
Come Identificare i Crawler AI nei Log del Server
Scopri come identificare e monitorare i crawler AI come GPTBot, ClaudeBot e PerplexityBot nei log del tuo server. Guida completa con stringhe user-agent, verifi...
9 min di lettura

Scopri come bloccare o autorizzare i crawler AI come GPTBot e ClaudeBot utilizzando robots.txt, blocchi a livello di server e metodi di protezione avanzati. Guida tecnica completa con esempi.
Lo scenario digitale si è spostato radicalmente dalla tradizionale ottimizzazione per i motori di ricerca alla gestione di una nuova categoria di visitatori automatizzati: i crawler AI. A differenza dei bot di ricerca convenzionali che portano traffico al tuo sito tramite i risultati di ricerca, i crawler di training AI consumano i tuoi contenuti per costruire grandi modelli linguistici senza necessariamente restituire traffico di referral. Questa differenza ha profonde implicazioni per editori, creatori di contenuti e aziende che dipendono dal traffico web come fonte di reddito. La posta in gioco è alta: controllare quali sistemi AI accedono ai tuoi contenuti influisce direttamente sul tuo vantaggio competitivo, la privacy dei dati e il risultato economico.
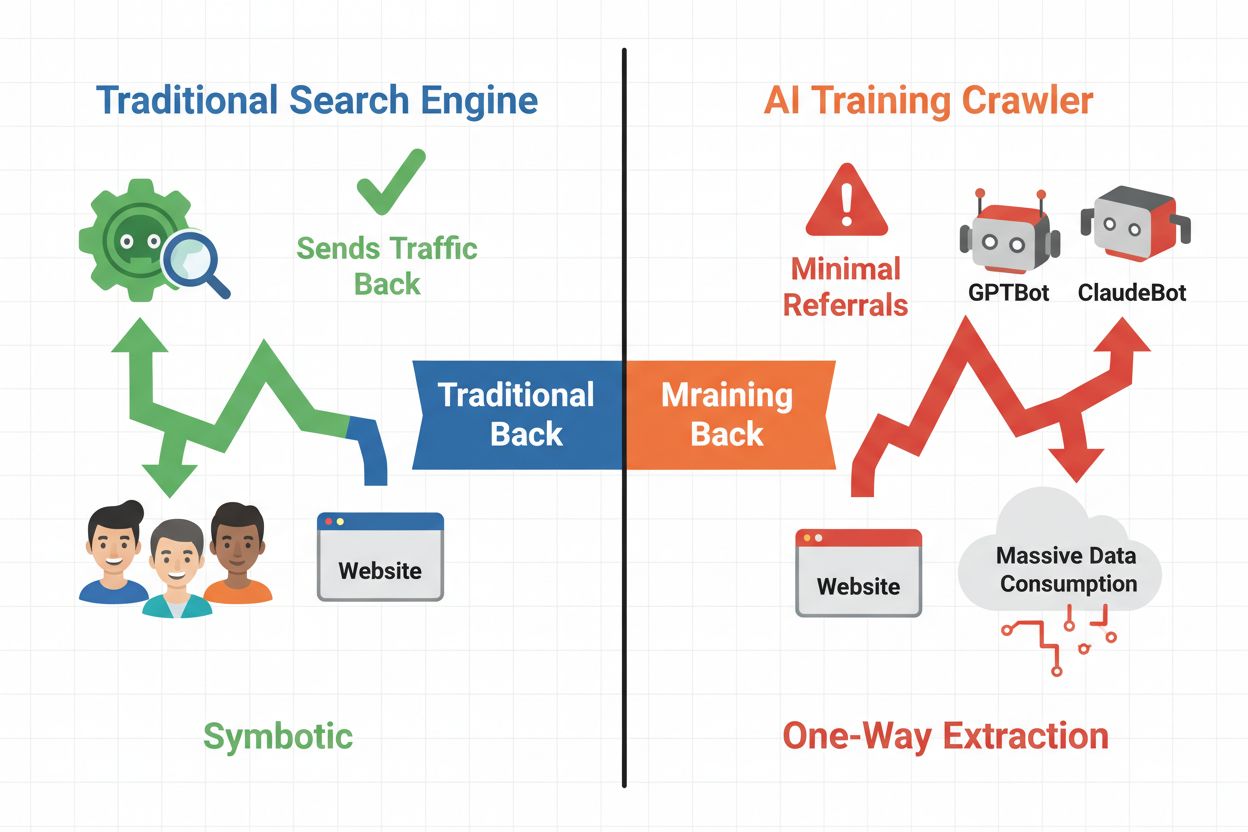
I crawler AI si suddividono in tre categorie distinte, ciascuna con scopi e impatti sul traffico diversi. I crawler di training vengono usati dalle aziende AI per costruire e migliorare i loro modelli linguistici, agendo solitamente su larga scala con un ritorno di traffico minimo. I crawler di ricerca e citazione indicizzano i contenuti per motori di ricerca AI e sistemi di citazione, spesso generando un po’ di traffico di referral agli editori. I crawler attivati dagli utenti recuperano contenuti su richiesta quando gli utenti interagiscono con applicazioni AI, rappresentando un segmento piccolo ma in crescita. Comprendere queste categorie ti aiuta a decidere quali crawler autorizzare o bloccare in base al tuo modello di business.
