
差別的クローラーアクセス
ビジネス目標に基づきAIクローラーを選択的に許可・ブロックする方法を解説。差別的クローラーアクセスを実装し、コンテンツを保護しつつAIシステムでの可視性を維持。GPTBot、ClaudeBotなどAIクローラーを管理するパブリッシャー向けの戦略ガイド。...
1 分で読める

robots.txtを使って、どのAIボットがあなたのコンテンツにアクセスできるかをコントロールする方法を学びましょう。GPTBot、ClaudeBot、その他のAIクローラーをブロックするための実践的な例と設定戦略を網羅した完全ガイドです。
ここ2年でウェブクローリングの状況は根本的に変化し、従来の検索エンジンによるインデックス作成から、AIモデル学習という複雑な世界へと進化しました。GoogleのGooglebotが長らく予測可能な訪問者だったのに対し、現在はまったく異なる意図と消費パターンを持つ新世代のクローラーがやってきています。OpenAIのGPTBotは約1,700:1というクロール・リファー比率を示し、1,700ページをクロールしてようやく1回だけサイトにリファーラルを返す一方、AnthropicのClaudeBotはさらに極端な73,000:1という比率で動作します。これは、クロール活動が実際のトラフィックに結びつくGoogleの14:1とは大きく異なります。この根本的な違いにより、コンテンツ制作者にとって緊急のビジネス判断が求められます。ボットに無制限アクセスを許せば、あなたのコンテンツはAIモデルの学習に使われ、結果的に自分のトラフィックや収益と競合するAIが生まれますが、見返りのトラフィックや報酬はほとんどありません。今やパブリッシャーはAIボットのアクセスを許可する価値命題が自社のビジネスモデルに合致するかどうかを積極的に判断する必要があり、robots.txtの設定は単なる技術的選択ではなく、戦略的ビジネス課題となっています。
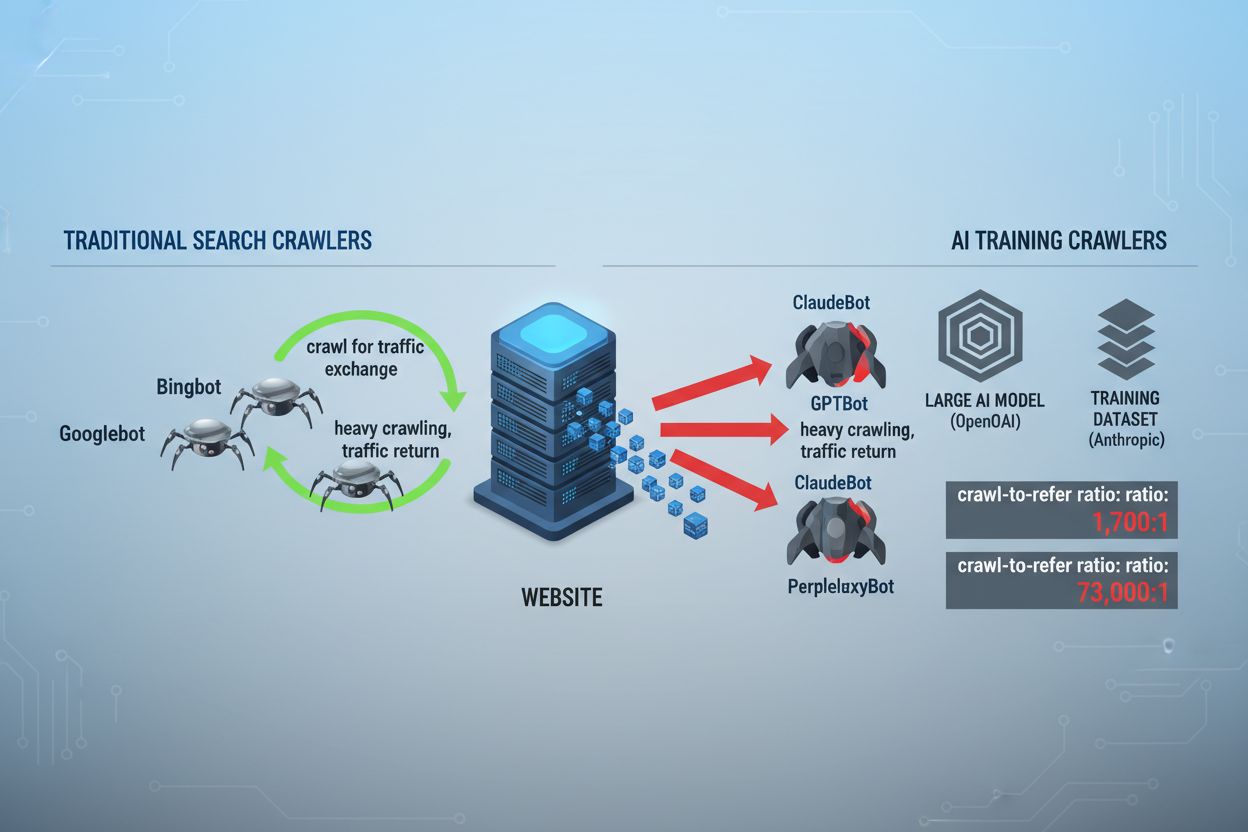
AIクローラーは大きく3つのカテゴリに分かれ、それぞれ目的もブロック戦略も異なります。1つ目は基礎AIモデルの学習のために大量のコンテンツを収集する「学習クローラー」で、OpenAIのGPTBot、AnthropicのClaudeBot、GoogleのGoogle-Extended、PerplexityのPerplexityBot、MetaのMeta-ExternalAgent、AppleのApplebot-Extended、Amazonbot、Bytespider、cohere-aiなどが該当します。2つ目はAI検索体験のための「検索クローラー」で、これらは通常トラフィックをパブリッシャーに返します(OpenAIのOAI-SearchBot、AnthropicのClaude-Web、Perplexityの検索機能など)。3つ目はユーザーの明示的なリクエスト時のみアクセスする「ユーザー起動型エージェント」で、ChatGPT-UserやClaude-Webのような実際のユーザー操作によるインタラクションが該当します。この分類を正しく理解することが重要です。なぜなら、ビジネス上の優先順位に応じて、トラフィックをもたらす検索クローラーは歓迎し、対価のない学習クローラーはブロックする、といった戦略的な設定が可能になるからです。主要AI企業は各自で専用クローラーを運用し、違いは主にユーザーエージェント文字列で判別されるため、正確な識別とターゲットを絞ったブロックがrobots.txt設定の成否を分けます。
