AIボットによるウェブサイトのクロール許可方法:robots.txt&llms.txt完全ガイド
GPTBot、PerplexityBot、ClaudeBotなどのAIボットによるサイトクロールの許可方法を解説します。robots.txt・llms.txtの設定やAI向け最適化の方法もわかります。...
2 分で読める

AIトレーニングクローラーと検索クローラーの重要な違いを発見しましょう。これらがあなたのコンテンツの可視性、最適化戦略、AIによる引用にどのように影響するかを学びます。
GooglebotやBingbotのような検索エンジンクローラーは、従来の検索エンジン運用の基盤です。これらの自動ボットはウェブ全体を体系的に巡回し、コンテンツを発見・インデックス化して検索結果ページ(SERPs)に何を表示するか決定します。Googleが運用するGooglebotが最も有名かつ活動的な検索クローラーであり、続いてMicrosoftのBingbot、YandexのYandexBotが続きます。これらのクローラーは高度な機能を持ち、JavaScriptを実行して動的コンテンツを表示でき、複雑なウェブサイト構造も理解します。サイトの権威性やコンテンツの新しさ、更新履歴などに応じて頻繁に訪問し、権威性の高いサイトほどクロール頻度が高まります。検索クローラーの主な目的はランキングのためのインデックス化であり、関連性・品質・ユーザー体験などのシグナルに基づきページを評価します。
| クローラー種別 | 主な目的 | JavaScript対応 | クロール頻度 | ゴール |
|---|---|---|---|---|
| Googlebot | 検索順位のためのインデックス化 | あり(制限あり) | 権威性に応じて頻繁 | ランキング・可視性 |
| Bingbot | 検索順位のためのインデックス化 | あり(制限あり) | コンテンツ更新に応じて定期的 | ランキング・可視性 |
| YandexBot | 検索順位のためのインデックス化 | あり(制限あり) | サイトシグナルに応じて定期的 | ランキング・可視性 |
AIトレーニングクローラーは、検索インデックス用ではなく、大規模言語モデル(LLM)の学習用データ収集を目的とした根本的に異なるカテゴリのウェブボットです。OpenAIが運用するGPTBotが最も著名なAIトレーニングクローラーで、ほかにAnthropicのClaudeBot、HuaweiのPetalBot、Common CrawlのCCBotなどがあります。検索クローラーがコンテンツの順位付けを目的とするのに対し、AIトレーニングクローラーはAIモデルの知識ベースと応答生成能力を向上させるために、高品質かつ文脈豊かな情報の収集に注力します。これらのクローラーは検索クローラーよりも訪問頻度が少なく、数週間から数ヶ月に一度しか訪れないことが多く、量よりも質を重視します。この違いは重要で、Googlebotによって検索用に徹底的にインデックスされていても、GPTBotによるAIモデル学習では一部しかクロールされない場合があります。
| クローラー種別 | 主な目的 | JavaScript対応 | クロール頻度 | ゴール |
|---|---|---|---|---|
| GPTBot | LLM学習用データ収集 | なし | まれ・選択的 | 学習データ品質 |
| ClaudeBot | LLM学習用データ収集 | なし | まれ・選択的 | 学習データ品質 |
| PetalBot | LLM学習用データ収集 | なし | まれ・選択的 | 学習データ品質 |
| CCBot | Common Crawl用データ収集 | なし | まれ・選択的 | 学習データ品質 |
