
AI向けrobots.txt:どのボットがあなたのコンテンツにアクセスできるかをコントロールする方法
robots.txtを使って、どのAIボットがあなたのコンテンツにアクセスできるかをコントロールする方法を学びましょう。GPTBot、ClaudeBot、その他のAIクローラーをブロックするための実践的な例と設定戦略を網羅した完全ガイドです。...
2 分で読める
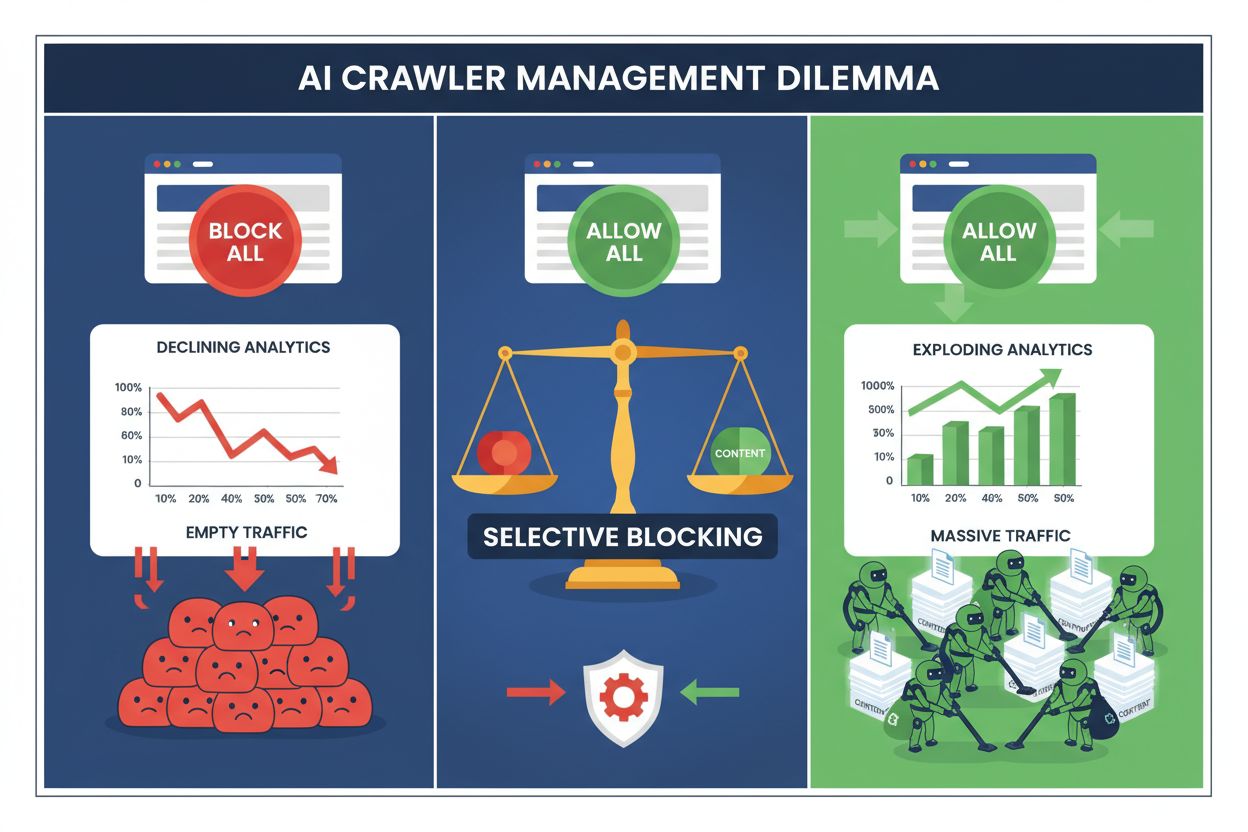
現代のパブリッシャーは、すべてのAIクローラーをブロックして貴重な検索エンジントラフィックを失うか、すべて許可してコンテンツが無償で学習用データセットに利用されるのを見過ごすか、という難しい選択を迫られています。生成AIの台頭により、robots.txtのルールが収益を生む検索エンジンと価値を吸い上げるトレーニングクローラーの両方に無差別に適用される、分岐したクローラーエコシステムが生まれました。このパラドックスにより、先進的なパブリッシャーは、ビジネスメトリクスへの実際の影響に基づいてAIボットの種類を区別する、選択的クローラー制御戦略を開発するようになっています。
AIクローラーの世界は、目的もビジネスへの影響も大きく異なる2つのカテゴリに分かれます。OpenAI・Anthropic・Googleなどが運営するトレーニングクローラーは、大規模言語モデルの構築・改良のために膨大なテキストデータを取り込みます。一方、検索クローラーはコンテンツを検索・発見のためにインデックス化します。トレーニングボットはAI関連ボット活動の約80%を占めますが、パブリッシャーに直接的な収益は一切もたらしません。対してGooglebotやBingbotのような検索クローラーは、年間数百万規模の訪問と広告インプレッションを生み出します。この違いは重要です。なぜなら、1台のトレーニングクローラーが数千人分のユーザー帯域を消費する一方、検索クローラーは効率化されていて通常レート制限も尊重するからです。
| ボット名 | 運営者 | 主な目的 | トラフィック潜在力 |
|---|---|---|---|
| GPTBot | OpenAI | モデルトレーニング | なし(データ抽出) |
| Claude Web Crawler | Anthropic | モデルトレーニング | なし(データ抽出) |
| Googlebot | 検索インデックス | 2億4,380万件の訪問(2025年4月) | |
| Bingbot | Microsoft | 検索インデックス | 4,520万件の訪問(2025年4月) |
| Perplexity Bot | Perplexity AI | 検索+トレーニング | 1,210万件の訪問(2025年4月) |
データは明白です。ChatGPTのクローラー単体で2025年4月に2億4,380万件の訪問がパブリッシャーにもたらされましたが、これらの訪問はクリックも広告表示も収益も生みませんでした。一方、Googlebotのトラフィックは実際のユーザーエンゲージメントや収益化機会へと転換されます。この違いを理解することが、コンテンツを守りつつ検索可視性を維持する選択的ブロック戦略の第一歩となります。
すべてのAIクローラーを一律でブロックすることは、ほとんどのパブリッシャーにとって経済的な自滅行為です。トレーニングクローラーは無償で価値を吸い上げますが、検索クローラーは断片化するデジタル環境において最も安定したトラフィック源の一つです。選択的ブロックの収益的根拠は以下の通りです:
選択的ブロックを実践したパブリッシャーは、検索トラフィックを維持・向上させつつ、無許可のコンテンツ抽出を最大85%削減したと報告しています。すべてのAIクローラーが同等でないことを認識し、ビジネス利益に即した柔軟なポリシーを採ることが、焼け野原的な全面ブロックより遥かに優れた戦略となります。
robots.txtファイルは、クローラー権限を伝達する主要なメカニズムであり、正しく設定すれば異なるボットタイプを区別するのに驚くほど有効です。この単純なテキストファイルをウェブサイトのルートディレクトリに設置し、user-agentディレクティブで各クローラーにアクセス権限を指定します。選択的AIクローラー制御では、検索エンジンは許可し、トレーニングクローラーのみをピンポイントでブロックできます。
以下は、トレーニングクローラーをブロックし、検索エンジンを許可する実例です:
# OpenAIのGPTBotをブロック
User-agent: GPTBot
Disallow: /
# AnthropicのClaudeクローラーをブロック
User-agent: Claude-Web
Disallow: /
# その他のトレーニングクローラーをブロック
User-agent: CCBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
# 検索エンジンを許可
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: *
Disallow: /admin/
Disallow: /private/
この方法で、良識あるクローラーには明確な指示を出しつつ、検索結果での発見性も維持できます。ただし、robots.txtはあくまで自主的な標準であり、クローラー運営側が指示を守ることが前提です。遵守に不安がある場合は、さらなる強制レイヤーが必要です。
robots.txtだけでは、約13%のAIクローラーがディレクティブを完全に無視するため、遵守を保証できません。Webサーバーやアプリケーション層でサーバーレベルのブロックを行えば、クローラーの挙動に関係なく不正アクセスを技術的に遮断できます。この方法では、HTTPレベルでリクエストを遮断するため、帯域やリソース消費を最小限に抑えます。
Nginxによるサーバーレベルブロックの実装例は以下の通りです:
# Nginxのサーバーブロック内
location / {
# サーバーレベルでトレーニングクローラーをブロック
if ($http_user_agent ~* (GPTBot|Claude-Web|CCBot|anthropic-ai|Omgili)) {
return 403;
}
# ユーザーエージェントを偽装するクローラーにはIPレンジでブロック
if ($remote_addr ~* "^(192\.0\.2\.|198\.51\.100\.)") {
return 403;
}
# 通常のリクエスト処理を継続
proxy_pass http://backend;
}
この設定では、ブロック対象のクローラーに403 Forbiddenを返し、極めて少ないサーバーリソースでアクセス拒否を明確に伝えます。robots.txtと組み合わせることで、守るべきクローラー、守らないクローラーの両方に対応した二重防御が構築できます。サーバーレベルルールを適切に実装すれば、13%のバイパス率もほぼゼロに抑えられます。