| 企業 | 学習クローラー | 検索クローラー | ユーザー起動型エージェント |
|---|---|---|---|
| OpenAI | GPTBot | OAI-SearchBot | ChatGPT-User |
| Anthropic | ClaudeBot, anthropic-ai | Claude-Web | claude-web |
| Google-Extended | — | (標準Googlebotを使用) | |
| Perplexity | PerplexityBot | PerplexityBot | Perplexity-User |
| Meta | Meta-ExternalAgent | — | Meta-ExternalFetcher |
| Apple | Applebot-Extended | — | Applebot |
効果的なrobots.txt設定のためには、AIボットのユーザーエージェントリストを正確かつ最新に保つことが不可欠です。しかしこの分野は、新モデルの登場や企業の戦略変更により、非常に速いペースで進化しています。主要な学習クローラーには、GPTBot(OpenAI)、ClaudeBot(Anthropic)、anthropic-ai(Anthropicの別ID)、Google-Extended(GoogleのAI学習用トークン)、PerplexityBot、Meta-ExternalAgent、Applebot-Extended、CCBot(Common Crawl)、Amazonbot、Bytespider(ByteDance)、cohere-ai(Cohere)、DuckAssistBot(DuckDuckGo)、YouBot(You.com)などがあります。検索向けクローラーにはOAI-SearchBot、Claude-Web、PerplexityBot(検索モード時)などが含まれます。問題は、このリストが決して固定ではないことです。新しいAI企業が次々に誕生し、既存企業も新製品用のクローラーを投入し、ユーザーエージェント文字列も時折変更や拡張が行われます。パブリッシャーはrobots.txtを「生きたドキュメント」として、四半期ごとに見直し・更新し、業界トラッキング情報の購読やサーバーログで未知のユーザーエージェントを監視することが必要です。ユーザーエージェントリストの更新を怠ると、意図せず新しい学習クローラーのアクセスを許したり、本来許可したかった検索クローラーまでブロックしてしまうリスクがあります。
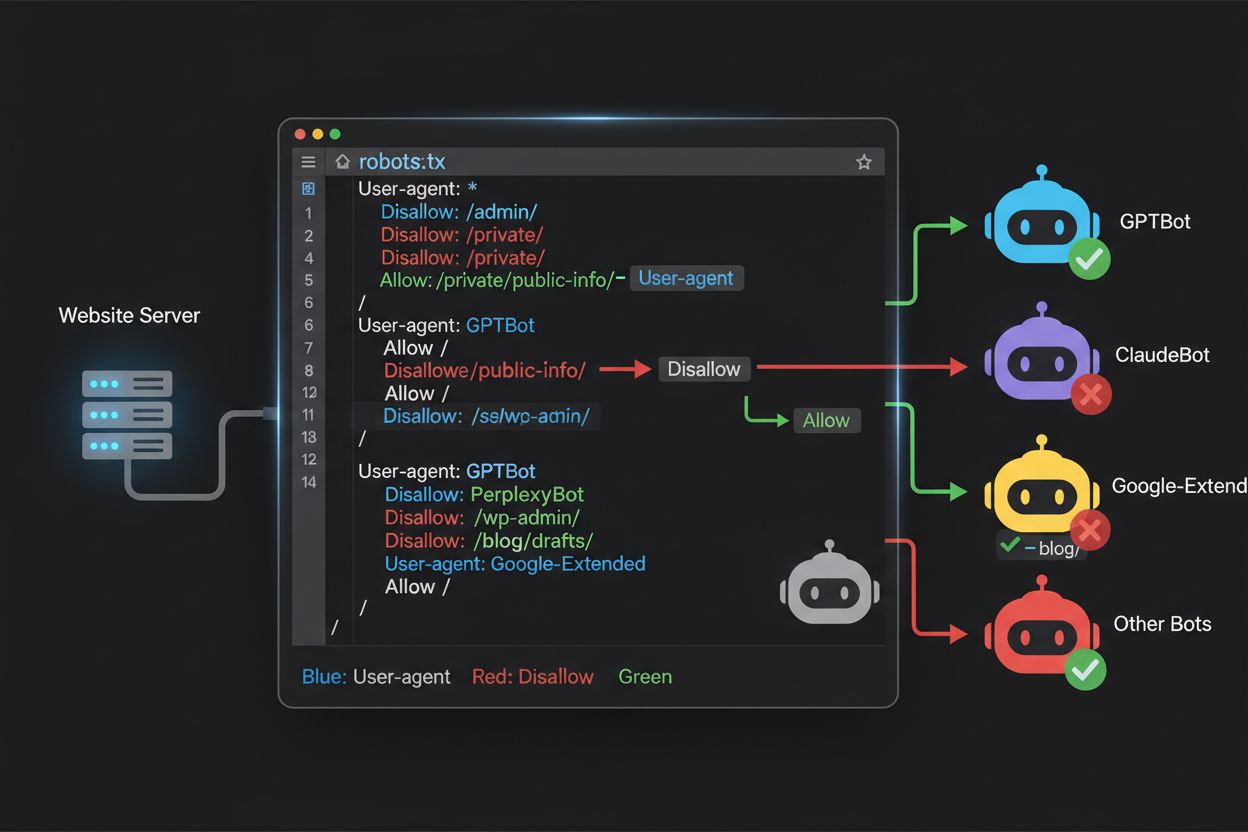
robots.txtファイルはドメインルート(yourdomain.com/robots.txt)に配置し、プロトコルを守るボットに対してクロールの希望を伝えるシンプルな構文を持ちます。各ルールはUser-Agentディレクティブで対象ボットを指定し、続くDisallowディレクティブでボットがアクセスできないパスを示します。