
GPT-4
GPT-4 è l’avanzato LLM multimodale di OpenAI che combina elaborazione di testo e immagini. Scopri le sue capacità, l’architettura e l’impatto sul monitoraggio d...
14 min di lettura

Un’architettura di rete neurale basata su meccanismi di self-attention multi-head che processa dati sequenziali in parallelo, consentendo lo sviluppo dei moderni grandi modelli linguistici come ChatGPT, Claude e Perplexity. Introdotti nell’articolo del 2017 ‘Attention is All You Need’, i transformer sono diventati la tecnologia fondamentale alla base di praticamente tutti i sistemi di IA all’avanguardia.
Un'architettura di rete neurale basata su meccanismi di self-attention multi-head che processa dati sequenziali in parallelo, consentendo lo sviluppo dei moderni grandi modelli linguistici come ChatGPT, Claude e Perplexity. Introdotti nell'articolo del 2017 'Attention is All You Need', i transformer sono diventati la tecnologia fondamentale alla base di praticamente tutti i sistemi di IA all'avanguardia.
L’Architettura Transformer è una progettazione rivoluzionaria di rete neurale introdotta nell’articolo del 2017 “Attention is All You Need” dai ricercatori di Google. Si basa fondamentalmente su meccanismi di self-attention multi-head che permettono ai modelli di processare intere sequenze di dati in parallelo, invece che in modo sequenziale. L’architettura è composta da strati encoder e decoder impilati, ciascuno contenente sottostrati di self-attention e reti neurali feed-forward, collegati tramite connessioni residue e layer normalization. L’Architettura Transformer è diventata la tecnologia fondamentale alla base di praticamente tutti i moderni grandi modelli linguistici (LLM), tra cui ChatGPT, Claude, Perplexity e Google AI Overviews, rendendola probabilmente l’innovazione più importante nelle reti neurali dell’ultimo decennio.
L’importanza dell’Architettura Transformer va ben oltre la sua eleganza tecnica. L’articolo del 2017 “Attention is All You Need” è stato citato oltre 208.000 volte, rendendolo uno dei lavori di ricerca più influenti nella storia del machine learning. Questa architettura ha cambiato radicalmente il modo in cui i sistemi di IA processano e comprendono il linguaggio, consentendo lo sviluppo di modelli con miliardi di parametri in grado di effettuare ragionamenti sofisticati, scrittura creativa e risoluzione di problemi complessi. Il mercato enterprise dei LLM, costruito quasi interamente sulla tecnologia transformer, è stato valutato 6,7 miliardi di dollari nel 2024 e si prevede cresca a un tasso annuo composto del 26,1% fino al 2034, a dimostrazione della sua importanza critica per l’infrastruttura IA moderna.
Lo sviluppo dell’Architettura Transformer rappresenta un momento cruciale nella storia del deep learning, frutto di decenni di ricerca sulle reti neurali per l’elaborazione di dati sequenziali. Prima dei transformer, le reti neurali ricorrenti (RNN) e le loro varianti, in particolare le reti LSTM (Long Short-Term Memory), dominavano i compiti di elaborazione del linguaggio naturale. Tuttavia, queste architetture presentavano limiti fondamentali: processavano le sequenze in modo sequenziale, un elemento alla volta, risultando lente da addestrare e poco efficaci nel catturare dipendenze tra elementi distanti in sequenze lunghe. Il problema della scomparsa del gradiente limitava ulteriormente la capacità delle RNN di apprendere relazioni a lungo raggio, poiché i gradienti si riducevano esponenzialmente propagandosi all’indietro attraverso molti strati.