| Tipo di Crawler | Scopo | Impatto sul traffico | Esempi |
|---|---|---|---|
| Training | Costruzione/miglioramento LLM | Minimo o nullo | GPTBot, ClaudeBot, Bytespider |
| Ricerca/Citazione | Indicizzazione per ricerca AI & citazioni | Traffico di referral moderato | Googlebot-Extended, Perplexity |
| Attivato dall’utente | Recupero su richiesta per utenti | Basso ma costante | Plugin ChatGPT, navigazione Claude |
L’ecosistema dei crawler AI include bot delle più grandi aziende tecnologiche mondiali, ognuno con user agent e scopi distinti. GPTBot di OpenAI (user agent: GPTBot/1.0) effettua crawling per addestrare ChatGPT e altri modelli, mentre ClaudeBot di Anthropic (user agent: Claude-Web/1.0) ha scopi simili per Claude. Googlebot-Extended di Google (user agent: Mozilla/5.0 ... Googlebot-Extended) indicizza contenuti per AI Overviews e Bard, mentre Meta-ExternalFetcher di Meta effettua crawling per le iniziative AI di Meta. Altri attori principali includono:
Ogni crawler opera su scale diverse e rispetta le direttive di blocco con gradi di conformità variabili.
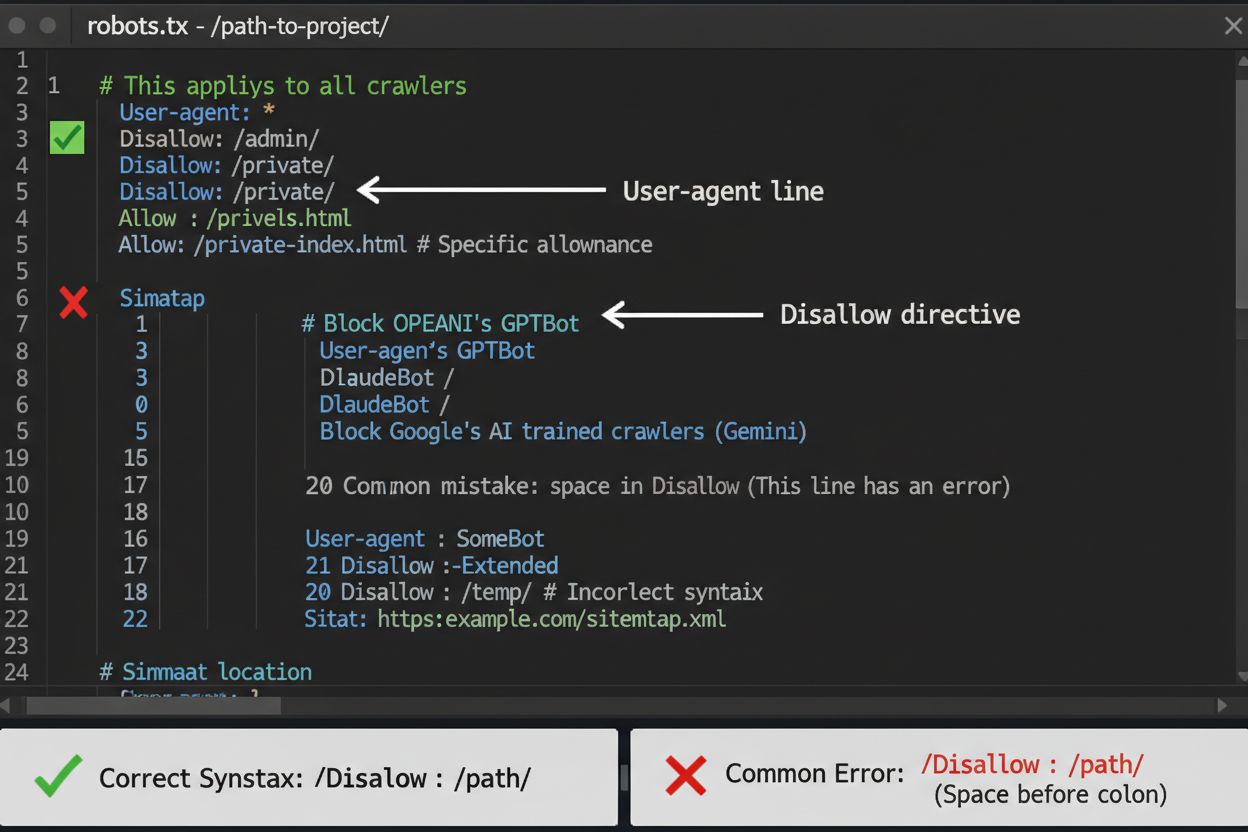
Il file robots.txt è la tua prima linea di difesa per controllare l’accesso dei crawler AI, ma è importante capire che ha valore consultivo e non legale. Situato nella root del tuo dominio (es: tuosito.com/robots.txt), questo file usa una sintassi semplice per indicare ai crawler quali aree evitare. Per bloccare in modo completo tutti i principali crawler AI, aggiungi queste regole:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
Se preferisci un blocco selettivo—autorizzando i crawler di ricerca ma bloccando quelli di training—usa questo approccio:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
Un errore comune è utilizzare regole troppo generiche come Disallow: * che possono confondere i parser, o dimenticare di specificare i singoli crawler quando vuoi bloccarne solo alcuni. Le grandi aziende come OpenAI, Anthropic e Google generalmente rispettano robots.txt, anche se alcuni crawler come Perplexity sono noti per ignorare queste regole.
Quando robots.txt non basta, esistono diversi metodi di protezione più efficaci per controllare l’accesso dei crawler AI. Il blocco basato su IP consiste nell’identificare gli intervalli IP dei crawler AI e bloccarli a livello di firewall o server—è molto efficace ma richiede manutenzione poiché gli IP cambiano spesso. Il blocco a livello di server tramite file .htaccess (Apache) o configurazioni Nginx offre un controllo più granulare ed è più difficile da eludere rispetto a robots.txt. Per server Apache, implementa questa regola:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
