
Embedding
Scopri cosa sono gli embedding, come funzionano e perché sono essenziali per i sistemi AI. Scopri come il testo si trasforma in vettori numerici che catturano i...
13 min di lettura

Scopri come gli embedding vettoriali permettono ai sistemi di IA di comprendere il significato semantico e abbinare i contenuti alle query. Esplora la tecnologia alla base della ricerca semantica e dell’abbinamento dei contenuti tramite IA.

Gli embedding vettoriali costituiscono la base numerica che alimenta i moderni sistemi di intelligenza artificiale, trasformando i dati grezzi in rappresentazioni matematiche che le macchine possono comprendere ed elaborare. Alla loro base, gli embedding convertono testo, immagini, audio e altri tipi di contenuti in array di numeri—tipicamente da decine a migliaia di dimensioni—che catturano il significato semantico e le relazioni contestuali all’interno di quei dati. Questa rappresentazione numerica è fondamentale per il modo in cui i sistemi IA eseguono l’abbinamento dei contenuti, la ricerca semantica e i compiti di raccomandazione, consentendo alle macchine di capire non solo quali parole o immagini sono presenti, ma cosa significano effettivamente. Senza embedding, i sistemi IA faticherebbero a cogliere le relazioni sfumate tra i concetti, rendendoli un’infrastruttura essenziale per qualsiasi applicazione IA moderna.
La trasformazione dai dati grezzi agli embedding vettoriali viene realizzata tramite sofisticati modelli di reti neurali addestrati su enormi dataset per apprendere schemi e relazioni significative. Quando inserisci un testo in un modello di embedding, esso passa attraverso molteplici strati di reti neurali che estraggono progressivamente informazioni semantiche, producendo infine un vettore di dimensioni fisse che rappresenta l’essenza di quel contenuto. I modelli di embedding più diffusi come Word2Vec, GloVE e BERT adottano ciascuno approcci differenti—Word2Vec utilizza reti neurali superficiali ottimizzate per la velocità, GloVE combina la fattorizzazione di matrici globali con finestre di contesto locali, mentre BERT sfrutta l’architettura transformer per comprendere il contesto bidirezionale.
| Modello | Tipo di Dato | Dimensioni | Caso d’Uso Principale | Vantaggio Chiave |
|---|---|---|---|---|
| Word2Vec | Testo (parole) | 100-300 | Relazioni tra parole | Veloce, efficiente |
| GloVE | Testo (parole) | 100-300 | Relazioni semantiche | Combina contesto globale e locale |
| BERT | Testo (frasi/documenti) | 768-1024 | Comprensione contestuale | Consapevolezza del contesto bidirezionale |
| Sentence-BERT | Testo (frasi) | 384-768 | Similarità tra frasi | Ottimizzato per la ricerca semantica |
| Universal Sentence Encoder | Testo (frasi) | 512 | Compiti cross-lingua | Indipendente dalla lingua |
Questi modelli producono vettori ad alta dimensione (spesso da 300 a 1.536 dimensioni), dove ogni dimensione cattura diversi aspetti del significato, dalle proprietà grammaticali alle relazioni concettuali. Il pregio di questa rappresentazione numerica è che consente operazioni matematiche—puoi sommare, sottrarre e confrontare vettori per scoprire relazioni che sarebbero invisibili nel testo grezzo. Questa base matematica è ciò che rende possibile la ricerca semantica e l’abbinamento intelligente dei contenuti su larga scala.
La vera potenza degli embedding emerge attraverso la similarità semantica, ovvero la capacità di riconoscere che parole o frasi diverse possono significare essenzialmente la stessa cosa nello spazio vettoriale. Quando gli embedding sono creati in modo efficace, i concetti semanticamente simili si raggruppano naturalmente nello spazio ad alta dimensione—“re” e “regina” sono vicini, così come “auto” e “veicolo”, anche se sono parole diverse. Per misurare questa similarità, i sistemi IA utilizzano metriche di distanza come la cosine similarity (che misura l’angolo tra i vettori) o il prodotto scalare (che misura ampiezza e direzione), che quantificano quanto due embedding siano vicini tra loro. Ad esempio, una query su “trasporto automobilistico” avrà un’alta similarità coseno con documenti su “viaggio in auto”, permettendo al sistema di abbinare i contenuti in base al significato piuttosto che alla sola corrispondenza delle parole chiave. Questa comprensione semantica è ciò che distingue la ricerca IA moderna dal semplice keyword matching, consentendo ai sistemi di comprendere l’intento dell’utente e restituire risultati realmente rilevanti.
