
PerplexityBot
PerplexityBotについて学びましょう。PerplexityのAI回答エンジンのためにコンテンツをインデックスするウェブクローラーです。その仕組みやrobots.txtへの対応、ウェブサイトでの管理方法を理解しましょう。...
1 分で読める

PerplexityBotクローラーの完全ガイド - 仕組みの理解、アクセス管理、引用の監視、Perplexity AIでの可視性の最適化までを解説。ステルスクローリングの懸念点やベストプラクティスも学べます。
PerplexityBotは、Perplexity AIによって開発された公式ウェブクローラーであり、PerplexityのAI検索結果にウェブサイトをインデックス化・表示するために設計されています。一部のAIクローラーが大規模言語モデルのトレーニング用データを集めるのとは異なり、PerplexityBotの主な目的は「ユーザーの質問に関連する答えを提供するウェブサイトを発見し、クロールしてリンクすること」です。クローラーは明確に定義されたユーザーエージェント文字列(Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; PerplexityBot/1.0; +https://perplexity.ai/perplexitybot))を使用して動作し、IPアドレス範囲も公開しているため、ウェブサイト運営者はクローラーのトラフィックを特定・管理できます。PerplexityBotが何をしているのかを理解しておくことは、自分のコンテンツのPerplexity回答エンジンでの可視性を制御し、サイトへのアクセスの透明性を保つうえで重要です。

PerplexityBotは標準的なウェブクローラーとして動作し、インターネット上のウェブページを継続的にスキャンして発見・インデックス化します。ウェブサイトにアクセスすると、まずrobots.txtファイルを読み込み、アクセス許可されたコンテンツを理解した上で、ページを体系的にクロールし内容を抽出・インデックスします。このインデックス情報はPerplexityの検索アルゴリズムに活用され、ユーザーの質問に対する引用付き回答の提供に使われます。ただし、Perplexityは異なる目的を持つ2種類のクローラーを運用しており、それぞれ独自のユーザーエージェントと挙動パターンを持ちます。これらの違いを理解することは、アクセス制御を細かく調整したいウェブサイト運営者にとって重要です。
| 機能 | PerplexityBot | Perplexity-User |
|---|---|---|
| 目的 | 検索結果や引用のためにウェブサイトをインデックス化 | ユーザーの質問にリアルタイムで特定ページを取得 |
| ユーザーエージェント文字列 | PerplexityBot/1.0 | Perplexity-User/1.0 |
| robots.txt遵守 | robots.txtのdisallow指示を尊重 | 通常robots.txtを無視(ユーザー主導リクエスト) |
| IPレンジ | perplexity.com/perplexitybot.jsonにて公開 | perplexity.com/perplexity-user.jsonにて公開 |
| 頻度 | 継続的かつ定期的なクロール | ユーザーのクエリごとにオンデマンド |
| 用途 | 検索インデックス構築 | 回答用の最新情報取得 |
この2種類のクローラーの違いは、robots.txtのルールやファイアウォール設定で個別に制御できるため重要です。PerplexityBotによる定期的なインデックスクロールはrobots.txt指示を尊重しますが、Perplexity-Userは特定ユーザーリクエストへの対応のため、robots.txtを回避する場合があります。いずれもIPアドレス範囲を公開しているため、ウェブサイト運営者は特定のクローラートラフィックを許可・ブロックする精密なファイアウォールルールを実装可能です。
