Definizione di Knowledge Graph
Un knowledge graph è un database di informazioni interconnesse che rappresenta entità del mondo reale—come persone, luoghi, organizzazioni e concetti—e illustra le relazioni semantiche tra di esse. A differenza dei database tradizionali che organizzano le informazioni in formati tabellari rigidi, i knowledge graph strutturano i dati come reti di nodi (entità) e archi (relazioni), consentendo ai sistemi di comprendere significato e contesto anziché limitarsi all’abbinamento di parole chiave. Il Knowledge Graph di Google, lanciato nel 2012, ha rivoluzionato la ricerca introducendo la comprensione basata sulle entità, permettendo al motore di risposta di rispondere a domande fattuali come “Quanto è alta la Torre Eiffel?” o “Dove si sono tenute le Olimpiadi estive 2016?” comprendendo cosa stanno effettivamente cercando gli utenti, non solo le parole usate. A maggio 2024, il Knowledge Graph di Google contiene oltre 1,6 trilioni di fatti su 54 miliardi di entità, rappresentando un’espansione enorme rispetto ai 500 miliardi di fatti su 5 miliardi di entità nel 2020. Questa crescita riflette l’importanza crescente della conoscenza strutturata e semantica nel potenziare la ricerca moderna, i sistemi di IA e le applicazioni intelligenti in tutti i settori.
Contesto e Sviluppo Storico
Il concetto di knowledge graph nasce da decenni di ricerca nell’intelligenza artificiale, nelle tecnologie del web semantico e nella rappresentazione della conoscenza. Tuttavia, il termine ha raggiunto ampia diffusione quando Google ha introdotto il suo Knowledge Graph nel 2012, cambiando radicalmente il modo in cui i motori di ricerca presentano i risultati. Prima del Knowledge Graph, i motori di ricerca utilizzavano principalmente l’abbinamento delle parole chiave—se cercavi “foca”, Google restituiva risultati per tutti i possibili significati della parola senza capire quale entità volevi realmente conoscere. Il Knowledge Graph ha cambiato questo paradigma applicando i principi dell’ontologia—un quadro formale per definire entità, attributi e relazioni—su vasta scala. Questo passaggio da “stringhe a cose” ha rappresentato un avanzamento fondamentale nella tecnologia di ricerca, consentendo agli algoritmi di capire che “foca” può riferirsi a un mammifero marino, un artista musicale, un’unità militare o un dispositivo di sicurezza, e di determinare quale significato sia più rilevante in base al contesto. Il mercato globale dei knowledge graph riflette questa importanza, con