
Cloudflare e bot AI: Gestire l’accesso all’edge
Scopri come il controllo dei crawler AI di Cloudflare, basato sull’edge, ti aiuta a monitorare, controllare e monetizzare l’accesso dei crawler AI ai tuoi conte...
13 min di lettura
Scopri come implementare il blocco selettivo dei crawler AI per proteggere i tuoi contenuti dai bot di addestramento mantenendo la visibilità nei risultati di ricerca AI. Strategie tecniche per editori.
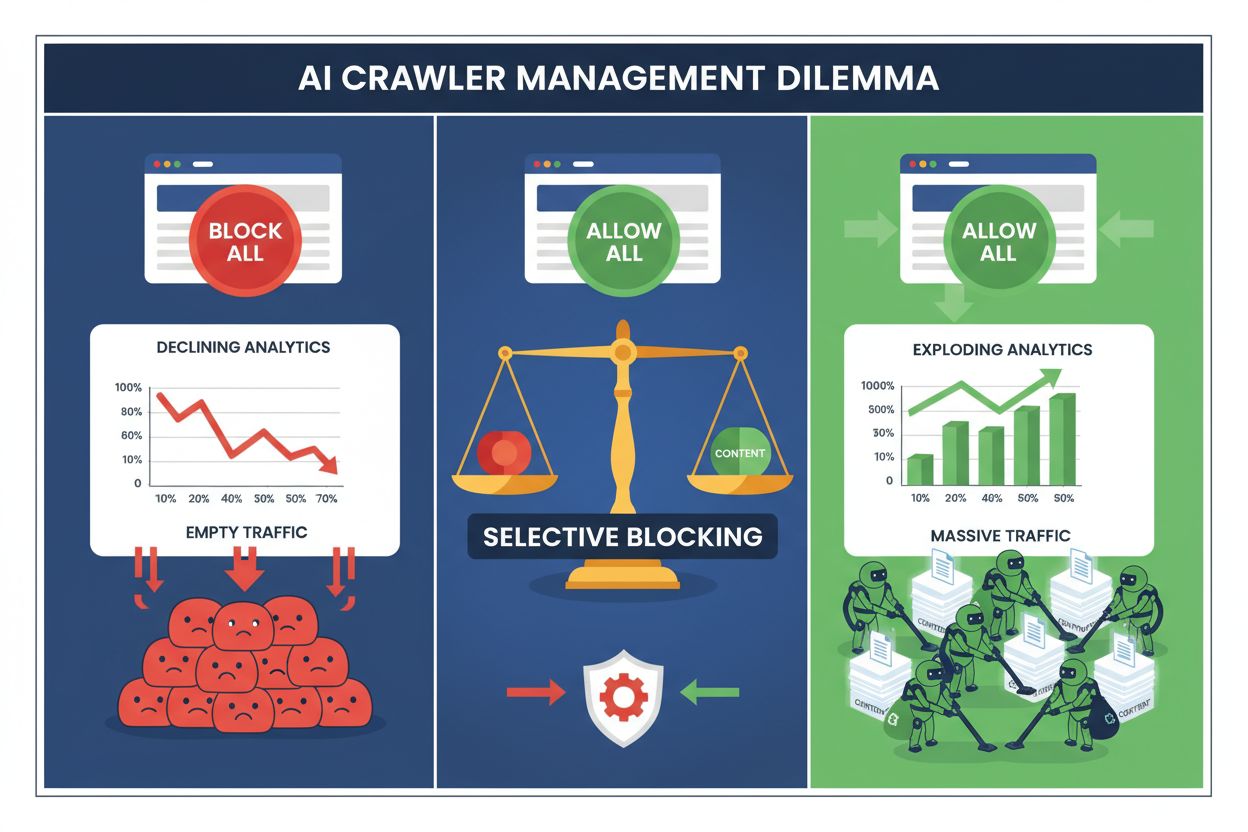
Gli editori oggi si trovano di fronte a una scelta impossibile: bloccare tutti i crawler AI e perdere prezioso traffico dai motori di ricerca, oppure consentirli tutti e vedere i propri contenuti alimentare dataset di addestramento senza alcuna compensazione. L’ascesa dell’AI generativa ha creato un ecosistema di crawler biforcato, in cui le stesse regole robots.txt si applicano indiscriminatamente sia ai motori di ricerca che generano ricavi sia ai crawler di addestramento che estraggono valore. Questo paradosso ha spinto gli editori più lungimiranti a sviluppare strategie di controllo selettivo dei crawler che distinguono tra diversi tipi di bot AI in base al loro reale impatto sulle metriche di business.
