AIトレーニングをブロックし検索は許可:選択的クローラー制御
AIトレーニングボットからコンテンツを守りつつ、AI検索結果での可視性を維持するための選択的AIクローラーのブロック方法を解説。パブリッシャー向けの技術的戦略。...
2 分で読める

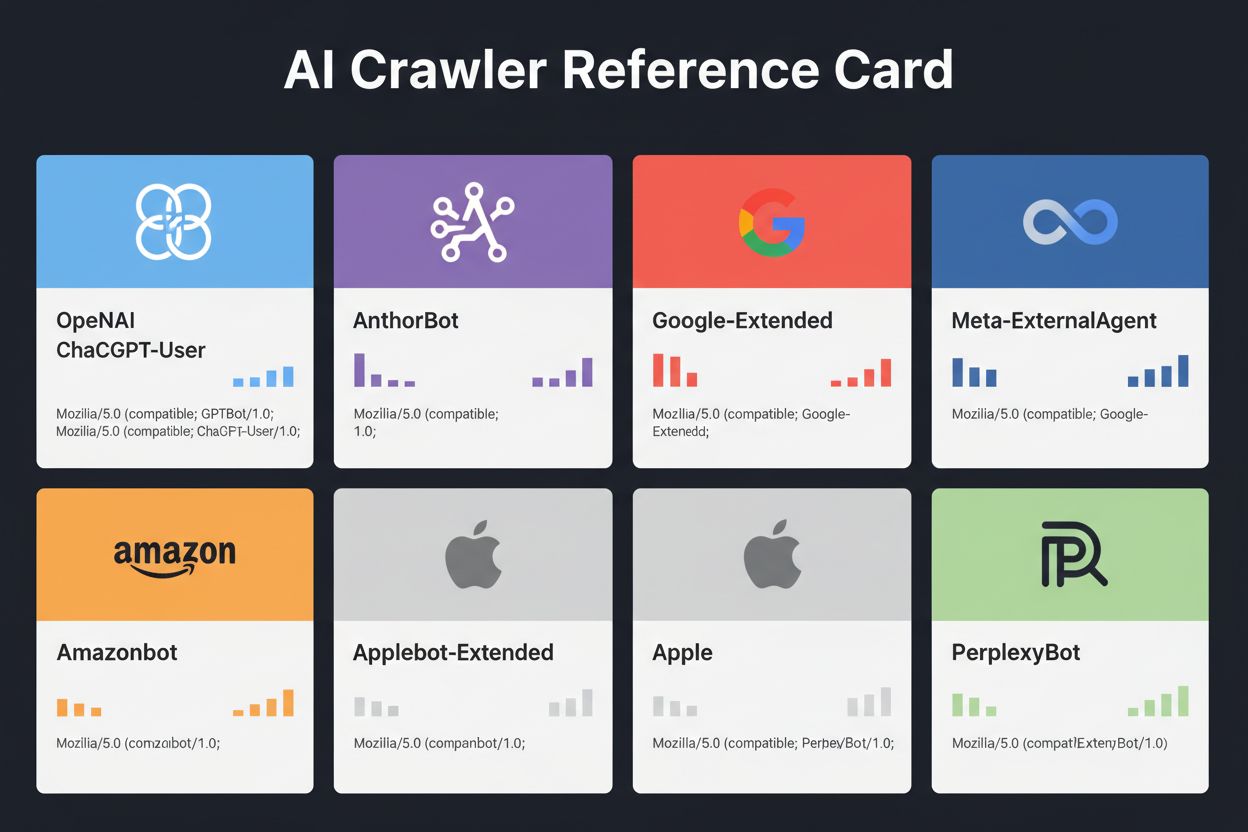
AIクローラーおよびボットの完全リファレンスガイド。GPTBot、ClaudeBot、Google-Extended、20種類以上のAIクローラーをユーザーエージェント・クロールレート・ブロック戦略とともに識別可能。
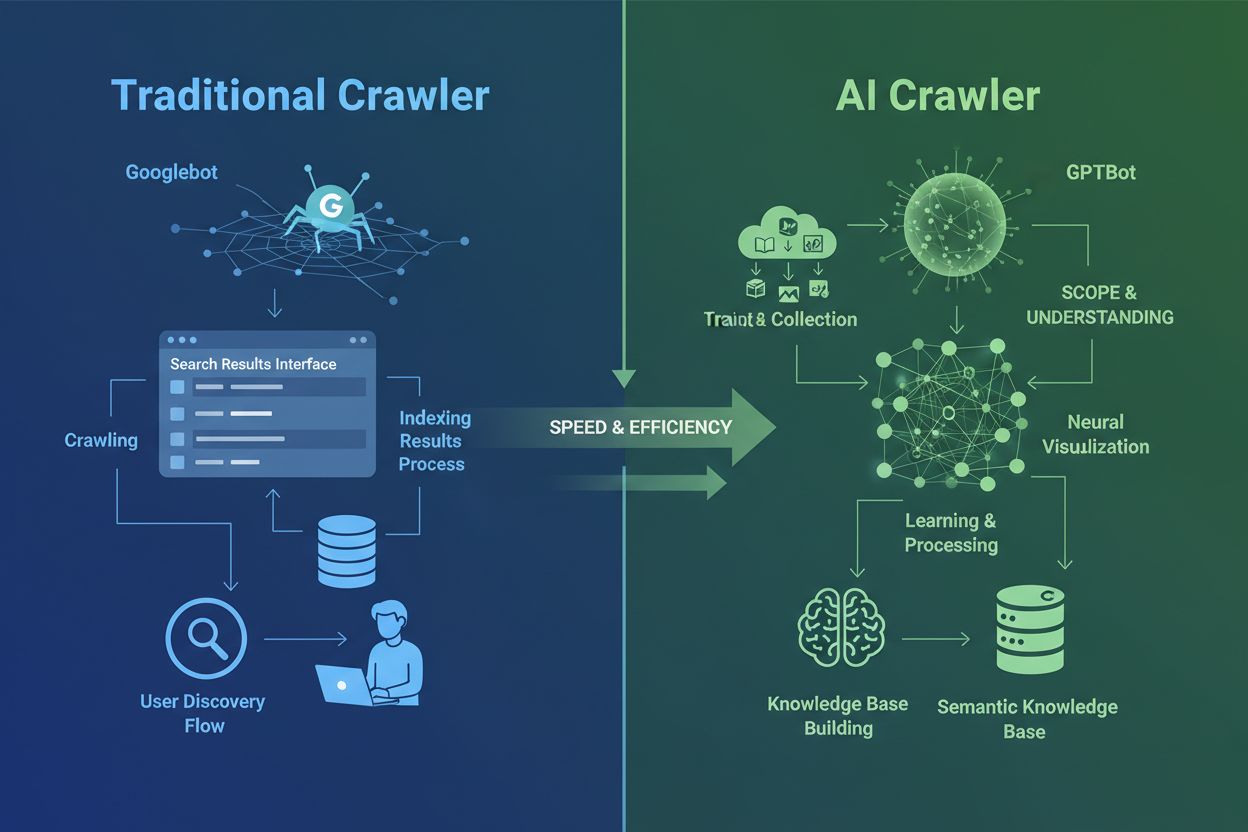
AIクローラーは、長年使われてきた従来の検索エンジンクローラーとは根本的に異なります。GooglebotやBingbotがユーザーの情報探索のためにコンテンツをインデックスするのに対し、GPTBotやClaudeBotなどのAIクローラーは、大規模言語モデル訓練を目的としてデータを収集します。この違いは非常に重要です。従来型クローラーは人間の発見経路を作り、AIクローラーはAIシステムの知識ベースへ情報を供給します。最近のデータによると、AIクローラーは全ウェブサイトのボットトラフィックの約80%を占めており、訓練用クローラーは大量のコンテンツを消費する一方でパブリッシャーへのリファラートラフィックは極めて少量です。従来型クローラーが動的なJavaScript重サイトのクロールに苦戦するのとは対照的に、AIクローラーは高度な機械学習でコンテキストを人間のように理解可能です。意味・トーン・目的をマニュアル設定なしに解釈できるため、ウェブインデックス技術における飛躍をもたらし、サイト運営者はクローラーマネジメント戦略の全面的な見直しを迫られています。
大手テック企業が独自の大規模言語モデルを構築するなか、AIクローラーの勢力図はますます複雑化しています。OpenAI、Anthropic、Google、Meta、Amazon、Apple、Perplexityは、それぞれ異なる役割のクローラーを複数運用し、それぞれのAIエコシステムで別個のミッションを担っています。企業が複数のクローラーを運用するのは、用途ごとに求められる動作が異なるためです。あるクローラーは大規模な訓練データ収集、他はリアルタイム検索インデックス、また他はユーザーリクエスト時のみコンテンツ取得を担当します。このエコシステムを理解するには、主な3カテゴリを押さえましょう:モデル訓練用クローラー、AI検索・引用用クローラー、そしてユーザーリクエスト時専用のフェッチャーです。以下の表は主要プレイヤーの概要です:
| 企業 | クローラー名 | 主な目的 | クロールレート | 訓練データ利用 |
|---|---|---|---|---|
| OpenAI | GPTBot | モデル訓練 | 100ページ/時 | あり |
| OpenAI | ChatGPT-User | ユーザーリクエスト | 2400ページ/時 | なし |
| OpenAI | OAI-SearchBot | 検索インデックス | 150ページ/時 | なし |
| Anthropic | ClaudeBot | モデル訓練 | 500ページ/時 | あり |
| Anthropic | Claude-User | リアルタイムアクセス | 10ページ未満/時 | なし |
| Google-Extended | Gemini AI訓練 | 変動 | あり | |
| Gemini-Deep-Research | リサーチ機能 | 10ページ未満/時 | なし | |
| Meta | Meta-ExternalAgent | AIモデル訓練 | 1100ページ/時 | あり |
| Amazon | Amazonbot | サービス改善 | 1050ページ/時 | あり |
