
エンティティ認識
エンティティ認識は、テキスト中の固有表現を識別・分類するAIの自然言語処理機能です。その仕組みやAIモニタリングでの応用、現代のAIシステムにおける役割について解説します。...
1 分で読める

AIシステムがテキスト内のエンティティをどのように認識・処理するかを探ります。NERモデル、トランスフォーマーアーキテクチャ、エンティティ理解の実際の応用例について学びましょう。
エンティティ理解は現代の人工知能システムにおける基盤的な能力となっており、機械が非構造テキストから主要な人物・場所・概念を特定し理解できるようにしています。検索エンジンがユーザーの意図を理解したり、チャットボットが特定の人物や組織に関する複雑な質問に答えたりできるのは、エンティティ認識が人とコンピュータの意味ある対話の土台を成しているからです。この技術は業界を問わず重要であり、金融機関はコンプライアンス監視、医療システムは患者記録管理、ECプラットフォームは商品言及や顧客フィードバックの理解に活用しています。AIシステムがどのようにエンティティを抽出・解釈するのかを理解することは、実運用でNLPアプリケーションを構築・導入する全ての人にとって不可欠です。
固有表現抽出(NER)は、テキスト内の「意味のある特定単位」をあらかじめ定義されたカテゴリに分類するNLPタスクです。これらのエンティティは、言語における意味的重みを持つ具体的な主語を表します。すなわち、行動する人、意思決定する組織、出来事が起こる場所、時間を示す表現、取引を数量化する金額、売買される商品などです。エンティティ分類は、生のテキストを機械が推論・行動可能な構造化知識へと変換するために不可欠です。分類なしでは「Apple(会社)」と「apple(果物)」の違いや「John Smith」と「J. Smith」が同一人物であることも区別できません。エンティティを正確に分類できることが、ナレッジグラフ構築・情報抽出・質問応答・関係検出など下流アプリケーションを可能にします。
| エンティティタイプ | 定義 | 例 |
|---|---|---|
| PERSON | 個人 | “Steve Jobs”、“Marie Curie” |
| ORGANIZATION | 企業・団体・グループ | “Microsoft”、“United Nations”、“Harvard University” |
| LOCATION | 地理的な場所・地域 | “New York”、“Amazon川”、“Silicon Valley” |
| DATE | 日付や時間表現 | “2024年1月15日”、“次の火曜日”、“2023年第3四半期” |
| MONEY | 金額や通貨 | “$50 million”、"€100"、“5000円” |
| PRODUCT | 商品・サービス・創作物 | “iPhone 15”、“Windows 11”、“ChatGPT” |
現代のAIシステムは、トークン化により生テキストを個々のトークンに分割することから始まる多段階パイプラインでエンティティを処理します。各トークンは単語埋め込みによって数値ベクトルへと変換され、意味を保持した形でニューラルネットワークに入力されます。トランスフォーマーベースのモデルは、従来の逐次処理とは異なり、シーケンス全体を並列処理することで長距離依存関係や複雑な文脈関係を捉え、エンティティ理解に不可欠な情報を把握します。トランスフォーマー内部の自己注意機構は、シーケンス中の各トークンが他の全トークンの重要度を動的に重み付けし、周囲の文脈に応じて語の意味を決定します。