Paginazione
La paginazione suddivide grandi insiemi di contenuti in pagine gestibili per una migliore UX e SEO. Scopri come funziona la paginazione, il suo impatto sul posi...
11 min di lettura

Scopri come la paginazione influisce sulla visibilità nell’IA. Scopri perché la suddivisione tradizionale delle pagine aiuta i sistemi di IA a trovare i tuoi contenuti mentre l’infinite scroll li nasconde, e come ottimizzare la paginazione per i generatori di risposte IA.
La paginazione è la pratica di suddividere grandi insiemi di contenuti in più pagine collegate. Sì, influisce significativamente sui sistemi di IA: la paginazione crea URL distinti e indicizzabili che aiutano i motori di ricerca IA come ChatGPT, Perplexity e SGE di Google a scoprire e indicizzare i tuoi contenuti in modo più efficace, mentre le implementazioni di infinite scroll spesso nascondono i contenuti ai crawler IA.
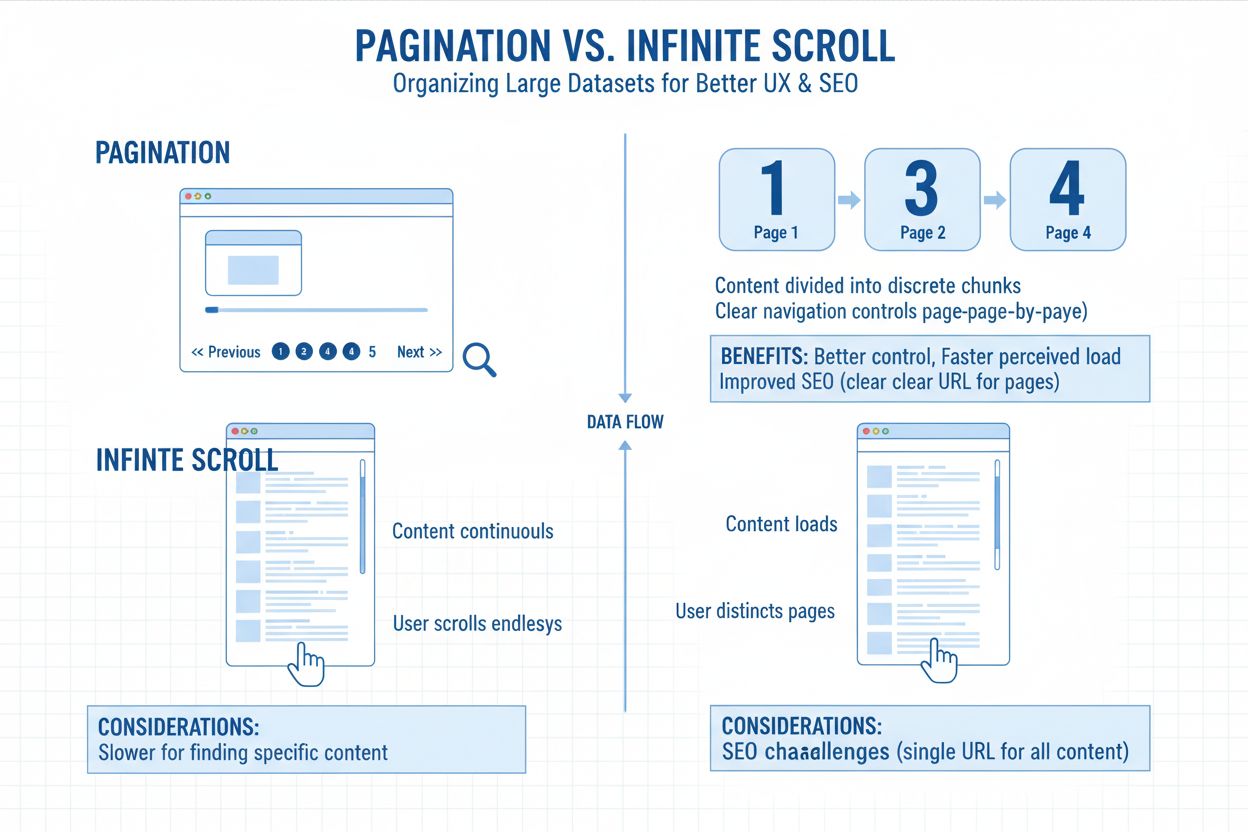
La paginazione si riferisce alla pratica di suddividere grandi insiemi di contenuti in più pagine collegate, invece di mostrare tutto su un’unica schermata infinita. Pensala come i capitoli di un libro: ogni pagina contiene una porzione gestibile del contenuto totale, collegata tramite link numerati o pulsanti “successivo/precedente”. Questo approccio strutturale è ovunque, dalle liste di prodotti nei negozi eCommerce agli archivi dei blog, thread dei forum e risultati di ricerca. La struttura degli URL riflette tipicamente questa divisione attraverso parametri come ?page=2 o percorsi puliti come /categoria/pagina/2/, permettendo sia agli utenti sia ai motori di ricerca di capire la loro posizione nella serie di contenuti. La paginazione funge da fondamentale strumento organizzativo che bilancia l’esperienza utente con i requisiti tecnici per l’accessibilità dei contenuti.