検索クローラーとAIトレーニングクローラーの技術的な違いは、コンテンツの可視性に大きな影響をもたらします。最も重要なのはJavaScriptの実行です。Googlebotのような検索クローラーは(制限はあるものの)JavaScriptを実行できるため、動的にレンダリングされたコンテンツも確認できます。一方、AIトレーニングクローラーはJavaScriptを一切実行せず、初回読み込み時の生HTMLのみを解析します。このため、クライアントサイドスクリプトで動的に読み込まれるコンテンツはAIクローラーから完全に見えません。また、検索クローラーはクロールバジェットを意識し、サイト構造や内部リンクに基づいてページを優先的にクロールしますが、AIクローラーはより選択的かつ品質重視のクロールパターンを取ります。検索クローラーはrobots.txtを厳格に遵守しますが、一部のAIクローラーはその対応が不透明な場合もあります。クロール頻度も大きく異なり、検索クローラーは活動的なサイトを週に何度も、場合によっては毎日訪れますが、AIトレーニングクローラーは数週間や数ヶ月に一度しか訪れないこともあります。さらに、検索クローラーはランキングシグナルやユーザー体験指標を重視しますが、AIクローラーはクリーンで構造化されたテキスト収集に特化しています。
| 特徴 | 検索クローラー | AIトレーニングクローラー |
|---|---|---|
| JavaScript実行 | あり(制限あり) | なし |
| クロール頻度 | 高い(週に複数回) | 低い(数週間に1回程度) |
| コンテンツ解析 | ページ全体レンダリング | 生HTMLのみ |
| robots.txt順守 | 厳格 | ばらつきあり |
| クロールバジェット重視 | 権威性優先 | 品質選択型 |
| 動的コンテンツ対応 | レンダリング・インデックス可能 | 完全に見逃す |
| 主な目的 | ランキング・検索可視性 | 学習データ収集 |
| タイムアウト耐性 | 長め(複雑なレンダリング可) | 短い(1〜5秒) |
AIクローラーがJavaScriptを実行できないことは、多くの現代ウェブサイトにとって重要な可視性ギャップを生み出します。JavaScriptで動的にコンテンツ(商品説明、レビュー、価格情報、画像など)を読み込んでいる場合、その内容はAIクローラーには見えません。これは特にReact、Vue、Angularなどで構築されたSPA(シングルページアプリケーション)で顕著です。例えば、ECサイトがJavaScriptで商品在庫や価格を表示している場合、GPTBotからは空白のページやHTMLの骨組みしか見えません。同様に、画像の遅延読み込みや無限スクロールを利用している場合、それらの要素もAIクローラーには完全に見逃されます。ビジネスへの影響は大きく、商品情報やお客様の声、重要なコンテンツがJavaScriptの裏側に隠れていると、ChatGPTやPerplexityのようなAIシステムはその情報を回答生成に使えません。結果、Googleでは高順位でもAIによる回答には全く登場せず、AIを情報探索に使うユーザー層から見えなくなってしまうのです。
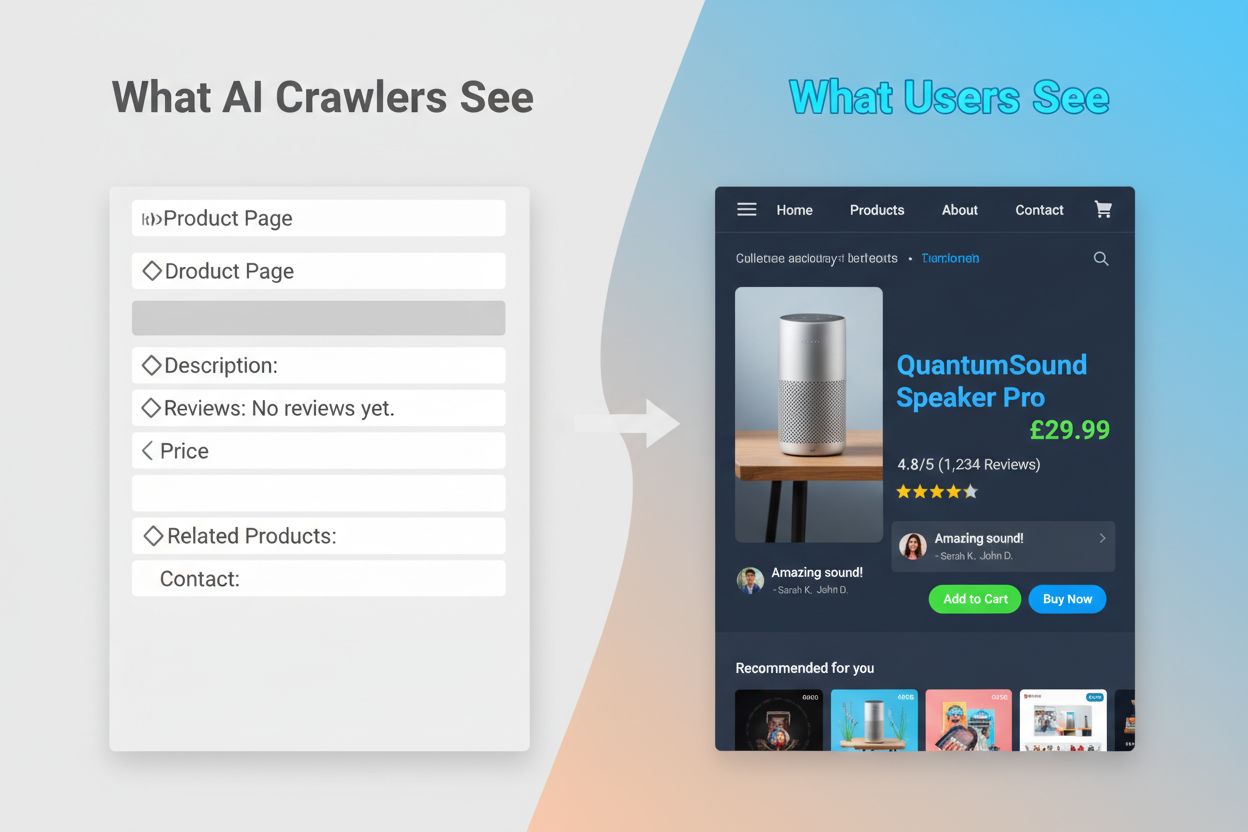
これら技術的な違いがもたらす実務上の影響は大きく、ウェブサイト運営者にしばしば誤解されています。あなたのサイトがGoogleで素晴らしい順位を獲得していても、同時にChatGPTやPerplexityなどAIシステムからはほとんど見えない可能性があります。つまり、従来のSEO成功がAIでの可視性を保証しないというパラドックスです。ユーザーがChatGPTに業界や製品について質問した際、AIはあなたではなく競合他社を引用するかもしれません。なぜなら、競合のコンテンツの方がAIクローラーにとってアクセス可能だったからです。また、学習データと検索引用の関係も複雑です。AIモデルの学習に使われたコンテンツは、そのモデルの検索結果で優先的に取り上げられる場合があり、AIトレーニングクローラーをブロックするとAIによる可視性低下につながる可能性もあります。出版社やコンテンツ制作者にとって、AIクローラーを許可・拒否する戦略的判断は将来の流入に直結します。GPTBotをブロックしてコンテンツ流用を防げば、ChatGPTでの露出も同時に減るかもしれません。逆に、AIクローラーにアクセスを許可しても引用や流入が保証されるわけではなく、最適解が存在しない本質的なジレンマとなっています。