たとえば「bank」は"river bank"と"savings bank"で異なる意味になることを文脈から理解できます。事前学習済み言語モデル(BERTやGPTなど)は、大規模コーパスから一般的な言語パターンを学び、エンティティ認識タスク用に微調整されます。これにより、構文・意味・世界知識の表現を活用できます。最終的なエンティティ認識層は通常、系列ラベリング手法(CRFや単純な分類ヘッドなど)を用いて、ニューラルネットワークが獲得した文脈表現にもとづきトークンごとにエンティティラベルを割り当てます。こうしたアーキテクチャにより、AIはエンティティの存在だけでなく、相互関係や文中での役割まで理解できるようになります。
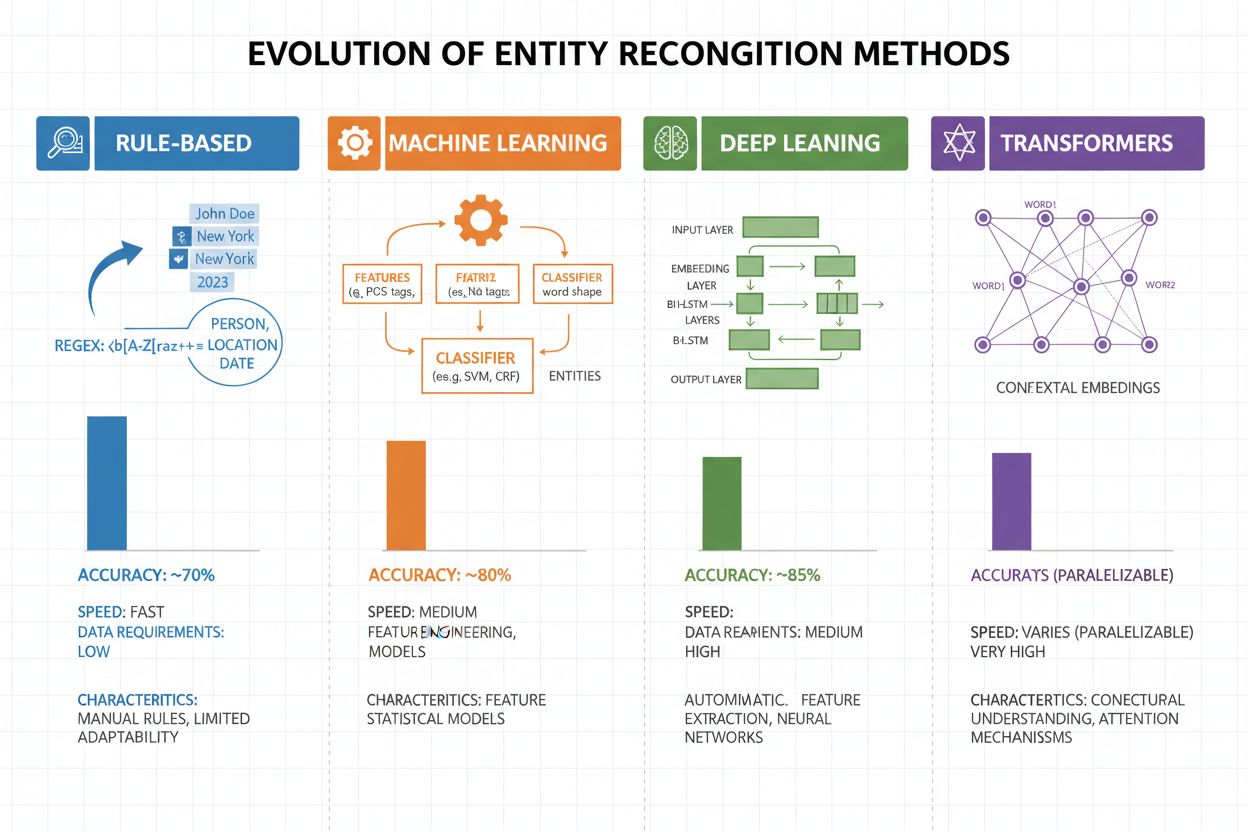
エンティティ認識はこの20年で大きく進化し、単純なルールベースから高度なニューラルアーキテクチャへと発展しました。初期のシステムは手作業によるルールや辞書に頼り、正規表現やパターンマッチでエンティティを検出していました。これは解釈しやすく訓練データも少量で済みますが、汎用性が低く保守が大変でした。機械学習の登場により、**サポートベクターマシン(SVM)や条件付き確率場(CRF)**などの教師あり手法が導入され、特徴設計によって精度が向上しましたが、依然として専門家による特徴設計が不可欠でした。ディープラーニング手法(LSTMやBiLSTMなど)は特徴抽出を自動化し、大規模ラベル付きデータセットさえあれば手作業なく高精度を実現しました。トランスフォーマーモデル(BERTやRoBERTaなど)は自己注意機構によって長距離依存や文脈の微妙な違いを捉え、CoNLL-2003でF1スコア90.9%という最先端性能を実現しつつ、大規模事前学習モデルからの転移学習も可能にしました。複雑さと精度のトレードオフも転換し、ルールベースはリソース制約下や特化分野で依然有用ですが、十分な計算資源とデータがある場合はトランスフォーマーが主流となっています。DistilBERTのような軽量モデルはレイテンシ制約のある実運用にも適しています。
トランスフォーマーベースのモデルは、並列自己注意機構により前世代とは異次元の文脈理解力をエンティティ認識にもたらしました。BERTやその派生モデル(RoBERTa、DistilBERT、ALBERT)は、大規模未ラベルコーパスで双方向事前学習を行い、構文と意味の両面を網羅した普遍的言語表現を獲得します。これを少量のラベル付きデータでエンティティ認識用に微調整するのが主流です。事前学習+ファインチューニングの枠組みは、数千例のラベルでも十分な精度を実現し、ゼロから学習する場合と比べてデータ要件を大幅に削減します。トランスフォーマーのマルチヘッドアテンションは、異なるヘッドが異なるエンティティ関係(構文的境界や意味的関連など)に特化できるため、複雑な文脈やエンティティ間の関係把握に優れています。多言語エンティティ認識も、mBERTやXLM-RoBERTaのような多言語事前学習モデルの登場で劇的に進化し、リソースの乏しい言語やクロスリンガルなエンティティリンキングにも対応可能となりました。新興モデルGLiNER(Generalist Language Model for Instruction-based Named Entity Recognition)は、自然言語プロンプトで任意のエンティティタイプを指示しタスク固有の微調整なしで抽出できるなど、より柔軟で汎用性の高いエンティティ理解システムへと進化しています。