| Perplexity | PerplexityBot | 検索インデックス | 150ページ/時 | なし |
| Apple | Applebot-Extended | AI訓練 | 10ページ未満/時 | あり |
| Common Crawl | CCBot | オープンデータセット | 10ページ未満/時 | あり |
OpenAIはChatGPTエコシステムの中で3つのクローラーを運用しており、それぞれが異なる役割を持ちます。OpenAIのGPTBotは、インターネット上で最も広範かつ攻撃的なAIクローラーの一つです:
GPTBot - OpenAIの主力訓練クローラーで、ChatGPTやGPT-4oを含むGPTモデルの訓練・改良のために公開データを体系的に収集します。およそ1時間あたり100ページのペースで稼働し、robots.txtの指示を守ります。公式IPアドレスは https://openai.com/gptbot.json で公開されています。
ChatGPT-User - ユーザーがChatGPT上で特定のウェブページを閲覧リクエストした際に発動します。ユーザー動作に応じて高頻度(最大2400ページ/時)で稼働しますが、訓練には利用されません。ChatGPT検索結果でのリアルタイム可視性に貢献します。
OAI-SearchBot - ChatGPTの検索機能専用クローラーで、訓練データ収集は行わず、リアルタイム検索結果用のインデックス作成のみを担います(約150ページ/時)。
OpenAIのクローラーはrobots.txtを遵守し、公式IPレンジからのみ稼働するため、他社より管理しやすいのが特徴です。
Claude AIを開発するAnthropicも、複数目的・異なる透明性レベルのクローラーを運用しています。OpenAIほどドキュメントは充実していませんが、サーバーログから振る舞いが判明しています:
ClaudeBot - Claudeの知識ベース強化のための主力訓練クローラー。1時間あたり約500ページをクロールし、Claudeのモデル訓練に使われます。ユーザーエージェント文字列は Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)。
Claude-User - ClaudeユーザーがリアルタイムWebアクセスを要求した際にオンデマンドで最小限の量だけコンテンツを取得。認証を尊重し、制限突破を試みないためリソース面で比較的穏やかです。
Claude-SearchBot - Claude内検索機能をサポートするクローラーで、ごく低頻度でインデックス用にのみ稼働します。
Anthropicクローラーのクロール:リファー比率は特に問題視されており、Cloudflareデータによれば1件のリファラルに対し約38,000~70,000ページが事前クロールされているとのこと。これにより、コンテンツが大規模に消費されつつも引用はほとんどないという課題があります。
GoogleはAIクロールと検索インデックスを厳格に分離しており、Google-ExtendedがGemini(旧Bard)などAI製品訓練専用のクローラーとして稼働します(従来のGooglebotとは完全に分離)。
Google-Extendedのユーザーエージェントは:Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0。この分離により、robots.txtでGoogle-Extendedのみをブロックしても検索可視性に一切影響しません。Google公式でもGoogle-Extendedのブロックが検索順位・AI Overviewsへの掲載に影響しないと明言しています。ただし一部ウェブマスターからは懸念報告もありますので注意が必要です。Gemini-Deep-Researchも、Geminiのリサーチ機能をサポートする低頻度クローラーです。Googleクローラーの大きな技術的利点は、JavaScript実行と動的コンテンツのレンダリング能力にあり、React・Vue・Angularアプリもクロール可能です(OpenAIやAnthropicには不可)。JS依存サイト運営者にとって、この違いはAI可視性戦略上極めて重要です。