L’introduzione dei meccanismi di attenzione nel 2014 da parte di Bahdanau e colleghi ha rappresentato una svolta, permettendo ai modelli di concentrarsi su parti rilevanti delle sequenze di input indipendentemente dalla distanza. Tuttavia, l’attenzione veniva inizialmente usata come potenziamento delle RNN più che come loro sostituto. L’articolo del 2017 sul Transformer ha portato questo concetto oltre, proponendo che l’attenzione è tutto ciò che serve: ovvero, un’intera architettura di rete neurale poteva essere costruita usando solo meccanismi di attenzione e strati feed-forward, eliminando completamente la ricorrenza. Questa intuizione si è rivelata rivoluzionaria. Eliminando l’elaborazione sequenziale, i transformer hanno permesso una massiccia parallelizzazione, consentendo ai ricercatori di addestrare su quantità di dati senza precedenti tramite GPU e TPU. Il modello transformer più grande dell’articolo originale, addestrato su 8 GPU per 3,5 giorni, ha dimostrato che scala e parallelizzazione potevano portare a miglioramenti prestazionali drammatici.
Dopo il primo articolo sui transformer, l’architettura si è evoluta rapidamente. BERT (Bidirectional Encoder Representations from Transformers), rilasciato da Google nel 2019, ha dimostrato che gli encoder transformer potevano essere pre-addestrati su enormi corpus testuali e poi raffinati per diversi compiti downstream. Il modello più grande di BERT conteneva 345 milioni di parametri e fu addestrato su 64 TPU specializzati per quattro giorni a un costo stimato di 7.000 dollari, raggiungendo risultati all’avanguardia su numerosi benchmark di comprensione linguistica. Contemporaneamente, la serie GPT di OpenAI ha seguito una strada diversa, utilizzando architetture solo decoder addestrate su compiti di language modeling. GPT-2 con 1,5 miliardi di parametri ha stupito la comunità di ricerca dimostrando che il solo language modeling poteva produrre sistemi molto capaci. GPT-3, con 175 miliardi di parametri, ha mostrato capacità emergenti—abilità che appaiono solo su larga scala, come l’apprendimento few-shot e ragionamenti complessi—cambiando radicalmente le aspettative su ciò che i sistemi di IA potevano raggiungere.
