
どのAIクローラーにアクセスを許可すべきか?2025年完全ガイド
どのAIクローラーをrobots.txtで許可またはブロックすべきかを解説。GPTBot、ClaudeBot、PerplexityBotなど25種類以上のAIクローラーと設定例を網羅した総合ガイド。...
2 分で読める

GPTBotやClaudeBotなどのAIクローラーをrobots.txt、サーバーレベルブロック、高度な保護方法でブロックまたは許可する方法を学びます。事例付きの完全な技術ガイド。
デジタルの世界は、従来型SEOからAIクローラーという新しい自動訪問者カテゴリの管理へと大きくシフトしました。従来の検索ボットが検索結果からサイトへトラフィックを送るのに対し、AIトレーニングクローラーはコンテンツを消費して大規模言語モデルを構築しますが、必ずしも紹介トラフィックを返すわけではありません。この違いは、ウェブトラフィックを収益源とする出版社やコンテンツ制作者、企業にとって非常に大きな意味を持ちます。どのAIシステムが自分のコンテンツへアクセスできるかを制御することは、競争優位性、データプライバシー、収益に直結する重大な問題です。
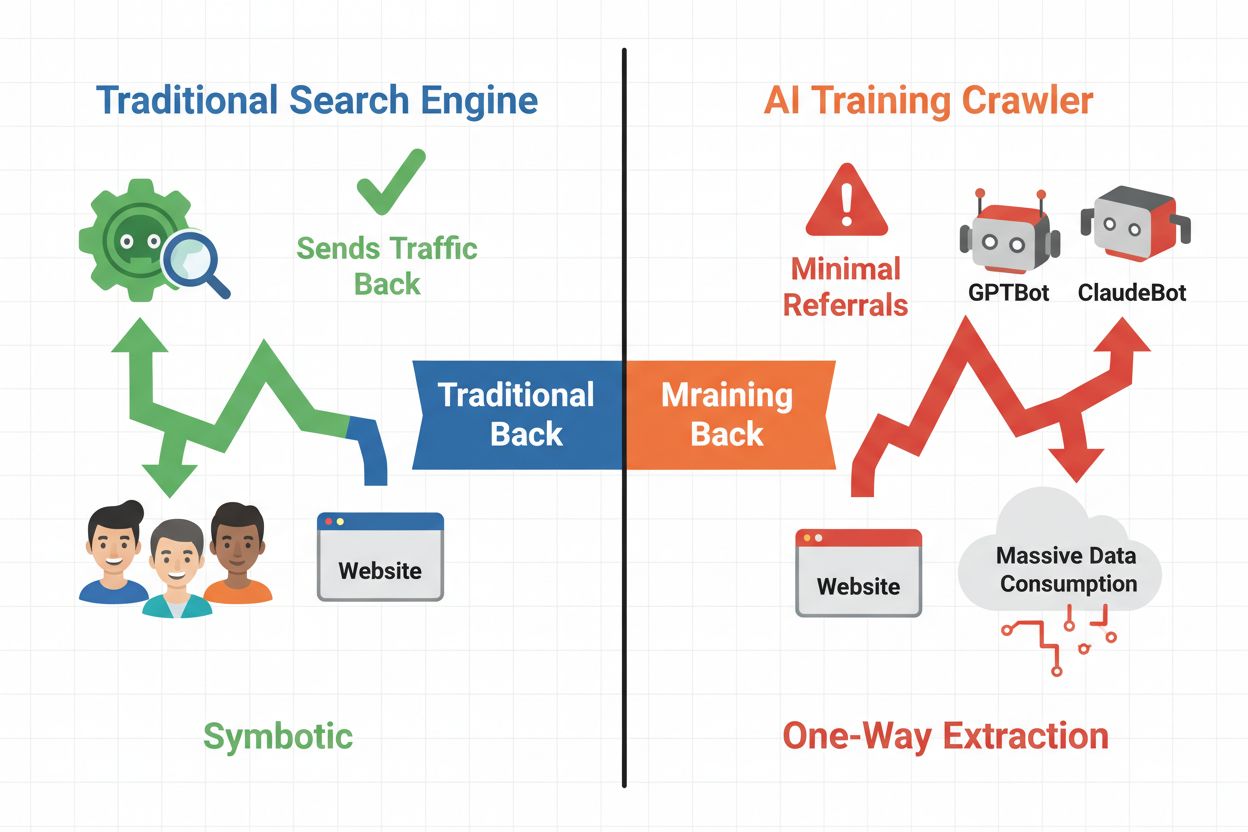
AIクローラーは大きく3つのカテゴリに分かれ、それぞれ用途やトラフィックへの影響が異なります。トレーニングクローラーはAI企業が言語モデルの構築・改良のために大量に巡回しますが、返ってくるトラフィックはほとんどありません。検索・引用クローラーはAI検索エンジンや引用システムのためにインデックス化し、一定の紹介トラフィックをもたらす場合があります。ユーザー起動型クローラーは、ユーザーがAIアプリを操作した際にオンデマンドでコンテンツを取得するもので、規模は小さいながらも近年増加傾向です。これらを理解することで、自社のビジネスモデルに応じた許可・ブロック判断がしやすくなります。
| クローラー種別 | 目的 | トラフィックへの影響 | 代表例 |
|---|---|---|---|
| トレーニング | LLM構築・改良 | ほぼ無し | GPTBot, ClaudeBot, Bytespider |
| 検索・引用 | AI検索・引用用インデックス | 中程度の紹介トラフィック | Googlebot-Extended, Perplexity |
| ユーザー起動型 | ユーザー要求時に取得 | 少ないが継続的 | ChatGPTプラグイン, Claudeブラウジング |
AIクローラーのエコシステムには、世界有数の大手テクノロジー企業のクローラーが含まれ、それぞれ異なるユーザーエージェントと目的を持っています。OpenAIのGPTBot(ユーザーエージェント: GPTBot/1.0)はChatGPTなどの学習用、AnthropicのClaudeBot(ユーザーエージェント: Claude-Web/1.0)も同様です。GoogleのGooglebot-Extended(ユーザーエージェント: Mozilla/5.0 ... Googlebot-Extended)はAI OverviewsやBardのためにインデックス化、MetaのMeta-ExternalFetcherは同社のAI向けにクロールします。その他の主要クローラーには次のようなものがあります:
各クローラーは巡回規模やブロック指示の遵守度合いもさまざまです。
robots.txtファイルはAIクローラーのアクセス制御における第一防衛線ですが、法的拘束力はなくガイドラインである点に注意が必要です。ドメイン直下(例: yoursite.com/robots.txt)に設置し、簡単な構文でクローラーごとのアクセス禁止範囲を指示します。すべてのAIクローラーを包括的にブロックしたい場合、以下のように記載します:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Googlebot-Extended
Disallow: /
User-agent: Meta-ExternalFetcher
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
選択的にブロック(検索クローラーは許可し、トレーニングクローラーのみブロック)したい場合は次のようにします:
User-agent: GPTBot
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: Googlebot-Extended
Disallow: /news/
Allow: /
Disallow: *のような広すぎるルールは解析エラーの原因になりやすく、特定クローラーだけをブロックしたい場合は個別指定を忘れないよう注意しましょう。OpenAI、Anthropic、Googleなど大手は一般的にrobots.txtを遵守しますが、Perplexityのように無視するクローラーも確認されています。
robots.txtだけでは不十分な場合、AIクローラー制御を強化する複数の方法があります。IPベースのブロックはAIクローラーのIPレンジを特定し、ファイアウォールやサーバーレベルで遮断する方法で非常に有効ですが、IPが頻繁に変わるため保守が必要です。サーバーレベルのブロックはApacheの.htaccessやNginxの設定ファイルで、より細かい制御ができrobots.txtより回避が難しくなります。Apacheの場合は以下を追加します:
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} (GPTBot|Claude-Web|Bytespider|Amazonbot) [NC]
RewriteRule ^.*$ - [F,L]
</IfModule>
メタタグによるブロック(<meta name="robots" content="noindex, noimageindex, nofollowbydefault">)はインデックス化を防げますが、学習クローラーのアクセス自体は止められません。リクエストヘッダ検証では、リバースDNSやSSL証明書の確認で正規クローラーかどうかを判定します。確実にアクセスを遮断したい場合はサーバーレベルブロックを行い、複数の方法を組み合わせて最大限の保護を実現しましょう。
AIクローラーをブロックするかどうかは、いくつかの利害を天秤にかけて決める必要があります。トレーニングクローラー(GPTBot、ClaudeBot、Bytespider)をブロックすれば、知的財産や競争優位性を守ることができます。一方、検索クローラー(Googlebot-Extended、Perplexity)を許可すれば、AI活用型の検索結果での可視性や紹介トラフィックを得られる可能性があります。ただしAI企業のクロール数と紹介数の比率は極端で、Anthropicは約38,000回のクロールごとに1件、OpenAIも約400:1という低い紹介率です。サーバー負荷や帯域コストも無視できません。AIクローラーをブロックすればインフラコスト削減にもつながります。報道機関や出版社は紹介トラフィック重視、SaaSや独自コンテンツ事業者はブロック推奨など、自社のビジネスモデルに合わせて判断しましょう。
クローラーブロックを設定した後は、本当に指示が守られているか検証が不可欠です。サーバーログ解析が主な手段で、アクセスログから該当クローラーのユーザーエージェントやIPを確認します。例えば次のコマンドでアクセス回数を集計できます:
grep -i "gptbot\|claude-web\|bytespider" /var/log/apache2/access.log | wc -l
また、curlなどのテストツールでクローラーリクエストをシミュレーションし、ブロックが機能しているか確認しましょう:
curl -A "GPTBot/1.0" https://yoursite.com/robots.txt
導入後1か月は週1でログを確認し、その後は四半期ごとに監視しましょう。robots.txt無視が判明した場合は、サーバーレベルブロックや運営元への通報も検討します。
AIクローラーの世界は急速に変化しており、新規クローラーの登場やユーザーエージェント・IPの変更も頻繁です。四半期ごとの見直しで、抜け漏れや正規トラフィックの誤ブロックを防ぎましょう。エコシステムは分散しており、完全な恒久ブロックリストの構築は不可能です。次の情報源を継続的に監視すると良いでしょう:
90日ごとにrobots.txtやサーバールールを見直すリマインダーを設定し、新規クローラー情報を追うセキュリティ系メーリングリストにも登録しましょう。
AIクローラーのブロックはアクセス遮断に有効ですが、AmICitedは補完的な課題である「AIシステムが自社ブランドやコンテンツをどのように引用・参照しているか」の監視を支援します。AmICitedはAI生成回答における組織名の登場箇所を追跡し、自社コンテンツがAIモデルにどう影響しているか、ブランドがAI検索結果でどう現れているかを可視化します。robots.txtやサーバーブロックによるアクセス制御と組み合わせることで、AIエコシステム内での自社プレゼンスを「遮断から引用測定まで」一元的に管理できるようになります。
いいえ。GPTBot、ClaudeBot、BytespiderなどのAIトレーニングクローラーをブロックしても、GoogleやBingの検索順位には影響しません。従来の検索エンジンは独立したクローラー(Googlebot、Bingbot)を使っています。それらまでブロックしない限り、検索結果から完全に消えることはありません。
OpenAI(GPTBot)、Anthropic(ClaudeBot)、Google(Google-Extended)、Perplexity(PerplexityBot)などの主要クローラーは公式にrobots.txtの指示に従うと明言しています。ただし、小規模または透明性の低いボットは無視する場合もあり、そのため多層的な保護戦略が存在します。
戦略によります。トレーニングクローラー(GPTBot、ClaudeBot、Bytespider)のみをブロックすれば、検索型クローラーを許可したままコンテンツの学習利用を防げます。完全なブロックはAIエコシステムからの除外を意味します。
最低でも四半期に一度は設定を見直してください。AI企業は新しいクローラーを頻繁に導入しています。Anthropicは「anthropic-ai」と「Claude-Web」ボットを「ClaudeBot」に統合し、ルールを更新していないサイトには一時的に無制限のアクセスを与えました。
ブロックはクローラーのコンテンツアクセスを完全に防ぎ、学習データ収集やインデックス化を阻止します。許可するとコンテンツが学習やAI検索結果への掲載に使われる可能性があり、紹介トラフィックは最小限です。
はい、robots.txtは法的強制力のないガイドラインです。大手企業のクローラーは一般的に従いますが、一部は無視します。より強力な対策には.htaccessやファイアウォールによるサーバーレベルのブロックを実施しましょう。
サーバーログでブロック対象クローラーのユーザーエージェント文字列を確認してください。ブロックしたはずのクローラーからのリクエストがあれば、robots.txtが守られていない可能性があります。Google Search Consoleのrobots.txtテスターやcurlコマンドなどの検証ツールも活用しましょう。
トレーニングクローラーをブロックしても、元々紹介トラフィックが少ないため直接的な影響は最小限です。ただし、検索クローラーをブロックすればAI活用型の発見プラットフォームでの可視性が低下します。ブロック後30日間はアナリティクスで実際の影響を観察しましょう。
robots.txtでクローラーのアクセスを制御する一方、AmICitedはAIシステムがあなたのコンテンツをどのように引用・参照しているかを追跡します。AI領域でのプレゼンスを完全に可視化しましょう。
どのAIクローラーをrobots.txtで許可またはブロックすべきかを解説。GPTBot、ClaudeBot、PerplexityBotなど25種類以上のAIクローラーと設定例を網羅した総合ガイド。...

GPTBot、ClaudeBot、PerplexityBotなどのAIクローラーをサーバーログで特定・監視する方法を解説。ユーザーエージェント文字列、IP検証、実践的な監視戦略を網羅した完全ガイド。...

AIクローラーをブロックするかどうかの戦略的判断方法を解説します。コンテンツタイプ、トラフィックソース、収益モデル、競争状況を評価するための包括的な意思決定フレームワークをご紹介。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.