Tecniche per garantire che i crawler AI accedano e indicizzino in modo efficiente i contenuti più importanti di un sito web entro i limiti del loro crawl. L’ottimizzazione del crawl budget gestisce l’equilibrio tra la capacità di scansione (risorse del server) e la domanda di scansione (richieste dei bot) per massimizzare la visibilità nelle risposte generate dall’AI controllando al contempo i costi operativi e il carico sul server.
Ottimizzazione del Crawl Budget per l'AI
Tecniche per garantire che i crawler AI accedano e indicizzino in modo efficiente i contenuti più importanti di un sito web entro i limiti del loro crawl. L'ottimizzazione del crawl budget gestisce l'equilibrio tra la capacità di scansione (risorse del server) e la domanda di scansione (richieste dei bot) per massimizzare la visibilità nelle risposte generate dall'AI controllando al contempo i costi operativi e il carico sul server.
Cos’è il Crawl Budget nell’Era dell’AI
Crawl budget si riferisce alla quantità di risorse—misurata in richieste e banda—che i motori di ricerca e i bot AI destinano alla scansione del tuo sito web. Tradizionalmente, questo concetto si applicava principalmente al comportamento di scansione di Google, ma l’avvento dei bot alimentati da AI ha trasformato radicalmente il modo in cui le organizzazioni devono pensare alla gestione del crawl budget. L’equazione del crawl budget è composta da due variabili essenziali: capacità di scansione (il numero massimo di pagine che un bot può scansionare) e domanda di scansione (il numero effettivo di pagine che il bot desidera scansionare). Nell’era dell’AI, questa dinamica è diventata esponenzialmente più complessa, poiché bot come GPTBot (OpenAI), Perplexity Bot e ClaudeBot (Anthropic) ora competono per le risorse del server insieme ai tradizionali crawler dei motori di ricerca. Questi bot AI operano con priorità e schemi diversi rispetto a Googlebot, spesso consumando molta più banda e perseguendo obiettivi di indicizzazione differenti, rendendo l’ottimizzazione del crawl budget non più opzionale ma essenziale per mantenere le prestazioni del sito e controllare i costi operativi.
Perché i Crawler AI Hanno Cambiato le Regole del Gioco
I crawler AI differiscono profondamente dai bot tradizionali dei motori di ricerca nei loro schemi di scansione, frequenza e consumo di risorse. Mentre Googlebot rispetta i limiti di crawl budget e applica sofisticati meccanismi di throttling, i bot AI spesso mostrano comportamenti di scansione più aggressivi, talvolta richiedendo più volte gli stessi contenuti e prestando meno attenzione ai segnali di carico del server. Le ricerche indicano che GPTBot di OpenAI può consumare 12-15 volte più banda rispetto al crawler di Google su determinati siti, soprattutto quelli con grandi librerie di contenuti o pagine frequentemente aggiornate. Questo approccio aggressivo deriva dalle esigenze di training dell’AI: questi bot devono ingerire continuamente nuovi contenuti per migliorare le prestazioni del modello, creando una filosofia di scansione fondamentalmente diversa rispetto ai motori di ricerca focalizzati sull’indicizzazione per il recupero delle informazioni. L’impatto sui server è rilevante: molte organizzazioni segnalano aumenti significativi nei costi di banda, nell’utilizzo della CPU e nel carico server direttamente attribuibili al traffico dei bot AI. Inoltre, l’effetto cumulativo di più bot AI che scansionano contemporaneamente può degradare l’esperienza utente, rallentare i tempi di caricamento delle pagine e aumentare le spese di hosting, rendendo la distinzione tra crawler tradizionali e AI una questione critica di business più che una curiosità tecnica.