Il panorama dei crawler AI si divide in due categorie distinte con scopi e implicazioni di business molto diverse. I crawler di addestramento—gestiti da aziende come OpenAI, Anthropic e Google—sono progettati per ingerire enormi quantità di testo al fine di costruire e migliorare i grandi modelli linguistici, mentre i crawler di ricerca indicizzano contenuti per il recupero e la scoperta. I bot di addestramento rappresentano circa l'80% di tutta l’attività bot correlata all’AI, ma generano zero ricavi diretti per gli editori, mentre crawler di ricerca come Googlebot e Bingbot portano milioni di visite e impression pubblicitarie ogni anno. La distinzione è importante perché un singolo crawler di addestramento può consumare larghezza di banda equivalente a migliaia di utenti umani, mentre i crawler di ricerca sono ottimizzati per l’efficienza e normalmente rispettano i limiti di frequenza.
| Nome Bot | Operatore | Scopo primario | Potenziale traffico |
|---|---|---|---|
| GPTBot | OpenAI | Addestramento modelli | Nessuno (estrazione dati) |
| Claude Web Crawler | Anthropic | Addestramento modelli | Nessuno (estrazione dati) |
| Googlebot | Indicizzazione ricerca | 243,8M visite (Aprile 2025) | |
| Bingbot | Microsoft | Indicizzazione ricerca | 45,2M visite (Aprile 2025) |
| Perplexity Bot | Perplexity AI | Ricerca + addestramento | 12,1M visite (Aprile 2025) |
I dati parlano chiaro: il crawler di ChatGPT da solo ha inviato 243,8 milioni di visite agli editori nell’aprile 2025, ma queste visite hanno generato zero click, zero impression pubblicitarie e zero ricavi. Nel frattempo, il traffico di Googlebot si è tradotto in reale coinvolgimento degli utenti e opportunità di monetizzazione. Comprendere questa distinzione è il primo passo per implementare una strategia di blocco selettivo che protegga i tuoi contenuti preservando la visibilità nella ricerca.
Bloccare indiscriminatamente tutti i crawler AI è economicamente autodistruttivo per la maggior parte degli editori. Mentre i crawler di addestramento estraggono valore senza compenso, i crawler di ricerca restano una delle fonti di traffico più affidabili in un panorama digitale sempre più frammentato. Il caso finanziario per il blocco selettivo si basa su diversi fattori chiave:
Gli editori che implementano strategie di blocco selettivo riferiscono di mantenere o migliorare il traffico di ricerca riducendo l’estrazione non autorizzata dei contenuti fino all'85%. L’approccio strategico riconosce che non tutti i crawler AI sono uguali e che una policy sfumata serve molto meglio gli interessi di business rispetto a un approccio “terra bruciata”.
Il file robots.txt resta il principale meccanismo per comunicare i permessi ai crawler ed è sorprendentemente efficace nel distinguere tra diversi tipi di bot se configurato correttamente. Questo semplice file di testo, posizionato nella directory root del tuo sito, utilizza direttive user-agent per specificare quali crawler possono accedere a quali contenuti. Per il controllo selettivo dei crawler AI puoi consentire i motori di ricerca bloccando con precisione chirurgica i crawler di addestramento.
Ecco un esempio pratico che blocca i crawler di addestramento consentendo i motori di ricerca:
# Blocca GPTBot di OpenAI
User-agent: GPTBot
Disallow: /
# Blocca il crawler Claude di Anthropic
User-agent: Claude-Web
Disallow: /
# Blocca altri crawler di addestramento
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# Consenti i motori di ricerca
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
Questo approccio fornisce istruzioni chiare ai crawler “beneducati” mantenendo la scoperta del tuo sito nei risultati di ricerca. Tuttavia, robots.txt è fondamentalmente uno standard volontario—si basa sulla correttezza degli operatori dei crawler. Per gli editori preoccupati della conformità, sono necessari ulteriori livelli di enforcement.
Il solo robots.txt non può garantire la conformità poiché circa il 13% dei crawler AI ignora completamente le direttive robots.txt, per negligenza o deliberata elusione. L’enforcement a livello di server tramite il tuo web server o layer applicativo offre una protezione tecnica che previene l’accesso non autorizzato a prescindere dal comportamento del crawler. Questo approccio blocca le richieste a livello HTTP prima che consumino banda o risorse significative.
