
AI回答においてAIモデルは何を引用するかどう決めるのか
ChatGPT、Perplexity、GeminiなどのAIモデルがどのように引用元を選ぶのか、その引用メカニズムやランキング要因、AIで可視性を高めるための最適化戦略を解説します。...
1 分で読める
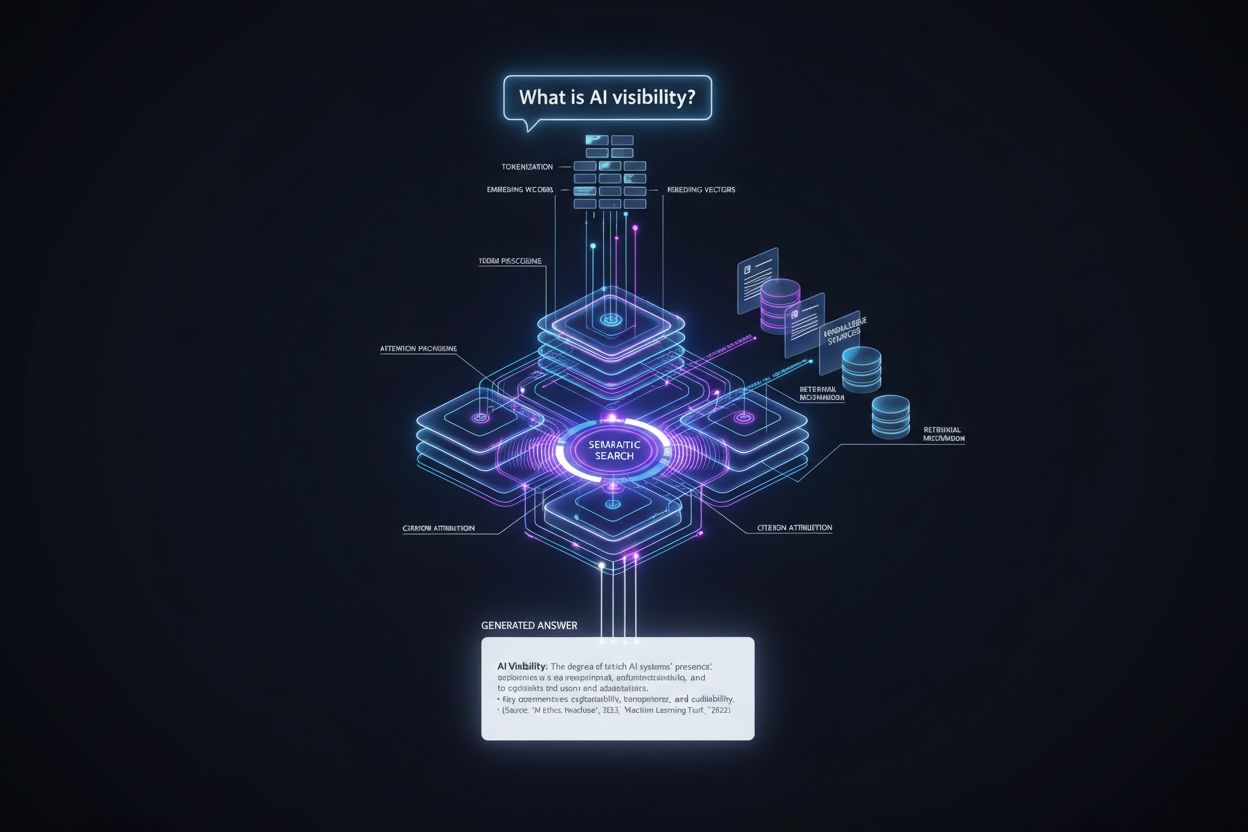
AIモデルがどのように回答を生成し、引用を配置するかを学びましょう。ChatGPT、Perplexity、Google AIの回答であなたのコンテンツがどこに現れるか、AIでの可視性を最適化する方法を解説します。
AI生成回答は、何百万人ものユーザーにとって主要な情報発見手段となり、インターネット上の情報の流れを根本的に変えています。最新の調査によると、研究者のAI利用率は2025年に84%へと急増し、そのうち62%が研究や出版業務にAIツールを活用しています(2024年の全体AI利用率はわずか57%でした)。しかし、多くのコンテンツ制作者は、AI生成回答内での引用の配置がランダムではなく、どのソースが可視化され、どのソースが見えなくなるかを決定する高度な技術アーキテクチャに従っていることを認識していません。引用がどこで、なぜ現れるのかを理解することは、AI主導の発見環境において可視性を維持したい全ての人にとって不可欠となっています。
モデルネイティブ合成と**検索拡張生成(RAG)**の違いは、AI回答における引用の現れ方を根本的に左右します。モデルネイティブ合成は学習時に組み込まれた知識のみに依存しますが、RAGは最新情報を外部から検索し、回答を現実の情報に根拠付けます。この違いは引用の配置や可視性に大きな影響を与えます。
| 特徴 | モデルネイティブ合成 | RAG |
|---|---|---|
| 定義 | 学習データのみから生成された回答 | リアルタイムに検索したソースに基づく回答 |
| 速度 | 高速(検索のオーバーヘッドなし) | 遅い(検索ステップが必要) |
| 正確性 | 幻覚や古い情報を含む場合あり | 最新ソースで高精度 |
| 引用能力 | 引用が制限される、またはなし | 豊富で追跡可能な引用 |
| 主な用途 | 一般知識・創造的タスク | ニュース・研究・ファクトチェック・独自データ |
PerplexityやGoogleのAI OverviewsのようなRAGベースのシステムは、検索ソースを必ず参照する必要があるため、引用が多くなります。一方、従来のChatGPT回答などモデルネイティブ方式は引用が少ない傾向があります。どの方式を採用しているかを理解することで、制作者は引用の可能性を予測し最適化できます。
ユーザーの問い合わせから引用付き回答が生成されるまでには、引用配置が複数の段階で決定される正確な技術パイプラインがあります。プロセスは以下の通りです。
クエリ処理:ユーザーの質問はトークン化され(モデルが理解できる単位に分割)、意図・エンティティ・意味が埋め込みベクトルで解析されます。
情報検索:システムは知識ベース(学習データ、インデックス化文書、リアルタイムソース)から意味検索を実施し、キーワード一致ではなく意味的な一致で候補ソースを検索、関連度順に返します。
コンテキスト組み立て:取得した情報はコンテキストウィンドウ(モデルが同時に処理できるテキスト量)に整理され、最も関連性の高いソースが注目される位置に配置されます。
トークン生成:モデルは自己注意メカニズムで直前のトークンやソース情報を参照しながら、一度に1トークンずつ回答文を生成し、一貫性と文脈のある回答を作ります。