大きく進歩したとはいえ、エンティティ認識システムには依然として現実的な課題が山積しています。最も難しいのは曖昧性や文脈依存性であり、「Apple」が果物なのか企業なのかは周辺文脈の理解が不可欠です。最先端モデルでもノイズや曖昧なテキストでは意味的判別に苦戦します。**未知語エンティティ(OOV)**も大きな課題で、標準データセットで学習したモデルは、稀少な固有名詞や新興分野の語、誤記などに遭遇すると誤分類や認識失敗が起こります。ドメイン適応も難しく、ニュースコーパスで学習したモデル(CoNLL-2003など)は、医学・法律・SNSなど語彙や構文が大きく異なる分野では精度が著しく低下し、都度の再アノテーションや微調整が必要です。境界検出エラー(エンティティの存在は認識するが開始・終了位置が誤る)は、複数語や入れ子構造のエンティティ(例:“New York City"と"New York"の区別や"Apple Inc.の最高経営責任者"のような名称)で特に多発します。多言語対応の複雑さも、言語ごとに大文字化や形態論、エンティティ命名規則が異なるため、英語学習済みモデルを他言語に適用すると失敗しがちです。専門分野でのデータ不足(希少疾病名や新技術、企業内用語など)はアノテーションコストが高く、精度かコストかの選択を迫られます。
エンティティ理解はあらゆる業界で不可欠な技術となり、非構造テキストからの価値抽出を根底から変えています。情報抽出やナレッジグラフ構築では、エンティティ認識によって文書から構造化データベースを自動生成し、検索エンジンやレコメンドシステムが人物・場所・概念間の関係を理解できるようになります。医療機関では、臨床記録から薬剤名・用量・症状・患者属性を特定し、臨床意思決定支援や副作用検出システムの精度向上に寄与します。金融機関は、ニュースや決算報告から銘柄コード・金額・市場イベントを抽出し、アルゴリズム取引やリスク管理をリアルタイムで支援します。リーガルテック企業は、契約書から関係者・日付・義務・責任条項などを自動抽出し、弁護士による文書レビュー工数を大幅削減します。カスタマーサービスやチャットボットは、注文番号・商品名・課題タイプなどの意図や文脈を抽出することで、正確な担当者割当や迅速な解決を実現します。ECプラットフォームでは、顧客レビューや検索クエリから商品名・ブランド・仕様・特徴を抽出し、商品発見やパーソナライズを強化します。コンテンツ推薦システムは、ユーザーが関与するエンティティを理解することで、協調フィルタリングや内容ベース推薦を高度化し、エンゲージメントと収益の向上を実現しています。
実運用に耐えるエンティティ理解システムを構築するには、データ準備・モデル選択・評価に細心の注意が必要です。まず高品質なアノテーションデータを用意し、エンティティタイプの定義を明確にし、アノテーター間一致率で一貫性を担保し、エンティティタイプごとに500〜1000例を目指しましょう(ドメインによってはさらに多く必要です)。モデル選択は要件次第で、ルールベースは解釈容易・低レイテンシが魅力、従来型ML(CRF/SVM)は中程度のデータで良好な性能、トランスフォーマー(BERT/RoBERTa)は最先端精度だがリソースとデータが多く必要です。学習・微調整戦略には、クラス不均衡対策のデータ拡張、過学習防止のクロスバリデーション、学習率やバッチサイズのハイパーパラメータ調整が有効です。評価指標は、適合率(正しく抽出したエンティティ)、再現率(実際のエンティティ中見つけた割合)、F1スコア(両者の調和平均)で、エンティティタイプごとに弱点を把握しましょう。運用時はバッチ or リアルタイム処理、スケーラビリティ、既存データパイプラインとの統合、運用後の性能劣化や誤検出率・ユーザーフィードバックを監視し、再学習トリガーを設計します。