従来の検索エンジンにはアクセスを許可しつつ、主要なAI学習クローラーだけをブロックするには、ブロックしたい各クローラー(GPTBot、ClaudeBot、anthropic-ai、Google-Extended、PerplexityBot、Meta-ExternalAgent、Applebot-Extendedなど)ごとにUser-Agentブロックを作り、それぞれ"Disallow: /“で全ページへのアクセスを拒否します。同時に、GooglebotやBingbot、検索用OAI-SearchBotなど正規の検索クローラーはブロックしないようにして、引き続きコンテンツのインデックス化とトラフィック獲得を維持します。robots.txtにはまた、XMLサイトマップへのSitemap参照も記載しておくことで、検索エンジンによる効率的なクロールを促進できます。設定ミスは致命的です。1つの構文ミスや文字の誤り、ユーザーエージェント名の間違いで、望まぬクローラーの侵入や正規トラフィックの喪失につながります。公開前のテストは絶対に欠かせません。
# AI学習クローラーをブロック
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
User-agent: Applebot-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: DuckAssistBot
Disallow: /
User-agent: YouBot
Disallow: /
# 従来型検索エンジンは許可
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# サイトマップ参照
Sitemap: https://yoursite.com/sitemap.xml
多くのパブリッシャーは、「AI検索結果には掲載されたいが、コンテンツを学習用に使われたくはない」という微妙な判断を迫られます。この選択的戦略では、同じ企業の中でも検索用クローラーと学習クローラーを区別して設定します。例えば、OpenAIのOAI-SearchBot(ChatGPTの検索機能用でトラフィックを返す)は許可し、GPTBot(学習用)はブロックします。同様に、PerplexityBotの検索クローラーは許可し、学習用の動作は拒否、Claude-Webはユーザー検索用に許可し、ClaudeBotの学習活動はブロックします。検索クローラーは一般的にクロール・リファー比率が低く、実際にトラフィックを返す設計ですが、学習クローラーは大量のコンテンツを消費し、見返りはほぼありません。このアプローチには、企業側の戦略やユーザーエージェントの変更に応じた継続的な監視が求められます。サーバーログを定期的に監査し、意図したクローラーがアクセスしているか、ブロックが正しく機能しているかを確認し、AI業界の変化や新規参入に合わせてrobots.txtを調整しましょう。
# AI検索クローラーを許可
User-agent: OAI-SearchBot
Allow: /
User-agent: Perplexity-User
Allow: /
User-agent: ChatGPT-User
Allow: /
# 学習クローラーをブロック
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
User-agent: Meta-ExternalAgent
Disallow: /