L’Architettura Transformer comprende diversi componenti tecnici interconnessi che lavorano insieme per abilitare l’elaborazione parallela e una sofisticata comprensione del contesto. Il livello di embedding di input converte i token discreti (parole o subword) in rappresentazioni vettoriali continue, di solito di dimensione 512 o superiore. Questi embedding sono poi arricchiti dal positional encoding, che aggiunge informazioni sulla posizione di ciascun token nella sequenza tramite funzioni seno e coseno a frequenze diverse. Questa informazione posizionale è essenziale perché, a differenza delle RNN che preservano l’ordine tramite la loro struttura ricorrente, i transformer processano tutti i token simultaneamente e necessitano di segnali espliciti per comprendere l’ordine delle parole e le distanze relative.
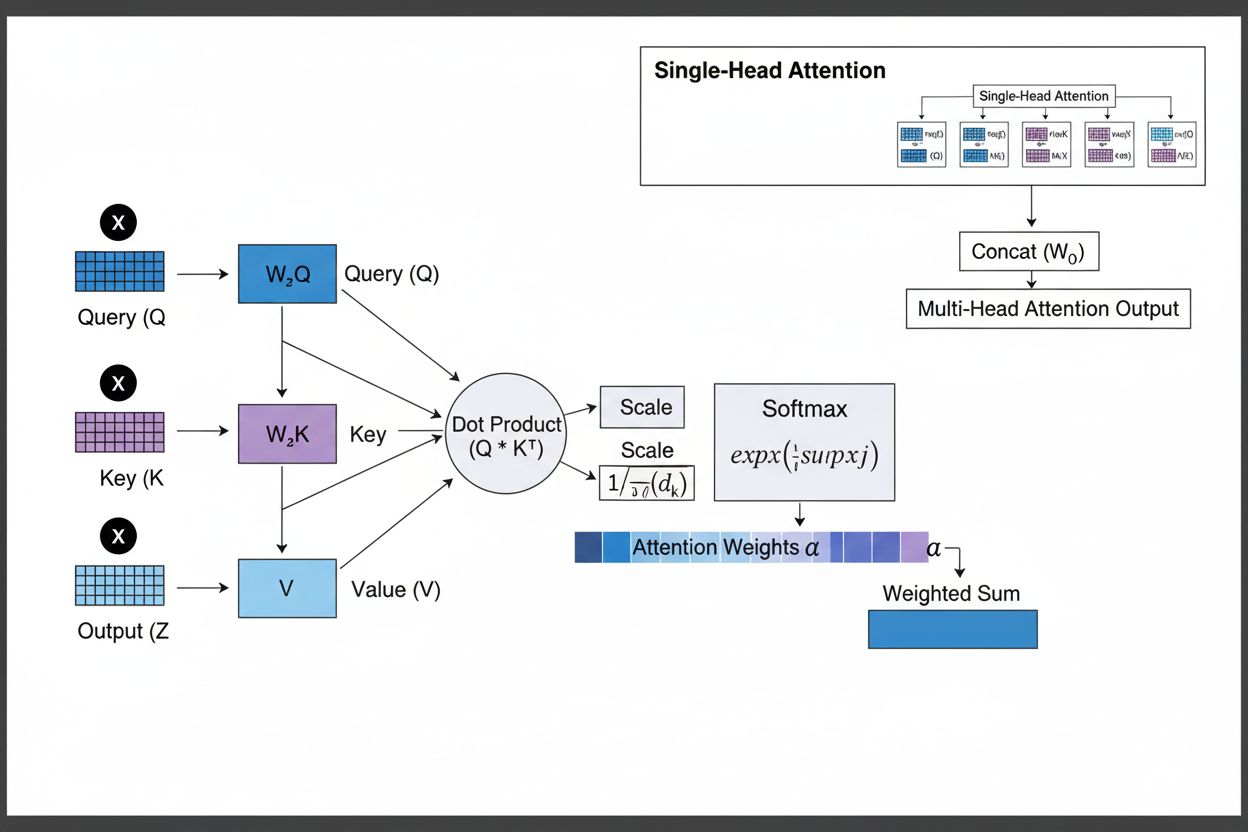
Il meccanismo di self-attention è l’innovazione architetturale che distingue i transformer da tutte le precedenti reti neurali. Per ogni token della sequenza di input, il modello calcola tre vettori: un vettore Query (che rappresenta l’informazione cercata dal token), vettori Key (che rappresentano l’informazione contenuta da ciascun token) e vettori Value (che rappresentano l’effettiva informazione da trasmettere). Il meccanismo di attenzione calcola uno score di similarità tra la Query di ciascun token e tutte le Key tramite prodotti scalari, normalizza questi score tramite softmax per creare pesi di attenzione tra 0 e 1, e li usa per ottenere una somma pesata dei Value. Questo processo consente a ciascun token di concentrarsi selettivamente su altri token rilevanti, permettendo al modello di comprendere contesto e relazioni.
L’attenzione multi-head estende questo concetto eseguendo simultaneamente molteplici meccanismi di attenzione, tipicamente 8, 12 o 16 head. Ogni head opera su diverse proiezioni lineari dei vettori Query, Key e Value, permettendo al modello di focalizzarsi su vari tipi di relazioni e pattern in sottospazi di rappresentazione distinti. Ad esempio, una head può concentrarsi su relazioni sintattiche tra parole, un’altra su relazioni semantiche o dipendenze a lungo raggio. Gli output di tutte le head vengono concatenati e trasformati linearmente, fornendo al modello informazioni contestuali ricche e sfaccettate. Questo approccio si è rivelato molto efficace: la ricerca mostra che le diverse head imparano a specializzarsi in fenomeni linguistici differenti.
