
引用品質スコア
引用品質スコアとは何か、そしてAIによる引用の顕著性、文脈、感情をどのように測定するかを学びましょう。引用品質の評価方法、スコアリングフレームワークの実装、およびAI生成回答でブランドの可視性を最適化する方法を探ります。...
1 分で読める
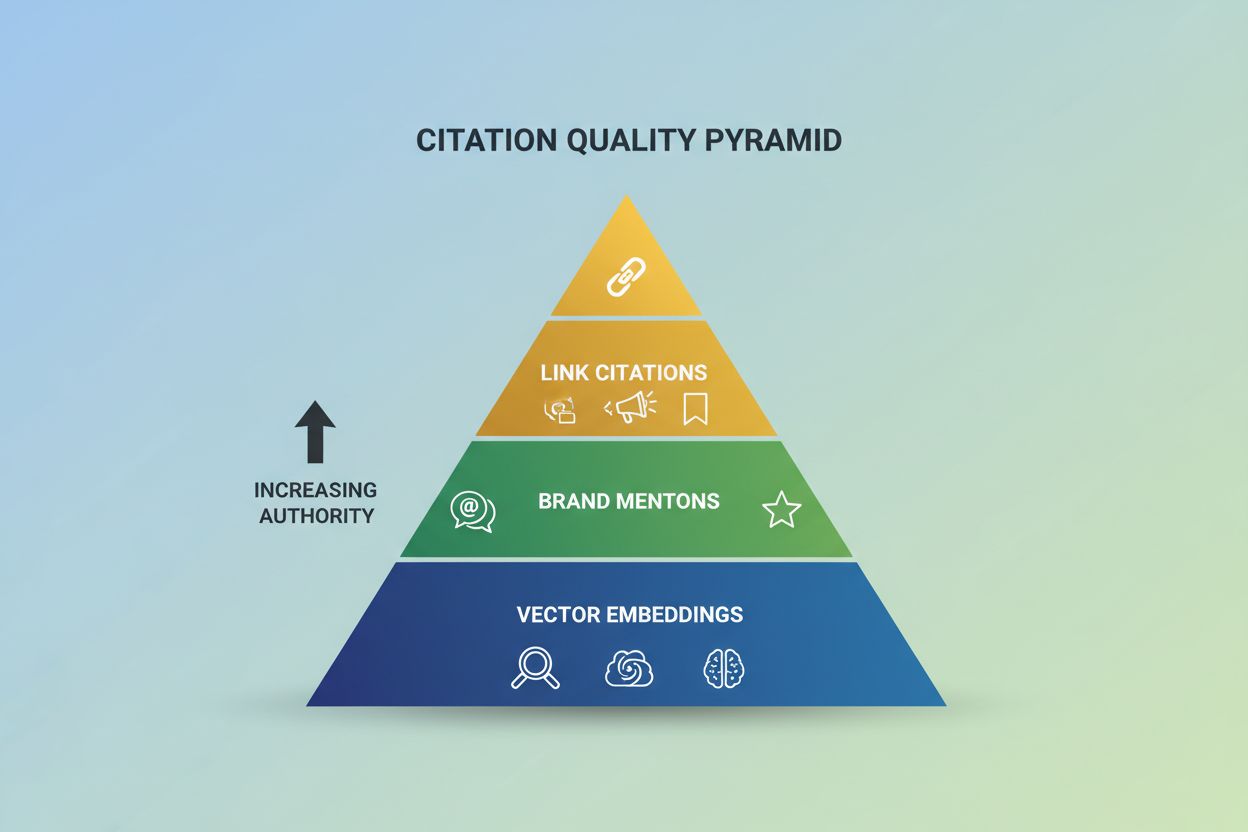
なぜ引用の質が量よりも重要なのかを学びましょう。AIでの言及、リンク、埋め込みを最大限にビジネス成果に結びつける測定と最適化方法を解説します。
多くのブランドは引用量—AIの応答で自社ブランドが何回登場するか—に固執しがちですが、すべての引用が同じ価値を持つわけではないという重要な事実を見落としています。「さらに情報を見る」セクションに埋もれた引用はクリック率が2%未満ですが、同じ引用がAIの回答文で目立つ位置に表示されると15~25%ものCTRを生みます。これは10倍もの差ですが、多くの監視ツールはまったく無視しています。引用数だけを追跡し、質を測らないままでは、AIプラットフォームから実際にトラフィックやコンバージョンを生み出している要素が見えません。
AIの引用の質は、回答生成のパイプライン内で連携する3つの異なる次元で機能しており、それぞれを理解することが戦略的最適化に不可欠です。ベクトル埋め込みは、あなたのコンテンツがそもそも候補情報源として取得されるかどうかを決め、ブランド言及はAIがブランド名を参照することで権威性と認知を高め、リンク引用はクリック可能なURLでサイトにトラフィックを直接もたらします。リサーチによると、検索品質(埋め込み)が引用のばらつきの60~70%を占め、権威シグナルや帰属マークアップが残り30~40%を左右します—つまり、そもそもコンテンツが取得されなければ、どれだけE-E-A-Tを最適化しても引用されません。
| 引用次元 | 定義 | ビジネスへの影響 |
|---|---|---|
| ベクトル埋め込み | 検索システム内の意味的表現 | コンテンツが考慮されるかを決定(ばらつきの60~70%) |
| ブランド言及 | リンクのない参照 | 権威性・ブランド認知を構築 |
| リンク引用 | URL付きの出典 | トラフィックとコンバージョンを生み出す |
それぞれ異なる測定アプローチと最適化戦略が必要ですが、多くの組織はリンク引用だけに注目し、埋め込みの基盤や言及のブランド構築力を見過ごしがちです。

データは明確です:権威ある文脈での質の高い10件の引用は、質の低い100件の言及よりもビジネス成果を生み出します。量重視から質重視の戦略に転換した組織は、8.3倍の有望リード、340%高いコンバージョン率、247%のAIドリブントラフィック増加という結果が出ています。これは単なる引用数カウントでは把握できません。掲載場所の違いだけでも大きな成果差が生まれ、AI Overviewsの目立つ引用は15~25%のCTRを維持し、展開式セクションに埋もれた引用は2%未満です。この10倍もの差は、引用の質を平均45/100から65/100に上げる方が、引用量を50%増やすより大きな価値をもたらすことを意味しますが、多くのブランドはいまだに売上と関連しない量の指標を追い続けています。
言及の質を体系的に測定するには、単なるカウントをはるかに超えた構造化されたテストとスコア付けの手法が必要です。まず自社分野に関連する高意図クエリを50~100個特定しましょう—情報クエリ(「Xとは」)、比較クエリ(「X vs Y」)、ハウツークエリ(「Xのやり方」)、商用意図クエリ(「Yに最適なX」)などを含めます。主要なAIプラットフォームで毎月それぞれを検索し、ブランドが表示されるか、言及の文脈、感情(ポジティブ、中立、ネガティブ)、ポジション(主要情報源、補助参照、代替案、通りすがりの言及)を記録。ビジネス価値を反映した加重スコアリングを作成します:
70点以上の言及は高品質—ブランドポジション強化につながる権威ある参照です。単なる言及数でなく、平均スコアの推移を追いましょう。平均45から65への向上は、言及数が変わらなくても意味のある前進です。
多くの組織にとってリンク引用はブランド可視性と直接トラフィック獲得を両立する「金字塔」ですが、掲載場所、文脈、アンカーテキスト、ユーザー意図との整合性によって質は大きく異なります。可視性とトラフィックポテンシャルを反映したスコアリングを設計しましょう:掲載目立ち度(ファーストビューの特集引用=35点、本回答内インライン=25点、補助情報リスト=15点、展開式「詳細を見る」=8点)、文脈適合度(クエリへの直接回答=25点、関連する補足=18点、やや関連=10点、関連薄=5点)、アンカーテキストの質(説明的で意図に合致=20点、ブランド名=15点、「情報源」など汎用=8点、URLのみ=5点)、クエリ意図との一致(完全一致=20点、良好=15点、部分一致=10点、低一致=5点)。75点以上なら大きなトラフィック・コンバージョンが見込めるプレミアム掲載、50点未満は存在してもビジネス価値が低い可能性が高くなります。リンク引用の量と質の分布を両方追いましょう—低品質な100件より高品質な20件の方がはるかに価値があります。
ベクトル埋め込みは最も技術的かつ目に見えにくい引用の次元ですが、そもそもあなたのコンテンツが言及やリンクの候補に上がるかを根本的に決定します。AIがRAG(検索拡張生成)でクエリを処理する際、クエリをベクトル埋め込みに変換し、ベクトルデータベースから意味的に類似したコンテンツを検索し、最も近い5~20件を取得します—この時点で取得されなければ、以降の権威評価や引用選定に進みません。ベクトル埋め込みはテキストを高次元(通常768または1536次元)の数値配列として意味を符号化し、類似した概念はコサイン類似度(-1~1、1が同義、0が無関係)で測定します。リサーチでは、ドメイン特化クエリで0.75以上の意味的類似度が高品質検索と強く相関します。埋め込みの質を測るには、OpenAIのtext-embedding-3やGoogle Vertex AI、sentence-transformers等でコンテンツとユーザークエリの埋め込みを生成し、コサイン類似度を計算、優先クエリで0.75以上を達成したコンテンツと0.60未満で取得されないものを特定します。多くの組織は直接分析する技術インフラがありませんが、代用指標でも実用的な洞察が得られます:コンテンツ群のコア概念周辺の用語の一貫性、組織名・キーワードの明確な定義、コアトピックの網羅性と深さ、内部リンクの密度と論理構造—これらは埋め込みモデルが内容の焦点を理解するのに役立ちます。
効果的な引用の質評価には3つの次元すべてを統合的に測定することが不可欠で、各層が前段階に基づいて構築されます:強い埋め込みは検索を促し、検索は言及候補を生み、正しい帰属で言及はリンク引用となります。50~100のコアクエリでベースラインを設定し、月次で引用量と質スコアの変化を追跡、加重フレームワークで各引用タイプの質スコアを算出し、競合と比較してギャップと機会を特定する四半期フレームワークを作りましょう。ダッシュボードに表示すべき主要指標は4つ:ベクトル品質(意味的類似度、トピック一貫性、エンティティ明瞭性—主要クエリで0.75以上を目標)、言及品質(言及率、平均スコア、感情分布—言及率30%超・平均65点以上を目標)、リンク品質(引用数、質スコア分布、CTR推定—20件以上・平均70点超を目標)、ビジネス成果(AI由来トラフィック、ブランド検索ボリューム、コンバージョン率—AI引用由来で15%以上を目標)。リソースが限られる場合は、現状のボトルネックに基づいて優先順位を決めましょう:埋め込み品質が弱ければまずそこに注力(取得されなければE-E-A-Tも無意味)、埋め込みが強いのに言及率が低ければ権威性・内容深度を強化、言及は強いがリンク引用が弱ければ技術的な帰属マークアップやスキーマ実装を重視しましょう。
