
E-E-A-TとAI検索:ブランド権威性がかつてないほど重要な理由
E-E-A-T(経験、専門性、権威性、信頼性)とは何か、そしてChatGPT、Perplexity、Google AI OverviewsのようなAI検索エンジンでの可視性にとってなぜ極めて重要なのかを理解しましょう。...
1 分で読める
E-E-A-TシグナルがLLMの引用やAIでの可視性にどう影響するかを解説。経験・専門性・権威性・信頼性が、AI主導の検索におけるコンテンツの発見性をどのように形成するか学びましょう。
デジタルの地殻変動が進んでいます。バックリンクは長年、権威性の主要な指標でしたが、ChatGPTやClaude、Geminiなどの大規模言語モデル(LLM)が情報の発見や評価方法を変革する中、権威の定義自体も進化しています。E-E-A-T(経験・専門性・権威性・信頼性)は、従来はSEOの二次的な要素でしたが、今や検索・AIプラットフォーム両方での可視性を左右する基盤となりました。ここで重要なのは、バックリンクだけがAIに引用されるか否かを決める唯一の指標ではなくなったということです。LLMはセマンティックな豊かさ、複数情報源での一貫性、知識の深さなどから権威性を判断します。この変化は、GoogleのAI OverviewsやPerplexity、ChatGPTといったAI引用システムで可視性を高めたいブランドにとって非常に重要です。AmICitedがこれらプラットフォームでブランドがAIにどう参照されているかをモニタリングする際、従来のリンクプロファイルを超えた多様なシグナルを追跡しています。もはや「誰がリンクしてくれるか?」ではなく、「あなたのコンテンツは本物の専門性を示し、AIが信頼して引用できるか?」が問われています。この違いを理解することは、AI検索時代に権威を築くために不可欠です。
E-E-A-Tは、コンテンツの信頼性を構成する4つの側面を表します。それぞれがGoogleやLLMがコンテンツの可視性を判断する上で役割を持っています。AI引用の文脈で、各柱を簡単に解説します。
経験は、自分自身で実際にその行為をしたことを意味します。例えば、6ヶ月使った人が書いた製品レビューは、一般的なまとめ記事より重みがあります。LLMは一次体験を示す言語パターン(具体的な詳細や実体験の観察、現場ならではのニュアンスなど)から経験値を認識します。
専門性は、資格や学歴、実績によって裏付けられた知識です。CFA資格を持つファイナンシャルアドバイザーが投資戦略について書く方が、一般ブロガーより権威があります。LLMは専門用語の正確な使用、論理的な説明の深さ、複雑なサブトピックへの対応力などで専門性を判断します。
権威性は、外部からの評価や認知です。他の信頼できる情報源から引用、リンク、言及されることで高まります。従来はバックリンクで測られてきましたが、LLMではセマンティックな足跡(ブランドや名前が複数プラットフォームにどれだけ一貫して現れるか)が重視されつつあります。
信頼性は全てを支える土台です。信頼がなければ他の3つも崩れます。著者情報や連絡先の明示、正確な情報と出典、HTTPSやプロフェッショナルなサイト構造などが信頼性を築きます。Googleも「信頼性はE-E-A-Tの中で最重要」と明言しており、LLMも引用元選定時に一貫性や信頼性を重視します。
| シグナル | 従来SEOでの評価 | LLM引用での評価 |
|---|---|---|
| 経験 | 著者紹介、体験談 | 一次体験を示す言語パターン |
| 専門性 | 資格、権威サイトからの被リンク | セマンティックな深さ、専門用語、トピックの網羅性 |
| 権威性 | 被リンク数、ドメインオーソリティ | エンティティ認識、クロスプラットフォームでの言及、セマンティック権威 |
| 信頼性 | HTTPS、サイト構造、ユーザーレビュー | 複数情報源での一貫性、正確性の検証、明確さ |