2025年、Cloudflareは、Perplexityがウェブサイト制限を回避するために未宣言のクローラーを使用しているとする詳細な調査結果を発表しました。調査によれば、公式に宣言されたクローラー(PerplexityBotおよびPerplexity-User)がrobots.txtやファイアウォールでブロックされた場合、Perplexityは「Chrome on macOS」などの汎用的なブラウザユーザーエージェントや、異なるASN(Autonomous System Number)からのローテーションIPを使った追加クローラーを導入し、制限されたコンテンツへのアクセスを継続していたとのことです。この挙動は、透明性とウェブサイト運営者の意向尊重を重視するRFC 9309等のウェブクローリング基準に明確に反します。調査では、新規ドメインを作成し、robots.txtで明確にアクセス禁止ルールを設定したにもかかわらず、Perplexityがその内容に関する詳細な情報を提供したことから、未宣言データソースやステルスクローリングが行われている可能性が示唆されました。
この点は、OpenAIによるクローラー管理と著しく対照的です。OpenAIのGPTBotは明確に自身を識別し、robots.txtの指示を守り、ブロックされればクロールを停止します。つまり透明で倫理的なクローラー運用が実現可能であることを示しています。Cloudflareの調査結果は、Perplexityがウェブサイト運営者の意向を本当に尊重しているのかという懸念を強く喚起しました。特に自分のコンテンツをAIにインデックス化・引用されたくない運営者にとっては、クローラー挙動の監視や多層的な防御策(robots.txt、WAFルール、IPブロック)の重要性が浮き彫りになりました。
自サイトでPerplexityBotを許可するかどうかは、いくつかの重要な要素を秤にかけて判断する必要があります。一方で、クローラーを許可すれば自分のコンテンツがPerplexityの回答に引用され、AI回答を見たユーザーからのリファラル流入が期待できます。しかしその一方で、帯域幅消費やコンテンツの無断引用、情報利用のコントロール喪失などの正当な懸念もあります。最終的な判断は、ビジネス目標やコンテンツ戦略、AIによるデータ利用への許容度によって異なります。
PerplexityBotを許可する際の主なポイント:
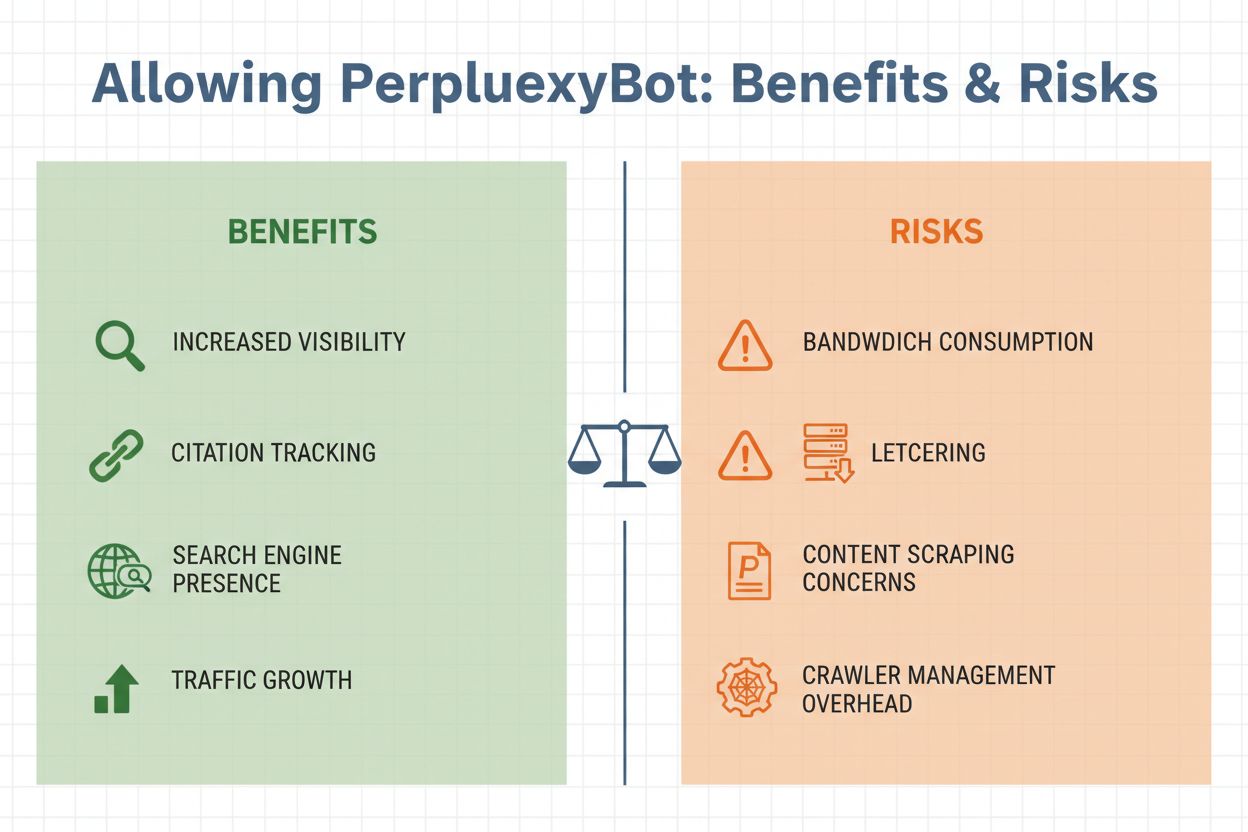
PerplexityBotへのアクセス管理は簡単で、技術基盤や要件に応じて複数の方法で実装できます。最も一般的なのはrobots.txtファイルを使う方法で、全ての良識あるクローラーに対しアクセス可能なコンテンツを明示できます。
robots.txtでPerplexityBotを許可するには:
User-agent: PerplexityBot
Allow: /
robots.txtでPerplexityBotをブロックするには:
User-agent: PerplexityBot
Disallow: /
特定ディレクトリのみブロックし、他は許可する場合は、より細かいルールを設定できます。
User-agent: PerplexityBot
Disallow: /admin/
Disallow: /private/
Allow: /public/
特にステルスクローリングが懸念される場合は、Web Application Firewall(WAF)レベルでのファイアウォールルール実装が有効です。Cloudflare WAFユーザーの場合、ユーザーエージェントとIPアドレス双方の条件でPerplexityBotをブロックするカスタムルールを作成できます。
AWS WAFユーザーは、https://www.perplexity.com/perplexitybot.jsonで公開されているIPレンジを使ったIPセットを作成し、それとPerplexityBotユーザーエージェントに一致するルールを作成します。正規のクローラートラフィックのため、IPレンジは必ず公式の最新情報を利用しましょう。