どのクローラーがどの頻度で自サイトにアクセスしているかを理解することは、コンテンツ戦略の最適化に不可欠です。ログファイル解析が主な手法で、サーバーログを分割・解析して、どのボットがいつどのページにアクセスしたかを特定できます。サーバーログのUser-Agent文字列を調べることで、Googlebot、GPTBot、OAI-SearchBotなど各種クローラーの行動パターンが分かります。注視すべき指標は、クロール頻度(各クローラーの訪問頻度)、クロール深度(サイト構造の何階層までクロールされているか)、クロールバジェット(一定期間内にクロールされた総ページ数)です。Google Search ConsoleやBing Webmaster Toolsは検索クローラーの活動を可視化しますし、AmICited.comのような専用サービスならChatGPT、Perplexity、Google AI Overviewsなど複数AIプラットフォームでのAIクローラー行動を包括的に把握できます。AmICited.comは特に、AIシステムがあなたのブランドやコンテンツをどのように参照しているか、どのAIプラットフォームでどの頻度で引用されたかを追跡します。こうしたパターンを理解することで、技術的な問題を早期発見し、クロールバジェット配分の最適化やクローラーアクセス・コンテンツ最適化の意思決定に役立てられます。
従来の検索クローラーへの最適化は、コンテンツが発見・インデックス化されやすいよう技術的SEOの基本を徹底することが重要です。以下の戦略は検索可視性を高めるうえで不可欠です。
Googleなどの検索エンジンは、近年クロール効率性をより重視しており、Googlebotの今後のクロール量は減少傾向とされています。つまり、サイト構造をできるだけシンプルにし、明確な階層と内部リンクでクローラーが重要ページへ直行できる設計がますます重要です。
AIトレーニングクローラーへの最適化は、ランキングシグナルよりもコンテンツの品質・明瞭性・アクセシビリティに重点を置く必要があります。AIクローラーは構造化され文脈豊かなコンテンツを優先するため、包括性と読みやすさを重視した最適化が求められます。JavaScript依存の重要情報は避け、商品情報、価格、レビューなどは生HTMLに記載しましょう。包括的かつ詳細なコンテンツ作成でAIモデルが学習しやすい文脈を提供します。見出し・箇条書き・番号リストで明確なフォーマットを作り、テキストを解析しやすくします。意味が明瞭な表現を心掛け、過度な専門用語を避けてAIモデルが理解しやすい言葉を使いましょう。**見出し階層(H1, H2, H3)**を正しく設定し、コンテンツ構造や関連性をAIクローラーが理解できるようにします。適切なメタデータやスキーママークアップでコンテンツの文脈を補足します。ページの読み込み速度も高速化し、AIクローラーの厳しいタイムアウト(通常1〜5秒)に耐えられるようにしましょう。
検索最適化との最大の違いは、AIクローラーはランキング指標や被リンク、キーワード密度を気にしない点です。むしろ、明快で整理された情報量の多いコンテンツを重視します。Googleで上位表示されないページでも、そのトピックについて包括的で構造化された情報であればAIモデルには非常に価値がある場合もあります。
ウェブクローリングの世界は急速に進化しており、AIクローラーの重要性は今後ますます高まります。ChatGPT、Perplexity、Google AI OverviewsといったAI搭載の検索ツールが普及するにつれ、これらAIシステムに発見され引用される能力は従来の検索順位と同等に重要となるでしょう。トレーニングクローラーと検索クローラーの違いは今後さらに細分化される可能性があり、OpenAIのGPTBotとOAI-SearchBotのように、データ収集と検索取得を明確に分離する動きが進むかもしれません。ウェブサイト運営者は、従来型SEOとAI可視性を両立させる戦略を構築する必要があり、これは競合するものではなく相補的な目標であると理解することが重要です。専用モニタリングツールの進化により、従来型とAI型両方のクローラー活動を容易に追跡できるようになり、データに基づいたクローラーアクセスやコンテンツ最適化の意思決定が可能になります。今この段階で検索・AI両方のクローラー最適化に取り組む先行者は、今後の多様なチャネルでの発見性を高め、競争優位を得ることができるでしょう。今後のコンテンツ可視性は、あなたのコンテンツを発見・利用する全てのクローラーを理解し最適化することにかかっています。
