Meccanismi tecnici e legali che consentono a creatori di contenuti e titolari di diritti d’autore di impedire che il proprio lavoro venga utilizzato nei dataset di addestramento di grandi modelli linguistici. Questi includono direttive robots.txt, dichiarazioni legali di esclusione e tutele contrattuali previste da regolamenti come l’AI Act dell’UE.
Esclusione dall’addestramento AI
Meccanismi tecnici e legali che consentono a creatori di contenuti e titolari di diritti d'autore di impedire che il proprio lavoro venga utilizzato nei dataset di addestramento di grandi modelli linguistici. Questi includono direttive robots.txt, dichiarazioni legali di esclusione e tutele contrattuali previste da regolamenti come l’AI Act dell’UE.
Che cos’è l’Esclusione dall’Addestramento AI?
L’esclusione dall’addestramento AI si riferisce ai meccanismi tecnici e legali che permettono a creatori di contenuti, titolari di diritti d’autore e proprietari di siti web di impedire che il proprio lavoro venga utilizzato nei dataset di addestramento dei grandi modelli linguistici (LLM). Poiché le aziende AI raccolgono enormi quantità di dati dal web per addestrare modelli sempre più sofisticati, la possibilità di controllare se i propri contenuti partecipino a questo processo è diventata essenziale per proteggere la proprietà intellettuale e mantenere il controllo creativo. Questi meccanismi di esclusione operano su due livelli: direttive tecniche che istruiscono i crawler AI a saltare i tuoi contenuti e quadri giuridici che stabiliscono diritti contrattuali per escludere il proprio lavoro dai dataset di addestramento. Comprendere entrambe le dimensioni è fondamentale per chiunque sia interessato all’uso dei propri contenuti nell’era dell’AI.
Meccanismi Tecnici: robots.txt e User Agent
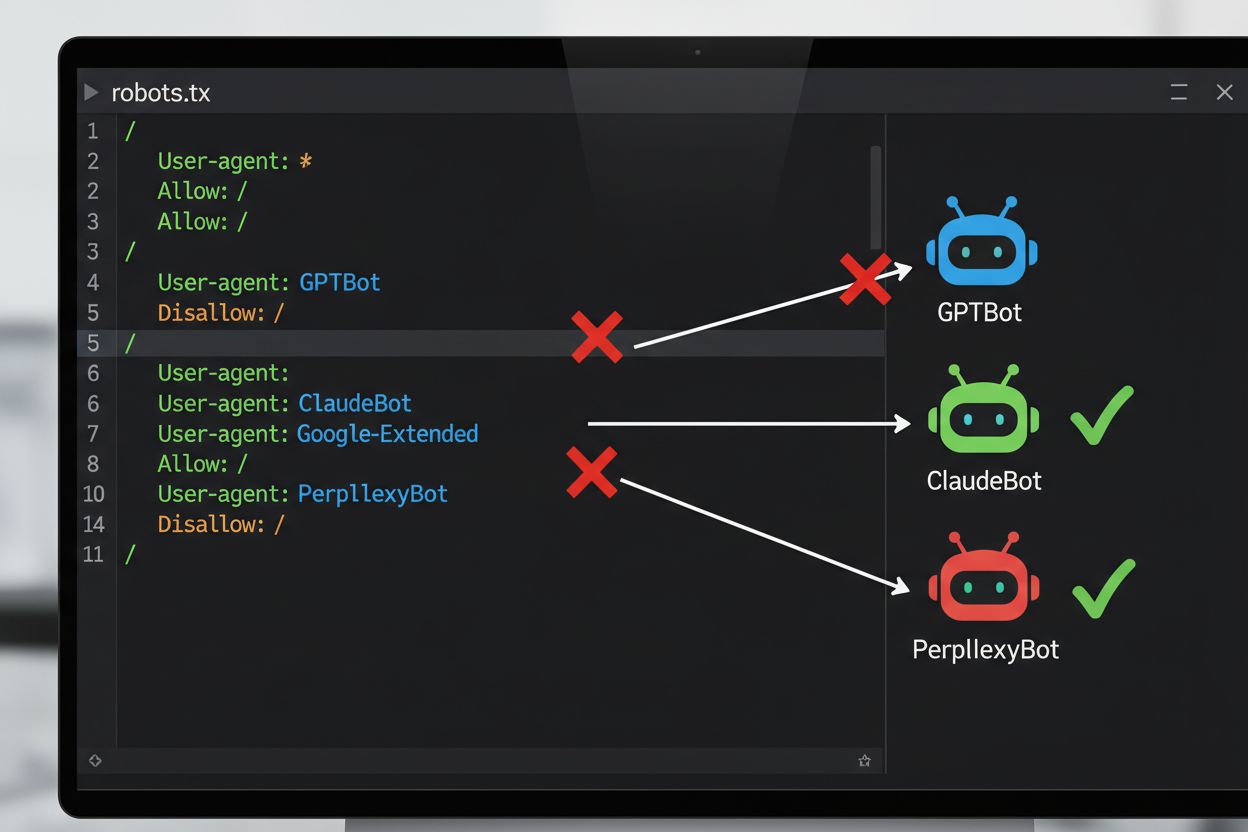
Il metodo tecnico più comune per escludersi dall’addestramento AI è tramite il file robots.txt, un semplice file di testo posizionato nella directory principale di un sito che comunica i permessi di accesso ai bot automatici. Quando un crawler AI visita il tuo sito, controlla innanzitutto robots.txt per vedere se gli è consentito accedere ai contenuti. Aggiungendo specifiche direttive di disallow per determinati user agent dei crawler, puoi istruire i bot AI a saltare