
AIの可視性のための調査データ:独自統計が引用を増やす理由
独自の調査データとオリジナル統計がどのようにLLMから引用を集める磁石になるのかを解説します。AIの可視性を高め、ChatGPT、Perplexity、Google AI Overviewなどからより多く引用されるための戦略を学びましょう。...
2 分で読める
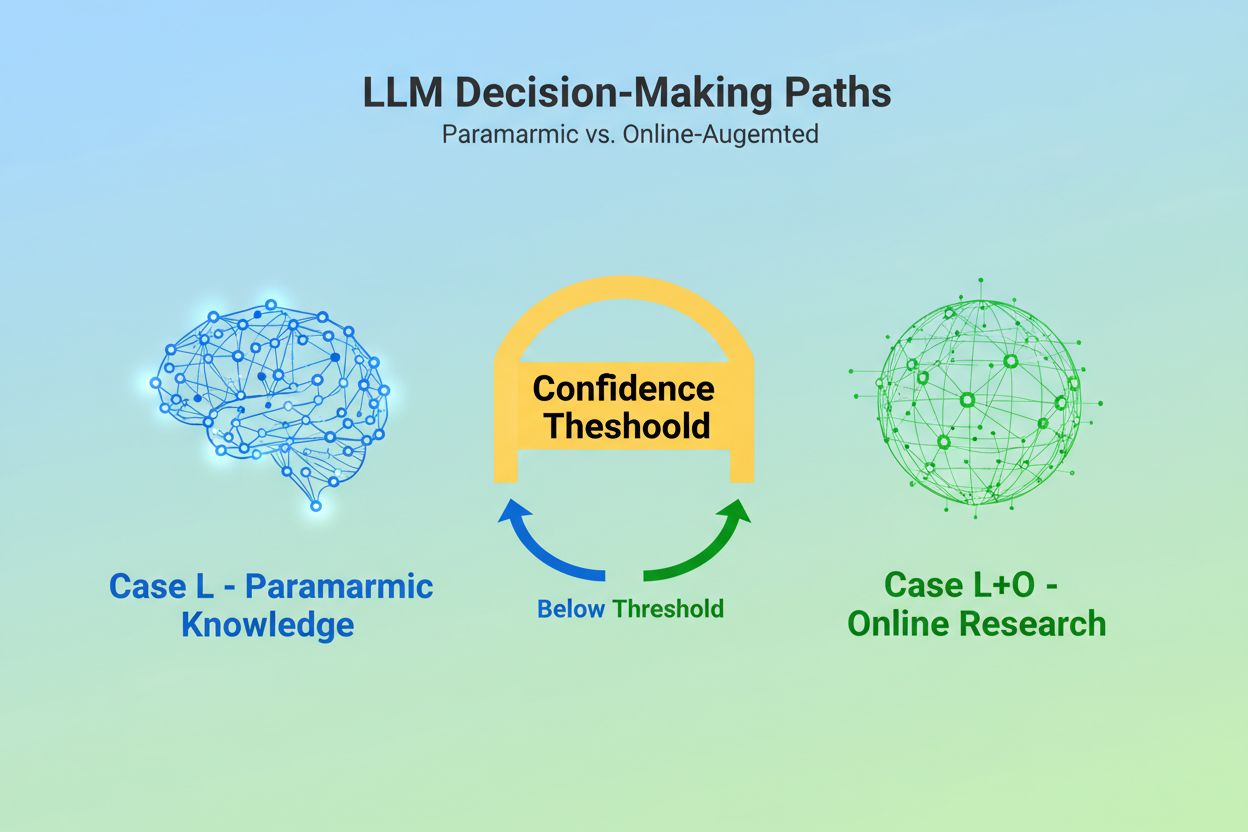
大規模言語モデル(LLM)がクエリを受け取るとき、根本的な判断に直面します。それは、学習時に埋め込まれた知識のみに頼るべきか、それとも最新情報を求めてウェブ検索を行うべきかという選択です。この2択、すなわちCase L(学習データのみ)とCase L+O(学習データ+オンライン調査)は、LLMがそもそも情報ソースを引用するかどうかを左右します。Case Lモードでは、モデルはパラメトリック知識ベース、つまり学習時に凝縮されたパターン(通常、数か月から1年以上前の情報)だけに依拠します。Case L+Oモードでは、一定の信頼度閾値を下回ると外部調査が発動し、「候補空間」と呼ばれるURLや情報ソースの探索が始まります。この判断点は多くのモニタリングツールからは見えませんが、ここからすべての引用メカニズムが始まるのです――この検索フェーズが始まらない限り、外部の情報ソースは評価も引用もされません。
LLMが外部ソース検索を決断した瞬間、引用選択において最も重要なフェーズ――証拠の重み付け――に入ります。ここで単なる言及と権威ある推薦との差が生まれます。モデルは、単にソースの出現回数や検索順位をカウントするのではありません。証拠自体の構造的完全性を評価します。ドキュメントの構成――明確なデータ関係、繰り返し現れる識別子、参照リンクの有無――が信頼性のサインとして解釈されます。モデルは「証拠グラフ」を構築し、ノードがエンティティ、エッジがドキュメント間関係を表します。各ソースは、内容の関連性だけでなく、複数ドキュメントで事実がどれだけ一貫して確認されるか、情報の主題的な関連度、ドメインの権威性など、多次元的に評価されます。この包括的評価が証拠マトリクスとなり、どのソースが十分信頼できて引用に値するかを決定します。このフェーズはLLMの推論層で動作するため、取得信号しか測定しない従来のGEOモニタリングツールでは可視化できません。
特にJSON-LD、Schema.orgマークアップ、RDFaなどの構造化データは、証拠重み付けプロセスで乗数的な効果を発揮します。適切に構造化データを実装したソースは、非構造化コンテンツと比べて証拠マトリクスで2~3倍高い重みを受けます。これはLLMが見た目のフォーマットを好むからではなく、エンティティリンク、つまり@id、sameAs、Q-ID(Wikidata識別子)など機械可読な識別子でドキュメント間の参照を結びつけられるからです。LLMが組織のQ-ID付きソースを見つけた場合、複数ドキュメントで即座にそのエンティティを検証し、「ドキュメント横断エンティティ共参照」を実現します。この検証が、ソースの信頼性に対する確信度を飛躍的に高めます。
| データ形式 | 引用精度 | エンティティリンク | ドキュメント横断検証 |
|---|---|---|---|
| 非構造化テキスト | 62% | なし | 手動推測 |
| 基本HTMLマークアップ | 71% | 限定的 | 部分一致 |
| RDFa/マイクロデータ | 81% | 良好 | パターンベース |
| Q-ID付きJSON-LD | 94% | 優秀 | 検証済みリンク |
| ナレッジグラフ形式 | 97% | 完全 | 自動検証 |