Googlebotのような検索クローラーは検索順位のためにコンテンツをインデックスし、JavaScriptを実行して動的コンテンツも確認できます。一方、GPTBotのようなAIトレーニングクローラーはLLMの学習用データを収集しますが、通常JavaScriptを実行できないため、動的に読み込まれるコンテンツを見逃します。この根本的な違いにより、あなたのウェブサイトはGoogleでは高く評価されても、ChatGPTからはほとんど見えなくなる可能性があります。
はい、robots.txtを利用してGPTBotなどの特定のAIクローラーのみをブロックし、検索クローラーを許可することが可能です。ただし、AIによる回答や要約での可視性が低下する可能性があります。コンテンツ保護を優先するか、AI経由の流入を優先するかによって戦略的な判断が必要です。
GPTBotのようなAIクローラーは、初回ページ読み込み時の生HTMLのみを解析し、JavaScriptを実行しません。スクリプトによって動的に読み込まれるコンテンツ(商品情報、レビュー、画像など)は完全に見えません。これはクライアントサイドレンダリングに依存した現代ウェブサイトにとって重大な制限となります。
AIトレーニングクローラーは、検索クローラーよりも訪問頻度が低く、間隔も長い傾向にあります。権威性の高いコンテンツを優先し、数週間から数ヶ月に一度だけクロールする場合もあります。このクロール頻度の低さは、量よりも質を重視していることを反映しています。
商品情報、カスタマーレビュー、遅延読み込みの画像、インタラクティブ要素(タブ、カルーセル、モーダル)、価格情報、JavaScriptで隠されたコンテンツが最も影響を受けやすいです。ECサイトやSPA型サイトでは、これが重要コンテンツの大部分を占める場合もあります。
重要なコンテンツは生HTMLで提供し、サイトの速度を向上させ、見出し階層を意識した明確な構造・フォーマットにし、スキーママークアップを実装し、JavaScript依存の重要コンテンツを避けましょう。両方のクローラーにアクセス可能なコンテンツ作りが目標です。
ログ解析ツール、Google Search Console、Bing Webmaster Tools、AmICited.comのような専門モニタリングサービスがクローラーの挙動を追跡できます。特にAmICited.comは、ChatGPT、Perplexity、Google AI OverviewsでAIシステムがあなたのブランドをどのように参照しているかを監視します。
可能性があります。トレーニングクローラーをブロックすることでコンテンツは保護できますが、AIによる検索結果や要約での可視性が低下する可能性があります。また、ブロック前にクロールされたコンテンツは既に学習済みモデルに残るため、慎重な判断が求められます。
ChatGPT、Perplexity、Google AI OverviewsでAIシステムがあなたのブランドをどのように参照しているかを追跡。AIでの可視性をリアルタイムで把握し、コンテンツ戦略を最適化しましょう。
GPTBot、PerplexityBot、ClaudeBotなどのAIボットによるサイトクロールの許可方法を解説します。robots.txt・llms.txtの設定やAI向け最適化の方法もわかります。...
どのAIクローラーをrobots.txtで許可またはブロックすべきかを解説。GPTBot、ClaudeBot、PerplexityBotなど25種類以上のAIクローラーと設定例を網羅した総合ガイド。...
GPTBot、PerplexityBot、ClaudeBotなどのAIクローラーをサーバーログで特定・監視する方法を解説。ユーザーエージェント文字列やIP検証手法、AIトラフィック追跡のベストプラクティスもご紹介。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.