Caratteristica
Crawler tradizionali (Googlebot)
Crawler AI (GPTBot, ClaudeBot)
Frequenza di scansione
Adattiva, rispetta il crawl budget
Aggressiva, continua
Consumo di banda
Moderato, ottimizzato
Elevato, intensivo
Rispetto del Robots.txt
Conformità rigorosa
Conformità variabile
Comportamento caching
Caching sofisticato
Richieste frequenti
Identificazione User-Agent
Chiara, coerente
Talvolta offuscata
Obiettivo di business
Indicizzazione per la ricerca
Training dei modelli/acquisizione dati
Impatto sui costi
Minimo
Significativo (12-15x superiore)
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Comprendere il crawl budget richiede la padronanza dei suoi due componenti di base: capacità di scansione e domanda di scansione. La capacità di scansione rappresenta il numero massimo di URL che il tuo server può gestire nell’arco di un determinato periodo, influenzata da diversi fattori interconnessi. Questa capacità dipende da:
Risorse del server (CPU, RAM, disponibilità di banda)
Tempo di risposta (risposte più rapide consentono tassi di scansione più elevati)
Segnali di salute del server (codici di stato HTTP, timeout)
Qualità dell’infrastruttura (uso di CDN, bilanciamento del carico, livelli di caching)
Distribuzione geografica (hosting multi-regione aumenta la capacità)
La domanda di scansione, invece, rappresenta quante pagine i bot desiderano effettivamente scansionare, guidata dalle caratteristiche dei contenuti e dalle priorità dei bot. I fattori che influenzano la domanda di scansione includono:
Freschezza dei contenuti (le pagine aggiornate di frequente attirano più scansioni)
Qualità e autorevolezza dei contenuti (le pagine di alta qualità ricevono priorità di scansione)
Frequenza di aggiornamento (le pagine aggiornate quotidianamente ricevono più attenzione rispetto a quelle statiche)
Struttura dei link interni (le pagine ben collegate vengono scansionate più spesso)
Inclusione nelle sitemap (le pagine presenti nelle sitemap ricevono priorità di scansione)
Pattern storici di scansione (i bot apprendono quali pagine cambiano più spesso)
La sfida di ottimizzazione emerge quando la domanda di scansione supera la capacità: i bot devono scegliere quali pagine scansionare, rischiando di tralasciare aggiornamenti importanti. Al contrario, quando la capacità è molto superiore alla domanda, si sprecano risorse server. L’obiettivo è raggiungere l’efficienza di scansione: massimizzare la scansione delle pagine importanti minimizzando le scansioni inutili di contenuti a basso valore. Questo equilibrio diventa sempre più complesso nell’era AI, dove molteplici tipologie di bot con priorità diverse competono per le stesse risorse, richiedendo strategie sofisticate per allocare il crawl budget in modo efficace tra tutti gli stakeholder.
Misurare le Prestazioni Attuali del Crawl Budget
La misurazione delle prestazioni del crawl budget inizia con Google Search Console, che fornisce statistiche di scansione nella sezione “Impostazioni”, mostrando richieste giornaliere di scansione, byte scaricati e tempi di risposta. Per calcolare il tuo rapporto di efficienza di scansione, dividi il numero di scansioni riuscite (risposte HTTP 200) per il totale delle richieste di scansione: i siti sani raggiungono tipicamente un’efficienza dell'85-95%. Una formula base è: (Scansioni riuscite ÷ Richieste totali di scansione) × 100 = % di efficienza scansione. Oltre ai dati di Google, un monitoraggio pratico richiede:
Analisi dei log server con strumenti come Splunk o ELK Stack per identificare tutto il traffico bot, inclusi i crawler AI
Monitoraggio degli errori 4xx e 5xx per individuare pagine che sprecano crawl budget su errori
Monitoraggio della profondità di scansione (quanti livelli in profondità i bot penetrano nella struttura del sito)
Misurazione delle tendenze dei tempi di risposta per identificare degradi dovuti al carico di scansione
Segmentazione del traffico per user-agent per capire quali bot consumano più risorse
Per il monitoraggio specifico dei crawler AI, strumenti come AmICited.com offrono tracciamento specializzato dell’attività di GPTBot, ClaudeBot e Perplexity Bot, fornendo insight su quali pagine questi bot privilegiano e con quale frequenza tornano. Inoltre, implementare alert personalizzati per picchi insoliti di scansione—soprattutto da bot AI—permette di reagire rapidamente a consumi imprevisti di risorse. La metrica chiave da monitorare è il costo di scansione per pagina: dividendo le risorse server totali consumate per le scansioni per il numero di pagine uniche scansionate si capisce se il crawl budget viene usato in modo efficiente o sprecato su pagine a basso valore.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Strategie di Ottimizzazione per i Crawler AI
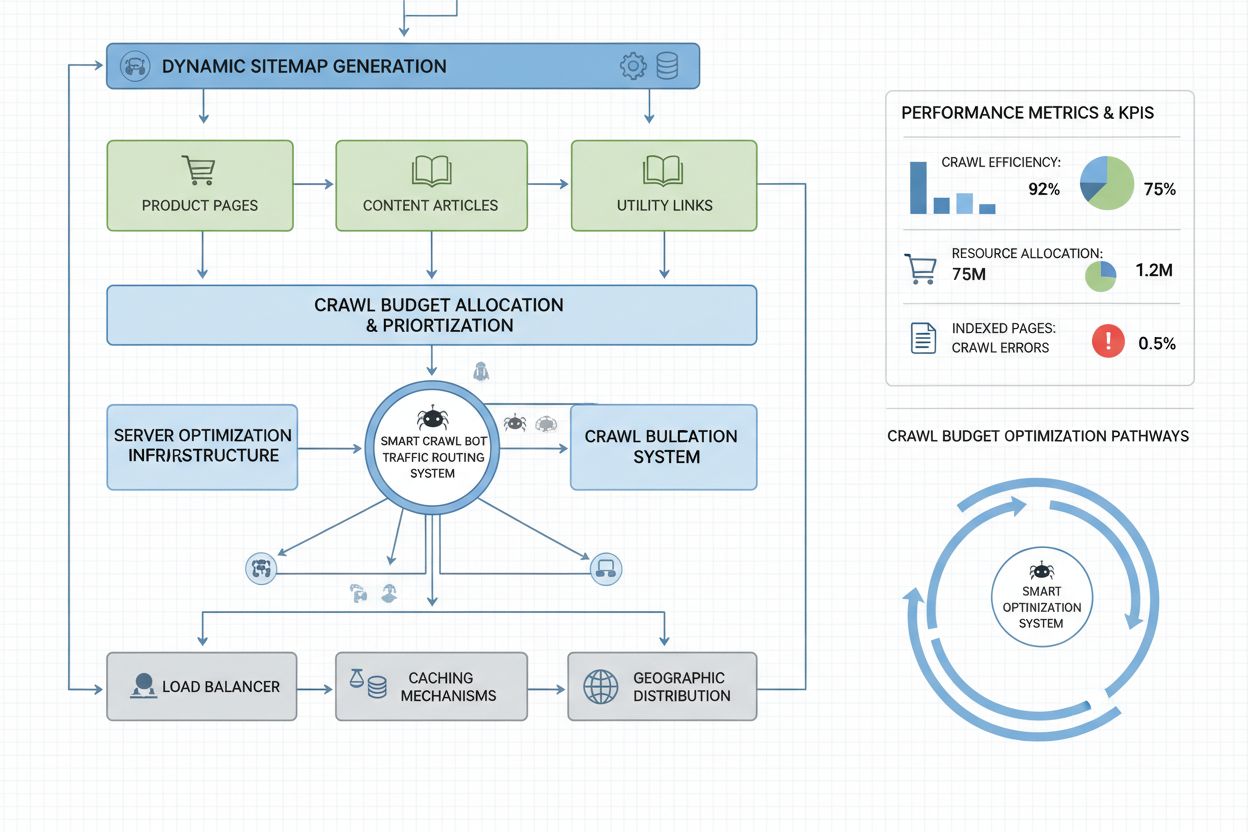
Ottimizzare il crawl budget per i bot AI richiede un approccio multilivello che combina implementazione tecnica e decisioni strategiche. Le principali tattiche di ottimizzazione includono:
Ottimizzazione del robots.txt: Blocca i bot AI dalla scansione di pagine a basso valore (archivi, contenuti duplicati, sezioni amministrative) consentendo l’accesso ai contenuti principali
Sitemap dinamiche: Crea sitemap separate per diversi tipi di contenuti, dando priorità ai contenuti aggiornati frequentemente e alle pagine di alto valore
Ottimizzazione della struttura URL: Implementa URL gerarchici e puliti che riducono la profondità di scansione e rendono le pagine importanti più scopribili
Blocco selettivo: Usa regole specifiche per user-agent per consentire Googlebot e limitare i bot AI più aggressivi se stanno consumando troppe risorse
Direttive crawl-delay: Implementa valori appropriati di crawl-delay nel robots.txt per limitare le richieste dei bot (anche se i bot AI potrebbero non rispettarle)
Canonicalizzazione: Usa con decisione i tag canonici per consolidare contenuti duplicati e ridurre sprechi di scansione su varianti
La scelta strategica della tattica dipende dal modello di business e dalla strategia di contenuto. I siti e-commerce potrebbero bloccare i crawler AI sulle pagine prodotto per evitare che i concorrenti addestrino i loro modelli sui dati, mentre gli editori di contenuti potrebbero consentire la scansione per ottenere visibilità nelle risposte AI. Per i siti che subiscono realmente stress server da traffico bot AI, implementare blocchi specifici per user-agent nel robots.txt è la soluzione più diretta: User-agent: GPTBot seguito da Disallow: / impedisce al crawler di OpenAI di accedere completamente al sito. Tuttavia, così facendo si sacrifica la potenziale visibilità nelle risposte di ChatGPT e altre app AI. Una strategia più sfumata prevede il blocco selettivo: consentire ai crawler AI l’accesso ai contenuti pubblici bloccandoli invece da aree sensibili, archivi o contenuti duplicati che consumano crawl budget senza valore per il bot o per l’utente.