proiezioni che mostrano una crescita da 1,49 miliardi di dollari nel 2024 a 6,94 miliardi entro il 2030, con un tasso di crescita annuale composto di circa il 35%. Questa crescita esplosiva è trainata dall’adozione aziendale nei settori finanziario, sanitario, retail e della gestione della supply chain, dove le organizzazioni riconoscono sempre più che comprendere le relazioni tra entità è fondamentale per il decision making, il rilevamento delle frodi e l’efficienza operativa.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Come Funzionano i Knowledge Graph: Architettura Tecnica
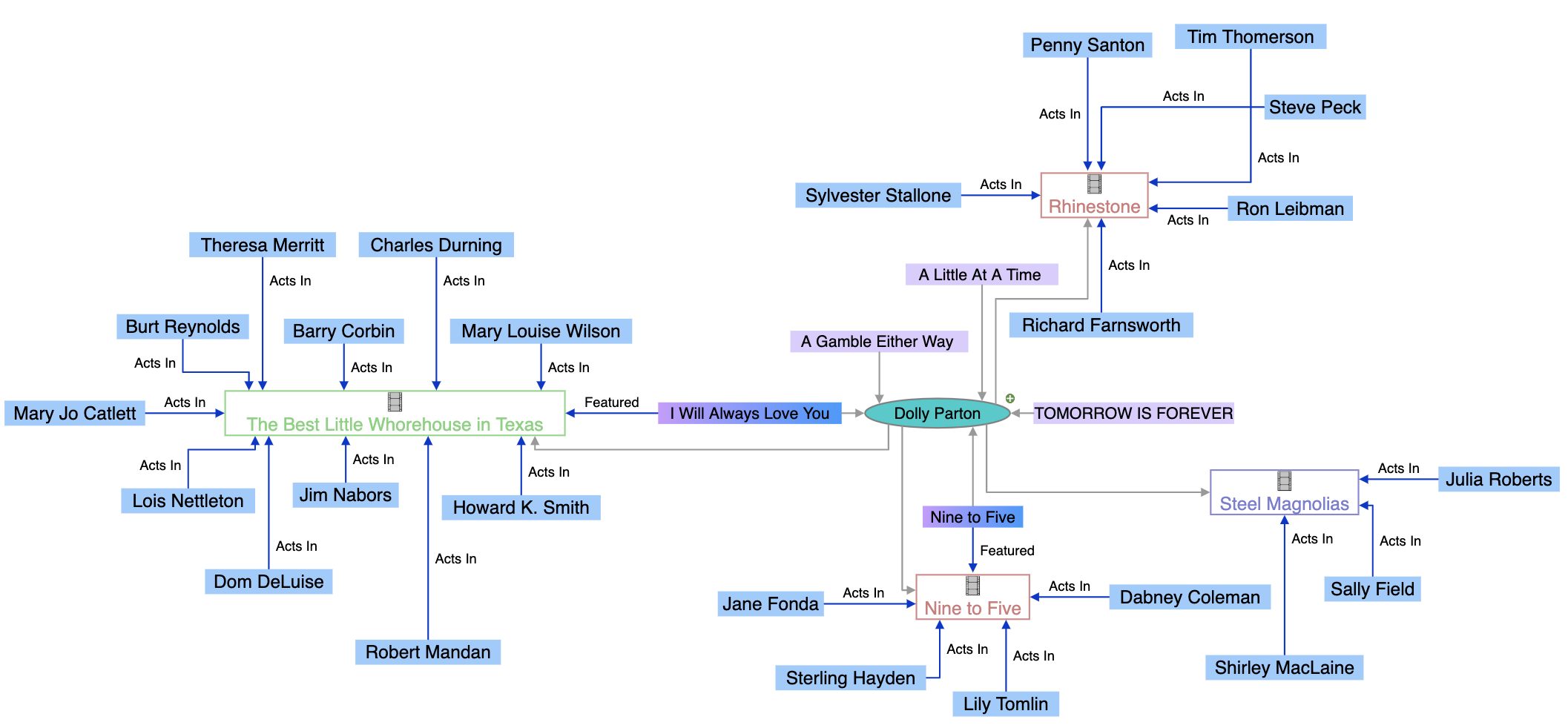
I knowledge graph operano grazie a una sofisticata combinazione di strutture dati, tecnologie semantiche e algoritmi di machine learning. Al loro nucleo, i knowledge graph utilizzano un modello dati strutturato a grafo composto da tre componenti fondamentali: nodi (che rappresentano entità come persone, organizzazioni o concetti), archi (che rappresentano le relazioni tra le entità) e etichette (che descrivono la natura di tali relazioni). Ad esempio, in un semplice knowledge graph, “Seal” potrebbe essere un nodo, “è un” un’etichetta di arco, e “Artista musicale” un altro nodo, creando la relazione semantica “Seal è un Artista musicale”. Questa struttura è sostanzialmente diversa dai database relazionali, che costringono i dati in righe e colonne con schemi predefiniti. I knowledge graph sono costruiti utilizzando labeled property graph (che memorizzano le proprietà direttamente su nodi e archi) o triple store RDF (Resource Description Framework) (che rappresentano tutte le informazioni come triple soggetto-predicato-oggetto). La potenza dei knowledge graph emerge dalla loro capacità di integrare dati da fonti multiple con strutture e formati diversi. Quando i dati vengono acquisiti in un knowledge graph, i processi di arricchimento semantico utilizzano NLP e machine learning per identificare entità, estrarre relazioni e comprendere il contesto. Questo permette ai knowledge graph di riconoscere automaticamente che “IBM”, “International Business Machines” e “Big Blue” si riferiscono alla stessa entità e di capire come questa entità sia collegata a “Watson”, “Cloud Computing” e “Intelligenza Artificiale”. La struttura interconnessa risultante consente interrogazioni sofisticate e ragionamenti impossibili nei database tradizionali, permettendo ai sistemi di rispondere a domande complesse attraversando relazioni e deducendo nuova conoscenza da connessioni esistenti.