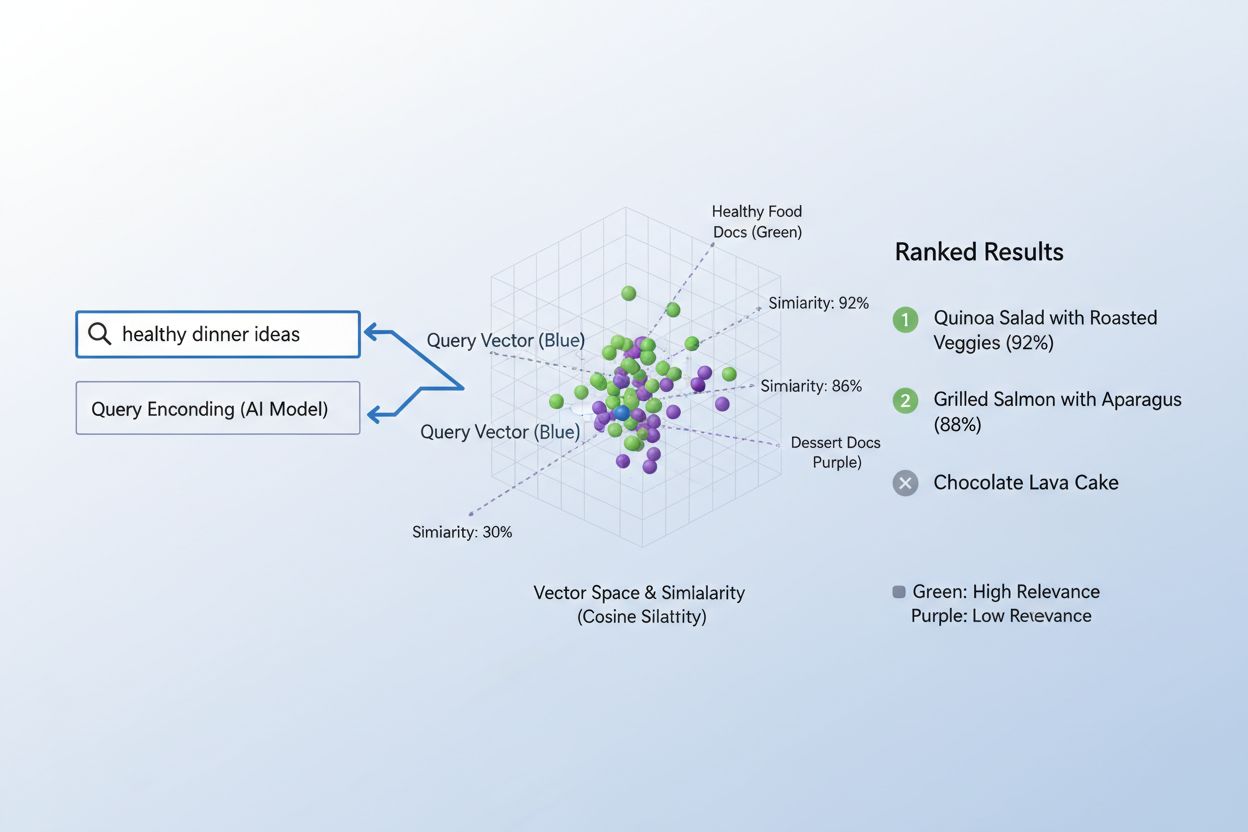
Il processo di abbinamento dei contenuti alle query tramite embedding segue un flusso di lavoro elegante in due fasi che alimenta tutto, dai motori di ricerca ai sistemi di raccomandazione. Prima di tutto, sia la query dell’utente che i contenuti disponibili vengono convertiti indipendentemente in embedding utilizzando lo stesso modello—una query come “migliori pratiche per il machine learning” diventa un vettore, così come ogni articolo, documento o prodotto nel database del sistema. Successivamente, il sistema calcola la similarità tra l’embedding della query e quello di ogni contenuto, tipicamente utilizzando la similarità coseno, che produce un punteggio indicante quanto ogni contenuto sia rilevante per la query. Questi punteggi di similarità vengono quindi ordinati, e i contenuti con il punteggio più alto vengono mostrati all’utente come risultati più pertinenti. In uno scenario reale di motore di ricerca, quando cerchi “come addestrare reti neurali”, il sistema codifica la tua query, la confronta con milioni di embedding di documenti e restituisce articoli su deep learning, ottimizzazione dei modelli e tecniche di training—tutto senza richiedere corrispondenze esatte di parole chiave. Questo processo di matching avviene in millisecondi, rendendolo pratico per applicazioni in tempo reale che servono milioni di utenti simultaneamente.