I siti web implementano la paginazione principalmente per ottimizzare le prestazioni e organizzare i contenuti. Caricare centinaia o migliaia di elementi contemporaneamente sovraccaricherebbe le risorse del server e rallenterebbe i tempi di caricamento della pagina, danneggiando in particolare le metriche che influenzano il posizionamento nei motori di ricerca. Gli utenti apprezzano la possibilità di salvare nei preferiti pagine specifiche, andare direttamente alla pagina 10 o capire quanto contenuto resta disponibile. Da una prospettiva tecnica, dividere i contenuti crea URL distinti che i motori di ricerca possono indicizzare singolarmente, preservando la distribuzione dell’equità dei link nell’architettura del sito. Questa chiarezza strutturale diventa sempre più importante man mano che i sistemi di IA si evolvono per comprendere le relazioni tra i contenuti e i modelli di accessibilità.
Il rapporto tra paginazione e visibilità nell’IA rappresenta una delle considerazioni SEO tecniche più critiche nel panorama moderno della ricerca. I motori di ricerca tradizionali come Google hanno da tempo compreso la paginazione seguendo i link e riconoscendo i pattern di pagine sequenziali. Tuttavia, i motori di ricerca e i generatori di risposte basati su IA operano in modo fondamentalmente diverso, richiedendo un approccio più sfumato all’organizzazione dei contenuti. I large language model che alimentano ChatGPT, Perplexity e la Search Generative Experience (SGE) di Google non necessariamente scansionano le pagine in modo lineare o seguono le gerarchie di navigazione tradizionali. Invece, lavorano tokenizzando e riassumendo input testuali—spesso derivati da dati pubblici, API o database strutturati più che da gerarchie di profondità di scansione.
Quando i tuoi contenuti sono distribuiti su più pagine con struttura minima, i motori di IA possono saltare le voci più profonde o fraintendere la loro relazione con l’insieme dei contenuti più ampio. Se c’è poca variazione nei metadati o segnali semantici deboli, i tuoi contenuti paginati sembrano ridondanti—o vengono ignorati del tutto. Questo crea una lacuna critica di visibilità: contenuti che si posizionano bene nella ricerca tradizionale di Google potrebbero restare completamente invisibili ai generatori di risposte IA. La distinzione è importante perché i sistemi di IA danno priorità a dati strutturati, completi e facilmente recuperabili. Non stanno “scorrendo” come un utente. Analizzano codice, URL e metadata per riassumere o citare contenuti con velocità e precisione. Se la tua pagina non espone i contenuti tramite URL indicizzabili o metadati ricchi, i motori di IA non possono recuperarli per includerli nelle risposte generate.
La scelta tra paginazione tradizionale e infinite scroll è diventata un fattore determinante per la scoperta dei contenuti da parte dell’IA. Le implementazioni di infinite scroll caricano i contenuti tramite JavaScript solo dopo l’interazione dell’utente, creando un problema fondamentale di accessibilità per i crawler IA. La maggior parte delle configurazioni di infinite scroll non espone i contenuti attraverso URL distinti—caricano tutto su una sola pagina tramite esecuzione dinamica di JavaScript. Questo significa che i crawler IA, che non simulano il comportamento reale dell’utente come lo scroll o il click, spesso si perdono tutto ciò che va oltre la prima visualizzazione. Se la tua pagina non espone quei contenuti extra tramite URL indicizzabili o metadati, i motori di IA non possono recuperarli. Potresti avere 200 articoli, 300 prodotti o decine di case study, ma se sono nascosti dietro eventi di caricamento attivati da JavaScript, l’IA vede solo 12 elementi. Forse.