Knowledge Graph vs. Database Tradizionali: Tabella Comparativa
| Aspetto | Knowledge Graph | Database Relazionale Tradizionale | Graph Database |
|---|
| Struttura Dati | Nodi, archi ed etichette che rappresentano entità e relazioni | Tabelle, righe e colonne con schemi predefiniti | Nodi e archi ottimizzati per la traversata delle relazioni |
| Flessibilità dello Schema | Altamente flessibile; si evolve man mano che emergono nuove informazioni | Rigido; richiede la definizione dello schema prima dell’inserimento dati | Flessibile; supporta l’evoluzione dinamica dello schema |
| Gestione delle Relazioni | Supporto nativo per relazioni complesse e multi-hop | Richiede join tra più tabelle; computazionalmente oneroso | Ottimizzato per query su relazioni efficienti |
| Linguaggio di Query | SPARQL (per RDF), Cypher (per property graph) o API personalizzate | SQL | Cypher, Gremlin o SPARQL |
| Comprensione Semantica | Enfatizza significato e contesto tramite ontologie | Si concentra su archiviazione e recupero dati | Si concentra su traversate efficienti e pattern matching |
| Casi d’Uso | Ricerca semantica, knowledge discovery, sistemi IA, risoluzione entità | Transazioni aziendali, reportistica, sistemi OLTP | Motori di raccomandazione, rilevamento frodi, analisi di reti |
| Integrazione Dati | Eccelle nell’integrare dati eterogenei da fonti multiple | Richiede notevole ETL e trasformazione dati | Buono per dati connessi ma meno focus semantico |
| Scalabilità | Scala a miliardi di entità e trilioni di fatti | Scala bene per dati strutturati e transazionali | Scala bene per query ricche di relazioni |
| Capacità di Inferenza | Ragionamento avanzato e derivazione della conoscenza tramite ontologie | Limitata; richiede programmazione esplicita | Limitata; focalizzata sul pattern matching |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Il Ruolo dei Knowledge Graph in SEO e Visibilità nell’IA
I knowledge graph sono diventati centrali nelle moderne strategie SEO e di visibilità nell’IA perché determinano in modo fondamentale come le informazioni appaiono nei risultati di ricerca e nelle risposte generate dall’IA. Quando Google elabora una query di ricerca, uno dei compiti principali è identificare l’entità ricercata dall’utente e recuperare informazioni pertinenti dal Knowledge Graph per popolare le funzionalità della SERP. Questo approccio basato sulle entità ha portato all’emergere della ricerca semantica—la capacità di Google di comprendere significato e contesto delle query anziché limitarsi all’abbinamento di parole chiave. Il Knowledge Graph alimenta molteplici funzionalità ad alta visibilità nella SERP che impattano direttamente sul click-through rate e sulla visibilità del brand. I knowledge panel appaiono in posizione prominente su desktop e mobile, mostrando fatti selezionati sull’entità cercata provenienti dal Knowledge Graph. Gli AI Overviews (precedentemente Search Generative Experience) sintetizzano informazioni da più fonti identificate tramite le relazioni nel Knowledge Graph, offrendo risposte complete che spesso spingono i risultati organici più in basso nella pagina. I box Le persone chiedono anche sfruttano le relazioni tra entità per suggerire ricerche e argomenti correlati. Comprendere queste funzionalità è cruciale per i brand perché rappresentano spazi di primo piano nei risultati di ricerca, spesso sopra le classiche inserzioni organiche. Per le organizzazioni che monitorano la propria presenza nei sistemi di IA come Perplexity, ChatGPT, Claude e Google AI Overviews, l’ottimizzazione per i knowledge graph diventa essenziale. Questi sistemi IA si basano sempre più su informazioni strutturate sulle entità e relazioni semantiche per generare risposte accurate e contestuali. Un brand che ha ottimizzato in modo corretto la propria presenza di entità nei knowledge graph—tramite dati strutturati, knowledge panel rivendicati e informazioni coerenti tra le fonti—ha maggiori probabilità di apparire nelle risposte generate dall’IA su argomenti rilevanti. Al contrario, brand con informazioni di entità incomplete o incoerenti rischiano di essere trascurati o rappresentati in modo errato nei sistemi IA, con impatti diretti su visibilità e reputazione.