Diverse tipologie di embedding servono a scopi differenti a seconda di ciò che si intende abbinare o comprendere. Gli embedding di parole catturano il significato delle singole parole e sono ideali per compiti che richiedono comprensione semantica fine, mentre gli embedding di frasi e di documenti aggregano il significato su testi più lunghi, rendendoli perfetti per abbinare intere query ad articoli o documenti completi. Gli embedding di immagini rappresentano numericamente i contenuti visivi, permettendo ai sistemi di trovare immagini visivamente simili o di abbinarle a descrizioni testuali; gli embedding utente e di prodotto catturano pattern comportamentali e caratteristiche, alimentando i sistemi di raccomandazione che suggeriscono articoli in base alle preferenze dell’utente. La scelta tra queste tipologie di embedding comporta dei compromessi: quelli di parola sono efficienti ma perdono il contesto, mentre quelli di documento conservano il significato completo ma richiedono maggiore potenza di calcolo. Gli embedding specifici per settore, ottimizzati su dataset specializzati come letteratura medica o documenti legali, spesso superano i modelli generici per applicazioni di settore, sebbene richiedano dati di addestramento aggiuntivi e risorse computazionali maggiori.
Nella pratica, gli embedding alimentano alcune delle applicazioni IA più impattanti che usiamo ogni giorno, dai risultati di ricerca che visualizzi ai prodotti che ti vengono consigliati online. I motori di ricerca semantici utilizzano gli embedding per comprendere l’intento della query e mostrare contenuti rilevanti indipendentemente dalla corrispondenza esatta delle parole chiave, mentre i sistemi di raccomandazione di Netflix, Amazon e Spotify sfruttano embedding di utenti e articoli per prevedere cosa vorrai guardare, acquistare o ascoltare dopo. I sistemi di moderazione dei contenuti usano gli embedding per rilevare contenuti dannosi confrontando i post degli utenti con embedding di violazioni note delle policy, mentre i sistemi di question answering abbinano domande degli utenti ad articoli pertinenti della knowledge base trovando contenuti semanticamente simili. I motori di personalizzazione utilizzano gli embedding per capire le preferenze degli utenti e personalizzare le esperienze, e i sistemi di rilevamento anomalie identificano pattern insoliti riconoscendo quando nuovi dati si discostano dai cluster di embedding attesi. In AmICited, sfruttiamo gli embedding per monitorare come i sistemi IA vengono utilizzati in rete, abbinando query e contenuti per tracciare dove compaiono contenuti generati o assistiti dall’IA, aiutando i brand a comprendere la propria presenza IA e garantire la corretta attribuzione.
Implementare gli embedding in modo efficace richiede attenzione a diversi aspetti tecnici che incidono sia sulle prestazioni sia sui costi. La selezione del modello è cruciale—occorre bilanciare la qualità semantica degli embedding con i requisiti computazionali, con modelli più grandi come BERT che producono rappresentazioni più ricche ma richiedono maggiore potenza rispetto alle alternative leggere. La dimensionalità comporta un compromesso chiave: embedding ad alta dimensione catturano più sfumature ma consumano più memoria e rallentano i calcoli di similarità, mentre embedding a bassa dimensione sono più rapidi ma possono perdere informazioni semantiche importanti. Per gestire il matching su larga scala in modo efficiente, i sistemi utilizzano strategie di indicizzazione specializzate come FAISS (Facebook AI Similarity Search) o Annoy (Approximate Nearest Neighbors Oh Yeah), che permettono di trovare embedding simili in millisecondi invece che in secondi, organizzando i vettori in strutture ad albero o con hash sensibili alla località. L’ottimizzazione dei modelli di embedding su dati specifici di dominio può migliorare notevolmente la rilevanza per applicazioni specializzate, anche se richiede dati etichettati e maggiore potenza computazionale. Le organizzazioni devono continuamente bilanciare velocità e accuratezza, costi computazionali e qualità semantica, modelli generici e alternative specialistiche in base alle esigenze e ai vincoli specifici.