La struttura encoder-decoder organizza questi meccanismi di attenzione in una pipeline gerarchica di elaborazione. L’encoder è composto da più strati impilati (tipicamente 6 o più), ciascuno con un sottostrato di attenzione multi-head seguito da una rete feed-forward position-wise. Le connessioni residue attorno a ciascun sottostrato consentono ai gradienti di fluire direttamente durante l’addestramento, migliorando la stabilità e permettendo architetture più profonde. Dopo ciascun sottostrato viene applicata la layer normalization, normalizzando le attivazioni per mantenere scale coerenti in tutta la rete. Il decoder ha una struttura simile ma include un ulteriore strato di attenzione encoder-decoder che consente al decoder di focalizzarsi sull’output dell’encoder, permettendo di concentrare l’attenzione sulle parti rilevanti dell’input durante la generazione di ciascun token di output. Nelle architetture solo decoder come GPT, il decoder genera i token in modo autoregressivo, con ogni nuovo token dipendente da tutti quelli generati in precedenza.
| Aspetto | Architettura Transformer | RNN/LSTM | Reti Neurali Convoluzionali (CNN) |
|---|---|---|---|
| Metodo di Elaborazione | Elaborazione parallela di intere sequenze tramite attenzione | Elaborazione sequenziale, un elemento alla volta | Operazioni di convoluzione locale su finestre di dimensione fissa |
| Dipendenze a Lungo Raggio | Eccellente; l’attenzione può collegare direttamente token distanti | Scarsa; limitata da scomparsa dei gradienti e colli di bottiglia sequenziali | Limitata; il campo recettivo locale richiede molti strati |
| Velocità di Addestramento | Molto veloce; massiccia parallelizzazione su GPU/TPU | Lento; l’elaborazione sequenziale impedisce la parallelizzazione | Veloce per input di dimensione fissa; meno adatto a sequenze variabili |
| Requisiti di Memoria | Alti; quadratici in funzione della lunghezza della sequenza a causa dell’attenzione | Più bassi; lineari rispetto alla lunghezza della sequenza | Moderati; dipendono dalla dimensione del kernel e dalla profondità |
| Scalabilità | Eccellente; scala a miliardi di parametri | Limitata; difficile addestrare modelli molto grandi | Buona per immagini; meno adatta a sequenze |
| Applicazioni Tipiche | Language modeling, traduzione automatica, generazione di testo | Serie temporali, previsione sequenziale (meno comune oggi) | Classificazione immagini, object detection, computer vision |
| Flusso del Gradiente | Stabile; le connessioni residue permettono reti profonde | Problematico; gradienti che scompaiono/esplodono | Generalmente stabile; le connessioni locali aiutano il flusso del gradiente |
| Informazione di Posizione | Richiede positional encoding esplicito | Implicita tramite elaborazione sequenziale | Implicita tramite struttura spaziale |
| LLM All’Avanguardia | GPT, Claude, Llama, Granite, Perplexity | Raramente usate nei LLM moderni | Non usate per language modeling |
Il legame tra Architettura Transformer e i moderni grandi modelli linguistici è fondamentale e indissolubile. Ogni LLM principale rilasciato negli ultimi cinque anni—tra cui GPT-4 di OpenAI, Claude di Anthropic, Llama di Meta, Gemini di Google, Granite di IBM e i modelli IA di Perplexity—è costruito sull’architettura transformer. La capacità dell’architettura di scalare efficientemente sia con la dimensione del modello che con i dati di addestramento si è rivelata essenziale per ottenere le capacità che definiscono i sistemi IA moderni. Quando i ricercatori hanno aumentato la dimensione dei modelli da milioni a miliardi e poi a centinaia di miliardi di parametri, la parallelizzazione e i meccanismi di attenzione del transformer hanno permesso questa scalabilità senza incrementi proporzionali nei tempi di addestramento.
Il processo di decodifica autoregressiva utilizzato dalla maggior parte dei LLM moderni è un’applicazione diretta dell’architettura decoder del transformer. Durante la generazione di testo, questi modelli processano il prompt di input tramite l’encoder (o, nei modelli solo decoder, tramite il decoder completo), quindi generano i token di output uno alla volta. Ogni nuovo token viene generato calcolando le distribuzioni di probabilità su tutto il vocabolario tramite softmax, con il modello che seleziona il token a probabilità più alta (o estrae dalla distribuzione secondo il parametro di temperatura). Questo processo, ripetuto centinaia o migliaia di volte, produce testo coerente e contestualmente appropriato. Il meccanismo di self-attention consente al modello di mantenere il contesto su tutta la sequenza generata, permettendo di produrre passaggi lunghi e coerenti che mantengono temi, personaggi e logica consistenti.