Fonti di Dati e Costruzione del Knowledge Graph
Il Knowledge Graph di Google attinge da un ecosistema diversificato di fonti di dati, ognuna delle quali contribuisce con tipologie di informazioni differenti e assolve a scopi diversi. Dati open e progetti comunitari come Wikipedia e Wikidata costituiscono la base di gran parte del contenuto del Knowledge Graph. Wikipedia fornisce descrizioni narrative e informazioni riassuntive che spesso compaiono nei knowledge panel, mentre Wikidata—una base dati strutturata a supporto di Wikipedia—offre dati sulle entità e relazioni leggibili dalle macchine. Google in passato utilizzava Freebase, il proprio database modificabile dalla comunità, ma è passato a Wikidata dopo la chiusura di Freebase nel 2016. Fonti di dati governative forniscono informazioni autorevoli, soprattutto per le query fattuali. Il CIA World Factbook offre informazioni su paesi, aree geografiche e organizzazioni. Data Commons, il progetto di dati pubblici strutturati di Google, aggrega dati da organizzazioni governative e multi-governative come Nazioni Unite e Unione Europea, fornendo statistiche e informazioni demografiche. Dati su meteo e qualità dell’aria provengono da agenzie meteorologiche nazionali e internazionali, abilitando le funzionalità meteo “nowcast” di Google. Dati privati su licenza arricchiscono il Knowledge Graph con informazioni che cambiano frequentemente o richiedono competenze specialistiche. Google acquisisce dati di mercato finanziario da provider come Morningstar, S&P Global e Intercontinental Exchange per fornire informazioni su prezzi di azioni e mercati. I dati sportivi arrivano da partnership con leghe, squadre e aggregatori come Stats Perform, offrendo punteggi in tempo reale e statistiche storiche. Dati strutturati dai siti web contribuiscono in modo significativo all’arricchimento del Knowledge Graph. Quando i siti implementano markup Schema.org, forniscono informazioni semantiche esplicite che Google può estrarre e incorporare. Per questo l’implementazione corretta dei dati strutturati—schema Organization, LocalBusiness, FAQPage e altri markup rilevanti—è fondamentale per i brand che vogliono influenzare la propria rappresentazione nel Knowledge Graph. Dati di Google Books da oltre 40 milioni di libri digitalizzati forniscono contesto storico, informazioni biografiche e descrizioni dettagliate che arricchiscono la conoscenza sulle entità. Feedback degli utenti e knowledge panel rivendicati permettono a individui e organizzazioni di influenzare direttamente le informazioni nel Knowledge Graph. Quando gli utenti inviano feedback sui knowledge panel o quando rappresentanti autorizzati rivendicano e aggiornano i pannelli, queste informazioni vengono elaborate e possono portare ad aggiornamenti del Knowledge Graph. Questo approccio human-in-the-loop garantisce che il Knowledge Graph resti accurato e rappresentativo, sebbene i sistemi automatizzati di Google abbiano l’ultima parola su quali informazioni vengano mostrate.