引用付与:トークン生成中、モデルはどのソース文書が特定の主張に影響したかを追跡し、信頼度やプラットフォーム要件に応じて明示的な引用を付与するか決定します。
出力提供:最終回答は各プラットフォームの仕様(インライン引用、脚注、ソースパネル、ホバーリンク等)に沿って整形され、権威性や関連性のメタデータとともにユーザーに届けられます。
引用の配置はAIプラットフォームごとに大きく異なり、制作者の可視性機会も変わります。主なプラットフォームの引用処理は以下の通りです。
ChatGPT:引用は回答下部の「Sources」パネルにまとめて表示され、ユーザーがクリックして初めて見られます。リンクは通常3~5件で、高権威ドメインが優先されます。
Perplexity:引用は回答本文中に上付き数字でインライン表示され、下部に全ソースリストが付きます。全ての主張が追跡でき、最も引用の透明性が高いスタイルです。
Google Gemini:引用は回答文中のリンクとしてインライン表示され、「Sources」セクションに全参照資料が一覧されます。Googleのナレッジグラフとの統合でソース選定が左右されます。
Claude:引用は脚注形式で角括弧付きで示され、回答の流れを妨げずにソースが確認できます。多様性と信頼性を重視します。
DeepSeek:引用は本文に目立たないインラインハイパーリンクで表示され、ソースがナラティブに溶け込むスタイルです。
この違いにより、Perplexityで引用されたソースは直接トラフィックを得やすいのに対し、ChatGPTで引用されてもユーザーが「Sources」パネルを開かなければ見逃される可能性があります。プラットフォームごとの引用パターンはトラフィックと可視性に直結します。

引用配置の判断は、回答生成前の検索システム段階で始まります。意味検索は、ユーザーのクエリとインデックス化された文書をベクトル埋め込み(キーワードではなく意味を数値化したもの)に変換します。システムは、クエリ埋め込みと文書埋め込み間の類似度スコアを計算し、ユーザー意図に最も近いソースを特定します。
ランキングアルゴリズムは、関連度スコア、ドメイン権威性、コンテンツの新鮮さ、ユーザーエンゲージメント指標、構造化データの質など複数のシグナルで候補を並べ替えます。ここで上位にランクされたソースが生成モデルのコンテキストウィンドウに含まれやすく、引用される可能性が高まります。つまり、権威あるドメインの構造化・意味明瞭な記事は、同じ内容でも新興ドメインの未構造記事より頻繁に引用されます。検索段階が事実上、引用候補を決めてしまうのです。
コンテンツ構造はユーザー体験だけでなく、AIが情報を抽出・理解・引用できるかに直結します。AIモデルはフォーマットの手がかりから情報の境界や関連性を判断します。引用されやすくする構造要素は以下の通りです。
これらの原則に沿ったコンテンツは、構造化されていない同等品質のものより2~3倍多く引用されます。理由は単純で、AIが抽出・属性付けしやすいからです。
ソースが検索・コンテキストウィンドウへ組み込まれると、モデルは複数の信頼性レンズで各ソースを評価し、引用するかを決定します。ソース信頼性評価は、(バックリンクやドメイン年齢、ブランド認知による)ドメイン権威性、著者の専門性(署名、著者略歴、資格シグナル)、主題関連性(クエリとの主な一致)などを考慮します。