Tecniche Avanzate per Siti di Grandi Dimensioni
I siti aziendali con milioni di pagine richiedono strategie di ottimizzazione del crawl budget più sofisticate rispetto alla semplice configurazione del robots.txt. Le sitemap dinamiche rappresentano un progresso fondamentale, generando le sitemap in tempo reale sulla base della freschezza dei contenuti, del punteggio di importanza e della storia di scansione. Invece di sitemap XML statiche che elencano tutte le pagine, le sitemap dinamiche privilegiano le pagine appena aggiornate, quelle ad alto traffico e con maggiore potenziale di conversione, assicurando che i bot si concentrino sui contenuti più rilevanti. La segmentazione degli URL divide il sito in zone logiche di scansione, ciascuna con strategie di ottimizzazione dedicate: le sezioni news possono usare aggiornamenti aggressivi delle sitemap per garantire la scansione immediata dei contenuti quotidiani, mentre i contenuti evergreen vengono aggiornati meno frequentemente.
Le ottimizzazioni lato server includono l’implementazione di strategie di caching consapevoli della scansione che servono risposte cache ai bot e contenuti freschi agli utenti, riducendo il carico generato dalle richieste bot ripetute. Le Content Delivery Network (CDN) con routing specifico per bot possono isolare il traffico dei crawler da quello degli utenti, evitando che i crawler consumino la banda destinata ai visitatori reali. Il rate limiting per user-agent permette ai server di rallentare le richieste dei bot AI mantenendo velocità normali per Googlebot e traffico umano. Per realtà di grandi dimensioni, la gestione distribuita del crawl budget su più regioni server elimina i single point of failure e consente il bilanciamento geografico del traffico bot. Il crawl prediction basato su machine learning analizza i pattern storici dei crawler per prevedere quali pagine verranno richieste successivamente, consentendo di ottimizzare in anticipo le prestazioni e la cache di quelle pagine. Queste strategie di livello enterprise trasformano il crawl budget da vincolo a risorsa gestita, permettendo a grandi organizzazioni di servire miliardi di pagine mantenendo prestazioni ottimali per bot e utenti umani.
La Scelta Strategica – Bloccare o Consentire i Crawler AI
La decisione di bloccare o consentire i crawler AI rappresenta una scelta strategica fondamentale con grandi implicazioni in termini di visibilità, posizionamento competitivo e costi operativi. Consentire i crawler AI porta notevoli benefici: i tuoi contenuti possono essere inclusi nelle risposte generate dall’AI, potenzialmente generando traffico da ChatGPT, Claude, Perplexity e altre applicazioni AI; il tuo brand ottiene visibilità in un nuovo canale distributivo; e ottieni vantaggi SEO derivanti dalle citazioni da parte dei sistemi AI. Tuttavia, questi benefici hanno un costo: aumento del carico server e del consumo di banda, potenziale training dei modelli AI dei concorrenti sui tuoi contenuti proprietari, e perdita di controllo su come le informazioni vengono presentate e attribuite nelle risposte AI.