Knowledge Graph ed E-E-A-T: Costruire Autorità e Fiducia
Google ha dichiarato esplicitamente di dare priorità alle informazioni provenienti da fonti che dimostrano un alto livello di E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness: Esperienza, Competenza, Autorevolezza e Affidabilità) nella costruzione e aggiornamento del Knowledge Graph. Questo legame tra E-E-A-T e inclusione nel Knowledge Graph non è casuale—riflette l’impegno di Google a mostrare informazioni affidabili e autorevoli. Se i contenuti del tuo sito vengono inseriti nelle funzionalità della SERP alimentate dal Knowledge Graph, spesso è un segnale forte che Google riconosce il tuo sito come autorevole su quell’argomento. Al contrario, se i tuoi contenuti non compaiono nelle funzionalità alimentate dal Knowledge Graph, potrebbe indicare problemi di E-E-A-T da risolvere. Costruire E-E-A-T per la visibilità nel Knowledge Graph richiede un approccio a più livelli. Esperienza significa dimostrare che tu o i tuoi collaboratori avete esperienza diretta sull’argomento. Per un sito sanitario, questo può significare presentare contenuti di professionisti medici qualificati con anni di attività clinica. Per un’azienda tecnologica, significa mettere in evidenza le competenze di ingegneri e ricercatori che hanno costruito i prodotti trattati. Competenza implica la creazione di contenuti approfonditi che trattano i temi con completezza e accuratezza. Questo va oltre spiegazioni superficiali per dimostrare una reale comprensione di sfumature, casi particolari e concetti avanzati. Autorevolezza richiede di costruire riconoscimento nel proprio settore. Questo può derivare da premi, certificazioni, menzioni sui media, partecipazione come relatori ed essere citati da altre fonti autorevoli. Per le organizzazioni, significa affermare il proprio brand come leader riconosciuto nel settore. Affidabilità si costruisce sugli altri tre elementi e si dimostra con trasparenza, accuratezza, citazioni corrette, chiara attribuzione dell’autore e servizio clienti reattivo. Le organizzazioni che eccellono nei segnali E-E-A-T hanno maggiori probabilità di vedere le proprie informazioni incluse nel Knowledge Graph e di apparire nelle risposte generate dall’IA, creando un circolo virtuoso in cui l’autorità porta visibilità, che a sua volta rafforza l’autorità.
Knowledge Graph nei Sistemi IA e Ricerca Generativa
L’emergere dei large language model (LLM) e dell’IA generativa ha creato nuova importanza per i knowledge graph nell’ecosistema dell’IA. Sebbene gli LLM come ChatGPT, Claude e Perplexity non siano addestrati direttamente sul Knowledge Graph proprietario di Google, si basano sempre più su conoscenze strutturate simili e comprensione semantica. Molti sistemi IA adottano approcci di retrieval-augmented generation (RAG), in cui il modello interroga knowledge graph o database strutturati in fase di inferenza per ancorare le risposte a informazioni fattuali e ridurre le allucinazioni. Knowledge graph pubblici come Wikidata vengono utilizzati per il fine-tuning dei modelli o per iniettare conoscenza strutturata, migliorando la capacità di comprendere relazioni tra entità e fornire informazioni accurate. Per brand e organizzazioni, ciò significa che l’ottimizzazione per i knowledge graph ha implicazioni che vanno oltre la tradizionale ricerca Google. Quando gli utenti pongono domande ai sistemi IA sul tuo settore, prodotto o organizzazione, la capacità del sistema IA di offrire informazioni accurate dipende in parte dalla rappresentazione della tua entità nelle fonti strutturate di conoscenza. Un’organizzazione con una voce Wikidata aggiornata, knowledge panel Google rivendicato e dati strutturati coerenti sul proprio sito avrà maggiori probabilità di essere rappresentata accuratamente nelle risposte generate dall’IA. Al contrario, organizzazioni con informazioni incomplete o in conflitto tra le fonti rischiano di essere rappresentate in modo errato o ignorate nelle risposte IA. Ciò crea una nuova dimensione di monitoraggio della visibilità nell’IA—non solo verificare come il brand appare nei risultati di ricerca tradizionali, ma come viene rappresentato nelle risposte IA su più piattaforme. Strumenti e piattaforme che monitorano la presenza del brand nei sistemi di IA si concentrano sempre più sulla comprensione delle relazioni entità e della rappresentazione nei knowledge graph, riconoscendo che questi fattori influenzano direttamente la visibilità nell’IA.