従来SEOが構造的なシグナル(リンクやドメイン指標)を頼りにするのに対し、LLMはセマンティック・文脈分析でE-E-A-Tを評価します。つまり、本物の専門性と一貫性があれば、大規模なリンク構築がなくても権威性を築ける時代です。
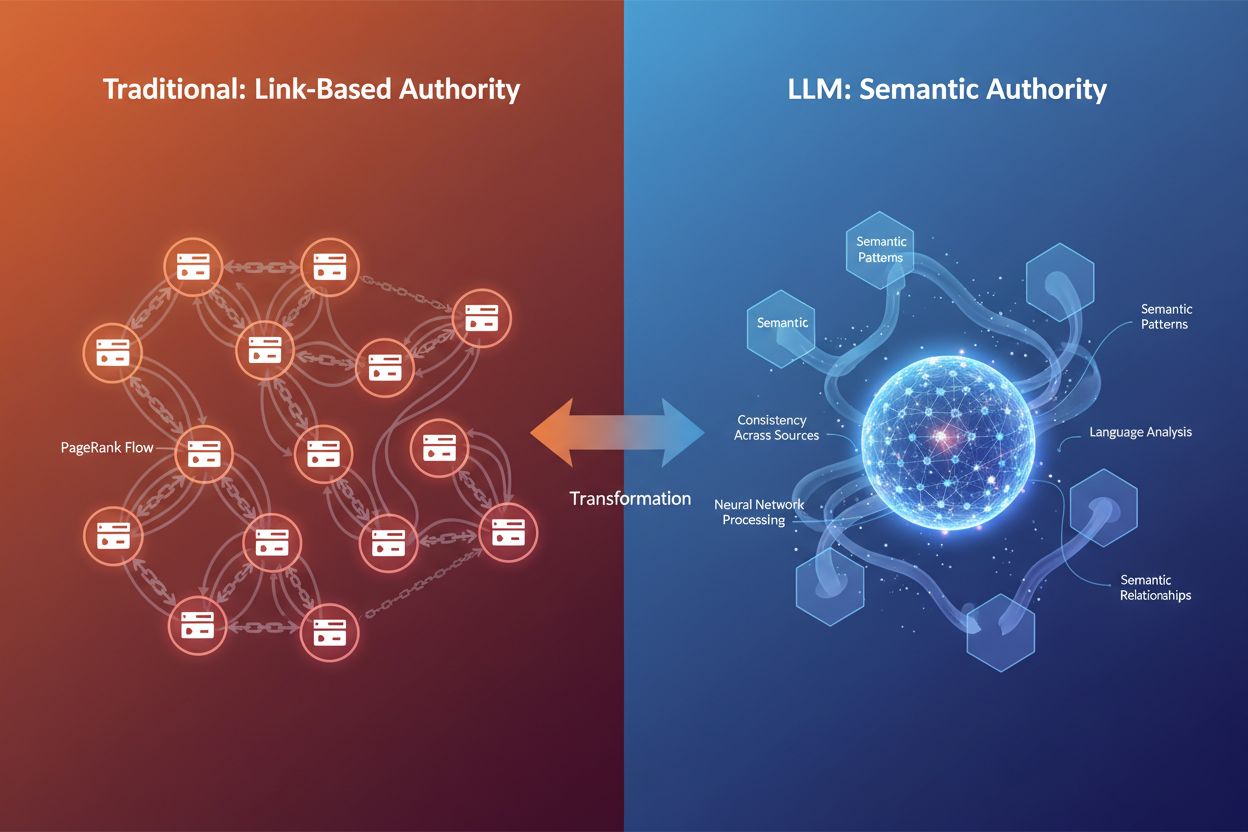
大規模言語モデルは、従来の検索エンジンのようにバックリンクやドメインスコアを参照しません。確率機械として、言語・文脈・情報の一貫性のパターンを認識します。LLMがコンテンツを引用するか判断する際、Googleのランキングアルゴリズムとは根本的に異なる問いを投げかけています。
パターン認識 vs. 構造的シグナル:従来検索は「誰がリンクしているか?」で権威性を検証します。一方、LLMは言語的に権威を認識します。専門用語の適切な使用、論理展開、確信あるトーン、トピックの微妙な側面への言及など、専門性を示すかどうかを分析します。例えば心臓病の記事で「コレステロール」「動脈プラーク」「心血管リスク要因」など関連概念が自然に盛り込まれていれば、被リンクがなくてもセマンティック権威を示せます。
セマンティック関連性とトピックの深さ:LLMは、1つの話題を多角的に掘り下げたコンテンツを優先します。AIアシスタントはユーザーの質問を複数のサブクエリ(「クエリファンアウト」)に分解し、それらに合致する情報を収集します。関連サブトピックや追加質問、コンテキストまで網羅したコンテンツほど引用されやすくなります。これがセマンティックな豊かさが新たな権威性シグナルとなった理由です。
複数ソースでの一貫性:LLMは数百万の文書を横断し、一貫性と独自性の両方がある情報を権威性が高いと見なします。逆に、根拠なく通説と大きく異なる内容は信頼性が低いと判定されがちです。新しいアイデアを提示する場合も、検証可能な情報に基づくことが大切です。
権威性評価の主な違い:
結論:LLMは意味によって権威を認識し、従来のメトリクスには依存しません。これがAIでの可視性最適化のアプローチを根本から変えています。
近年のLLM引用行動を調査した研究で最も顕著だったのは、強い新規性バイアスです。ChatGPT、Gemini、Perplexityの引用9万件を分析すると、引用URLの多くがLLM回答時点から数百日以内に公開されたものでした。これは偶然ではなく、設計思想に基づきます。LLMは新しい情報ほど関連性・品質が高いと判断しやすいのです。
RAG検索における鮮度の重要性:LLMがRetrieval-Augmented Generation(RAG)でリアルタイム検索を行う際、「今最も関連性の高い情報は何か?」を問うことになります。新しい=信頼できるという判断軸です。時事・市場動向・最新研究などは、1ヶ月前の記事が5年前のものより信頼されやすくなります。よって、定期的な更新・メンテナンスを続けるコンテンツ制作者が有利です。
プラットフォームごとの鮮度傾向:調査によると、Geminiが最も新しいコンテンツを強く好み、引用も公開から0~300日以内が最多です。Perplexityは新旧バランス型、OpenAIは幅広い年代を参照しますが、やはり最新情報の引用が活発です。自社のオーディエンスがどのAIプラットフォームをよく使うかを踏まえ、最適化方針を立てましょう。
時事性の高い話題は更新必須:YMYL(健康・金融・法務など生活に影響する分野)や変化の早い業界では、鮮度が絶対条件です。例えば2021年の暗号資産規制の記事は、2025年の引用対象になりにくいものです。統計は年1回(業界によっては四半期ごと)更新し、「最終更新日」を明示し、重要データは新情報登場時に随時刷新しましょう。これがAI・人間双方に現役コンテンツであるシグナルとなります。