completamente il tuo sito. Ogni azienda AI opera con più crawler dotati di identificatori user agent distinti—questi sono essenzialmente i “nomi” che i bot usano per identificarsi nelle richieste. Ad esempio, GPTBot di OpenAI si identifica con la stringa user agent “GPTBot”, mentre Claude di Anthropic usa “ClaudeBot”. La sintassi è semplice: specifichi il nome dell’user agent e poi dichiari quali percorsi sono vietati, come “Disallow: /” per bloccare l’intero sito.
Azienda AI
Nome Crawler
Token User Agent
Scopo
OpenAI
GPTBot
GPTBot
Raccolta dati per addestramento modelli
OpenAI
OAI-SearchBot
OAI-SearchBot
Indicizzazione ricerca ChatGPT
Anthropic
ClaudeBot
ClaudeBot
Recupero citazioni chat
Google
Google-Extended
Google-Extended
Addestramento dati Gemini AI
Perplexity
PerplexityBot
PerplexityBot
Indicizzazione ricerca AI
Meta
Meta-ExternalAgent
Meta-ExternalAgent
Addestramento modelli AI
Common Crawl
CCBot
CCBot
Dataset aperto per addestramento LLM
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Il panorama legale relativo all’esclusione dall’addestramento AI si è evoluto notevolmente con l’introduzione dell’AI Act dell’UE, entrato in vigore nel 2024 e che incorpora disposizioni dalla Direttiva sul Text and Data Mining (TDM). Secondo queste normative, gli sviluppatori di AI possono utilizzare opere protette da copyright per scopi di machine learning solo se hanno accesso legittimo ai contenuti e il titolare dei diritti non ha espressamente riservato il diritto di escludere la propria opera dal text and data mining. Questo crea un meccanismo legale formale di esclusione: i titolari dei diritti possono depositare riserve di esclusione insieme alle proprie opere, impedendone così l’uso nell’addestramento AI senza permesso esplicito. L’AI Act dell’UE rappresenta un cambiamento significativo rispetto all’approccio precedente del “muoversi velocemente e rompere le regole”, stabilendo che le aziende che addestrano modelli AI devono verificare se i titolari dei diritti hanno riservato i propri contenuti e implementare salvaguardie tecniche e organizzative per prevenire l’uso involontario di opere escluse. Questo quadro legale si applica in tutta l’Unione Europea e influenza il modo in cui le aziende AI globali affrontano la raccolta dati e le pratiche di addestramento.