Implementare il blocco a livello server con Nginx è semplice ed estremamente efficace:
# Nel blocco server di Nginx
location / {
# Blocca i crawler di addestramento a livello server
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# Blocca per range di IP se necessario (per crawler che falsificano l'user agent)
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# Continua con l'elaborazione normale delle richieste
proxy_pass http://backend;
}
Questa configurazione restituisce una risposta 403 Forbidden ai crawler bloccati, consumando risorse minime del server e comunicando chiaramente che l’accesso è negato. Insieme al robots.txt, l’enforcement a livello server crea una difesa a due livelli che intercetta sia i crawler conformi sia quelli non conformi. Il tasso di elusione del 13% si avvicina allo zero quando le regole server sono correttamente implementate.
I Content Delivery Network e i Web Application Firewall forniscono un ulteriore livello di enforcement, operando prima che le richieste raggiungano i tuoi server di origine. Servizi come Cloudflare, Akamai e AWS WAF consentono di creare regole che bloccano specifici user agent o range IP direttamente all’edge, impedendo a crawler dannosi o indesiderati di consumare risorse della tua infrastruttura. Questi servizi mantengono elenchi aggiornati di IP e user agent noti di crawler di addestramento, bloccandoli automaticamente senza dover configurare manualmente.
I controlli a livello CDN offrono diversi vantaggi rispetto all’enforcement server: riducono il carico sui server di origine, permettono blocchi geografici e offrono analisi in tempo reale sulle richieste bloccate. Molti provider CDN ora offrono regole di blocco AI specifiche tra le funzionalità standard, riconoscendo la diffusa preoccupazione degli editori sull’estrazione non autorizzata di dati per l’addestramento. Per chi usa Cloudflare, abilitare l’opzione “Blocca crawler AI” nelle impostazioni di sicurezza offre una protezione one-click contro i principali crawler di addestramento mantenendo l’accesso ai motori di ricerca.
Un blocco selettivo efficace richiede un approccio sistematico alla classificazione dei crawler in base al loro impatto di business e al livello di affidabilità. Invece di trattare tutti i crawler AI allo stesso modo, gli editori dovrebbero implementare un framework a tre livelli che rifletta il reale valore e rischio di ciascun crawler. Questo schema permette decisioni sfumate che bilanciano la protezione dei contenuti con le opportunità di business.
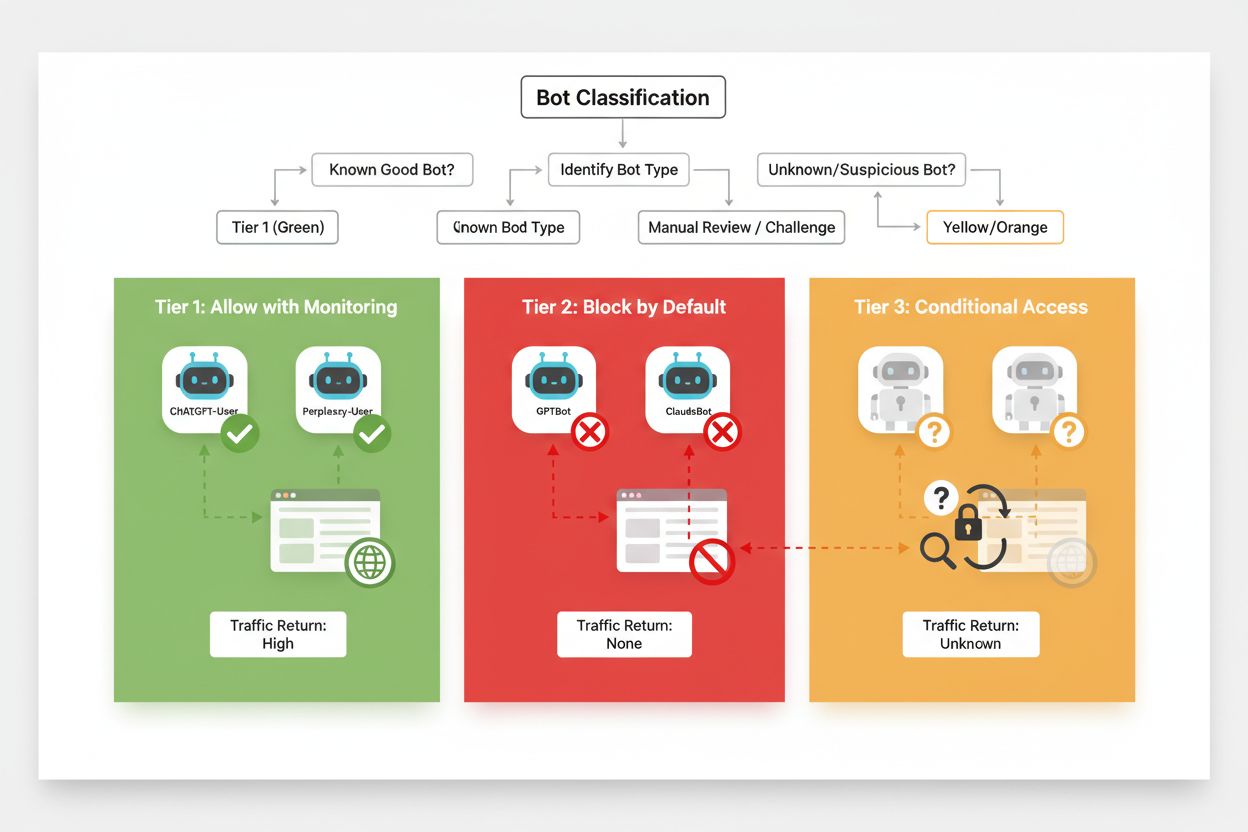
| Livello | Classificazione | Esempi | Azione |
|---|---|---|---|
| Livello 1: Generatori di ricavi | Motori di ricerca e fonti di traffico di riferimento | Googlebot, Bingbot, Perplexity Bot | Consentire pieno accesso; ottimizzare la scan |
| Livello 2: Neutrali/Non provati | Nuovi crawler con intenti poco chiari | Startup AI minori, bot di ricerca | Monitorare attentamente; consentire con rate limiting |