La paginazione tradizionale vince ancora nettamente per l’indicizzazione IA perché produce URL puliti e indicizzabili (es. /blog/pagina/4), permettendo ai motori di accedere e segmentare completamente i tuoi contenuti. Segnala la struttura tematica tramite collegamenti interni, utilizzando link standardizzati come “Pagina successiva” o “Pagina precedente” per aiutare i motori a capire come i contenuti sono collegati. La paginazione limita la dipendenza dal JavaScript, garantendo che i tuoi contenuti vengano caricati per i crawler indipendentemente da come l’utente interagisce con la pagina. Questa chiarezza strutturale si traduce direttamente in una migliore visibilità nell’IA—quando ChatGPT o Perplexity scansionano il tuo sito, possono scoprire e indicizzare i contenuti paginati molto più efficacemente rispetto ai contenuti nascosti dietro implementazioni di infinite scroll.
| Aspetto | Paginazione | Infinite Scroll |
|---|---|---|
| Accessibilità alla scansione | URL unici consentono indicizzazione profonda | Contenuto spesso nascosto dietro caricamenti JS |
| Scoperta da parte dell’IA | Più pagine possono posizionarsi indipendentemente | Tipicamente viene indicizzata solo una pagina |
| Dati strutturati | Più facile da assegnare alle singole pagine | Spesso mancanti o diluiti |
| Collegamento diretto | Facile collegarsi a contenuti specifici | Difficile creare link profondi diretti |
| Compatibilità sitemap | Compatibile e completa | Spesso omette contenuti profondi |
| Struttura URL | URL chiari e distinti per pagina | Un solo URL con caricamento dinamico |
| Visibilità dei contenuti | Tutti i contenuti accessibili ai crawler | I contenuti richiedono esecuzione JS |
L’architettura tecnica dell’infinite scroll crea barriere fondamentali alla scoperta dei contenuti da parte dell’IA. Quando i contenuti si caricano solo tramite JavaScript, e nessun URL riflette quei nuovi contenuti, i motori IA non li vedranno mai. Per un crawler, il resto dell’elenco semplicemente non esiste. Non è un limite dei sistemi IA—è una conseguenza di come l’infinite scroll viene tipicamente implementato. La maggior parte delle configurazioni infinite scroll privilegia l’esperienza utente sull’accessibilità tecnica, caricando i contenuti dinamicamente senza creare URL o metadati corrispondenti che i sistemi IA possano analizzare.
Considera un caso reale: un rivenditore di moda globale ha ridisegnato il sito con un’interfaccia infinite scroll accattivante. Le prestazioni del sito sono migliorate, i dati di engagement sembravano ottimi, ma il traffico proveniente dai riassunti IA è crollato drasticamente. I loro SKU sembravano spariti dagli strumenti di ricerca conversazionale. Dopo un audit dell’architettura, il problema era chiaro: l’intero catalogo era nascosto dietro infinite scroll senza fallback indicizzabili. Nessun URL di pagina secondaria. Nessun collegamento supplementare. Solo una lunga lista di prodotti invisibile. Google SGE e ChatGPT non riuscivano ad accedere a più di una dozzina di prodotti per categoria. Per quanto bello fosse il sito, la sua scoperta era compromessa per i sistemi IA.
Una corretta implementazione della paginazione richiede attenzione a più fattori tecnici che insieme determinano se i sistemi IA possono scoprire e citare i tuoi contenuti. La base parte da strutture URL pulite e logiche che indicano chiaramente le relazioni sequenziali. Che tu utilizzi parametri di query (?page=2) o strutture basate su percorso (/pagina/2/), la coerenza conta più del formato scelto. Entrambi gli approcci funzionano egualmente bene per i sistemi IA se implementati correttamente. Ciò che importa è che ogni URL paginato carichi contenuti distinti e sia accessibile tramite link HTML standard che non richiedano l’esecuzione di JavaScript.