Come Funzionano i Meccanismi di Esclusione nella Pratica
Implementare un meccanismo di esclusione richiede sia configurazione tecnica che documentazione legale. Dal punto di vista tecnico, i proprietari di siti web aggiungono direttive di disallow nel file robots.txt per specifici user agent dei crawler AI, che i crawler conformi rispetteranno quando visitano il sito. Dal punto di vista legale, i titolari dei diritti possono depositare dichiarazioni di esclusione presso società di gestione collettiva e organizzazioni di diritti—ad esempio, la società olandese Pictoright e la società musicale francese SACEM hanno stabilito procedure formali di esclusione che consentono ai creatori di riservare i propri diritti contro l’uso nell’addestramento AI. Molti siti web e creatori di contenuti ora includono dichiarazioni esplicite di esclusione nei termini di servizio o nei metadati, dichiarando che i propri contenuti non devono essere utilizzati per l’addestramento di modelli AI. Tuttavia, l’efficacia di tali meccanismi dipende dalla conformità dei crawler: sebbene aziende come OpenAI, Google e Anthropic abbiano dichiarato pubblicamente di rispettare le direttive robots.txt e le riserve di esclusione, l’assenza di un meccanismo centralizzato di enforcement implica che verificare se una richiesta di esclusione sia stata effettivamente rispettata richiede monitoraggio e verifica continui.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Sfide e Limiti dell’Esclusione
Nonostante la disponibilità di meccanismi di esclusione, permangono sfide significative che ne limitano l’efficacia:
Standard Volontario: robots.txt è una “gentleman’s agreement” senza forza esecutiva legale, quindi i crawler non conformi possono ignorare le tue direttive
Evasione dei Crawler: bot sofisticati possono camuffare la stringa user agent per sembrare browser legittimi, aggirando i blocchi basati sull’user agent
Rotazione IP: gli scraper possono ruotare tra centinaia di migliaia di indirizzi IP tramite proxy o botnet, rendendo inefficaci i blocchi basati su IP
Copertura Incompleta: robots.txt blocca circa il 40-60% dei bot AI, lasciando un traffico significativo non bloccato senza misure tecniche aggiuntive
Crawler Non Autorizzati: aziende AI non affidabili e scraper indipendenti possono ignorare completamente i meccanismi di esclusione, operando in aree legali grigie
Lacune nell’Enforcement: anche in caso di violazione dell’esclusione, il ricorso legale è costoso e lento, con esiti incerti in tribunale
Metodi di Implementazione Tecnica Oltre robots.txt
Per le organizzazioni che richiedono una protezione più forte rispetto al solo robots.txt, esistono diversi metodi tecnici aggiuntivi. Il filtraggio degli user agent a livello di server o firewall può bloccare le richieste provenienti da identificatori specifici di crawler prima che raggiungano la tua applicazione, anche se questo metodo resta vulnerabile al camuffamento. Il blocco degli indirizzi IP può mirare agli intervalli IP noti dei principali crawler AI, anche se scraper determinati possono aggirare il blocco tramite reti proxy. Il rate limiting e il throttling possono rallentare gli scraper limitando il numero di richieste consentite al secondo, rendendo lo scraping economicamente sconveniente, ma bot sofisticati possono distribuire le richieste su più IP per aggirare questi limiti. Requisiti di autenticazione e paywall forniscono una protezione forte limitando l’accesso agli utenti registrati o paganti, impedendo di fatto lo scraping automatico. Device fingerprinting e analisi comportamentale possono rilevare i bot analizzando pattern come API browser, handshake TLS e schemi di interazione che differiscono dai visitatori umani. Alcune organizzazioni hanno persino implementato honeypot e tarpit—link nascosti o labirinti infiniti di link che solo i bot seguirebbero—per sprecare risorse dei crawler e potenzialmente inquinare i loro dataset di addestramento con dati inutili.
Esempi Pratici e Casi di Studio
La tensione tra aziende AI e creatori di contenuti ha prodotto diversi scontri di alto profilo che illustrano le sfide pratiche dell’enforcement dell’esclusione. Reddit ha adottato una posizione aggressiva nel 2023 aumentando drasticamente i prezzi di accesso alle API, in particolare per far pagare le aziende AI per i dati, escludendo di fatto gli scraper non autorizzati e costringendo aziende come OpenAI e Anthropic a negoziare accordi di licenza. Twitter/X ha implementato misure ancora più drastiche, bloccando temporaneamente ogni accesso non autenticato ai tweet e limitando il numero di tweet leggibili dagli utenti loggati, mirando esplicitamente agli scraper di dati. Stack Overflow ha inizialmente bloccato GPTBot di OpenAI nel proprio robots.txt a causa di preoccupazioni sulle licenze del codice degli utenti, per poi rimuovere il blocco—probabilmente a seguito di trattative con OpenAI. Le organizzazioni di news hanno risposto in massa: oltre il 50% dei principali siti di notizie ha bloccato i crawler AI già nel 2023, con testate come The New York Times, CNN, Reuters e The Guardian che hanno aggiunto GPTBot alle proprie disallow list. Alcuni gruppi editoriali hanno intrapreso azioni legali, come The New York Times che ha citato OpenAI per violazione del copyright, mentre altri come Associated Press hanno negoziato accordi di licenza per monetizzare i propri contenuti. Questi esempi dimostrano che, sebbene i meccanismi di esclusione esistano, la loro efficacia dipende sia dall’implementazione tecnica che dalla volontà di agire legalmente in caso di violazioni.