| Livello 3: Estrattori di valore | Crawler di addestramento senza benefici diretti | GPTBot, Claude-Web, CCBot | Bloccare completamente; enforcement multilivello |
Implementare questo framework richiede ricerca continua su nuovi crawler e i loro modelli di business. Gli editori dovrebbero auditare regolarmente i log di accesso per identificare nuovi bot, ricercare i termini di servizio e le policy di compensazione degli operatori e regolare di conseguenza le classificazioni. Un crawler che parte dal Livello 3 può passare al 2 se l’operatore offre revenue sharing, mentre un crawler precedentemente affidabile può scendere al 3 se viola i limiti di frequenza o le direttive robots.txt.
Il blocco selettivo non è una configurazione “imposta e dimentica”—richiede monitoraggio e regolazione continui man mano che evolve l’ecosistema dei crawler. Gli editori dovrebbero implementare log e analisi completi per tracciare quali crawler accedono ai contenuti, quanta banda consumano e se rispettano le restrizioni impostate. Questi dati guidano le decisioni strategiche su quali crawler consentire, bloccare o limitare.
Analizzare i log di accesso rivela pattern di comportamento che suggeriscono aggiustamenti alla policy:
# Identifica tutti i crawler AI che accedono al sito
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# Calcola la banda consumata da specifici crawler
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "Banda GPTBot: " sum/1024/1024 " MB"}'
# Monitora le risposte 403 ai crawler bloccati
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
Un’analisi regolare di questi dati—idealmente settimanale o mensile—rivela se la strategia di blocco funziona come previsto, se sono apparsi nuovi crawler e se eventuali crawler precedentemente bloccati hanno cambiato comportamento. Queste informazioni alimentano il framework di classificazione, garantendo che le policy restino allineate con gli obiettivi di business e la realtà tecnica.
Gli editori che implementano il blocco selettivo dei crawler spesso commettono errori che minano la strategia o producono effetti indesiderati. Comprendere questi errori ti aiuta ad evitarli e implementare una policy più efficace fin dall’inizio.
Bloccare tutti i crawler indiscriminatamente: l’errore più comune è usare regole di blocco troppo ampie che includono i motori di ricerca insieme ai crawler di addestramento, distruggendo la visibilità nella ricerca nel tentativo di proteggere i contenuti.
Affidarsi solo al robots.txt: pensare che il solo robots.txt impedisca l’accesso non autorizzato ignora il 13% dei crawler che lo ignorano completamente, lasciando i contenuti vulnerabili.
Non monitorare e non regolare: implementare una policy statica senza mai rivederla significa perdere nuovi crawler, non adattarsi a modelli di business in evoluzione e magari bloccare crawler utili che hanno migliorato le loro pratiche.