Il blocco tramite meta tag usando <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> impedisce l’indicizzazione ma non ferma i crawler di training. La verifica degli header delle richieste controlla che i crawler provengano effettivamente dalle fonti dichiarate tramite verifica del reverse DNS e dei certificati SSL. Usa il blocco a livello di server quando vuoi essere certo che i crawler non accedano ai tuoi contenuti, e combina più metodi per la massima protezione.
Decidere se bloccare i crawler AI significa valutare diversi interessi in conflitto. Bloccare i crawler di training (GPTBot, ClaudeBot, Bytespider) impedisce l’uso dei tuoi contenuti per addestrare modelli AI, proteggendo la tua proprietà intellettuale e il vantaggio competitivo. Tuttavia, autorizzare i crawler di ricerca (Googlebot-Extended, Perplexity) può portare traffico di referral e aumentare la visibilità nei risultati AI—un canale di scoperta in crescita. Il compromesso si complica considerando che alcune aziende AI hanno rapporti tra crawling e referral molto sbilanciati: i crawler di Anthropic generano circa 38.000 richieste di crawling per ogni singolo referral, mentre il rapporto di OpenAI è circa 400:1. Carico sul server e banda sono un altro aspetto: i crawler AI consumano molte risorse, e bloccarli può ridurre i costi infrastrutturali. La decisione deve essere allineata al tuo modello di business: le testate giornalistiche e gli editori possono beneficiare del traffico di referral, mentre aziende SaaS e creatori di contenuti proprietari preferiscono generalmente il blocco.
Implementare i blocchi ai crawler è solo metà del lavoro—devi verificare che i crawler rispettino davvero le tue direttive. L’analisi dei log del server è lo strumento principale: esamina i log di accesso per le stringhe user agent e gli indirizzi IP dei crawler che tentano di accedere dopo il blocco. Usa grep per cercare nei log:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
Questo comando conta quante volte questi crawler hanno visitato il sito. Strumenti di test come curl possono simulare le richieste dei crawler per verificare che le regole di blocco funzionino correttamente:
curl -A "GPTBot/1.0" https://tuosito.com/robots.txt
Monitora i log settimanalmente per il primo mese dopo aver implementato i blocchi, poi ogni trimestre. Se rilevi crawler che ignorano robots.txt, passa a blocchi a livello di server o contatta il team abusi dell’operatore del crawler.