Implementazione Pratica: Ottimizzare per i Knowledge Graph
Le organizzazioni che vogliono ottimizzare la propria presenza nei knowledge graph dovrebbero seguire un approccio sistematico che parta dai fondamenti SEO e aggiunga strategie specifiche sulle entità. Il primo passo è implementare markup di dati strutturati utilizzando il vocabolario Schema.org. Questo significa aggiungere markup JSON-LD, Microdata o RDFa al sito web che descriva esplicitamente organizzazione, prodotti, persone e altre entità rilevanti. I principali tipi di schema sono Organization (per informazioni aziendali), LocalBusiness (per informazioni locali), Person (per profili individuali), Product (per prodotti) e FAQPage (per domande frequenti). Dopo l’implementazione dello schema, è essenziale testare e validare il markup tramite lo Strumento di Test dei Dati Strutturati di Google per assicurarsi che sia formattato e riconosciuto correttamente. Il secondo passo consiste nell’audit e ottimizzazione delle informazioni su Wikidata e Wikipedia. Se la tua organizzazione o le tue entità chiave hanno pagine Wikipedia, assicurati che siano accurate, complete e ben fontate. Su Wikidata, verifica che la tua entità esista e che le proprietà e le relazioni siano rappresentate correttamente. Tuttavia, modificare Wikipedia o Wikidata richiede attenzione alle policy e alle norme comunitarie—l’autopromozione diretta o i conflitti di interesse non dichiarati possono portare all’annullamento delle modifiche e danneggiare la reputazione. Il terzo passo è rivendicare e ottimizzare il Google Business Profile (per le attività locali) e i knowledge panel (per persone e organizzazioni). Un knowledge panel rivendicato offre maggiore controllo su come la tua entità appare nei risultati di ricerca e consente di suggerire modifiche più rapidamente. Il quarto passo consiste nell’assicurare coerenza tra tutte le proprietà—il sito, il Google Business Profile, i profili social e le directory aziendali di terze parti. Informazioni in conflitto tra le fonti confondono i sistemi di Google e possono ostacolare una rappresentazione accurata nel Knowledge Graph. Il quinto passo è creare contenuti incentrati sulle entità invece che focalizzati sulle parole chiave. Invece di scrivere articoli intorno alle keyword, organizza la strategia dei contenuti attorno alle entità e alle loro relazioni. Ad esempio, invece di scrivere articoli separati su “miglior software CRM”, “funzionalità Salesforce” e “prezzi HubSpot”, crea un cluster di contenuti che stabilisca relazioni chiare tra le entità: Salesforce è una piattaforma CRM, compete con HubSpot, si integra con Slack, ecc. Questo approccio consente ai knowledge graph di comprendere il significato semantico e le relazioni dei tuoi contenuti.
Aspetti Chiave dell’Ottimizzazione e Implementazione dei Knowledge Graph
- Implementazione Dati Strutturati: Aggiungi markup Schema.org a tutte le pagine rilevanti, inclusi schema Organization, LocalBusiness, Product, Person e FAQPage, e valida tramite gli strumenti di test di Google
- Coerenza delle Entità: Mantieni informazioni aziendali identiche (nome, indirizzo, telefono, descrizione) su sito, Google Business Profile, social e directory di terze parti per evitare segnali contrastanti
- Rivendicazione Knowledge Panel: Rivendica il knowledge panel per avere controllo diretto sulle informazioni di entità e la possibilità di suggerire modifiche elaborate più velocemente da Google
- Ottimizzazione Wikidata: Assicurati che la tua organizzazione o le entità chiave abbiano voci Wikidata accurate e complete con proprietà e relazioni corrette, rispettando le linee guida della community
- Segnali E-E-A-T: Costruisci autorità tramite contenuti esperti, credenziali degli autori, riconoscimenti di settore, premi, menzioni sui media e fonti trasparenti per aumentare l’inclusione nel Knowledge Graph
- Strategia Contenuti Basata sulle Entità: Organizza i contenuti intorno alle entità e alle loro relazioni invece che sulle parole chiave, creando cluster di contenuti che stabiliscono connessioni semantiche