Bloccare solo tramite user agent: i crawler sofisticati falsificano o ruotano frequentemente gli user agent, rendendo inefficace il blocco solo su questa base senza regole IP supplementari e rate limiting.
Ignorare il rate limiting: anche i crawler consentiti possono consumare troppa banda se non limitati, degradando l’esperienza degli utenti umani e utilizzando inutilmente risorse.
Il futuro del rapporto tra editori e crawler AI probabilmente vedrà modelli di negoziazione e compensazione più sofisticati invece di semplici blocchi. Tuttavia, finché non emergeranno standard di settore, il controllo selettivo dei crawler resta l’approccio più pratico per proteggere i contenuti mantenendo la visibilità nella ricerca. Gli editori dovrebbero considerare la strategia di blocco come una policy dinamica che evolve insieme all’ecosistema dei crawler, rivalutando regolarmente a quali concedere l’accesso in base all’impatto di business e all’affidabilità.
Gli editori di maggior successo saranno quelli che implementano difese multilivello—combinando direttive robots.txt, enforcement server, controlli CDN e monitoraggio continuo in una strategia completa. Questo approccio protegge sia dai crawler conformi sia da quelli non conformi, preservando il traffico dei motori di ricerca che genera ricavi e coinvolgimento. Man mano che le aziende AI riconosceranno il valore dei contenuti e inizieranno a offrire compensi o accordi di licenza, il framework che costruisci oggi potrà adattarsi facilmente ai nuovi modelli di business mantenendo il controllo sui tuoi asset digitali.
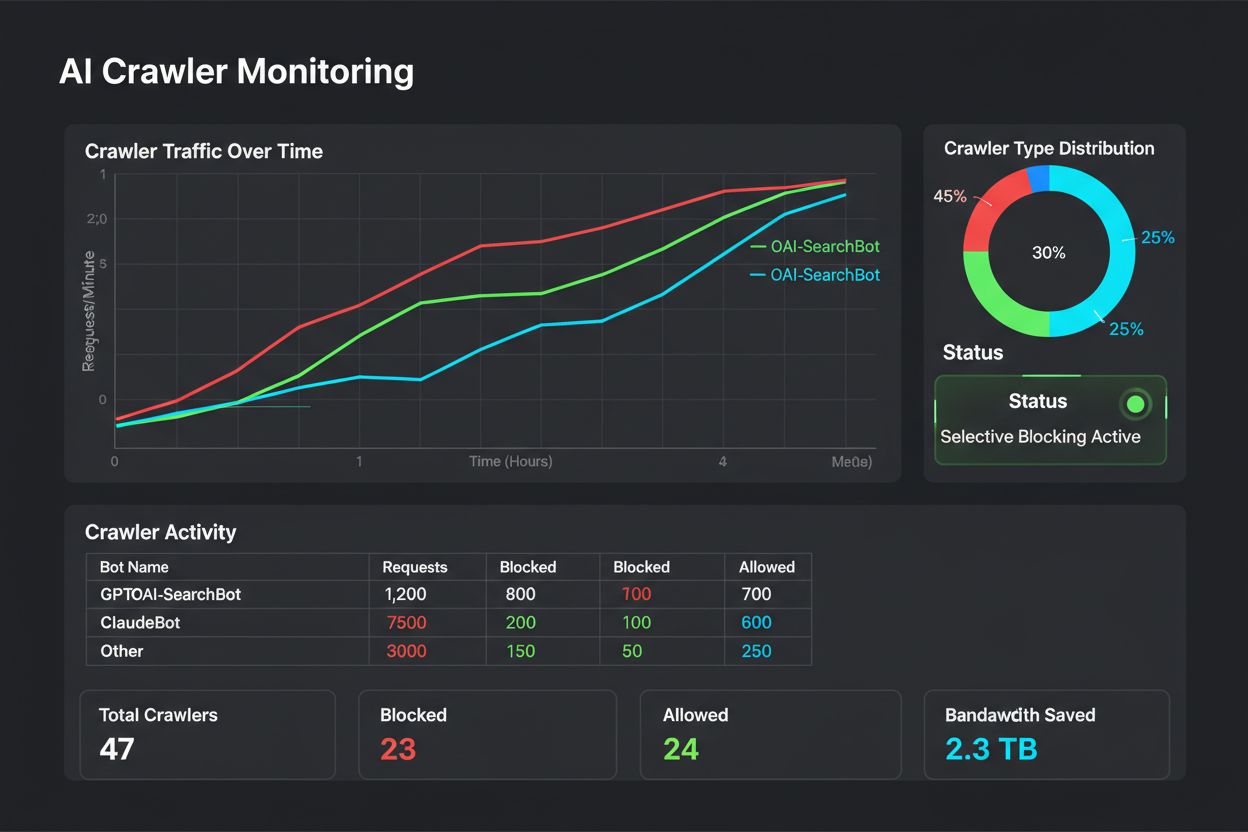
I crawler di addestramento come GPTBot e ClaudeBot raccolgono dati per costruire modelli AI senza restituire traffico al tuo sito. I crawler di ricerca come OAI-SearchBot e PerplexityBot indicizzano i contenuti per i motori di ricerca AI e possono generare traffico di riferimento significativo verso il tuo sito. Comprendere questa distinzione è cruciale per implementare una strategia di blocco selettivo efficace.