新規性バイアスのデータ:抽出可能な公開日付きURL 21,412件の分析では、3大LLMいずれも引用は公開から0~300日でピーク、その後はロングテールに減少します。つまり、公開1年目がAIでの可視性の勝負所。3年以上前のコンテンツは、更新やエバーグリーン化されていない限り、引用率が大きく低下します。
LLMはドメインオーソリティスコア自体を直接評価しませんが、権威性の高いドメインほど引用頻度が高い傾向は明らかです。ChatGPTで最も引用された上位1,000サイトを分析すると、DR60以上の高オーソリティサイトが圧倒的に多く、特にDR80~100が主な引用元でした。ただし、これは直接的というより間接的な影響です。高DRサイトは検索順位が高くなりやすく、LLMが検索を通じて情報を取得する際、必然的に権威サイトと出会う確率が高まります。
間接的権威効果:ドメインオーソリティとLLM引用の関係は、「LLMが検索(もしくは検索的なリトリーバル)で情報を探す→高オーソリティサイトが上位表示→結果的に引用されやすい」という構造です。LLM自身がDRスコアを読むわけではなく、「検索での可視性=引用機会増」という相関関係です。従来型SEOのバックリンクによる権威づくりは、AI時代でも依然価値があります。
セマンティックな豊かさが新たな権威シグナル:ドメイン指標だけでなく、LLMはトピックの深さ・広さからも権威性を認識します。関連キーワードを自然に使い、サブトピックや文脈情報もカバーしたページは、AIにとって専門性が高いとみなされます。例えば「地中海式ダイエットの利点」なら、文化的背景・健康効果・他の食事法との比較・よくある質問まで網羅した記事は、単なるリスト型記事よりセマンティック権威が高いです。
エンティティ関係とトピック権威:LLMはエンティティ認識で知識グラフ上の関連性も解析します。例えば「スティーブ・ジョブズ」の記事がApple・イノベーション・リーダーシップ・プロダクトデザインなどと一貫して関連付いていれば、AIは権威性の高い情報源と認識します。これゆえ、構造化データやスキーママークアップの重要性が増しています。
拡張クエリへの対応力:LLMはユーザーの問いを複数の関連クエリに拡張します。コンテンツは主クエリだけでなく、そのバリエーションや関連質問もカバーする必要があります。「アボカドの食べ頃を知る方法」なら、「アボカドの熟し具合の見分け方」「熟すまでの日数」「熟したアボカドの保存方法」なども網羅すると、複数のクエリで引用されやすくなります。
LLM引用を見据えたE-E-A-T最適化には、戦略的で多層的なアプローチが不可欠です。AIが専門性を認識・抽出しやすいコンテンツ作りが目標です。実践的なフレームワークを紹介します。
1. 資格・専門性を明確に表示 著者紹介は具体的かつ検証可能に。資格・学位・肩書き、経験年数、トピックへの関与実績を明記しましょう。ただの「マーケティング専門家」ではなく、「HubSpotやSalesforceで15年のB2B SaaSマーケティング経験を持つCMO」など具体性が重要。全てのコンテンツに著者情報を掲載し、Authorスキーマで機械可読化も推奨。
2. 独自調査・データを発信 一次調査データは最強の権威シグナルです。独自のアンケート、業界ベンチマーク、事例研究など、他で得られない情報を公開しましょう。LLMは独自性の高い一次情報を好んで引用します。調査方法やサンプル数の明示も忘れずに。
3. 複数プラットフォームで一貫した権威性を維持 もはや自社サイトだけで権威は築けません。LinkedIn・業界メディア・登壇・メディア掲載など、多様なチャネルで専門性や肩書き、発信内容を統一しましょう。AIは複数プラットフォームで一貫して同一人物・ブランドが権威として言及されているかを重視します。