構造化データの効果は2つの時間軸で働きます。一時的には、LLMがオンライン検索時にJSON-LDやSchema.orgマークアップをリアルタイムで読み込み、直ちに証拠重み付けへ組み込みます。永続的には、一貫して維持された構造化データは将来の学習サイクルでモデルのパラメトリック知識ベースに統合され、オンライン調査なしでもエンティティ評価や認識に影響します。この二重メカニズムによって、適切な構造化データを実装するブランドは、即時の引用可視性と長期的なAI内部権威の両方を確保できるのです。
LLMが情報ソースを引用する前に、まずそのソースが何についてであり、誰を表すかを理解しなければなりません。これこそがエンティティ認識の役割であり、人間の曖昧な言葉を機械が読めるエンティティへと変換します。たとえば「Apple」と記述された場合、LLMはApple Inc.なのか果物なのか、あるいは全く別なのかを判別する必要があります。モデルはWikipedia、Wikidata、Common Crawlから学習したエンティティパターンと、周辺文脈の解析を組み合わせて判断します。Case L+Oモードでは、さらに高度化し、外部構造化データの@id属性やsameAsリンク、Q-IDなどでエンティティ検証が行われます。この検証が不可欠なのは、曖昧または一貫性のないエンティティ参照がモデルの推論過程でノイズとなってしまうからです。命名に一貫性がなく明確な識別子もSchema.orgマークアップもないブランドは、機械にとって意味的に不明瞭となり、単一の一貫したソースではなく複数の異なるエンティティとして扱われてしまいます。一方、複数ドキュメントにわたり安定して参照されるエンティティを持つ組織は、LLMのナレッジグラフ内で信頼できるノードとして認識され、引用される確率が大幅に高まります。
クエリから引用に至るまでの道のりは、研究者がLLMの挙動を分析して明らかにした7段階の構造化プロセスに従います。フェーズ0:意図解析では、モデルが入力をトークン化し、意味解析を行い、ユーザーの本当の意図を抽象化した「インテントベクトル」を作成します。この段階で、検討すべき話題やエンティティ、関係性が絞り込まれます。フェーズ1:内部知識検索でパラメトリック知識を参照し、信頼度スコアを算出。閾値を超えればCase Lモードのまま、超えなければ外部調査へ進みます。フェーズ2:ファンアウトクエリ生成(Case L+Oのみ)では、意味的に多様な検索クエリ(通常1~6トークン)を生成し、候補空間を最大化します。フェーズ3:証拠抽出で検索結果のURLやスニペットを取得し、HTMLを解析、JSON-LD・RDFa・マイクロデータを抽出します。ここで初めて構造化データが引用メカニズムに現れます。フェーズ4:エンティティリンクで取得ドキュメントのエンティティを識別し、外部識別子で検証して一時的なナレッジグラフを構築。フェーズ5:証拠の重み付けで全ソースの証拠強度を評価――ドキュメント構成、ソース多様性、確認頻度、ソース間一貫性などを加味します。フェーズ6:推論と統合で内部・外部証拠を組み合わせ、矛盾を解消し、それぞれのソースを言及にとどめるか推薦とするかを決定。フェーズ7:最終回答作成で重み付けされた証拠を自然言語に変換し、適切な箇所で引用を挿入します。各フェーズは次にフィードバックし、矛盾があれば検索や証拠評価を再実行するループも持ちます。

現代のLLMは検索拡張生成(RAG)を積極的に採用しており、引用選択と根拠付けの方法を根本的に変えています。パラメトリック知識だけに頼らず、RAGシステムは関連文書を検索・取得し、証拠を抽出し、回答を特定ソースに基づいて構築します。これにより、引用が学習時の副産物ではなく、明示的かつ追跡可能なプロセスへと変化します。RAG実装は通常、ハイブリッド検索(キーワード検索+ベクトル類似検索)でリコール最大化を図り、候補文書取得後は意味的ランキングで単なるキーワード一致でなく内容の関連性で再評価し、最も適切なソースを上位表示します。この明示的な取得メカニズムにより、引用プロセスは透明かつ監査可能となり、それぞれの引用ソースがどの根拠文から選ばれたか追跡できます。AI可視性をモニタリングする組織にとって、RAGベースのシステムは特に重要で、測定可能な引用パターンを生み出します。AmICitedのようなツールは、RAGシステムが各AIプラットフォームであなたのブランドをどのように参照するかを追跡し、引用ソースとして登場しているのか、証拠取得段階の背景情報止まりなのかを可視化します。