Sì, questa è la strategia centrale del controllo selettivo dei crawler. Puoi utilizzare robots.txt per disabilitare i bot di addestramento e consentire quelli di ricerca, quindi applicare controlli a livello di server per i bot che ignorano robots.txt. Questo approccio protegge i tuoi contenuti dall'addestramento non autorizzato mantenendo la visibilità nei risultati di ricerca AI.
La maggior parte delle grandi aziende AI sostiene di rispettare robots.txt, ma la conformità è volontaria. Le ricerche mostrano che circa il 13% dei bot AI ignora completamente le direttive robots.txt. Ecco perché l'applicazione a livello di server è essenziale per gli editori seriamente intenzionati a proteggere i propri contenuti dai crawler non conformi.
Significativo e in crescita. ChatGPT ha inviato 243,8 milioni di visite a 250 siti di news e media nell'aprile 2025, con un aumento del 98% rispetto a gennaio. Bloccare questi crawler significa perdere questa nuova fonte di traffico. Per molti editori, il traffico di ricerca AI rappresenta ora il 5-15% del traffico di riferimento totale.
Analizza regolarmente i log del server con comandi grep per identificare gli user agent dei bot, tracciare la frequenza di crawl e monitorare la conformità alle tue regole robots.txt. Rivedi i log almeno mensilmente per identificare nuovi bot, comportamenti insoliti e verificare se i bot bloccati stanno effettivamente fuori dal sito. Questi dati ti aiutano a prendere decisioni strategiche sulla tua policy per i crawler.
Proteggi i tuoi contenuti dall'addestramento non autorizzato ma perdi visibilità nei risultati di ricerca AI, perdi nuove fonti di traffico e potenzialmente riduci le menzioni del brand nelle risposte generate dall'AI. Gli editori che implementano blocchi totali spesso vedono riduzioni del 40-60% nella visibilità di ricerca e perdono opportunità di scoperta del brand tramite piattaforme AI.
Almeno mensilmente, poiché nuovi bot emergono costantemente e quelli esistenti evolvono il loro comportamento. Lo scenario dei crawler AI cambia rapidamente, con nuovi operatori che lanciano crawler e player già presenti che uniscono o rinominano i propri bot. Revisioni regolari assicurano che la tua policy resti allineata agli obiettivi di business e alla realtà tecnica.
È il numero di pagine scansionate rispetto ai visitatori inviati al tuo sito. Anthropic scansiona 38.000 pagine per ogni visitatore restituito, mentre OpenAI mantiene un rapporto di 1.091:1 e Perplexity si attesta a 194:1. Rapporti più bassi indicano un valore migliore nel consentire il crawler. Questa metrica ti aiuta a decidere a quali crawler concedere l'accesso in base al loro reale impatto sul business.
AmICited traccia quali piattaforme AI citano il tuo brand e i tuoi contenuti. Ottieni insight sulla tua visibilità AI e assicurati la corretta attribuzione su ChatGPT, Perplexity, Google AI Overviews e molto altro.
Scopri come il controllo dei crawler AI di Cloudflare, basato sull’edge, ti aiuta a monitorare, controllare e monetizzare l’accesso dei crawler AI ai tuoi conte...

Scopri come i Web Application Firewall offrono un controllo avanzato sui crawler AI oltre robots.txt. Implementa regole WAF per proteggere i tuoi contenuti dall...

Scopri come bloccare o autorizzare i crawler AI come GPTBot e ClaudeBot utilizzando robots.txt, blocchi a livello di server e metodi di protezione avanzati. Gui...
Consenso Cookie
Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.