Le capacità emergenti osservate nei grandi modelli transformer—abilità che compaiono solo a sufficiente scala, come il few-shot learning, il chain-of-thought reasoning e l’in-context learning—sono una conseguenza diretta della progettazione dell’architettura. La capacità della multi-head attention di catturare relazioni diversificate, unita all’enorme numero di parametri e all’addestramento su dati vari, permette a questi sistemi di svolgere compiti per cui non sono stati addestrati esplicitamente. Ad esempio, GPT-3 poteva eseguire operazioni aritmetiche, scrivere codice e rispondere a domande nonostante fosse addestrato solo sul language modeling. Queste proprietà emergenti hanno reso i LLM basati su transformer la base della rivoluzione IA moderna, con applicazioni che vanno dalla IA conversazionale e generazione di contenuti a sintesi di codice e assistenza nella ricerca scientifica.
Il meccanismo di self-attention è l’innovazione architetturale che distingue fondamentalmente i transformer e ne spiega le prestazioni superiori rispetto agli approcci precedenti. Per comprendere la self-attention, si può considerare la sfida di interpretare pronomi ambigui nel linguaggio. Nella frase “Il trofeo non entra nella valigia perché è troppo grande”, il pronome “è” potrebbe riferirsi sia al trofeo che alla valigia, ma il contesto chiarisce che si riferisce al trofeo. Nella frase “Il trofeo non entra nella valigia perché è troppo piccola”, lo stesso pronome si riferisce ora alla valigia. Un modello transformer deve imparare a risolvere tali ambiguità comprendendo le relazioni tra le parole.
La self-attention realizza ciò tramite un processo matematicamente elegante. Per ogni token nella sequenza di input, il modello calcola un vettore Query moltiplicando l’embedding del token per una matrice di pesi appresa WQ. Allo stesso modo, calcola i vettori Key (usando WK) e i vettori Value (usando WV) per tutti i token. Il punteggio di attenzione tra la Query di un token e la Key di un altro è calcolato come prodotto scalare di questi vettori, normalizzato per la radice quadrata della dimensione della key (tipicamente √64 ≈ 8). Questi punteggi grezzi sono poi passati attraverso una funzione softmax, che li converte in pesi di attenzione normalizzati che sommano a 1. Infine, l’output per ciascun token è calcolato come somma pesata di tutti i vettori Value, con i pesi determinati dagli score di attenzione. Questo processo consente a ciascun token di aggregare selettivamente informazioni da tutti gli altri token, con i pesi appresi durante l’addestramento che catturano relazioni significative.
L’eleganza matematica della self-attention permette un’elaborazione efficiente. L’intero processo può essere espresso come operazioni di matrice: Attention(Q, K, V) = softmax(QK^T / √d_k)V, dove Q, K e V sono matrici che contengono tutti i vettori query, key e value rispettivamente. Questa formulazione matriciale consente la accelerazione tramite GPU, permettendo ai transformer di processare intere sequenze in parallelo invece che in modo sequenziale. Una sequenza di 512 token può essere elaborata in un tempo simile a quello richiesto per un solo token in una RNN, rendendo i transformer ordini di grandezza più veloci da addestrare. Questa efficienza computazionale, combinata con la capacità della self-attention di catturare dipendenze a lungo raggio, spiega perché i transformer sono diventati l’architettura dominante per il language modeling.
L’attenzione multi-head estende il meccanismo di self-attention eseguendo molteplici operazioni di attenzione parallele, ciascuna apprendendo aspetti diversi delle relazioni tra token. In un transformer tipico con 8 head di attenzione, gli embedding di input sono proiettati linearmente in 8 diversi sottospazi di rappresentazione, ciascuno con le proprie matrici di pesi Query, Key e Value. Ogni head calcola in modo indipendente i pesi di attenzione e produce vettori di output. Questi output sono poi concatenati e trasformati linearmente tramite una matrice di pesi finale, producendo l’output finale della multi-head attention. Questa architettura consente al modello di prestare attenzione simultaneamente a informazioni provenienti da diversi sottospazi in posizioni diverse.