すべての引用が等価とは限りません。LLMはあるソースを背景情報として言及し、他のソースを権威ある証拠として推薦することがあります――この違いは取得の成否ではなく、全て証拠重み付けで決まります。ソースは候補空間(フェーズ2~3)に現れても、証拠スコアが不十分なら推薦にはなりません。この言及と推薦の分離こそ、従来のGEO指標が見落とす点です。標準的なモニタリングツールはファンアウト(検索結果での露出)を測っても、LLMが実際にあなたのコンテンツを信頼して推薦するかまでは測れません。言及は「一部のソースによれば…」といった記述、推薦は「[ソース]によると証拠が示しています…」といった表現になります。この違いはフェーズ5の証拠マトリクススコアに現れます。一貫したQ-ID、整然としたドキュメント構成、複数独立ソースでの確認があるソースは推薦に昇格します。曖昧なエンティティ参照、構造不整合、孤立した主張しかないソースは言及どまりです。ブランドにとって、これは極めて重要な違いです:取得されることと、権威として引用されることは違います。取得から推薦へ進むには、意味的明確性、構造的完全性、証拠密度が不可欠――従来SEO最適化では対処されない要素です。
LLMがソースをどう選択するかを理解すれば、コンテンツ戦略に即座に応用できます。まず、ウェブサイト全体でSchema.orgマークアップを一貫して導入しましょう。特に組織情報、記事、主要エンティティでJSON-LD形式を使い、@idやsameAsリンクでWikidataやWikipediaなど権威あるソースに接続します。これがフェーズ5で証拠重みを直接高めます。次に、組織・製品・主要概念の明確なエンティティ識別子を確立しましょう。命名規則を統一し、曖昧な略称は避け、関連エンティティをisPartOf, about, mentions など階層的関係でリンクづけます。三つ目は、主張や実績・関係性に関する機械可読な証拠を作成すること。単に「当社はXのリーディングカンパニーです」と書くだけでなく、その主張を補強する構造化データ、引用、検証可能な関係を示しましょう。四つ目は、複数プラットフォーム・期間にわたってコンテンツの一貫性を維持しましょう。LLMは証拠密度を、独立ソース間で主張が確認されているかで評価します。単一プラットフォームの孤立した主張は重みが下がります。五つ目に、従来のSEO指標がAI引用を予測しないことを理解しましょう。検索順位が高くてもLLMの推薦が得られるとは限りません。むしろ意味的明確性と構造的完全性を重視すべきです。六つ目は、AmICitedのようなツールで引用パターンをモニタリングしましょう。言及と推薦のどちらに到達しているか、どのコンテンツが引用を誘発するかが明らかになります。最後に、AI可視性は長期的投資であることを認識しましょう。今実装する構造化データが、即時の引用確率(短期)と将来学習サイクルでの内部知識ベース(長期)の両方に影響します。
LLMの進化に伴い、引用メカニズムはますます高度かつ透明になりつつあります。将来のモデルは、引用グラフ――どのソースがどの主張にどう影響したかの明示的なマッピング――を実装する可能性が高いでしょう。一部の先進システムではすでに、引用ごとに確率的信頼度スコアを付与し、その関連性・信頼性についてモデルがどれだけ確信しているかを表示する実験も始まっています。さらに、人間参加型の検証――ユーザーが引用を指摘・フィードバックすることで、今後の証拠重み付けが洗練される仕組みも登場しつつあります。構造化データが学習サイクルに組み込まれることで、今セマンティックインフラを実装する組織は、事実上AIシステム内での長期的権威を築いているのです。検索エンジンの順位がアルゴリズム変更で変動するのとは異なり、構造化データの永続的効果はAI可視性の安定した基盤を作ります。「見つかる」から「信頼される」へのこのシフトは、ブランドがデジタルコミュニケーションにどう取り組むべきかを根本から変えます。新たなデジタル環境の勝者は、単に大量のコンテンツや高い検索順位を持つ者ではなく、機械が確実に理解・検証・推薦できる形で情報を構造化した者となるでしょう。