Bloccare i crawler AI elimina questi costi ma sacrifica i benefici di visibilità e, potenzialmente, lascia spazio di mercato ai concorrenti che autorizzano la scansione. La strategia ottimale dipende dal tuo modello di business: editori di contenuti e testate giornalistiche spesso traggono vantaggio dall’autorizzare la scansione per ottenere distribuzione tramite i riassunti AI; aziende SaaS e siti e-commerce potrebbero bloccare i crawler per evitare che i concorrenti addestrino i loro modelli sulle informazioni di prodotto; istituzioni educative e organizzazioni di ricerca solitamente consentono la scansione per massimizzare la diffusione della conoscenza. Un approccio ibrido rappresenta una soluzione intermedia: consente la scansione dei contenuti pubblici bloccando invece aree sensibili, contenuti generati dagli utenti o informazioni proprietarie. Questa strategia massimizza i benefici di visibilità proteggendo al contempo gli asset di valore. Inoltre, il monitoraggio tramite AmICited.com e strumenti simili rivela se i tuoi contenuti vengono effettivamente citati dai sistemi AI—se il sito non appare nelle risposte AI nonostante la scansione consentita, bloccare può diventare un’opzione più interessante, dal momento che si sostiene il costo della scansione senza ricevere i benefici di visibilità.
Strumenti e Monitoraggio per la Gestione del Crawl Budget
Una gestione efficace del crawl budget richiede strumenti specializzati che offrano visibilità sul comportamento dei bot e consentano decisioni di ottimizzazione basate sui dati. Conductor e Sitebulb offrono analisi di scansione di livello enterprise, simulando il comportamento dei motori di ricerca nel tuo sito e individuando inefficienze, sprechi su pagine di errore e opportunità di migliorare l’allocazione del crawl budget. Cloudflare fornisce gestione dei bot a livello di rete, consentendo un controllo granulare su quali bot possono accedere al sito e implementando rate limiting specifico per i crawler AI. Per il monitoraggio specifico dei bot AI, AmICited.com si distingue come soluzione completa, tracciando GPTBot, ClaudeBot, Perplexity Bot e altri bot AI con analisi dettagliate su quali pagine questi bot visitano, con quale frequenza e se i tuoi contenuti appaiono nelle risposte AI generate.
L’analisi dei log server resta fondamentale per l’ottimizzazione del crawl budget: strumenti come Splunk, Datadog o lo stack open source ELK consentono di analizzare i raw access log e segmentare il traffico per user-agent, identificando quali bot consumano più risorse e quali pagine attirano più attenzione da parte dei crawler. Dashboard personalizzate che tracciano le tendenze di scansione nel tempo permettono di valutare l’efficacia delle ottimizzazioni e di individuare nuovi bot emergenti. Google Search Console continua a fornire dati essenziali sul comportamento di scansione di Google, mentre Bing Webmaster Tools offre insight simili per il crawler Microsoft. Le organizzazioni più evolute adottano strategie di monitoraggio multi-tool combinando Search Console per i dati dei crawler tradizionali, AmICited.com per il tracciamento dei bot AI, analisi log per una visibilità bot completa e strumenti specializzati come Conductor per simulazione di scansione e analisi di efficienza. Questo approccio stratificato offre una visibilità completa su come tutti i tipi di bot interagiscono col sito, consentendo decisioni di ottimizzazione basate su dati concreti e non su ipotesi. Il monitoraggio regolare—idealmente con revisioni settimanali delle metriche di scansione—permette l’identificazione rapida di problemi come picchi di scansione inattesi, aumento dei tassi di errore o comparsa di nuovi bot aggressivi, consentendo una risposta tempestiva prima che le problematiche di crawl budget impattino su performance o costi operativi.
Domande frequenti
Qual è la differenza tra crawl budget per i bot AI e Googlebot?
I bot AI come GPTBot e ClaudeBot operano con priorità diverse rispetto a Googlebot. Mentre Googlebot rispetta i limiti del crawl budget e applica sofisticati meccanismi di throttling, i bot AI spesso mostrano comportamenti di scansione più aggressivi, consumando 12-15 volte più banda. I bot AI danno priorità all'ingestione continua di contenuti per l'addestramento dei modelli piuttosto che all'indicizzazione per la ricerca, rendendo il loro comportamento di scansione fondamentalmente diverso e richiedendo strategie di ottimizzazione specifiche.
Quanto crawl budget consumano tipicamente i bot AI?