4. 適切なスキーママークアップを実装 スキーマで専門性シグナルを機械可読に。Articleスキーマで公開日・著者情報、FAQスキーマでQ&A、Authorスキーマで資格紐付けなど活用を。検索キーワードの36.6%がスキーマ由来のフィーチャードスニペットを誘発しているという調査もあり、LLMにも有効です。
5. トピッククラスターで権威を築く 単発記事ではなく、関連トピックを網羅するハブコンテンツを構築・内部リンクで繋げましょう。サブトピックを徹底的に解説し、セマンティックな網を張ることで、検索エンジン・LLM双方にトピック権威を示せます。
6. 計画的なコンテンツ更新 鮮度はGoogle・LLM双方のランキング要因です。重要ページは四半期ごと見直し、統計は年1回刷新、「最終更新日」を明示しましょう。継続的なメンテナンスが現役コンテンツの証です。
7. 権威ある情報源を引用 信頼できる他サイトの研究・業界レポート・専門家などを引用しましょう。自分の主張の信頼性を補強し、LLMにとってもコンテキストの理解や信頼性向上に寄与します。
8. 限界や不確実性を透明化 本物の専門家は「知らないこと」も明示できます。専門外の話題・データの限界・仮説などは率直に伝えましょう。これは人間・AI両方に対する信頼構築に繋がります。
理論だけでなく、実際にどのようなコンテンツが高い引用性を持つかを見てみましょう。
高引用コンテンツの構成例:「Ahrefsの『SEOの費用はいくらか?』ページ」はLLM引用最適化の好例です。よく検索される質問に直接答え、独自調査(439人調査)を根拠に、タイムスタンプや価格バリエーション(フリーランス・代理店・地域ごと)を分かりやすく提示。見出しやデータビジュアライゼーションを駆使し、複数角度からテーマを掘り下げています。著者の資格明示やピアレビューも信頼性を強化。
引用されやすいコンテンツの特徴:特定質問に直接答え、独自データや検証可能な情報を根拠に、構造化された見出し・表・箇条書きで抽出しやすく、複数角度から深く解説し、専門性を示すものが高引用となります。LLMは「明確かつ正確な答えを抽出できるか?信頼できる情報源か?唯一無二の価値があるか?」を判断基準にしています。
構造化フォーマットが引用シグナルに:見出し階層・箇条書き・表・短文などで構造化された記事は引用されやすいです。これは人間の読みやすさだけでなく、AIの抽出しやすさにも直結します。見出しや箇条書きで整理された記事は、情報の特定・引用が容易です。
多角的なトピックカバー:1つのテーマを異なる視点から掘り下げることで、引用機会が増えます。例えば「リモートワークの生産性」なら、職種別・タイムゾーン別・自宅環境別・性格別など多角的に論じることで、複数クエリへの回答源となり、引用ポテンシャルが大幅に高まります。
実際の引用傾向:SearchAtlasによるLLM9万件の引用分析では、強いドメインオーソリティを持つサイトだけでなく、ニッチ専門家やReddit・Substackなどバックリンクが弱くても専門性と明快さを持つ記事も頻繁に引用されています。権威性はリンク指標だけでなく知識の深さで評価される時代になったことが分かります。
E-E-A-Tを強化するだけでなく、その効果を測定することも重要です。従来のSEO指標(順位・被リンク数)だけではAIでの可視性は把握できません。AI時代に合った新しい指標やツールが必要です。
AI各プラットフォームでの手動テスト:まずは自社コンテンツが答えるべき10~20の質問リストを作り、ChatGPT・Perplexity・Claude・Geminiで月次テストしましょう。自社・競合が引用されているか、変化や傾向を記録します。手間はかかりますが、実際にオーディエンスが何を見るかを直に把握できます。Googleスプレッドシート等で記録・分析しましょう。