Le analisi di modelli transformer addestrati hanno rivelato che le diverse head di attenzione si specializzano in differenti fenomeni linguistici. Alcune head si concentrano su relazioni sintattiche, imparando a prestare attenzione a parole grammaticalmente collegate (ad es. verbi che si collegano ai loro soggetti e oggetti). Altre head si concentrano su relazioni semantiche, imparando a prestare attenzione a parole con significati affini. Altre ancora catturano dipendenze a lungo raggio, prestando attenzione a parole distanti nella sequenza ma semanticamente correlate. Alcune head imparano persino a concentrarsi principalmente sul token corrente, agendo di fatto come operazioni identitarie. Questa specializzazione emerge spontaneamente durante l’addestramento senza supervisione esplicita, dimostrando la potenza dell’architettura multi-head nell’apprendere rappresentazioni diverse e complementari.
Il numero di head di attenzione è un iperparametro chiave dell’architettura. I modelli più grandi usano tipicamente più head (16, 32 o anche di più), permettendo di catturare relazioni più diversificate. Tuttavia, la dimensionalità totale dell’attenzione viene mantenuta costante, quindi più head significano meno dimensioni per ogni head. Questa scelta di design bilancia i benefici di molteplici sottospazi di rappresentazione con l’efficienza computazionale. L’approccio multi-head si è dimostrato così efficace che è diventato standard in praticamente tutte le implementazioni moderne di transformer, da BERT e GPT fino alle architetture specializzate per visione, audio e compiti multimodali.
L’architettura transformer originale, come descritta nell’articolo “Attention is All You Need”, utilizza una struttura encoder-decoder ottimizzata per compiti sequence-to-sequence come la traduzione automatica. L’encoder elabora la sequenza di input e produce una sequenza di rappresentazioni ricche di contesto. Ogni strato dell’encoder contiene due componenti principali: un sottostrato di self-attention multi-head che permette ai token di prestare attenzione ad altri token nell’input, e una rete feed-forward position-wise che applica la stessa trasformazione non lineare a ciascuna posizione. Questi sottostrati sono collegati tramite connessioni residue (o skip connection), che sommano l’input all’output di ciascun sottostrato. Questa scelta progettuale, ispirata alle reti residue nella computer vision, permette l’addestramento di reti molto profonde consentendo ai gradienti di fluire direttamente attraverso la rete.
Il decoder genera la sequenza di output un token alla volta, utilizzando informazioni sia dall’encoder che dai token generati in precedenza. Ogni strato del decoder contiene tre componenti principali: un sottostrato di self-attention mascherata che permette a ciascun token di prestare attenzione solo ai token precedenti (impedendo al modello di “barare” guardando i token futuri durante l’addestramento), un sottostrato di attenzione encoder-decoder che permette ai token del decoder di prestare attenzione agli output dell’encoder, e una rete feed-forward position-wise. Il mascheramento nel sottostrato di self-attention è cruciale: impedisce il flusso di informazioni da posizioni future a quelle passate, assicurando che le previsioni per la posizione i dipendano solo dagli output noti nelle posizioni minori di i. Questa struttura autoregressiva è essenziale per generare sequenze un token alla volta.
L’architettura encoder-decoder si è dimostrata particolarmente efficace per compiti in cui input e output hanno strutture o lunghezze diverse, come traduzione automatica (tradurre da una lingua all’altra), riassunto (condensare documenti lunghi) e question answering (generare risposte dal contesto). Tuttavia, i LLM moderni come GPT usano architetture solo decoder, dove un unico stack di strati decoder processa sia il prompt di input sia genera l’output. Questa semplificazione riduce la complessità del modello e si è dimostrata altrettanto, se non più, efficace per i compiti di language modeling, probabilmente perché il modello può apprendere a usare la self-attention per processare input e generare output in modo unificato.