Il panorama dei crawler AI si evolve rapidamente, con nuove aziende che lanciano prodotti AI e crawler esistenti che cambiano user agent e intervalli IP. Revisioni trimestrali della tua blocklist garantiscono che tu non perda nuovi crawler o blocchi accidentalmente traffico legittimo. L’ecosistema dei crawler è frammentato e decentralizzato, rendendo impossibile creare una blocklist davvero permanente. Monitora queste risorse per aggiornamenti:
Imposta promemoria per rivedere robots.txt e le regole a livello di server ogni 90 giorni, e iscriviti a mailing list di sicurezza che segnalano nuovi crawler.
Bloccare i crawler AI impedisce loro di accedere ai tuoi contenuti, ma AmICited affronta la sfida complementare: monitorare se e come i sistemi AI citano e fanno riferimento al tuo brand e ai tuoi contenuti nelle loro risposte. AmICited traccia le menzioni della tua organizzazione nelle risposte AI, offrendo visibilità su come i tuoi contenuti influenzano le uscite dei modelli e dove compare il tuo brand nei risultati di ricerca AI. Questo crea una strategia AI completa: controlli l’accesso dei crawler tramite robots.txt e blocchi a livello di server, mentre AmICited ti assicura di comprendere l’impatto a valle dei tuoi contenuti sui sistemi AI. Insieme, questi strumenti ti danno visibilità e controllo totali sulla tua presenza nell’ecosistema AI—dalla prevenzione dell’uso indesiderato dei tuoi dati per il training alla misurazione delle reali citazioni e referenze che i tuoi contenuti generano sulle piattaforme AI.
No. Bloccare i crawler di training AI come GPTBot, ClaudeBot e Bytespider non influisce sul posizionamento su Google o Bing. I motori di ricerca tradizionali usano crawler diversi (Googlebot, Bingbot) che operano in modo indipendente. Bloccali solo se vuoi scomparire completamente dai risultati di ricerca.
I principali crawler di OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) e Perplexity (PerplexityBot) dichiarano ufficialmente di rispettare le direttive robots.txt. Tuttavia, bot più piccoli o meno trasparenti potrebbero ignorare la tua configurazione, motivo per cui esistono strategie di protezione a più livelli.
Dipende dalla tua strategia. Bloccare solo i crawler di training (GPTBot, ClaudeBot, Bytespider) protegge i tuoi contenuti dall’addestramento dei modelli, consentendo comunque ai crawler focalizzati sulla ricerca di aiutarti ad apparire nei risultati AI. Il blocco totale ti esclude completamente dagli ecosistemi AI.
Rivedi la configurazione almeno ogni trimestre. Le aziende AI introducono regolarmente nuovi crawler. Anthropic ha unito i bot 'anthropic-ai' e 'Claude-Web' in 'ClaudeBot', dando al nuovo bot accesso temporaneamente illimitato ai siti che non avevano aggiornato le regole.
Il blocco impedisce ai crawler di accedere completamente ai tuoi contenuti, proteggendoli dalla raccolta per il training o dall’indicizzazione. L’autorizzazione consente l’accesso ma può portare all’uso dei tuoi contenuti per il training dei modelli o alla loro presenza nei risultati AI con traffico di referral minimo.
Sì, robots.txt è consultivo e non legalmente vincolante. I crawler ben gestiti delle grandi aziende generalmente rispettano robots.txt, ma alcuni crawler lo ignorano. Per una protezione più forte, implementa blocchi a livello di server tramite .htaccess o regole firewall.
Controlla i log del server per le stringhe user agent dei crawler bloccati. Se vedi richieste da crawler che hai bloccato, potrebbero non rispettare robots.txt. Usa strumenti di test come il robots.txt tester della Google Search Console o comandi curl per verificare la configurazione.
Bloccare i crawler di training di solito ha un impatto diretto minimo sul traffico, poiché inviano comunque poco traffico di referral. Tuttavia, bloccare i crawler di ricerca può ridurre la visibilità nelle piattaforme di scoperta AI. Monitora le tue analytics per 30 giorni dopo aver implementato i blocchi per misurare l’impatto effettivo.
Mentre controlli l’accesso dei crawler con robots.txt, AmICited ti aiuta a tracciare come i sistemi AI citano e fanno riferimento ai tuoi contenuti nelle loro risposte. Ottieni una visibilità completa della tua presenza AI.
Scopri come identificare e monitorare i crawler AI come GPTBot, ClaudeBot e PerplexityBot nei log del tuo server. Guida completa con stringhe user-agent, verifi...

Guida di riferimento completa ai crawler e bot AI. Identifica GPTBot, ClaudeBot, Google-Extended e oltre 20 altri crawler AI con user agent, frequenze di scansi...

Scopri quali crawler AI autorizzare o bloccare nel tuo robots.txt. Guida completa che copre GPTBot, ClaudeBot, PerplexityBot e oltre 25 crawler AI con esempi di...