I tag canonical autoreferenziali rappresentano un punto decisionale critico per la strategia di paginazione. Ogni pagina paginata dovrebbe includere un tag canonical che punta a sé stessa, segnalando che quella pagina è la versione preferita di sé stessa. Questo approccio preserva l’indipendenza degli URL sequenziali, permettendo a ciascuno di competere per il posizionamento in base ai propri contenuti e alla rilevanza per diverse query. Evita la pratica obsoleta di canonicalizzare tutte le pagine paginate sulla pagina uno—questo consolida i segnali ma elimina la possibilità che le pagine singole si posizionino indipendentemente nei sistemi IA. Canonicalizzando tutto su pagina uno, stai dicendo esplicitamente ai motori IA di ignorare pagine potenzialmente preziose che contengono prodotti, contenuti o informazioni uniche.
Metadati unici per ogni pagina diventano fondamentali per la visibilità nell’IA. Non usare titoli generici tipo “Pagina 2” o descrizioni duplicate nella sequenza. Scrivi invece metadati specifici per pagina e ricchi di keyword che riflettano il focus di ciascuna. Ad esempio, invece di “Prodotti - Pagina 2”, usa “Scarpe sportive donna sotto i 100€ - Pagina 2” o “Tendenze IA nel Retail – Case Library (Pagina 2)”. Questa chiarezza favorisce la visibilità perché i sistemi IA comprendono il contesto e determinano meglio quando i tuoi contenuti sono rilevanti per query specifiche. Ogni set di metadati deve seguire principi di chiarezza, unicità e allineamento delle keyword. L’obiettivo è rendere lo scopo di ogni pagina ovvio sia per le IA sia per i lettori umani.
L’architettura dei collegamenti interni determina se i sistemi IA possono scoprire e navigare efficientemente tra pagine sequenziali. Una struttura lineare (pagina 1 → 2 → 3) crea percorsi di scansione lunghi dove le pagine profonde sono a molti click dalla homepage, lasciando potenzialmente contenuti preziosi inesplorati. Implementazioni intelligenti includono link complementari come opzioni “Visualizza tutto” o hub di categoria che collegano direttamente alle pagine chiave, riducendo la profondità di scansione e distribuendo l’equità dei link in modo più uniforme. Il rapporto tra navigazione a faccette e pagine sequenziali aggiunge complessità, poiché le combinazioni di filtri possono generare migliaia di variazioni URL. Un corretto linking interno assicura che le pagine prioritarie ricevano l’attenzione dei crawler mentre combinazioni meno rilevanti vengano de-prioritizzate tramite l’uso strategico di tag noindex o segnali canonical.
Catene strategiche di collegamenti interni dai contenuti pillar verso pagine paginate specifiche guidano i sistemi IA nella struttura dei tuoi contenuti. Dalla pagina principale di una categoria, collega direttamente pagine paginate specifiche usando anchor text che aiuti la comprensione IA. Esempio: “Scopri altre storie di successo eCommerce nella nostra serie di case study – pagina 3.” Il segnale deve essere chiaro e facilmente individuabile. Questo approccio insegna ai sistemi IA come i tuoi contenuti sono collegati e come dovrebbero essere scoperti. Quando i crawler IA incontrano questi link contestuali, comprendono la relazione tra le pagine e determinano meglio quali contenuti sono più pertinenti per query specifiche.
Problemi di contenuti duplicati emergono quando più URL mostrano contenuti identici o sostanzialmente simili senza una differenziazione adeguata. Ciò avviene quando le pagine sequenziali mancano di elementi unici oltre agli elementi elencati, o quando i parametri URL creano più percorsi allo stesso contenuto. I motori di ricerca e i sistemi IA fanno fatica a determinare quale versione indicizzare, frammentando potenzialmente la visibilità su più URL. Inoltre, se le pagine paginate includono solo testo ricorrente, header e footer con pochi contenuti unici, possono essere percepite come pagine sottili di scarso valore. La soluzione richiede un uso attento dei tag canonical, meta description uniche per ogni pagina, e assicurarsi che ogni pagina offra un valore distintivo oltre agli elementi di navigazione e alle sezioni template.