CDN(コンテンツ配信ネットワーク)やWAF(ウェブアプリケーションファイアウォール)は、オリジンサーバーにリクエストが届く前に制御を行う追加レイヤーです。Cloudflare、Akamai、AWS WAFなどのサービスでは、特定のユーザーエージェントやIPレンジをエッジでブロックするルールを設定でき、不正・不要なクローラーによるインフラ消費を防げます。主要なCDNサービスは、既知のトレーニングクローラーのIPやユーザーエージェントリストを自動更新し、手動設定不要でブロックします。
CDNレベルの制御には、オリジンサーバー負荷の軽減、地域別ブロック、リアルタイム分析などの利点があります。多くのCDNプロバイダーは、AIトレーニングデータの無断抽出への懸念の高まりを受け、AI専用のブロックルールを標準機能として提供しています。Cloudflare利用者であれば、セキュリティ設定の「AIクローラーのブロック」オプションを有効にするだけで、主要なトレーニングクローラーをワンクリックで遮断しつつ、検索エンジンは維持できます。
効果的な選択的ブロックには、クローラーのビジネスインパクトや信頼性に基づく体系的な分類が不可欠です。すべてのAIクローラーを一律に扱うのではなく、以下の3段階フレームワークを導入し、それぞれの価値とリスクに応じて対応を差別化しましょう。この枠組みで、コンテンツ保護とビジネス機会のバランスを取った戦略的判断が可能です。
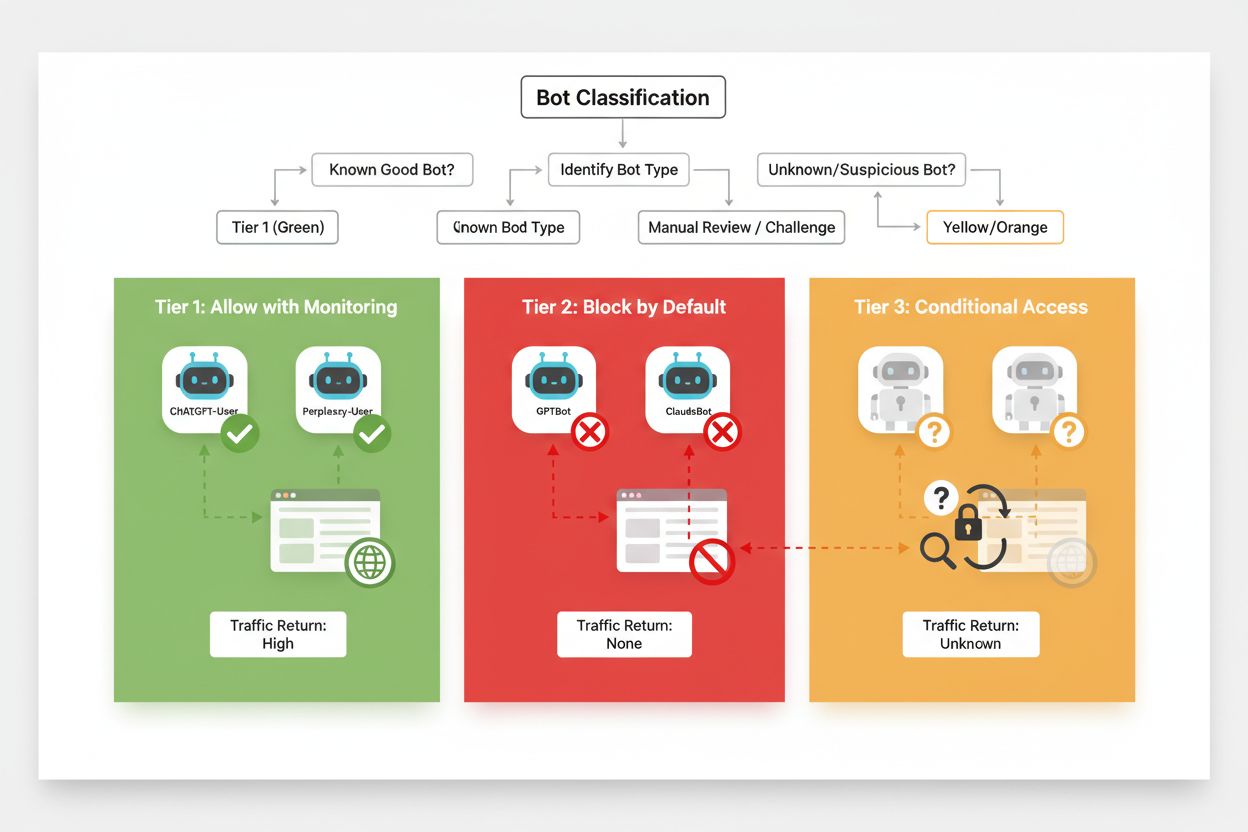
| ティア | 分類 | 例 | アクション |
|---|---|---|---|
| ティア1:収益源 | 検索エンジンや高トラフィックのリファラ | Googlebot, Bingbot, Perplexity Bot | 全面許可・クロール最適化 |
| ティア2:中立・未検証 | 意図が不明確な新興クローラー | 小規模AIスタートアップ、リサーチボット | 厳重監視・レート制限付き許可 |
| ティア3:価値抽出型 | 直接的な利益のないトレーニングクローラー | GPTBot, Claude-Web, CCBot | 完全ブロック・多層防御で強制 |
このフレームワークの運用には、新規クローラーやそのビジネスモデルの継続的な調査が必要です。パブリッシャーはアクセスログを定期的に監査し、新しいボットの出現や運営者の利用規約・収益分配方針を調べ、分類を随時調整しましょう。たとえばティア3のクローラーでも収益分配を開始すればティア2へ昇格、逆に信頼していたクローラーがレート制限違反やrobots.txt違反を始めたらティア3に降格、など柔軟な運用が求められます。
選択的ブロックは「設定して終わり」ではなく、クローラーの状況変化に応じた持続的な監視と調整が必要です。どのクローラーがどれだけコンテンツへアクセスし、帯域を消費し、設定した制限を守っているかをログ分析で把握し、許可・ブロック・レート制限の判断材料としましょう。
アクセスログ分析によるクローラー行動パターンの把握例:
# サイトにアクセスするすべてのAIクローラーを特定
grep -i "bot\|crawler" /var/log/nginx/access.log | \