PerplexityBotの対応方針を決めたら、実際のクローラー挙動を監視することで、ルールが正しく機能しているか・インフラへの影響を把握できます。サーバーログで特徴的なユーザーエージェント(PerplexityBot/1.0や、ステルスクローリング時の汎用ブラウザエージェント)を検索することで、PerplexityBotのリクエストを特定できます。多くのウェブ解析ツールやログ分析ツールでは、ユーザーエージェント別にトラフィックをフィルタし、パターンを可視化できます。
監視すべき主な指標は、クロール頻度・アクセスページ・消費帯域幅などです。もし公開IPレンジ外からのアクセスや、機密ページの急速クロールなど異常な挙動があれば、ステルスクローリングの兆候かもしれません。さらにAmICited.comのような専門ツールを活用すれば、Perplexityを含むAIプラットフォーム全体で、自分のブランドやコンテンツがどのように引用・言及されているかも追跡できます。AIシステムにとってどのページが価値があるかを把握できるため、将来のクローラー管理方針やコンテンツ最適化にも役立ちます。
PerplexityBotを適切に管理するには、自社の利益とAIによる可視性の価値をバランスよく考慮する必要があります。まず明確な方針を策定しましょう。Perplexityで引用されることによるトラフィックやブランド露出の価値が、帯域幅消費やコンテンツ管理上の懸念より優先されるかどうかを判断し、その方針をrobots.txtに明記し、チーム内にも共有します。
次に、多層的な防御の実装です。PerplexityBotをブロックする場合、robots.txtだけに頼らず、WAFルールやIPブロックも組み合わせて多重防御を施しましょう。特にステルスクローリング問題が示すように、robots.txtだけでは不十分な場合もあります。三つ目はクローラー挙動の継続監視です。ログを定期的にチェックし、AIクローラーの倫理や透明性に関する業界動向を把握しましょう。新たなクローラーや戦術が登場する可能性もあるため、素早い方針変更が求められる場合もあります。
最後に、戦略的に監視ツールを活用し、決定の実際の効果を測定しましょう。AmICited.comのようなツールを使えば、AIが自社コンテンツをどう引用しているか可視化され、PerplexityBotを許可した場合に期待通りの可視性が得られているかが分かります。許可しているなら引用最適化のヒントに、ブロックしているならブロックが有効で他経路での引用が起きていないかの確認にも役立ちます。
PerplexityBotは、様々な目的や透明性基準を持つAIクローラーが乱立する中で運用されています。OpenAIのGPTBotは、透明なクローラー運用の模範例として広く認知されており、明確に自身を識別・robots.txtを遵守・ブロック時にはクロールを停止します。GoogleのAI Overviews等のクローラーも同様に透明性とウェブサイト運営者の意向を尊重しています。一方、Cloudflareが記録したPerplexityのステルスクローリングは、これら標準から逸脱する懸念すべき事例です。
最大の違いは透明性と運営者意向の尊重にあります。GPTBotのような良識的なクローラーは、運営者が挙動を理解しやすく、制御手段も明確です。Perplexityの未宣言クローラーやIPローテーションによる制限回避は、この信頼を損なう行為です。ウェブサイト運営者は、Perplexityの公表方針を鵜呑みにせず、希望が確実に反映されるよう強固な技術的対策を講じるべきでしょう。AIクローラーのエコシステムが成熟するにつれ、Perplexityのような企業にも、ウェブ標準に準拠し運営者の自律性を尊重する、より透明で倫理的な運用が求められていくでしょう。
PerplexityBotはPerplexity AIの公式ウェブクローラーで、ウェブサイトをインデックス化し、PerplexityのAI検索結果に表示するために設計されています。一部のAIクローラーがトレーニング目的でデータを収集するのとは異なり、PerplexityBotはユーザーの質問に関連する答えを提供するウェブサイトを発見し、リンクすることに特化しています。公開されたユーザーエージェント文字列とIPアドレス範囲を用い、透明性を持って動作します。