Implementazioni solo JavaScript rappresentano forse l’errore più comune che nasconde i contenuti ai sistemi IA. Se il tuo sito usa framework come React o Angular per rendere i controlli di pagina solo lato client senza rendering server-side, i crawler IA potrebbero non scoprire mai i contenuti oltre la pagina uno. Assicurati che i link di navigazione esistano nell’HTML iniziale ricevuto dai sistemi IA, non generati esclusivamente tramite JavaScript dopo il caricamento della pagina. Usa l’enhancement progressivo—link HTML di base che JavaScript può migliorare con interazioni più fluide e animazioni. Testa la tua implementazione con strumenti che mostrino esattamente cosa vedono i crawler rispetto a ciò che mostrano i browser con JavaScript abilitato. Questo rivela lacune nell’indicizzabilità che potrebbero costarti visibilità nell’IA.
Monitorare l’efficacia della paginazione richiede di osservare come i sistemi IA interagiscono con i tuoi contenuti multipagina. A differenza della SEO tradizionale dove Google Search Console offre insight diretti, il monitoraggio della visibilità IA richiede approcci diversi. Strumenti come Screaming Frog SEO Spider possono scansionare il tuo sito in modo simile ai sistemi IA, mappando la struttura delle pagine e identificando pagine orfane o problemi di profondità di scansione. DeepCrawl e Sitebulk offrono analisi avanzate con visualizzazione delle relazioni tra pagine. Google Search Console fornisce insight dal punto di vista di Google, mostrando quali URL paginati sono indicizzati e i pattern di frequenza di scansione.
Gli indicatori chiave di prestazione per i contenuti paginati includono se le pagine profonde compaiono nelle risposte generate dall’IA, quanto spesso i sistemi IA citano i tuoi contenuti paginati, e se diverse pagine si posizionano per query long-tail differenti. Monitora le tue menzioni di brand nelle risposte IA—se i sistemi IA citano costantemente la tua pagina uno ma non menzionano mai le pagine più profonde, la tua struttura di paginazione potrebbe necessitare ottimizzazione. Traccia quali pagine paginate generano più traffico da fonti IA. Questi dati rivelano se la tua strategia di paginazione espone efficacemente i contenuti ai sistemi IA o se è necessario ristrutturare. Audit regolari intercettano problemi prima che incidano sulla visibilità, in particolare dopo aggiornamenti del sito o migrazioni di framework.
Il panorama della ricerca basata sull’IA continua a evolversi rapidamente, con nuovi sistemi e funzionalità che emergono regolarmente. Le strategie di paginazione che funzionano oggi dovrebbero rimanere efficaci man mano che i sistemi IA diventano più sofisticati, ma restare al passo richiede comprensione delle tendenze emergenti. Gli algoritmi di ricerca IA sono sempre più abili a comprendere le relazioni tra i contenuti e a determinare quali pagine paginate meritano priorità di indicizzazione. Il neural matching e la comprensione basata su BERT di Google aiutano i motori a riconoscere che la pagina due di una categoria offre prodotti diversi rispetto alla pagina uno, anche se il testo circostante è simile. Questa comprensione migliorata significa che una suddivisione ben strutturata delle pagine con differenze significative tra di esse trae più benefici che mai dall’indicizzazione indipendente.
Tuttavia, l’IA rileva meglio anche i contenuti davvero sottili o duplicati sulle pagine paginate, rendendo più difficile “ingannare” il sistema con pagine poco differenziate. Gli algoritmi di machine learning prevedono l’intento dell’utente con maggiore precisione, facendo emergere potenzialmente anche paginazioni profonde per query long-tail specifiche quando tali pagine corrispondono meglio all’intento di ricerca. L’implicazione pratica è assicurare che ogni pagina paginata offra reale valore unico—prodotti distintivi, contenuti diversi, o variazioni significative—invece di semplici divisioni meccaniche di informazioni identiche. Man mano che i sistemi IA continuano a evolversi, i principi fondamentali restano invariati: URL distinti, link indicizzabili, valore unico per pagina e metadati chiari continueranno a determinare l’efficacia della paginazione per la visibilità nell’IA.