エンティティ理解のツール群は、あらゆる規模や用途に対応するソリューションを提供しています。オープンソースライブラリのspaCyは、89.22%のF1スコアを持つ実運用向けNERパイプラインと優れたドキュメントを備え、MLに明るいチームに最適です。NLTKは教育用途や基本的なNERに、Hugging Face Transformersは最先端の事前学習モデルを少ないコードで微調整できるのが魅力です。クラウド型マネージドサービスはインフラ管理不要で、Google Cloud Natural Language API、AWS Comprehend、IBM Watson NLPなどが多言語・多様なエンティティタイプに対応し、スケーリングも自動・クラウドパイプラインと容易に統合できます。専門フレームワークのFlair(PyTorch上で優れた系列ラベリング対応)、DeepPavlov(多言語・多分野の事前学習モデル提供)は、汎用ライブラリよりカスタマイズ性を重視する研究者や開発者向けです。自前開発と既成ツールの選択は、データ機密性(オンプレミス/クラウド)、要求精度、ドメイン特化性、チームのノウハウに依存します。一般的用途・標準エンティティにはマネージドAPI、ドメイン特化・内部データ活用にはOSSライブラリ、既存ソリューションで要件を満たせない場合のみカスタムモデル構築を選択しましょう。
エンティティ理解の未来は、かつてない柔軟性と性能をもたらす**大規模言語モデル(LLM)**によって切り拓かれます。GPT-4やClaudeのようなモデルは、少数例・ゼロ例でのエンティティ認識を実現し、ほんの数例や自然言語説明だけでカスタムエンティティタイプを抽出できるため、アノテーション負担を劇的に軽減し価値実現までの時間を短縮します。マルチモーダルエンティティ理解も新たなフロンティアで、テキスト・画像・構造化データを組み合わせ、文書や請求書、Webページ上のエンティティを文脈豊かに認識できるため、自動文書処理やビジュアル検索など新たな応用が可能となります。リアルタイム処理の進歩も、モデル蒸留やエッジデバイス展開によって、スマートフォンやIoT機器でも高性能なエンティティ認識が実現し、AR・リアルタイム翻訳・自律システムなど新用途が拡大しています。ドメイン特化ファインチューニングの進化により、医療・法務・金融分野などに特化したモデルが汎用モデルを大幅に上回る精度を発揮し、ドメイン適応事前学習や転移学習でこれらがより身近になっています。今後、エンティティ理解はAIシステムの不可視の基盤層となり、機械が人間並みの意味理解で世界を把握する力を与え、想像を超えた可能性を切り拓いていくでしょう。
ChatGPT、Perplexity、Google AI OverviewsなどのAIシステムが情報探索・利用の主流となる中で、これらがいかにエンティティ(あなたのブランドを含む)を認識・参照しているかを把握することが重要になっています。エンティティ理解こそが、AIが企業・商品・人物・概念の言及を特定・処理する仕組みです。AIによるブランドのエンティティ認識・参照状況を監視することで、次のようなインサイトが得られます。
これこそがAmICitedの監視対象です。複数AIプラットフォーム横断で、あなたのブランドがどのようにエンティティとして認識・参照されているかを追跡します。エンティティ認識の仕組みを理解することで、AIが自社をどう認識し、どのように発信しているかをより深く把握できます。