- Profili Social Media: Crea e ottimizza profili sulle piattaforme riconosciute da Google (Facebook, Instagram, LinkedIn, YouTube, TikTok, X, Pinterest, Snapchat) e collegali tramite la proprietà “sameAs” dello schema
- Profili Aziendali di Terze Parti: Mantieni profili su directory aziendali autorevoli come Crunchbase, Forbes e Fortune, che Google utilizza come fonti per il Knowledge Graph
- Monitoraggio Accuratezza Dati: Verifica regolarmente le informazioni sulla tua entità su tutte le fonti e correggi dati obsoleti o errati, anche contattando siti terzi se necessario
- Invio Feedback: Usa i meccanismi di feedback di Google nei knowledge panel e nei risultati di ricerca per segnalare inesattezze e suggerire miglioramenti alle informazioni del Knowledge Graph
- Monitoraggio Visibilità IA: Tieni traccia di come il tuo brand appare nelle risposte generate dall’IA su Perplexity, ChatGPT, Claude e Google AI Overviews per comprendere la rappresentazione della tua entità nei sistemi IA
Il Futuro dei Knowledge Graph: Evoluzione e Implicazioni Strategiche
I knowledge graph stanno evolvendo rapidamente in risposta ai progressi dell’intelligenza artificiale, ai cambiamenti nei comportamenti di ricerca e all’emergere di nuove piattaforme e tecnologie. Una tendenza significativa è l’espansione dei knowledge graph multimodali che integrano testo, immagini, audio e video. Con la crescita della voice search e della ricerca visiva, i knowledge graph si stanno adattando per comprendere e rappresentare informazioni su più modalità. Il lavoro di Google sulla ricerca multimodale con prodotti come Google Lens ne è una dimostrazione—il sistema deve comprendere non solo query testuali ma anche input visivi, richiedendo knowledge graph in grado di rappresentare e collegare informazioni su diversi tipi di media. Un altro sviluppo importante è la crescente sofisticazione dell’arricchimento semantico e dell’elaborazione del linguaggio naturale nella costruzione dei knowledge graph. Con il miglioramento delle capacità NLP, i knowledge graph riescono a estrarre relazioni semantiche sempre più precise da testi non strutturati, riducendo la dipendenza da dati curati manualmente o markup espliciti. Questo significa che organizzazioni con contenuti di alta qualità e ben scritti possono vedere le proprie informazioni incorporate nei knowledge graph anche senza markup strutturato esplicito, anche se il markup resta importante per assicurare una rappresentazione accurata. L’integrazione dei knowledge graph con large language model e IA generativa rappresenta forse l’evoluzione più significativa. Man mano che i sistemi IA diventano centrali nel modo in cui le persone scoprono le informazioni, l’importanza dell’ottimizzazione per i knowledge graph si estende oltre la ricerca tradizionale fino alla visibilità nell’IA su più piattaforme. Le organizzazioni che comprendono e ottimizzano per i knowledge graph avranno vantaggi sia nella ricerca tradizionale che nelle risposte generate dall’IA. Inoltre, la crescita dei knowledge graph aziendali riflette la crescente consapevolezza che i principi dei knowledge graph si applicano anche alla gestione della conoscenza interna delle organizzazioni. Le aziende stanno costruendo knowledge graph interni per abbattere i silos di dati, migliorare il decision making e abilitare applicazioni IA più efficaci. Questa tendenza suggerisce che la conoscenza dei knowledge graph diventerà sempre più importante per leader aziendali, data scientist e professionisti del marketing. Infine, le dimensioni regolatorie ed etiche dei knowledge graph stanno acquisendo maggiore rilevanza. Poiché i knowledge graph influenzano il modo in cui le informazioni vengono presentate a miliardi di utenti, questioni di accuratezza, bias, rappresentazione e controllo delle informazioni stanno ricevendo crescente attenzione. Le organizzazioni devono essere consapevoli che la propria rappresentazione nei knowledge graph ha conseguenze reali su visibilità, reputazione e risultati di business, e dovrebbero affrontare l’ottimizzazione per i knowledge graph con la stessa attenzione ed etica applicate agli altri aspetti della propria presenza digitale.