Le ricerche indicano che il GPTBot di OpenAI può consumare 12-15 volte più banda rispetto al crawler di Google su determinati siti, in particolare quelli con grandi librerie di contenuti. Il consumo esatto dipende dalle dimensioni del sito, dalla frequenza di aggiornamento dei contenuti e da quanti bot AI stanno scansionando contemporaneamente. Più bot AI che scansionano insieme possono aumentare notevolmente il carico sul server e i costi di hosting.
Posso bloccare specifici crawler AI senza influire sulla SEO?
Sì, puoi bloccare specifici crawler AI tramite robots.txt senza impattare la SEO tradizionale. Tuttavia, bloccare i crawler AI significa rinunciare alla visibilità nelle risposte generate da ChatGPT, Claude, Perplexity e altre applicazioni AI. La decisione dipende dal tuo modello di business: gli editori di contenuti di solito beneficiano dall'autorizzare la scansione, mentre i siti e-commerce potrebbero bloccare per evitare l'addestramento dei concorrenti.
Qual è l'impatto di una cattiva gestione del crawl budget sul mio sito?
Una cattiva gestione del crawl budget può comportare la mancata scansione o indicizzazione delle pagine importanti, una più lenta indicizzazione dei nuovi contenuti, un aumento del carico sul server e dei costi di banda, un'esperienza utente degradata dovuta al consumo di risorse da parte dei bot e la perdita di opportunità di visibilità sia nella ricerca tradizionale che nelle risposte AI. I siti di grandi dimensioni con milioni di pagine sono i più vulnerabili a questi effetti.
Con quale frequenza dovrei monitorare il mio crawl budget?
Per risultati ottimali, monitora le metriche del crawl budget settimanalmente, con controlli giornalieri durante lanci di contenuti importanti o in caso di picchi di traffico imprevisti. Usa Google Search Console per i dati tradizionali, AmICited.com per il monitoraggio dei crawler AI e i log del server per una visibilità completa sui bot. Il monitoraggio regolare consente di identificare rapidamente i problemi prima che impattino le prestazioni del sito.
Il robots.txt è efficace per controllare la scansione dei bot AI?
Il robots.txt ha un'efficacia variabile con i bot AI. Mentre Googlebot rispetta rigorosamente le direttive del robots.txt, i bot AI mostrano conformità incostante: alcuni rispettano le regole, altri le ignorano. Per un controllo più affidabile, implementa blocchi specifici per user-agent, rate limiting a livello di server o usa strumenti di gestione bot basati su CDN come Cloudflare per un controllo più granulare.
Qual è la relazione tra crawl budget e visibilità nell'AI?
Il crawl budget incide direttamente sulla visibilità nell'AI perché i bot AI non possono citare o fare riferimento a contenuti che non hanno scansionato. Se le tue pagine importanti non vengono scansionate per limiti di budget, non appariranno nelle risposte generate dall'AI. Ottimizzare il crawl budget garantisce che i tuoi contenuti migliori vengano scoperti dai bot AI, aumentando le possibilità di essere citato nelle risposte di ChatGPT, Claude e Perplexity.
Come posso dare priorità alle pagine da far scansionare ai bot AI?
Dai priorità alle pagine tramite sitemap dinamiche che evidenziano i contenuti aggiornati di recente, le pagine ad alto traffico e quelle con potenziale di conversione. Usa robots.txt per bloccare le pagine di basso valore come archivi e duplicati. Implementa una struttura URL pulita e un linking interno strategico per guidare i bot verso i contenuti importanti. Monitora quali pagine i bot AI effettivamente scansionano con strumenti come AmICited.com per affinare la tua strategia.
Monitora in modo efficiente il tuo Crawl Budget AI
Tieni traccia di come i bot AI scansionano il tuo sito e ottimizza la tua visibilità nelle risposte generate dall'AI con la piattaforma completa di monitoraggio crawler AI di AmICited.com.
Cos'è il Crawl Budget per l'IA? Comprendere l'Allocazione delle Risorse dei Bot IA
Scopri cosa significa crawl budget per l'IA, in cosa si differenzia dai tradizionali crawl budget dei motori di ricerca e perché è importante per la visibilità ...
Il crawl budget è il numero di pagine che i motori di ricerca scansionano sul tuo sito web in un dato periodo. Scopri come ottimizzare il crawl budget per una m...