Case Lはモデルのパラメトリック知識ベースにある学習データのみを使用しますが、Case L+Oはこれに加えてリアルタイムのウェブ調査を行います。どちらの経路をとるかはモデルの信頼度閾値によって決まります。この違いは、外部ソースを評価し引用できるかどうかを左右するため非常に重要です。
この違いはエビデンス重み付けによって決まります。構造化データ、一貫した識別子、ドキュメント間での確認があるソースは「推薦」として格上げされ、単なる言及にとどまりません。検索結果に表示されても、証拠スコアが不十分な場合は推薦になりません。
構造化データ(JSON-LD、@id、sameAs、Q-ID)は証拠マトリクスで2~3倍高い重み付けを受けます。このマークアップによりエンティティのリンクやドキュメント間の検証が可能になり、信頼性スコアが劇的に向上します。Schema.orgを正しく実装しているソースは、権威ある引用先として選ばれる可能性が大幅に高くなります。
エンティティ認識とは、LLMが異なる団体や人物、概念などを識別・区別する方法です。一貫した命名や構造化識別子による明確なエンティティ特定は混乱を防ぎ、引用される確率を高めます。曖昧な参照はモデルの推論過程で埋もれてしまいます。
RAGシステムはリアルタイムでソースを取得・ランキングするため、引用選択がパラメトリック知識のみの場合より透明かつ証拠に基づくものになります。この明示的な取得メカニズムによって、AmICitedのようなモニタリングツールで追跡・分析可能な引用パターンが生まれます。
はい。Schema.orgマークアップの一貫した導入、明確なエンティティ識別子の設定、機械可読な証拠の作成、複数プラットフォームでのコンテンツ一貫性の維持、引用パターンのモニタリングが重要です。これらの要素が、LLMの回答内での言及または推薦獲得に直接影響します。
従来の可視性は検索結果での露出やランキングを測定します。AI可視性は、あなたのコンテンツがLLM推論過程で権威ある証拠として認識されているかを示します。検索で取得されることと、信頼できるものとして引用されることは異なり、後者には意味的明確性と構造的整合性が必要です。
AmICitedはGPT、Perplexity、Google AI OverviewsなどでAIシステムがあなたのブランドをどう参照するかを追跡。言及か推薦か、どのタイプのコンテンツが引用を誘発するか、各AIプラットフォーム間での引用パターンを可視化します。
独自の調査データとオリジナル統計がどのようにLLMから引用を集める磁石になるのかを解説します。AIの可視性を高め、ChatGPT、Perplexity、Google AI Overviewなどからより多く引用されるための戦略を学びましょう。...

戦略的なバックリンク獲得のためにLLMソースサイトを特定・ターゲットする方法を解説。どのAIプラットフォームが最も多くソースを引用しているかを知り、2025年のAI検索での可視性向上に向けてリンクビルディング戦略を最適化しましょう。...

LLMグラウンディングとウェブ検索によってAIシステムがリアルタイム情報へアクセスし、幻覚を減らし、正確な引用を提供できる仕組みを解説します。RAG、実装戦略、エンタープライズでの最適な運用方法を学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.