awk '{print $12}' | sort | uniq -c | sort -rn | head -20
# 特定クローラーによる帯域消費量を算出
grep "GPTBot" /var/log/nginx/access.log | \
awk '{sum+=$10} END {print "GPTBot帯域: " sum/1024/1024 " MB"}'
# ブロックされたクローラーへの403レスポンスを監視
grep " 403 " /var/log/nginx/access.log | grep -i "bot" | wc -l
こうしたデータ分析を毎週~毎月実施することで、ブロック戦略が想定通り機能しているか、新たなクローラーの出現、以前ブロックしたボットの行動変化などを検知できます。この情報は分類フレームワークの調整にフィードバックされ、ビジネス目標と技術現実に即したポリシー維持につながります。
選択的クローラーブロック導入時によくある失敗例と、その回避策を理解することで、より効果的な方針策定が可能になります。
無差別ブロック:最も多い失敗は、検索エンジンまで巻き込んでトレーニングクローラーと一緒に一括ブロックし、検索可視性を失うことです。
robots.txtだけに依存:robots.txtのみで十分と考え、13%の無視ボットへの対応を怠ると、コンテンツ抽出のリスクが残ります。
監視・調整の怠り:静的なブロックポリシーを放置し、新しいクローラーやビジネスモデルの変化、改善したクローラーを見逃してしまうこと。
ユーザーエージェントのみでブロック:高度なクローラーはユーザーエージェントを偽装・頻繁に切り替えるため、IPベースのルールやレート制限がなければ効果が薄くなります。
レート制限を無視:許可されたクローラーでも、レート制限なしでは帯域を過剰消費し、ユーザー体験やインフラリソースに悪影響を及ぼします。
今後、パブリッシャーとAIクローラーの関係は、単純なブロックから、より高度な交渉や収益分配モデルに移行していくでしょう。しかし、業界標準が確立するまでは、選択的クローラー制御がコンテンツ保護と検索可視性維持の最も現実的なアプローチです。ブロック戦略は、クローラー状況の変化に応じて進化する「動的なポリシー」と捉え、ビジネスインパクトと信頼性に基づき許可クローラーを定期的に見直してください。
最も成功しているパブリッシャーは、robots.txt、サーバーレベルの強制、CDN制御、継続的な監視という多層防御を組み合わせ、包括的な戦略を実践しています。このアプローチで、遵守するクローラー・しないクローラーの両方からコンテンツを守りつつ、収益やユーザーエンゲージメントの源である検索エンジントラフィックを確保できます。AI企業がパブリッシャーコンテンツの価値をより認識し、報酬やライセンス契約を開始する時代になれば、今構築しているフレームワークは新たなビジネスモデルにも柔軟に対応し、デジタル資産の主導権を維持できるでしょう。
GPTBotやClaudeBotのようなトレーニングクローラーは、AIモデルの構築のためにデータを収集しますが、あなたのサイトにトラフィックを返しません。OAI-SearchBotやPerplexityBotのような検索クローラーは、AI検索エンジン用にコンテンツをインデックスし、あなたのサイトに多くのリファラルトラフィックを送ることができます。この違いを理解することが、効果的な選択的ブロック戦略を実装する上で重要です。