Strumenti di Monitoraggio e Conformità
Implementare meccanismi di esclusione è solo metà del lavoro; verificarne l’effettivo funzionamento richiede monitoraggio e test continui. Diversi strumenti possono aiutare a validare la configurazione: Google Search Console include un tester robots.txt per la validazione specifica di Googlebot, mentre Merkle’s Robots.txt Tester e lo strumento di TechnicalSEO.com testano il comportamento dei singoli crawler per specifici user agent. Per un monitoraggio completo del rispetto delle direttive di esclusione da parte delle aziende AI, piattaforme come AmICited.com offrono monitoraggio specializzato che tiene traccia di come i sistemi AI citano il tuo brand e i tuoi contenuti su GPT, Perplexity, Google AI Overviews e altre piattaforme AI. Questo tipo di monitoraggio è particolarmente prezioso perché rivela non solo se i crawler stanno accedendo al tuo sito, ma anche se i tuoi contenuti compaiono effettivamente nelle risposte generate dall’AI—indicando l’efficacia reale della tua esclusione. Un’analisi regolare dei log del server può anche mostrare quali crawler tentano di accedere al sito e se rispettano le direttive robots.txt, anche se è necessaria competenza tecnica per interpretare correttamente i dati.
Best Practice per Creatori di Contenuti
Per proteggere efficacemente i tuoi contenuti dall’uso non autorizzato nell’addestramento AI, adotta un approccio a più livelli combinando misure tecniche e legali. Innanzitutto, implementa direttive robots.txt per tutti i principali crawler AI di addestramento (GPTBot, ClaudeBot, Google-Extended, PerplexityBot, CCBot e altri), consapevole che questa rappresenta una difesa di base contro le aziende conformi. In secondo luogo, aggiungi dichiarazioni esplicite di esclusione nei termini di servizio e nei metadati del tuo sito, dichiarando chiaramente che i tuoi contenuti non devono essere utilizzati per l’addestramento di modelli AI—aumentando la tua posizione legale in caso di violazioni. In terzo luogo, monitora regolarmente la configurazione tramite strumenti di test e analisi dei log per verificare che i crawler rispettino le tue direttive, e aggiorna il tuo robots.txt ogni trimestre poiché emergono costantemente nuovi crawler AI. In quarto luogo, considera misure tecniche aggiuntive come il filtraggio degli user agent o il rate limiting se hai risorse tecniche, riconoscendo che queste offrono protezione incrementale contro gli scraper più sofisticati. Infine, documenta accuratamente i tuoi sforzi di esclusione, poiché questa documentazione sarà fondamentale in caso di azioni legali contro aziende che ignorano le tue direttive. Ricorda che l’esclusione non è una configurazione “una tantum”, ma un processo continuo che richiede vigilanza e adattamento man mano che il panorama AI evolve.
Domande frequenti
Qual è la differenza tra esclusione tramite robots.txt ed esclusione legale?
robots.txt è uno standard tecnico e volontario che istruisce i crawler a saltare i tuoi contenuti, mentre l’esclusione legale implica la presentazione di riserve formali presso organizzazioni di gestione dei diritti o l’inclusione di clausole contrattuali nei tuoi termini di servizio. robots.txt è più facile da implementare ma manca di forza esecutiva, mentre l’esclusione legale offre una protezione giuridica più forte ma richiede procedure più formali.
Tutte le aziende AI rispettano le direttive robots.txt?
Le principali aziende AI come OpenAI, Google, Anthropic e Perplexity hanno dichiarato pubblicamente di rispettare le direttive robots.txt. Tuttavia, robots.txt è uno standard volontario senza meccanismo di applicazione, quindi crawler non conformi e scraper non autorizzati possono ignorare completamente le tue direttive.