大手以外にも、多数のAIクローラーが存在します。Meta-ExternalAgentは2024年7月にひっそりと公開され、MetaのAIモデル訓練やFacebook・Instagram・WhatsApp製品改善用にウェブコンテンツをクロールします(約1100ページ/時)。BytespiderはByteDance(TikTokの親会社)が2024年4月に公開し、インターネットで最も攻撃的なクローラーの一つとして急浮上。第三者監視によれば、GPTBotやClaudeBotよりもはるかに高頻度でクロールしており、robots.txtを一貫して守らないとの報告もあるためIPベースでのブロックが推奨されます。
Perplexityのクローラーには検索インデックス用のPerplexityBotと、リアルタイム取得用のPerplexity-Userがあります。robots.txt無視の報告もありますが、同社は順守を主張しています。AmazonbotはAlexaのQA機能を担い、robots.txtを守りつつ約1050ページ/時で稼働。Applebot-Extendedは2024年6月導入で、Applebotで既にインデックスされたコンテンツのAI訓練利用を判断しますが、直接ウェブページをクロールしません。CCBot(Common Crawl運営)はオープンウェブアーカイブ構築用で、OpenAI・Google・Meta・Hugging Face等が利用中。xAI(Grok)、Mistral、DeepSeekなど新興クローラーもサーバーログに現れ始めており、エコシステムの拡大は続きます。
以下は、公式ドキュメントやサーバーログ分析に基づく主要AIクローラーの目的・ユーザーエージェント・robots.txtブロック記法等をまとめた総合リファレンスです。IPリストで検証可能なものは確認済みです:
| クローラー名 | 企業 | 目的 | ユーザーエージェント | クロールレート | IP検証 | robots.txt記法 |
|---|---|---|---|---|---|---|
| GPTBot | OpenAI | 訓練データ収集 | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.3; +https://openai.com/gptbot) | 100/時 | ✓ 公式 | User-agent: GPTBot Disallow: / |
| ChatGPT-User | OpenAI | リアルタイムユーザーリクエスト | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0 | 2400/時 | ✓ 公式 | User-agent: ChatGPT-User Disallow: / |
| OAI-SearchBot | OpenAI | 検索インデックス | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36; compatible; OAI-SearchBot/1.3 | 150/時 | ✓ 公式 | User-agent: OAI-SearchBot Disallow: / |
| ClaudeBot | Anthropic | 訓練データ収集 | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com) | 500/時 | ✓ 公式 | User-agent: ClaudeBot Disallow: / |