Il futuro degli embedding si sta orientando verso una maggiore sofisticazione, efficienza e integrazione con sistemi IA più ampi, promettendo capacità di abbinamento e comprensione dei contenuti ancora più potenti. Stanno emergendo embedding multimodali che elaborano contemporaneamente testo, immagini e audio, permettendo ai sistemi di abbinare tra diversi tipi di contenuto—trovare immagini rilevanti per una query testuale o viceversa—aprendo possibilità completamente nuove per la scoperta e la comprensione dei contenuti. I ricercatori stanno sviluppando modelli di embedding sempre più efficienti che offrono qualità semantica comparabile con molti meno parametri, rendendo le capacità IA avanzate accessibili anche a organizzazioni più piccole e dispositivi edge. L’integrazione degli embedding con i grandi modelli di linguaggio sta creando sistemi che non solo abbinano contenuti semanticamente, ma comprendono anche contesto, sfumature e intenti a livelli senza precedenti. Man mano che i sistemi di IA diventano più diffusi sulla rete, la capacità di tracciare, monitorare e comprendere come i contenuti vengono abbinati e utilizzati diventa sempre più importante—è qui che piattaforme come AmICited sfruttano gli embedding per aiutare le organizzazioni a monitorare la presenza del brand, tracciare i pattern di utilizzo IA e assicurare che i contenuti vengano correttamente attribuiti e usati in modo appropriato. La convergenza di embedding migliori, modelli più efficienti e strumenti di monitoraggio sofisticati sta creando un futuro in cui i sistemi IA sono più trasparenti, responsabili e allineati ai valori umani.
Un embedding vettoriale è una rappresentazione numerica di dati (testo, immagini, audio) in uno spazio ad alta dimensione che cattura significato semantico e relazioni. Converte dati astratti in array di numeri che le macchine possono elaborare e analizzare matematicamente.
Gli embedding trasformano dati astratti in numeri che le macchine possono elaborare, permettendo all’IA di identificare schemi, somiglianze e relazioni tra diversi contenuti. Questa rappresentazione matematica consente ai sistemi di IA di comprendere il significato piuttosto che limitarsi al matching di parole chiave.
Il matching delle parole chiave cerca corrispondenze esatte, mentre la similarità semantica comprende il significato. Questo consente ai sistemi di trovare contenuti correlati anche senza parole identiche—ad esempio, abbinando 'automobile' con 'auto' sulla base della relazione semantica invece che sull’esatto testo.
Sì, gli embedding possono rappresentare testo, immagini, audio, profili utente, prodotti e altro. Diversi modelli di embedding sono ottimizzati per diversi tipi di dati, da Word2Vec per il testo a CNN per le immagini fino agli spettrogrammi per l’audio.
AmICited utilizza gli embedding per comprendere come i sistemi di IA abbinano e fanno riferimento semanticamente al tuo brand su diverse piattaforme e risposte IA. Questo aiuta a tracciare la presenza dei tuoi contenuti nelle risposte generate dall’IA e garantire la corretta attribuzione.
Le sfide chiave includono la scelta del modello giusto, la gestione dei costi computazionali, il trattamento di dati ad alta dimensione, l’ottimizzazione per domini specifici e il bilanciamento tra velocità e accuratezza nei calcoli di similarità.
Gli embedding abilitano la ricerca semantica, che comprende l’intento dell’utente e restituisce risultati rilevanti basati sul significato invece che solo sulla corrispondenza delle parole chiave. Questo permette ai sistemi di trovare contenuti concettualmente correlati anche senza termini di query esatti.
I grandi modelli di linguaggio utilizzano gli embedding internamente per comprendere e generare testo. Gli embedding sono fondamentali per il modo in cui questi modelli elaborano le informazioni, abbinano i contenuti e generano risposte contestualmente appropriate.
Gli embedding vettoriali alimentano sistemi di IA come ChatGPT, Perplexity e Google AI Overviews. AmICited traccia come questi sistemi citano e fanno riferimento ai tuoi contenuti, aiutandoti a capire la presenza del tuo brand nelle risposte generate dall’IA.
Scopri cosa sono gli embedding, come funzionano e perché sono essenziali per i sistemi AI. Scopri come il testo si trasforma in vettori numerici che catturano i...

Scopri come funzionano gli embeddings nei motori di ricerca AI e nei modelli linguistici. Comprendi le rappresentazioni vettoriali, la ricerca semantica e il lo...
Scopri come la ricerca vettoriale utilizza gli embedding di machine learning per trovare elementi simili basandosi sul significato piuttosto che sulle parole ch...