Una sfida cruciale nell’architettura transformer è rappresentare l’ordine dei token in una sequenza. A differenza delle RNN, che preservano implicitamente l’ordine tramite la loro struttura ricorrente, i transformer processano tutti i token in parallelo e non hanno una nozione incorporata di posizione. Senza informazioni esplicite sulla posizione, un transformer tratterebbe la sequenza “Il gatto si è seduto sul tappeto” come identica a “tappeto sul seduto è si gatto Il”, il che sarebbe disastroso per la comprensione del linguaggio. La soluzione è il positional encoding, che aggiunge vettori dipendenti dalla posizione agli embedding dei token prima dell’elaborazione.
L’articolo originale sui transformer usa positional encoding sinusoidali, dove il vettore di posizione per posizione pos e dimensione i è calcolato come:
Queste funzioni sinusoidali creano un pattern unico per ogni posizione, con frequenze diverse per ciascuna dimensione. Le frequenze più basse (i più piccoli) variano lentamente con la posizione, catturando informazioni di posizione a lungo raggio, mentre le frequenze più alte variano rapidamente, catturando dettagli fini sull’ordine. Questo design ha diversi vantaggi: generalizza naturalmente a sequenze più lunghe rispetto a quelle viste durante l’addestramento, fornisce transizioni di posizione fluide e permette al modello di apprendere relazioni di posizione relativa. I vettori di positional encoding sono semplicemente sommati agli embedding dei token prima del primo layer di attenzione, e il modello impara a usare questa informazione posizionale durante l’addestramento.
Sono stati proposti e studiati schemi alternativi di positional encoding, tra cui rappresentazioni di posizione relative (che codificano le distanze tra i token invece delle posizioni assolute) e rotary position embeddings (RoPE) (che ruotano i vettori embedding in base alla posizione). Queste alternative hanno mostrato miglioramenti in alcuni scenari, in particolare per sequenze molto lunghe o durante il fine-tuning su sequenze più lunghe di quelle viste in addestramento. La scelta del positional encoding può influenzare significativamente le prestazioni del modello e rimane un’area di ricerca attiva nell’ottimizzazione dell’architettura transformer.
Comprendere l’Architettura Transformer è essenziale per capire come i sistemi di IA moderni generano risposte che appaiono su piattaforme come ChatGPT, Claude, Perplexity e Google AI Overviews. Questi sistemi, tutti basati sulla tecnologia transformer, processano le query degli utenti tramite molteplici strati di self-attention, riuscendo così a comprendere il contesto e generare risposte coerenti e rilevanti. Quando un utente pone una domanda su un brand, un prodotto o un dominio, i meccanismi di attenzione del modello transformer determinano quali parti dei dati di addestramento sono più rilevanti, e il decoder genera una risposta che può menzionare o fare riferimento a quel brand.
Per le organizzazioni che utilizzano piattaforme di monitoraggio IA come AmICited, comprendere l’architettura transformer fornisce un contesto fondamentale per interpretare come e perché i brand appaiono nei contenuti generati dall’IA. La capacità della self-attention di catturare relazioni tra concetti fa sì che i brand menzionati nei dati di addestramento possano essere associati a specifici argomenti, settori o casi d’uso. Quando un utente interroga
L'Architettura Transformer elabora intere sequenze in parallelo utilizzando la self-attention, mentre RNN e LSTM processano le sequenze in modo sequenziale, un elemento alla volta. Questa parallelizzazione rende i transformer significativamente più veloci da addestrare e migliori nel catturare dipendenze a lungo raggio tra parole o token distanti. I transformer evitano anche il problema della scomparsa del gradiente che affliggeva le RNN, permettendo loro di apprendere efficacemente anche da sequenze molto lunghe.
La self-attention calcola tre vettori (Query, Key e Value) per ogni token nella sequenza di input. Il vettore Query di un token viene confrontato con i vettori Key di tutti i token per determinare i punteggi di rilevanza, che vengono normalizzati tramite softmax. Questi pesi di attenzione sono poi applicati ai vettori Value per creare rappresentazioni sensibili al contesto. Questo meccanismo permette a ciascun token di 'prestare attenzione' o concentrarsi su altri token rilevanti nella sequenza, consentendo al modello di comprendere contesto e relazioni.