| Claude-User | Anthropic | リアルタイムWebアクセス | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-User/1.0) | 10未満/時 | ✗ 無 | User-agent: Claude-User Disallow: / |
| Claude-SearchBot | Anthropic | 検索インデックス | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Claude-SearchBot/1.0) | 10未満/時 | ✗ 無 | User-agent: Claude-SearchBot Disallow: / |
| Google-Extended | Gemini AI訓練 | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Google-Extended/1.0) | 変動 | ✓ 公式 | User-agent: Google-Extended Disallow: / | |
| Gemini-Deep-Research | リサーチ機能 | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Gemini-Deep-Research) | 10未満/時 | ✓ 公式 | User-agent: Gemini-Deep-Research Disallow: / | |
| Bingbot | Microsoft | Bing検索 & Copilot | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0) | 1300/時 | ✓ 公式 | User-agent: Bingbot Disallow: / |
| Meta-ExternalAgent | Meta | AIモデル訓練 | meta-externalagent/1.1 (+https://developers.facebook.com/docs/sharing/webmasters/crawler) | 1100/時 | ✗ 無 | User-agent: Meta-ExternalAgent Disallow: / |
| Amazonbot | Amazon | サービス改善 | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1) | 1050/時 | ✓ 公式 | User-agent: Amazonbot Disallow: / |
| Applebot-Extended | Apple | AI訓練 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15; compatible; Applebot-Extended | 10未満/時 | ✓ 公式 | User-agent: Applebot-Extended Disallow: / |
| PerplexityBot | Perplexity | 検索インデックス | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0) | 150/時 | ✓ 公式 | User-agent: PerplexityBot Disallow: / |
| Perplexity-User | Perplexity | リアルタイム取得 | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Perplexity-User/1.0) | 10未満/時 | ✓ 公式 | User-agent: Perplexity-User Disallow: / |
