delle entità diventerà uno strato fondante invisibile nei sistemi di IA, permettendo alle macchine di comprendere il mondo con una profondità semantica simile a quella umana e aprendo possibilità che oggi possiamo solo immaginare.
Perché la Comprensione delle Entità È Importante per il Monitoraggio dell’IA
Poiché sistemi di IA come ChatGPT, Perplexity e Google AI Overviews sono sempre più integrati nel modo in cui le informazioni vengono scoperte e consumate, comprendere come questi sistemi riconoscono e citano le entità—compreso il tuo brand—diventa fondamentale. La comprensione delle entità è il meccanismo tramite cui i sistemi di IA identificano ed elaborano menzioni di aziende, prodotti, persone e concetti. Monitorando come i sistemi di IA comprendono e citano il tuo brand attraverso il riconoscimento delle entità, ottieni informazioni su:
Come il tuo brand è categorizzato nei sistemi di IA (come azienda, prodotto o concetto)
Quale contesto i sistemi di IA associano al tuo brand
Con quale accuratezza i sistemi di IA identificano il tuo brand tra i concorrenti
Quali entità vengono frequentemente menzionate insieme al tuo brand
È esattamente ciò che monitora AmICited—tracciando come i sistemi di IA riconoscono e citano il tuo brand come entità su più piattaforme AI. Comprendendo il riconoscimento delle entità, puoi capire meglio come i sistemi di IA percepiscono e comunicano riguardo alla tua azienda.
Domande frequenti
Qual è la differenza tra riconoscimento delle entità e link delle entità?
Il riconoscimento delle entità (NER) identifica e classifica le entità in un testo (ad es. 'Apple' come ORGANIZZAZIONE), mentre il link delle entità collega tali entità a basi di conoscenza o riferimenti canonici (ad es. collegare 'Apple' alla pagina Wikipedia di Apple Inc.). Il riconoscimento delle entità è il primo passo; il link delle entità aggiunge un ancoraggio semantico.
Quanto sono accurate le moderne tecnologie di riconoscimento delle entità?
I modelli all'avanguardia basati su transformer come BERT raggiungono il 90,9% di F1-score su benchmark standard come CoNLL-2003. Tuttavia, l'accuratezza varia notevolmente a seconda del dominio: i modelli addestrati su notizie hanno prestazioni scarse su testi biomedici o di social media. L'accuratezza reale dipende molto dall'adattamento al dominio e dalla qualità dei dati.
Il riconoscimento delle entità funziona su più lingue?
Sì, modelli multilingue come mBERT e XLM-RoBERTa supportano più di 100 lingue simultaneamente. Tuttavia, le prestazioni variano a seconda della lingua a causa delle differenze nelle convenzioni di capitalizzazione, morfologia e dati di addestramento disponibili. I modelli specifici per lingua generalmente superano quelli multilingue nelle applicazioni critiche.
Qual è la differenza tra riconoscimento delle entità basato su regole e su ML?
I sistemi basati su regole utilizzano schemi e dizionari creati a mano (veloci, interpretabili, ma fragili). I sistemi ML apprendono da dati etichettati (più flessibili, migliore generalizzazione, ma richiedono dati di addestramento ed estrazione di caratteristiche). I moderni approcci di deep learning automatizzano l'estrazione delle caratteristiche, raggiungendo un'accuratezza superiore.
Quanti dati di addestramento servono per un riconoscimento entità personalizzato?
I sistemi basati su regole necessitano solo delle definizioni degli schemi. I modelli ML tradizionali richiedono 300-500 esempi etichettati. I modelli basati su transformer funzionano con 800+ esempi ma beneficiano del transfer learning: i modelli pre-addestrati possono ottenere buoni risultati con solo 100-200 esempi specifici di dominio tramite fine-tuning.
Quali sono le principali sfide nella comprensione delle entità?
Le sfide chiave includono: ambiguità (stessa parola con significati diversi), entità fuori vocabolario, adattamento al dominio (modelli addestrati su un dominio falliscono su un altro), errori di rilevamento dei confini, complessità multilingue e scarsità di dati per domini specializzati. Tutto ciò richiede attenta progettazione e adattamento specifico al dominio.
Come influisce il contesto sull'accuratezza del riconoscimento delle entità?
Il contesto è cruciale—'banca' ha significati diversi in 'banca del fiume' e 'banca di risparmio'. I transformer moderni utilizzano la self-attention per pesare il contesto di tutti i token circostanti, consentendo loro di disambiguare le entità in base al contesto linguistico e semantico. Una gestione scarsa del contesto è una delle principali fonti di errore nel riconoscimento delle entità.
Qual è il futuro della comprensione delle entità nell'IA?
Gli sviluppi futuri includono: grandi modelli linguistici che abilitano il riconoscimento delle entità zero-shot, comprensione multimodale che combina testo e immagini, elaborazione in tempo reale su dispositivi edge e progressi nel fine-tuning specifico di dominio. La comprensione delle entità diventerà uno strato fondante invisibile che permetterà alle macchine di comprendere il mondo con una comprensione semantica simile a quella umana.
Monitora Come l'IA Fa Riferimento al Tuo Brand
AmICited traccia le menzioni delle entità nei sistemi di IA come ChatGPT, Perplexity e Google AI Overviews. Comprendi come l'IA comprende e cita il tuo brand in tempo reale.
Ottimizzazione delle Entità per l’IA: Rendi il Tuo Brand Riconoscibile agli LLM
Scopri come l’ottimizzazione delle entità aiuta il tuo brand a diventare riconoscibile dagli LLM. Padroneggia l’ottimizzazione dei grafi di conoscenza, il marku...
Il Riconoscimento delle Entità è una capacità di NLP dell'IA che identifica e categorizza le entità nominate nel testo. Scopri come funziona, le sue applicazion...
Che cos'è l'ottimizzazione delle entità per l'AI? Guida completa per il 2025
Scopri cos'è l'ottimizzazione delle entità per l'AI, come funziona e perché è fondamentale per la visibilità su ChatGPT, Perplexity e altri motori di ricerca AI...
13 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.