I componenti principali includono: (1) Input Embeddings e Positional Encoding per rappresentare token e le loro posizioni, (2) Strati di Multi-Head Self-Attention che calcolano l'attenzione tra diversi sottospazi di rappresentazione, (3) Reti Neurali Feed-Forward applicate indipendentemente a ciascuna posizione, (4) Stack di Encoder che processa le sequenze di input, (5) Stack di Decoder che genera le sequenze di output, e (6) Connessioni Residuali e Layer Normalization per la stabilità dell'addestramento. Questi componenti lavorano insieme per consentire un'elaborazione parallela efficiente e una comprensione del contesto.
L'Architettura Transformer è eccellente per i LLM perché consente l'elaborazione parallela di intere sequenze, riducendo drasticamente i tempi di addestramento rispetto alle RNN sequenziali. Cattura le dipendenze a lungo raggio in modo più efficace tramite la self-attention, permettendo ai modelli di comprendere il contesto su interi documenti. L'architettura si scala anche in modo efficiente con dataset e parametri più grandi, caratteristica essenziale per addestrare modelli con miliardi di parametri che dimostrano capacità emergenti.
L'attenzione multi-head esegue simultaneamente molteplici meccanismi di attenzione paralleli (tipicamente 8 o 16 head), ciascuno operante su diversi sottospazi di rappresentazione. Ogni head impara a concentrarsi su diversi tipi di relazioni e pattern nei dati. Gli output di tutte le head vengono concatenati e trasformati linearmente, consentendo al modello di catturare informazioni contestuali diversificate. Questo approccio migliora significativamente la capacità del modello di comprendere relazioni complesse e migliora le prestazioni complessive.
Il positional encoding aggiunge informazioni sulle posizioni dei token agli embedding di input utilizzando funzioni seno e coseno a diverse frequenze. Poiché i transformer processano tutti i token in parallelo (al contrario delle RNN sequenziali), necessitano di informazioni esplicite sulla posizione per comprendere l'ordine delle parole. I vettori di positional encoding vengono sommati agli embedding dei token prima dell'elaborazione, permettendo al modello di apprendere come la posizione influisce sul significato e di generalizzare anche su sequenze più lunghe di quelle viste in addestramento.
L'encoder elabora la sequenza di input e crea rappresentazioni contestuali ricche tramite molteplici strati di self-attention e reti feed-forward. Il decoder genera la sequenza di output un token alla volta, utilizzando l'attenzione encoder-decoder per concentrarsi sulle parti rilevanti dell'input. Questa struttura è particolarmente utile per compiti sequence-to-sequence come la traduzione automatica, ma i LLM moderni spesso usano architetture solo decoder per i task di generazione testuale.
L'Architettura Transformer alimenta i sistemi di IA che generano risposte su piattaforme come ChatGPT, Claude, Perplexity e Google AI Overviews. Comprendere come i transformer processano e generano testo è cruciale per le piattaforme di monitoraggio IA come AmICited, che tracciano dove appaiono brand e domini nelle risposte generate dall'IA. La capacità dell'architettura di comprendere il contesto e generare testo coerente influenza direttamente come i brand vengono menzionati e rappresentati negli output dell'IA.
Inizia a tracciare come i chatbot AI menzionano il tuo brand su ChatGPT, Perplexity e altre piattaforme. Ottieni informazioni utili per migliorare la tua presenza AI.
GPT-4 è l’avanzato LLM multimodale di OpenAI che combina elaborazione di testo e immagini. Scopri le sue capacità, l’architettura e l’impatto sul monitoraggio d...
L'Architettura dell'Informazione è la pratica di organizzare e strutturare i contenuti per un'usabilità ottimale. Scopri come l'IA migliora la reperibilità, l'e...
Il meccanismo di attenzione è una tecnica di machine learning che guida i modelli di deep learning a dare priorità alle parti rilevanti dei dati di input. Scopr...