エンティティ認識(NER)はテキスト内のエンティティ(例:「Apple」を組織として)を識別・分類します。一方、エンティティリンキングは認識されたエンティティを知識ベースや正規のリファレンス(例:「Apple」をApple Inc.のWikipediaページにリンク)に結び付けます。エンティティ認識が第一段階であり、エンティティリンキングが意味的な基盤を追加します。
最先端のトランスフォーマーベースのモデル(BERTなど)は、CoNLL-2003のような標準ベンチマークで90.9%のF1スコアを達成しています。ただし、精度はドメインによって大きく異なります。ニュースで学習したモデルは医療やSNSテキストでは精度が低下します。実際の精度は、ドメイン適応やデータ品質に大きく依存します。
はい。mBERTやXLM-RoBERTaのような多言語モデルは100以上の言語を同時にサポートしています。ただし、言語によって大文字小文字の規則、形態論、学習データの量などが異なるため、性能も言語ごとに変動します。重要な用途では通常、言語特化型モデルの方が多言語モデルより精度が高いです。
ルールベースのシステムはパターンや辞書を手作業で設計します(高速・解釈可能ですが脆弱です)。MLベースのシステムはラベル付きデータから学習します(柔軟で汎用性が高いですが、学習データや特徴設計が必要です)。深層学習型の最新手法は特徴抽出を自動化し、より高精度を実現します。
ルールベースのシステムはパターン定義だけで十分です。従来のMLモデルは300〜500件のラベル付き例が必要です。トランスフォーマーモデルは800件以上が望ましいですが、転移学習によって100〜200件のドメイン固有例でも微調整で十分な成果が得られます。
主な課題は曖昧性(同じ単語の意味の違い)、未知語エンティティ、ドメイン適応(ある分野で学習したモデルが他分野で失敗)、境界検出の誤り、多言語対応の複雑さ、専門分野でのデータ不足などです。これらには慎重なシステム設計やドメイン特化の調整が必要です。
文脈は極めて重要です。“bank”は“river bank”と“savings bank”で意味が異なります。最新のトランスフォーマーは自己注意機構で周囲のトークンから文脈を重視し、言語的・意味的コンテキストに基づいてエンティティを判別します。文脈処理の不十分さがエンティティ認識の主な誤り原因です。
今後は大規模言語モデルによるゼロショットエンティティ認識、テキストと画像を組み合わせたマルチモーダル理解、エッジデバイスでのリアルタイム処理、ドメイン特化型ファインチューニングの進展などが期待されます。エンティティ理解は、機械が人間並みの意味理解で世界を把握するための不可視の基盤となっていくでしょう。
AmICitedは、ChatGPT、Perplexity、Google AI OverviewsのようなAIシステム全体でエンティティの言及を追跡します。AIがリアルタイムであなたのブランドをどのように理解し、参照しているかを把握しましょう。
エンティティ認識は、テキスト中の固有表現を識別・分類するAIの自然言語処理機能です。その仕組みやAIモニタリングでの応用、現代のAIシステムにおける役割について解説します。...

AI検索におけるエンティティの可視性を高める方法を学びましょう。ナレッジグラフ最適化、スキーママークアップ、エンティティSEO戦略を習得し、ChatGPT、Perplexity、Google AI Overviewsでのブランドの存在感を高めます。...

AIシステムがテキスト内のエンティティ間の関係をどのように特定・抽出・理解するかを学びましょう。エンティティ関係抽出技術、NLP手法、実際の応用例を紹介します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.