Traccia come i tuoi contenuti vengono visualizzati nelle risposte generate dall'IA su ChatGPT, Perplexity e altri motori di ricerca IA. Assicurati che il tuo brand venga citato quando i sistemi di IA rispondono alle domande sul tuo settore.
La paginazione suddivide grandi insiemi di contenuti in pagine gestibili per una migliore UX e SEO. Scopri come funziona la paginazione, il suo impatto sul posi...
Le Pagine per sessione misurano la media delle pagine visualizzate per visita. Scopri come questa metrica di coinvolgimento influenza il comportamento degli ute...
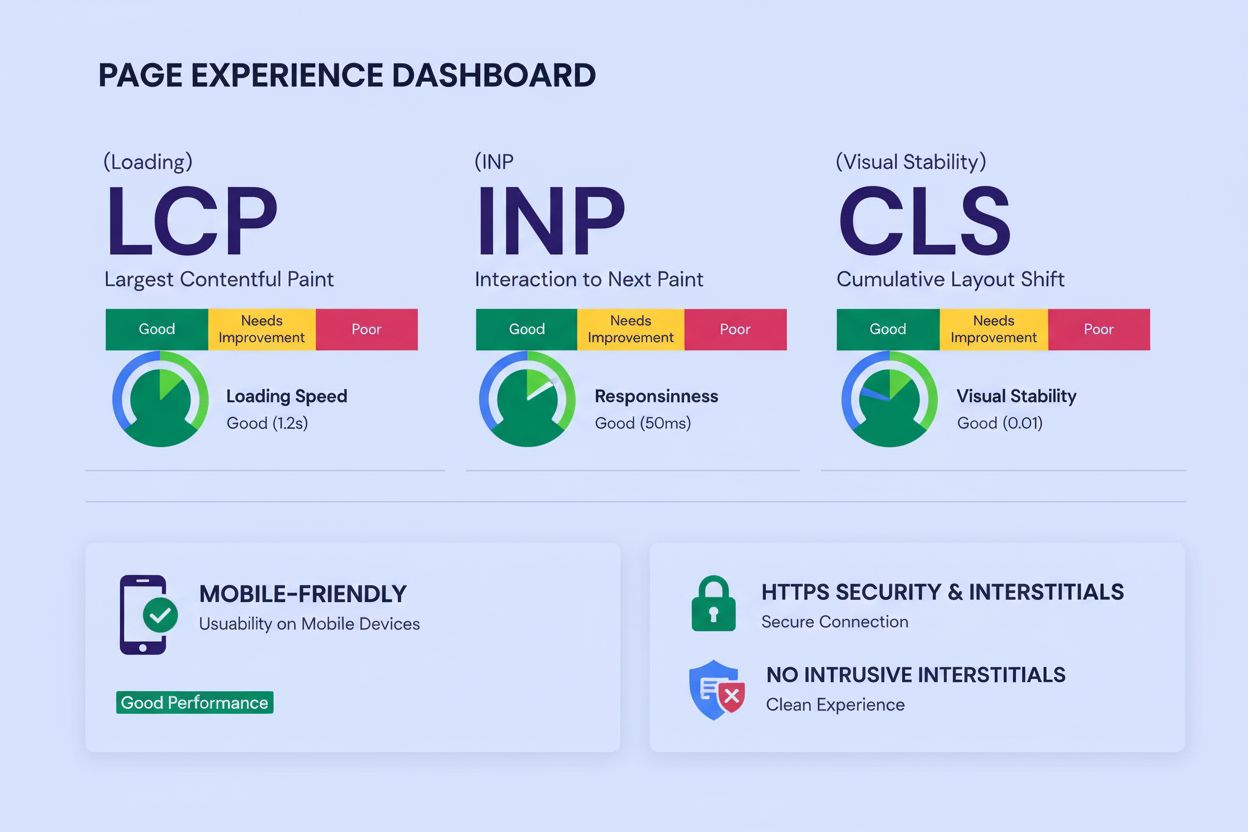
L'Esperienza della Pagina misura la qualità dell'interazione dell'utente tramite Core Web Vitals, compatibilità mobile, sicurezza HTTPS e interstitial invasivi....