関連度スコアは、ソースがクエリにどれほど直接回答しているかを測り、完全一致の回答が最も高評価になります。新鮮さ要因は、特にニュースや研究、変化の激しいテーマで、最新ソースの選択を左右します。権威シグナルには、他の権威ソースからの引用、学術データベースでの言及、ナレッジグラフの登場などが含まれます。メタデータの影響は、タイトルタグ・メタディスクリプション・構造化データの明示的な信頼性アピールから得られます。最後に、構造化データ(Schema.orgマークアップ)は著者資格・公開日・レビュー評価・ファクトチェック状況などの機械可読な信頼性シグナルを直接伝え、引用の確実性を高めます。
AIプラットフォームは引用表示方法に独自スタイルを採用しており、引用の可視性が異なります。主なパターンは以下です。
インライン引用(Perplexityスタイル):
「最新の調査によると、研究者のAI利用率は2025年に84%に跳ね上がりました[1]。そのうち62%は研究タスクにAIツールを利用しています[2]。」
段落末引用(Claudeスタイル):
「研究者のAI利用率は2025年に84%に跳ね上がり、62%が研究タスクにAIを利用しています。[出典: Wiley Research Report, 2025]」
脚注型引用(学術スタイル):
「研究者のAI利用率は2025年に84%¹、AIツール利用率は62%²となっています。」
ソースリスト型(ChatGPTスタイル):
本文でインライン引用はなく、回答の後に「Sources」セクションで3~5リンクがまとめて表示されます。
ホバー引用(新興パターン):
下線付きテキストにマウスを乗せるとソース情報が表示される形式で、視覚的な煩雑さを抑えつつ追跡性を確保します。
各スタイルはユーザー行動にも影響します。インライン引用は即時クリックを促し、ソースリストは能動的な操作が必要、ホバー引用は可視性と美観を両立します。引用される可能性はプラットフォームごとに異なるため、複数プラットフォームでの監視が不可欠です。
引用配置の仕組みを理解することは、ビジネス成果に直結します。トラフィックへの影響は即時的で、Perplexityでインライン引用されたソースは、ChatGPTのSourcesパネルだけに掲載された場合と比べ3~5倍のリファラルトラフィックを獲得します。可視性とクリック率の関係は直線的ではなく、引用されるだけではなく配置・プラットフォーム・文脈が重要です。
ブランド権威性は時間とともに強化されます。複数AIプラットフォームで継続的に引用されると権威シグナルが蓄積し、従来の検索順位も上がり、今後のAI引用率も高まる「好循環」が生まれます。競争優位性は、AI引用最適化を競合より早く始めたブランドが享受します。スキーマ実装や構造化最適化の早期導入は、現状で引用シェアを大きく獲得できます。SEOへの波及効果もあり、AI引用最適化されたコンテンツは従来検索でも高評価となる傾向です。AmICitedの価値は明白で、AI主導の発見環境では引用状況の可視性を持たないことは検索順位を知らないのと同じ「重大な死角」となります。
AI引用を最適化するには、コンテンツ作成と構造に具体的な変化が必要です。特に効果的な戦術は以下の通りです。
これらを実践した制作者は、3~6か月で引用率が40~60%向上し、リファラルトラフィックやブランド権威性も大きく高まります。
引用のモニタリングはもはや任意ではなく、AI主導の発見環境で自らの可視性を把握するための必須インフラです。なぜモニタリングが重要かは明快で、計測しないものは最適化できず、引用パターンはAIシステムの進化や新規プラットフォームの登場で変化し続けます。追跡すべき指標は、引用頻度(どれだけ引用されるか)、引用配置(インラインかソースリストか)、プラットフォーム分布(どこで引用されやすいか)、クエリ文脈(どのトピックで引用が発生するか)、トラフィック帰属(AI引用からのリファラル量)などです。