主要AIプラットフォームごとに引用の好みが大きく異なり、それぞれに合わせた最適化が不可欠です。6.8億件の引用を分析した研究では、著しく異なる情報源パターンが明らかになりました。ChatGPTは権威系ナレッジベース志向が強く、Wikipediaが全引用の7.8%、トップ10引用元の47.9%を占めます—百科事典的・事実重視の内容がソーシャルや新興プラットフォームより優先されます。Google AI Overviewsはバランス型で、Redditが全体の2.2%ながらトップ10では21%に留まり、YouTube(18.8%)、Quora(14.3%)、LinkedIn(13%)も上位に—プロフェッショナルな内容もコミュニティディスカッションも重視していることが分かります。Perplexityは独自のコミュニティ志向で、Redditが全引用の6.6%、トップ10の46.7%を占め、次いでYouTube(13.9%)、Gartner(7%)—伝統的権威よりピア情報や実体験重視が特徴です。これらの違いから、画一的な引用戦略は失敗します。ChatGPT対策はWikipediaや権威ソース、Google AI Overviewsは専門性とコミュニティ双方、PerplexityはRedditやUGC重視など、各プラットフォームの特性に合わせてコンテンツ・PRリソースを配分しましょう。
引用の質を高めるには、引用スタックの各次元ごとに異なる戦略が必要です。ベクトル埋め込みには、コア概念を網羅的に扱い、用語・階層を一貫させたトピッククラスターで意味的明瞭性を強化しましょう。説明的な見出し・定義・エンティティ参照で埋め込みモデルの理解を助け、1ページに異種トピックを混在させるのは避けましょう(意味的ドリフトが検索性能を損ないます)。関連概念間の内部リンクを戦略的に張ってトピカルシグナルを強化、権威ある外部ソースへの引用で文脈を補強、内容の鮮度も維持しましょう。ブランド言及には、著者情報や組織透明性、権威ある情報源の引用でE-E-A-Tを強化。断片的でなく意図に沿った網羅的コンテンツを作成し、独自調査や一次情報を発信、業界コミュニティ・フォーラムで積極的に議論に参加しましょう。リンク引用には、Article・HowTo・FAQPage・Organizationなどのスキーマ実装で内容目的と帰属を明確化、クリーンなURLや高速表示・モバイル最適化で技術品質を高め、AIが抽出しやすい独立したコンテンツチャンクや見出しを設け、ハウツーやFAQ形式のコンテンツを強化しましょう。著者ページで実績を示し、ContactやAbout、Privacyページも透明性基準を満たしましょう。
マーケティングテクノロジー領域のB2B SaaS企業が、AI生成の推奨に競合が頻繁に登場するのを受け、引用の質評価を全面導入したことで戦略が一変しました。初回監査では主要クエリでのリンク引用量は多い(85件)ものの質は低く(平均42点)、言及率も12%と低調—分析により、コンテンツは取得され(埋め込み良好)、技術面も適切でしたが、内容の深さや専門性シグナル不足で言及が稀だったと分かりました。そこで著者プロフィールや実績の充実、独自調査データの発信、断片的なブログではなく網羅的ガイドの作成に注力。6か月後、言及率は31%(158%増)、リンク引用の質スコアは68点(62%増)、AI由来トラフィックは47%増—技術基盤は既に十分で、ボトルネックは権威シグナルだったと判明しました。この事例は、引用の質測定によって量追跡では見えない最適化機会が明らかになり、リソースを最大活用できることを示しています。