Bloccare i bot di addestramento AI influenzerà il posizionamento nei motori di ricerca?
No. Bloccare crawler di addestramento AI come GPTBot e ClaudeBot non avrà impatto sul posizionamento su Google o Bing, poiché i motori di ricerca tradizionali utilizzano crawler diversi (Googlebot, Bingbot) che operano in modo indipendente. Blocca questi ultimi solo se desideri scomparire completamente dai risultati di ricerca.
Qual è l’approccio dell’AI Act dell’UE all’esclusione?
L’AI Act dell’UE richiede che gli sviluppatori di AI abbiano accesso legittimo ai contenuti e debbano rispettare le riserve di esclusione dei titolari dei diritti d’autore. I titolari dei diritti possono depositare dichiarazioni di esclusione insieme alle proprie opere, impedendone di fatto l’uso nell’addestramento AI senza un esplicito permesso. Questo crea un meccanismo legale formale per proteggere i contenuti dall’uso non autorizzato nell’addestramento.
Posso usare l’esclusione per impedire che i miei contenuti compaiano nei risultati di ricerca AI?
Dipende dal meccanismo specifico. Bloccare tutti i crawler AI impedirà ai tuoi contenuti di comparire nei risultati di ricerca AI, ma ciò ti esclude anche completamente dalle piattaforme di ricerca basate su AI. Alcuni editori preferiscono un blocco selettivo—consentendo i crawler focalizzati sulla ricerca e bloccando quelli dedicati all’addestramento—per mantenere la visibilità nella ricerca AI proteggendo al contempo i contenuti dall’addestramento dei modelli.
Cosa succede se un’azienda AI ignora la mia richiesta di esclusione?
Se un’azienda AI ignora le tue direttive di esclusione, hai la possibilità di ricorrere legalmente tramite reclami per violazione del copyright o per inadempienza contrattuale, a seconda della giurisdizione e delle circostanze specifiche. Tuttavia, le azioni legali sono costose e lente, con esiti incerti. Per questo il monitoraggio e la documentazione dei tuoi sforzi di esclusione sono fondamentali.
Con quale frequenza devo aggiornare la mia configurazione di esclusione?
Rivedi e aggiorna la configurazione del tuo robots.txt almeno ogni trimestre. Continuamente emergono nuovi crawler AI e le aziende introducono frequentemente nuovi agenti utente dei crawler. Ad esempio, Anthropic ha fuso i bot 'anthropic-ai' e 'Claude-Web' in 'ClaudeBot', dando a quest’ultimo accesso temporaneo illimitato ai siti che non avevano aggiornato le regole.
L’esclusione è efficace contro tutti i crawler AI?
L’esclusione è efficace contro aziende AI affidabili e conformi che rispettano robots.txt e i quadri legali. Tuttavia, è meno efficace contro crawler non autorizzati e scraper non conformi che operano in aree grigie legali. robots.txt blocca circa il 40-60% dei bot AI, motivo per cui è consigliato un approccio a più livelli che combini varie misure tecniche e legali.
Monitora come l’AI cita i tuoi contenuti
Tieni traccia se i tuoi contenuti compaiono nelle risposte generate da AI su ChatGPT, Perplexity, Google AI Overviews e altre piattaforme AI con AmICited.
Implicazioni sul Copyright dei Motori di Ricerca IA e dell'IA Generativa
Comprendi le sfide di copyright che affrontano i motori di ricerca IA, i limiti dell'equo utilizzo, le recenti cause legali e le implicazioni legali per le risp...
Audit di Accesso dei Crawler AI: I Bot Giusti Vedono i Tuoi Contenuti?
Scopri come eseguire un audit dell'accesso dei crawler AI al tuo sito web. Scopri quali bot possono vedere i tuoi contenuti e risolvi i blocchi che impediscono ...
Il rilevamento dei contenuti AI influisce sul posizionamento nei motori di ricerca? Cosa dice la ricerca
Scopri se il rilevamento AI influisce sulle classifiche SEO. Le ricerche dimostrano che Google non penalizza i contenuti AI. Concentrati invece su qualità, E-E-...
10 min di lettura
Consenso Cookie Usiamo i cookie per migliorare la tua esperienza di navigazione e analizzare il nostro traffico. See our privacy policy.