機会の特定には、引用ギャップ分析が有効です。競合が引用されて自分がされていないトピック、引用されにくいプラットフォーム、成果が出ていないコンテンツタイプを分析し、最適化のターゲットを明らかにします。たとえば、ハウツーガイドがスキーママークアップ未実装で引用されていなかったり、研究系コンテンツがPerplexityでインライン抽出できない構造だったりすることが分かります。
AmICitedは、ChatGPT、Perplexity、Gemini、Claudeなど主要AIプラットフォーム全体でリアルタイムに引用を自動追跡します。手作業で繰り返しクエリを投げる代わりに、AmICitedが引用パターンを自動監視し、新規引用を通知、競合比較データも提供します。コンテンツ制作者・マーケター・SEO担当者にとって、引用モニタリングを手間のかかる手作業から、自動で実用的なインサイトを得られる仕組みに変えます。AI主導の発見環境では、どこで引用されているかの可視性は検索順位の可視性と同等に重要であり、AmICitedならそれが大規模に実現できます。
モデルネイティブの回答は学習時に習得したパターンから生成されますが、RAGは回答を生成する前に最新データを取得します。RAGは特定のソースに基づいて回答を根拠付けるため、引用がより明確で追跡可能となり、ユーザーやコンテンツ作成者にとって透明性が高くなります。
各プラットフォームは異なるアーキテクチャを採用しています。PerplexityやGeminiは引用付与型RAGを重視しますが、ChatGPTは閲覧機能が有効でない限りモデルネイティブ生成が基本です。これは各プラットフォームの設計思想や透明性へのアプローチの違いを反映しています。
明確で整理された構造、直接的な回答、適切な見出しやスキーママークアップがあるコンテンツは、AIシステムが抽出しやすくなります。回答を冒頭に配置しリストや表を使うと、AIが解析・引用しやすくなります。
スキーママークアップはAIシステムがコンテンツの構造やエンティティの関係を理解しやすくし、正確な属性付けや引用を助けます。適切なスキーマ実装は引用の可能性を高め、AIがコンテンツの信頼性を検証する助けにもなります。
はい。回答優先の構造、明確なフォーマット、事実の正確性、信頼できるソース、適切なスキーマ実装に注力しましょう。引用状況をモニタリングし、実績データに基づいて継続的に改善することが重要です。
AmICitedのようなツールは、ChatGPT、Perplexity、Google AI Overviewsなどでのブランド言及をモニタリングし、どこでどのようにAI回答で引用されているかを可視化します。これにより最適化のための実用的なインサイトが得られます。
AIの引用自体がGoogleの順位に直接影響するわけではありませんが、ブランドの可視性や権威性のシグナルが高まります。AIに引用されることでトラフィック増加やオンラインプレゼンス強化につながり、間接的なSEO効果をもたらします。
両者は補完的です。従来のSEOは検索結果での順位向上を目指しますが、AI引用最適化はAI生成回答への露出に注力します。現代の発見環境において、どちらも包括的な可視性のために重要です。
AI生成回答であなたのブランドがどこに現れているかを正確に把握しましょう。ChatGPT、Perplexity、Google AI Overviewsなどでの引用をAmICitedで追跡できます。
ChatGPT、Perplexity、GeminiなどのAIモデルがどのように引用元を選ぶのか、その引用メカニズムやランキング要因、AIで可視性を高めるための最適化戦略を解説します。...