| Bytespider | ByteDance | AI訓練 | Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36; compatible; Bytespider | 10未満/時 | ✗ 無 | User-agent: Bytespider Disallow: / |
| CCBot | Common Crawl | オープンデータセット | CCBot/2.0 (https://commoncrawl.org/faq/ ) | 10未満/時 | ✓ 公式 | User-agent: CCBot Disallow: / |
| DuckAssistBot | DuckDuckGo | AI検索 | DuckAssistBot/1.2; (+http://duckduckgo.com/duckassistbot.html) | 20/時 | ✓ 公式 | User-agent: DuckAssistBot Disallow: / |
| Diffbot | Diffbot | データ抽出 | Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.1.2) Gecko/20090729 Firefox/3.5.2 Diffbot/0.1 | 10未満/時 | ✗ 無 | User-agent: Diffbot Disallow: / |
| MistralAI-User | Mistral | リアルタイム取得 | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; MistralAI-User/1.0) | 10未満/時 | ✗ 無 | User-agent: MistralAI-User Disallow: / |
| ICC-Crawler | NICT | AI/ML訓練 | ICC-Crawler/3.0 (Mozilla-compatible; https://ucri.nict.go.jp/en/icccrawler.html ) | 10未満/時 | ✗ 無 | User-agent: ICC-Crawler Disallow: / |
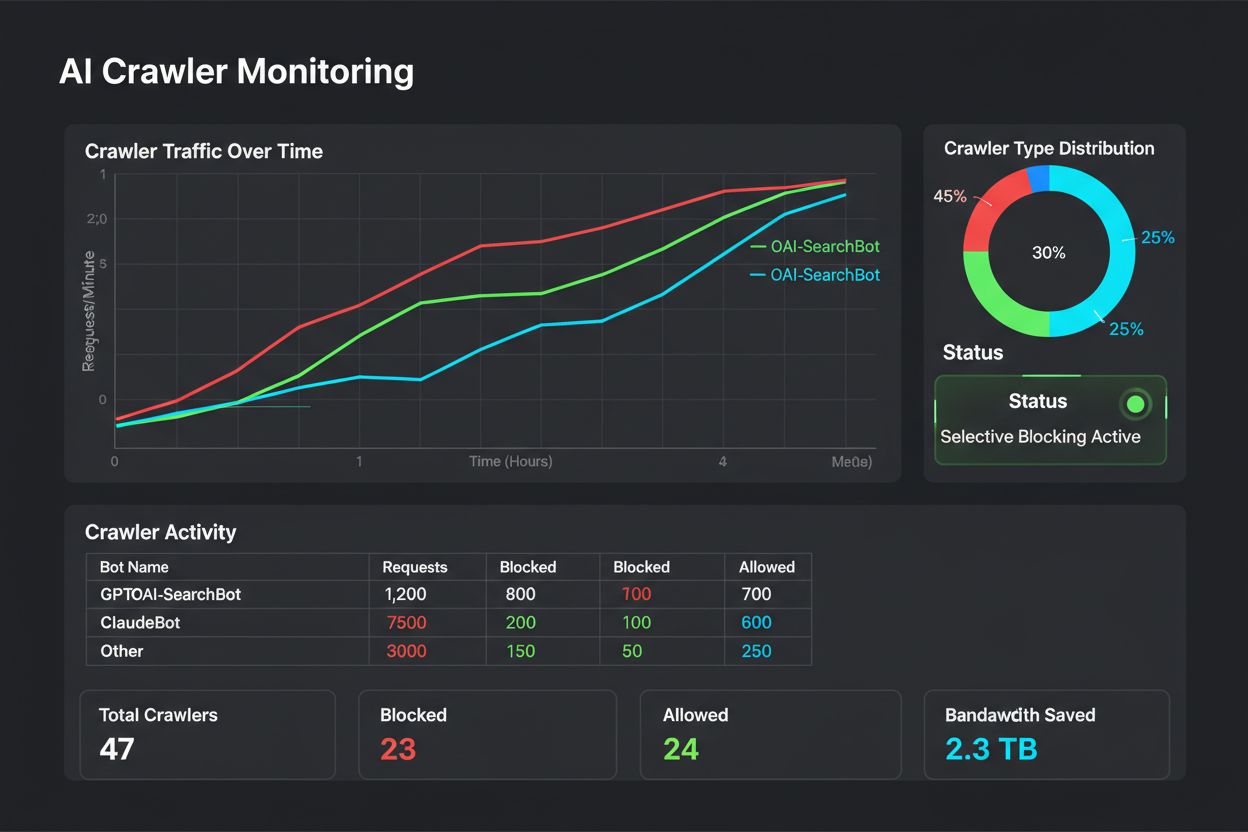
すべてのAIクローラーが同じ目的で動作しているわけではなく、これを理解することがブロック戦略の要となります。訓練クローラーはAIボットトラフィック全体の約8割を占め、主に大規模言語モデル構築用のデータセット収集を目的としています。一度あなたのコンテンツが訓練データセットに入れば、モデルの知識ベースに恒久的に組み込まれ、ユーザーがあなたのサイトを訪れる必要性が減る可能性もあります。GPTBot、ClaudeBot、Meta-ExternalAgentなどの訓練クローラーは高頻度かつ体系的にクロールし、リファラルはほぼゼロです。
検索・引用クローラーはAI検索体験用にインデックスを作成し、引用を通じてパブリッシャーに一定のトラフィックを送る場合があります。ChatGPTやPerplexityで質問された際に、関連ソースを表示するのがこのタイプ。訓練クローラーより中程度の頻度で、属性やリンク付きで動作します。ユーザーリクエスト型フェッチャーは、ユーザーがAIアシスタント経由で特定ページをリクエストした時だけ発動し、1回限りのオンデマンド取得を行います。これらの多くは訓練には使われないことを各社が明言しています。これらのカテゴリを理解することで、ビジネス上の優先順位に基づいた選択的ブロックが可能になります。
AIクローラーマネジメントの第一歩は、どのクローラーが実際にあなたのサイトを訪問しているか把握することです。サーバーアクセスログにはすべてのリクエストとユーザーエージェントが記録されています。多くのホスティングコントロールパネルにログ分析ツールがありますが、生ログへの直接アクセスも可能です。Apacheなら /var/log/apache2/access.log、Nginxなら /var/log/nginx/access.log です。以下のようにgrepで主要AIクローラーのリクエストを抽出できます:
grep -i "gptbot\|claudebot\|google-extended\|bytespider" /var/log/apache2/access.log | head -20
このコマンドは主要AIクローラーからの直近20件のリクエストを表示します。Google Search ConsoleはGoogle系クローラーの統計を、Cloudflare RadarはAIボットトラフィックのグローバル傾向を可視化できます。クローラーが正規かどうかは、リクエストIPが公式IPリスト(OpenAIは https://openai.com/gptbot.json、Amazonは https://developer.amazon.com/amazonbot/ip-addresses/ など)に含まれているかで判定しましょう。未認証IPからの偽装クローラーは即時ブロックが推奨されます。
robots.txtはクローラーアクセス制御の主力ツールです。サイトルートに配置し、どのクローラーがどこにアクセス可能かを指示します。AIクローラーごとにブロックするには以下のように記述します:
# OpenAIのGPTBotをブロック
User-agent: GPTBot
Disallow: /
# AnthropicのClaudeBotをブロック
User-agent: ClaudeBot
Disallow: /
# GoogleのAI訓練用(検索用ではない)をブロック
User-agent: Google-Extended
Disallow: /
# Common Crawlをブロック
User-agent: CCBot
Disallow: /
クローラーを許可しつつ、サーバーの過負荷を防ぐためレート制限も可能です:
User-agent: GPTBot
Crawl-delay: 10
Disallow: /private/
これはGPTBotに10秒間隔リクエストと/private/ディレクトリの回避を指示します。検索クローラーは許可し、訓練クローラーのみブロックするバランス型例:
# 従来検索エンジンは許可
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# AI訓練クローラーは全てブロック
User-agent: GPTBot
User-agent: ClaudeBot
User-agent: CCBot
User-agent: Google-Extended
User-agent: Bytespider
User-agent: Meta-ExternalAgent
Disallow: /
# AI検索クローラーのみ許可
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
ほとんどの信頼できるAIクローラーはrobots.txtを守りますが、一部攻撃的なものは無視するためrobots.txtだけでは完全防御はできません。
robots.txtはあくまで推奨(advisory)であり、強制力はありません。守らないクローラーへの強力な対策にはIPベースのサーバーレベルブロックが必要です。公式IPのみ許可し、それ以外からのAIクローラー偽装リクエストを全て遮断できます。
Apacheサーバーなら.htaccessで以下のようにブロック可能:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|ClaudeBot|anthropic-ai|Bytespider|CCBot) [NC]
RewriteRule .* - [F,L]
</IfModule>
robots.txt設定に関係なく、該当ユーザーエージェントは403 Forbiddenを返します。ファイアウォールルールでも公式IPレンジのみ許可し、他はブロック可能です。HTMLメタタグによるページ単位制御もあり、Amazon等一部クローラーはnoarchiveディレクティブを尊重します:
<meta name="robots" content="noarchive">
これは訓練利用を防止しつつインデックスは許可可能です。ターゲットや技術力に応じて最適なブロック方法を選びましょう。IPベースは最も強力ですが構成がやや難しく、robots.txtは手軽ですが非準拠クローラーには効果薄です。
ブロック実装は「やって終わり」ではありません。定期モニタリングで新たな問題や未対応クローラーを早期発見しましょう。週1回サーバーログで"bot"や"crawler"、“spider”、“GPT”、“Claude”、“Perplexity"等のユーザーエージェントをチェック。不自然なボットトラフィック増加には即時アラートを。Google Search ConsoleではGooglebotやGoogle-Extendedのクロール状況も追跡可能。Cloudflare RadarでAIクローラートレンドも把握しましょう。
robots.txtブロックの検証には yoursite.com/robots.txt を直接確認し、すべての指示が反映されているかチェック。サーバーレベルブロックはログで該当クローラーからのリクエストが遮断されているか確認します。ブロック後もアクセスがあれば、非準拠またはユーザーエージェント偽装の可能性が高いです。アナリティクスやサーバーログでクロール状況を随時テストしましょう。四半期ごとの見直しも必須です。AIクローラーの状況は急変し、新クローラーやユーザーエージェント変更も頻繁。定期的なリスト更新と検証を継続しましょう。
クローラー制御も重要ですが、AIが実際にあなたのコンテンツをどのように引用・参照しているか把握することも同じくらい重要です。AmICited.comはChatGPT・Perplexity・Google Geminiなど各種AIプラットフォーム上で、ブランドやコンテンツがどのようにAI回答に現れているかを包括的にモニタリングします。単にクローラーをブロックするだけでなく、AIクローラーによる可視性や権威性への実際の影響を把握できます。どのAIシステムが何回あなたのコンテンツを引用しているか、AI回答内でのブランド出現頻度、それがトラフィックや権威性にどう結びついているかも追跡可能。AI引用データをもとに、単なる推測ではなく実データで許可すべきクローラーを選択できるようになります。AmICited.comはあなたのコンテンツ戦略とも統合され、AI引用が多いトピックやコンテンツタイプも可視化。AI発見性最適化と知財保護を両立するデータドリブンな意思決定を実現します。
AIクローラーを許可・ブロックするかは、完全にあなたのビジネス状況と優先順位次第です。許可すべき場合: AI回答での可視性がトラフィック増加につながるニュースサイトやブログ、AI生成回答での引用がブランド価値向上につながる場合、業界理解のためAI訓練に参加したい場合、また
GPTBotやClaudeBotのようなAIクローラーは、大規模言語モデルを訓練するためにコンテンツを収集します。一方、Googlebotのような検索エンジンクローラーは、検索結果で人々が情報を見つけられるようにコンテンツをインデックスします。AIクローラーはAIシステムの知識ベースに情報を提供し、検索クローラーはユーザーがあなたのコンテンツを発見するのを助けます。主な違いは目的であり、「訓練」か「検索」かです。
いいえ、AIクローラーをブロックしても従来の検索順位には影響しません。GPTBotやClaudeBotなどのAIクローラーは、Googlebotのような検索エンジンクローラーとは完全に別物です。Google-Extended(AI訓練用)はブロックしつつ、Googlebot(検索用)は許可することも可能です。それぞれのクローラーは異なる目的を持っているため、一方をブロックしてももう一方には影響しません。