はい、これが選択的クローラー制御の中核戦略です。robots.txtでトレーニングボットを拒否し、検索ボットは許可できます。その上で、robots.txtを無視するボットにはサーバーレベルの制御を加えましょう。この方法は、無許可のトレーニングからコンテンツを守りつつ、AI検索結果での可視性を維持します。
主要なAI企業の多くはrobots.txtを守ると主張していますが、遵守は任意です。調査によると、AIボットの約13%はrobots.txtの指示を完全に無視しています。だからこそ、robots.txtに加えてサーバーレベルでの強制が、コンテンツを守りたいパブリッシャーには不可欠です。
非常に多く、増加傾向にあります。ChatGPTは2025年4月、250のニュース・メディアサイトに2億4,380万件の訪問を送り、1月から98%増加しました。こうしたクローラーをブロックすると、新たなトラフィック源を失います。多くのパブリッシャーにとって、AI検索経由のトラフィックは今や全リファラルトラフィックの5~15%を占めています。
サーバーログを定期的にgrepコマンドで解析し、ボットのユーザーエージェント、クロール頻度、robots.txtルールの遵守状況を追跡しましょう。少なくとも月1回はログを見直し、新しいボットや異常な行動パターン、ブロックしたはずのボットが本当に排除できているか確認してください。このデータがクローラーポリシーの意思決定に役立ちます。
無許可トレーニングからコンテンツは守られますが、AI検索結果での可視性を失い、新たなトラフィック源を逃し、AIによるブランドの言及も減る可能性があります。全面ブロックしたパブリッシャーは、検索での可視性が40~60%減少し、AIプラットフォーム経由のブランド認知の機会を逃すことが多いです。
少なくとも月1回は更新しましょう。新しいボットが常に登場し、既存のボットも行動を進化させています。AIクローラーの状況は急速に変化しているため、定期的な見直しでビジネス目標や技術的現実とポリシーを一致させましょう。
クロールされたページ数と、そこから実際にサイトに送られた訪問者の数の比率です。Anthropicは1人の訪問者につき38,000ページをクロールし、OpenAIは1,091:1、Perplexityは194:1です。比率が低いほど、クローラーを許可する価値が高いことを示します。この指標は、実際のビジネス効果に基づきアクセスを許可するクローラー選定の判断材料となります。
robots.txtを使って、どのAIボットがあなたのコンテンツにアクセスできるかをコントロールする方法を学びましょう。GPTBot、ClaudeBot、その他のAIクローラーをブロックするための実践的な例と設定戦略を網羅した完全ガイドです。...

AIクローラーおよびボットの完全リファレンスガイド。GPTBot、ClaudeBot、Google-Extended、20種類以上のAIクローラーをユーザーエージェント・クロールレート・ブロック戦略とともに識別可能。...

GPTBotやClaudeBotなどのAIクローラーをrobots.txt、サーバーレベルブロック、高度な保護方法でブロックまたは許可する方法を学びます。事例付きの完全な技術ガイド。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.