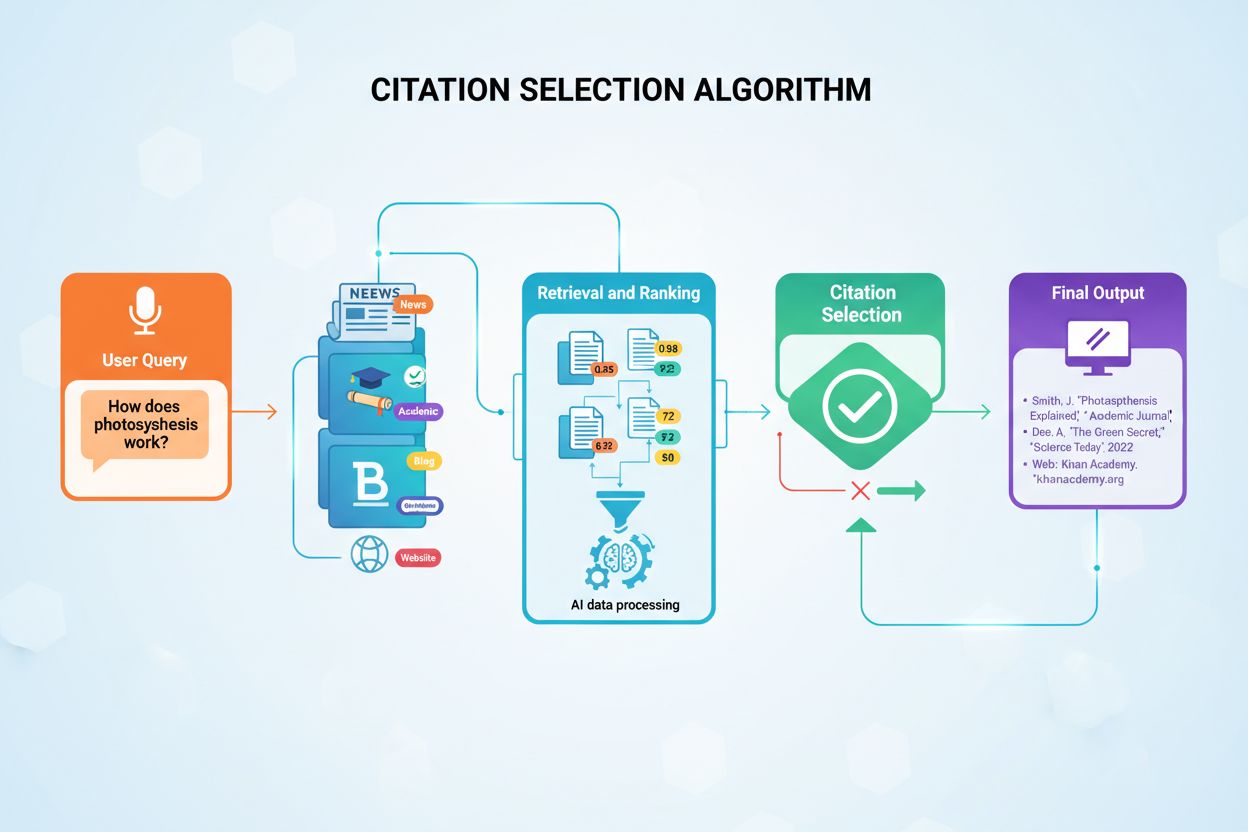
AIシステムがどの情報源を引用し、どれを要約・言い換えるかを選ぶ仕組みを解説。引用選択アルゴリズム、バイアスパターン、AI生成応答におけるコンテンツ可視性向上の戦略を理解しよう。...
AIモデルが何を引用するか決める仕組みについてのコミュニティディスカッション。ChatGPT、Perplexity、Geminiでの引用パターンを分析したSEO担当者たちのリアルな経験。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.