サーバーのアクセスログを確認することで、どのユーザーエージェントがあなたのサイトを訪れているか把握できます。GPTBot、ClaudeBot、CCBot、Bytespiderなどのボット名をユーザーエージェント文字列で探しましょう。多くのホスティングコントロールパネルにはログ解析ツールがあります。また、Google Search Consoleを使ってクロールアクティビティを監視できますが、ここではGoogleのクローラーのみが表示されます。
すべてのAIクローラーがrobots.txtを同じように尊重するわけではありません。OpenAIのGPTBot、AnthropicのClaudeBot、Google-Extendedは一般的にrobots.txtのルールを守ります。BytespiderやPerplexityBotについては、robots.txtを必ずしも一貫して守らないという報告もあります。robots.txtを守らないクローラーには、ファイアウォールや.htaccessによるIPベースのブロックが必要です。
これはあなたの目的次第です。独自コンテンツやサーバーリソースが限られている場合は訓練用クローラーをブロックしましょう。AI検索結果やチャットボットでの可視性を重視する場合は検索クローラーを許可すると良いでしょう。多くの企業は、特定のクローラーのみを許可し、Bytespiderのような攻撃的なものはブロックする選択的なアプローチをとっています。
新しいAIクローラーは定期的に登場するため、最低でも四半期ごとにブロックリストを見直し・更新しましょう。GitHubのai.robots.txtプロジェクトなど、コミュニティが管理するリストを追跡し、サーバーログを毎月チェックして未対応の新クローラーを特定します。AIクローラーの状況は急速に変化するので、戦略もあわせて進化させるべきです。
はい、リクエストのIPアドレスを、主要各社が公開している正式なIPリストと照合してください。OpenAIは https://openai.com/gptbot.json、Amazonは https://developer.amazon.com/amazonbot/ip-addresses/ で確認できます。他社も同様のリストを持っています。正規IPからのアクセスでない場合、たとえユーザーエージェントが本物でもブロックした方がよいでしょう。これは悪質なスクレイピングの可能性が高いです。
AIクローラーは大きな帯域幅やサーバーリソースを消費することがあります。BytespiderやMeta-ExternalAgentは特に攻撃的なクローラーです。AIクローラーのブロックによって、例えば帯域幅消費が1日800GBから200GBに減り、月約1500ドルのコスト削減になったという報告もあります。ピーク時のサーバーリソースを監視し、必要に応じて攻撃的なボットにレート制限を設けましょう。
どのAIクローラーがあなたのコンテンツを参照しているか把握し、ChatGPT・Perplexity・Google Geminiなどでの可視性を最適化しましょう。
AIトレーニングボットからコンテンツを守りつつ、AI検索結果での可視性を維持するための選択的AIクローラーのブロック方法を解説。パブリッシャー向けの技術的戦略。...

robots.txtを使って、どのAIボットがあなたのコンテンツにアクセスできるかをコントロールする方法を学びましょう。GPTBot、ClaudeBot、その他のAIクローラーをブロックするための実践的な例と設定戦略を網羅した完全ガイドです。...

GPTBotやClaudeBotなどのAIクローラーをrobots.txt、サーバーレベルブロック、高度な保護方法でブロックまたは許可する方法を学びます。事例付きの完全な技術ガイド。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.