引用量は言及やリンクの総数です。質は、掲載場所、文脈、感情、権威性などに基づき、各引用の価値を測定します。権威ある情報源からの質の高い10件の引用は、価値の低い100件の言及よりも大きな価値を生み出します。質はトラフィックやコンバージョンなどのビジネス成果と直接相関します。
毎月AIプラットフォーム全体で50~100件の関連クエリをテストします。各引用について、掲載目立ち度(0~35点)、文脈の一致度(0~25点)、アンカーテキストの質(0~20点)、クエリ意図との一致(0~20点)で採点します。時間とともに平均スコアを追跡しましょう。75点以上の引用は、意味のあるトラフィックを生み出しやすいプレミアムな掲載です。
3つとも異なる段階で重要です。埋め込みは情報の検索(引用のばらつきの60~70%)を決定します。言及は権威性と認知度を高めます。リンクはトラフィックとコンバージョンにつながります。すべての次元で戦略的に最適化することが成功の鍵です。
各プラットフォームは異なる学習データ、アルゴリズム、設計思想を持っています。ChatGPTはWikipediaなどの権威ある情報源を好みます。Google AI Overviewsは専門性とソーシャルな内容のバランス重視。Perplexityはコミュニティの議論を重視します。プラットフォームごとの特性に合わせて最適化しましょう。
四半期ごとに包括的な監査を行い、優先度の高いトピックは毎月スポットチェックを。AIからの自然トラフィック、ブランド検索ボリューム、引用率推移などの先行指標は毎週追跡。質のスコア変動に応じて戦略を調整し、早期の低下を検知しましょう。
部分的には可能です。既存コンテンツを構造化、スキーママークアップ、著者情報強化などで改善しましょう。E-E-A-Tシグナルも強化を。しかし、引用に値する新規コンテンツ(独自調査や網羅的ガイド)の作成が最も効果的です。
リンク引用なら70点以上が優秀。言及は60点以上で文脈適合性が高い証拠。埋め込みは0.75以上の意味的類似度が基準。競争が激しい業界はより高い閾値が必要。完璧を目指すより、四半期ごとに10~15点向上を狙いましょう。
AmICited.comはChatGPT、Perplexity、Google AI Overviewsなど様々なAIでブランドがどう参照されているかを追跡。掲載場所、感情、文脈、競合との位置関係など、量だけでなく質の指標も可視化し、戦略的最適化をサポートします。
単なる言及数を数えるのはやめて、本当に重要なものを測定しましょう。AmICited.comは、すべての主要AIプラットフォームでの引用の質を追跡し、どの言及が価値を生み出し、次に最適化すべきポイントを明確に示します。
引用品質スコアとは何か、そしてAIによる引用の顕著性、文脈、感情をどのように測定するかを学びましょう。引用品質の評価方法、スコアリングフレームワークの実装、およびAI生成回答でブランドの可視性を最適化する方法を探ります。...

ChatGPT、Perplexity、Google AIで引用頻度を高めるための確かな戦略を学びましょう。コンテンツの最適化、権威性の構築、AIシステムからより多く引用される方法を解説します。...
AIシステムにおける競合コンテンツの引用状況を分析し、可視性のギャップを特定。ChatGPT、Perplexity、Google AI Overviewsでブランドの存在感を最適化する方法を解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.