AIリファラル流入のアナリティクス追跡:多くのアナリティクスツールはAI検索流入を独立チャネルとして計測します。Ahrefs Web Analytics(無料)ではAI流入ページ・ユーザー行動(滞在時間・直帰率・スクロール率・CV率)を確認可能です。AI流入は全体の1%未満ですが、検索流入に比べて高い意図やCV率を示すことが多いです。
E-E-A-T効果測定指標:直接的なE-E-A-Tスコアではなく、AI Overviewの引用数(BrightEdgeやAuthoritasなどで計測)、ブランド検索ボリューム、業界内言及、アルゴリズムアップデート時の安定性などを追いましょう。強いE-E-A-Tコンテンツはアップデートにも強い傾向があります。LLM SEO E-E-A-T Score Checkerのようなツールでカテゴリ別分析も可能です。
大規模な有料モニタリング:手動テストが難しい場合は、Ahrefs Brand RadarのようなツールでAI6大プラットフォーム1億5000万プロンプトの引用を一括モニタリング可能です。どこで・いつ・どのトピックで引用されたか、競合比較や傾向分析もでき、AI可視性の全体像を把握できます。
主要モニタリング指標:AI引用頻度(どれだけ引用されるか)、引用多様性(トピックやプラットフォームの幅)、セマンティック関連スコア(引用内容とクエリの一致度)、鮮度(引用記事の平均年数)、ドメイン重複(競合と並んで引用されているか)などを総合的に追いましょう。
E-E-A-TやLLM最適化の注目度が上がる中、いくつかの誤解も広まっています。代表的なものを解説します。
誤解:「バックリンクは時代遅れ」 事実: バックリンクは依然Googleの重要な権威シグナルです。比重が下がっただけで、完全に不要になったわけではありません。権威あるサイトがLLMで多く引用されるのは、検索順位が高いからです。バックリンクは今や「セマンティック権威・鮮度・専門性」などと組み合わさった総合評価の一要素です。
誤解:「E-E-A-Tは直接的なランキング要因」 事実: E-E-A-Tはキーワードやページスピードのような直接要因ではなく、Googleの品質評価者ガイドラインを通じてアルゴリズムを調整する枠組みです。E-E-A-T最適化は本来人間のためであり、権威ある・信頼できるコンテンツを作ることに繋がります。ランキング効果は間接的なものです。
誤解:「AIは長期的に偽の権威を見抜ける」 事実: これは部分的に正しいですが、複雑です。LLMは言葉遣いや構造だけで「もっともらしい」偽権威を短期的には見抜けませんが、長期的には人間による検証や多様な学習データの増加で、本物と見せかけの差異が明確化しつつあります。最善策は「本物の権威を築く」ことです。
誤解:「LLM引用には大量のバックリンクが必要」 事実: 権威ドメインが引用されやすいのは事実ですが、ニッチな専門家やバックリンクが少ないサイトもLLM引用に頻出します。重要なのは特定分野での本物の専門性です。トピック深掘り型の専門ブログは、汎用サイトより高く評価されることもあります。
誤解:「LLMは検索上位10件だけを引用する」 事実: AI Overviewの52%は上位10件から引用されますが、それ以外からも引用は発生します。質と多様性が大切です。トピックに対して高い関連性・権威性があれば、主要クエリで上位表示されなくても、拡張クエリや独自価値が認められれば引用されます。
権威性のあり方はリアルタイムで変化しています。今後の方向性を理解することが、長期的な戦略構築に役立ちます。
リンク重視から意味重視のランキングへ:「誰がリンクしているか?」から「そのコンテンツが何を意味しているか?」へのシフトが進んでいます。構造的シグナルからセマンティックシグナルへの転換は、権威性の認識方法を根本から変えます。従来SEOはリンク構築で権威を形成しましたが、AI時代は専門性・