いいえ。Perplexityの公式ドキュメントによると、PerplexityBotは検索結果でウェブサイトを表示・リンクするために設計されており、AI基盤モデルやトレーニング目的でコンテンツをクロールするためのものではありません。このクローラーの唯一の機能は、Perplexityの回答エンジン用のインデックス作成です。
robots.txtファイルに「User-agent: PerplexityBot」と「Disallow: /」を追加することで、全アクセスを防ぐことができます。さらに強力な対策としては、CloudflareやAWS WAFでPerplexityBotのユーザーエージェントやIPレンジに一致するリクエストをブロックするWAFルールを実装できます。ただし、ステルスクローリングによってこれらの制御が回避される可能性があることに注意してください。
PerplexityはPerplexityBotの公式IPアドレスレンジをhttps://www.perplexity.com/perplexitybot.json、Perplexity-Userのレンジをhttps://www.perplexity.com/perplexity-user.jsonで公開しています。これらのレンジは定期的に更新されるため、ファイアウォールやWAF設定には必ず公式エンドポイントを使いましょう。古いIPリストではなく、常に公式情報を利用してください。
PerplexityBotはrobots.txtの指示に従うと主張していますが、Cloudflareの2025年の調査では、未宣言のユーザーエージェントやローテーションされたIPアドレスを使い、robots.txtの制限を回避してステルスクローリングを行っている証拠が見つかりました。宣言されたPerplexityBotクローラーは基本的にrobots.txtを尊重しますが、希望を厳守したい場合はWAFによる追加保護を推奨します。
帯域幅の使用量はサイトの規模やコンテンツ量により異なります。PerplexityBotはGoogleのクローラーと同様に継続的かつ定期的にクロールします。トラフィックの多いサイトでは、帯域幅消費が顕著になる場合があります。サーバーログでPerplexityBotのリクエストをフィルタリングし、データ転送量を分析することで、インフラへの影響を把握できます。
はい。自分のコンテンツに関連するクエリをPerplexityで手動検索し、回答内でサイトが引用されているか確認できます。より包括的に監視したい場合は、AmICited.comのようなツールを活用することで、Perplexityを含むAIプラットフォーム全体であなたのブランドやコンテンツがどのように表示されているか、リアルタイムで可視化できます。
PerplexityBotは定期的にウェブサイトをクロールして検索インデックスを構築するクローラーです。Perplexity-Userは、ユーザーが質問した際にリアルタイムで特定ページを取得するためにオンデマンドで動作します。PerplexityBotはrobots.txtを尊重しますが、Perplexity-Userはユーザーリクエストの性質上、通常robots.txtを無視します。両者は別々のユーザーエージェント文字列とIPレンジを持っています。
PerplexityBotについて学びましょう。PerplexityのAI回答エンジンのためにコンテンツをインデックスするウェブクローラーです。その仕組みやrobots.txtへの対応、ウェブサイトでの管理方法を理解しましょう。...

GPTBot、PerplexityBot、ClaudeBotなどのAIボットによるサイトクロールの許可方法を解説します。robots.txt・llms.txtの設定やAI向け最適化の方法もわかります。...
サーバーログ、ユーザーエージェントの特定、技術的な修正でAIクロールの問題をデバッグ。ChatGPT、Perplexity、Claudeクローラーを監視し、アクセス問題を解決します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.