E-E-A-Tは、経験(Experience)、専門性(Expertise)、権威性(Authoritativeness)、信頼性(Trust)の頭文字をとったものです。従来の検索やAIシステムでコンテンツの信頼性を判断するためのフレームワークです。LLMはE-E-A-Tシグナルを用いて、どの情報源を回答で引用するかを決定します。AIでの可視性確保に不可欠です。
LLMはバックリンクよりも、セマンティックなパターンや情報源間の一貫性、実証された専門性によって権威性を評価します。専門用語、論理的な深さ、トピックの網羅力など言語的側面から権威性を認識します。そのため、権威あるサイトが多く引用される傾向は変わりませんが、主にLLMが参照する検索結果で上位表示されるからです。
はい。大規模サイトに利点はありますが、バックリンクが少ないニッチな専門家でもLLMの引用に頻出します。重要なのは、セマンティックな豊かさ・トピックの深さ・一貫した発信で、特定分野で本物の専門性を示すことです。深い知識を持つ専門ブログは、より多くのバックリンクを持つ総合サイトよりも高く評価されることがあります。
E-E-A-Tは長期的な戦略です。本当の権威性や信頼性の構築には通常数ヶ月かかります。ただし、適切なスキーママークアップや著者情報の明示は、より即効性のある効果もあります。コンテンツ公開後の最初の1年がAIでの可視性にとって重要で、3年経過すると大幅に引用率が下がるため、定期的な更新が必要です。
バックリンクは依然として価値ある権威シグナルですが、それだけが評価基準ではありません。権威あるサイトはLLMで引用されやすいですが、それは主に検索結果で上位に表示されやすいためです。重要なのは、バックリンクも含め、セマンティックな権威性や鮮度、専門性の証明など、より大きなパズルの一部になったということです。
AIによる引用頻度、トピックやプラットフォームごとの引用多様性、セマンティック関連スコア、鮮度メトリクス、競合とのドメイン重複などを追跡しましょう。Ahrefs Brand Radarなどのツールで1億5000万件のプロンプトを横断的にモニタリングしたり、ChatGPT・Perplexity・Claude・Geminiで月次テストするのも有効です。
いいえ、E-E-A-Tは直接的なランキング要因ではありません。AIシステムがコンテンツ品質を評価する際のフレームワークです。E-E-A-T最適化は、まず人間読者にとって本当に権威があり信頼できるコンテンツを作ることに他なりません。その副次的効果としてユーザー満足度や引用率が向上します。
鮮度はLLMの引用選定で非常に重視されています。研究によると、LLMは公開から300日以内のコンテンツを大幅に高い頻度で引用します。特に時事性の高い話題では、1ヶ月前の記事は5年前の記事よりも信頼性が高いと見なされます。体系的な更新や「最終更新日」の明記はAIでの可視性維持に必須です。
ChatGPT、Perplexity、Google AI Overviews、その他のLLMによるブランドの引用状況を追跡。E-E-A-Tシグナルを理解し、AmICitedでAIでの可視性を最適化しましょう。
E-E-A-T(経験、専門性、権威性、信頼性)とは何か、そしてChatGPT、Perplexity、Google AI OverviewsのようなAI検索エンジンでの可視性にとってなぜ極めて重要なのかを理解しましょう。...
E-E-A-T(経験・専門性・権威性・信頼性)は、Googleがコンテンツ品質を評価するためのフレームワークです。SEO、AIの引用、ブランドの可視性にどのように影響するかを学びましょう。...

ChatGPT、Perplexity、Google AI Overviews などのAIシステムに対して、一次知識や経験シグナルをどのように示すかを学びましょう。AIによる引用や可視性の最適化方法もご紹介します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.