経験豊富なウェブ担当者でも、robots.txtの設定ミスにより本来ブロックしたかったクローラーを無防備にしてしまうことが珍しくありません。まず多いのは、User-Agent行だけを書き、続くDisallowディレクティブを書き忘れるパターンです(例:“User-Agent: GPTBot” のみ記載し、何をDisallowするか書かない)。この場合、ボットは完全に許可された状態になります。次に、ファイルの設置場所や名前、大文字小文字の間違いがよく見られます。ファイル名は必ず “robots.txt”(小文字)とし、ドメイン直下に配置、HTTPステータス200で提供する必要があります。サブディレクトリや"Robots.txt”、“robots.TXT"などは認識されません。ルールブロック内の空行も誤りです。多くのrobots.txtパーサーは空行でルールの区切りと判断し、後続ディレクティブが無効化されます。さらに、URLパスの大文字小文字のミスも多発します。ユーザーエージェント名は大文字小文字を区別しませんが、Disallowパスは区別します(例:“Disallow: /Admin"では”/admin"や”/ADMIN"はブロックされません)。ワイルドカードの誤用にも注意が必要です。アスタリスク(*)は任意の文字列に一致しますが、“Disallow: .pdf"ではなく"Disallow: /.pdf"や"Disallow: /*pdf"のように正しく記述しましょう。複数のDisallowが矛盾したり、クエリパラメータやURLパターンを考慮せずに複雑化しすぎると、意図しないコンテンツ開放やブロックにつながります。公開前には専用バリデーターで必ず構文チェックをしましょう。
よくあるミス例:
Google-Extendedは他のクローラーとは異なり、従来のボットではなく「コントロールトークン」として機能します。この違いを理解することが、適切なブロック判断には不可欠です。GooglebotがあなたのサイトをクロールしGoogle検索用にインデックスするのに対し、Google-ExtendedはコンテンツがGoogleのGemini AIモデル学習やAI Overview生成に使われるかどうかをコントロールします。Google-Extendedをブロックすると、Geminiの学習やAI Overview生成への利用は防げますが、従来の検索結果への掲載(Googlebotによるインデックス)は影響を受けません。この判断は大きな意味を持ちます。Google-ExtendedをブロックすればAI Overviewにコンテンツが掲載されなくなり、AI経由の新たなトラフィック機会は減りますが、Geminiによる競合AIの学習対象からは外れます。逆に許可すれば、AI Overview経由でトラフィックが得られる可能性がある一方、自社コンテンツがGeminiの学習素材となり将来的に競合リスクも生じます。直帰トラフィック依存や独自収益モデルを持つニュースサイト等はGoogle-Extendedをブロックする利点がありますが、AI経由の可視性や流入を重視する場合は許可も選択肢です。どちらにせよ、デフォルトではなく意図的にこの判断を下すことが重要です。
robots.txtは公開前のテストが絶対に必要です。設定ミスは検索可視性やコンテンツ保護戦略に長期的な悪影響を及ぼします。Google Search Consoleには組み込みのrobots.txtテスターがあり、特定のユーザーエージェントとURLの組み合わせでアクセス可否を検証できます(例:“GPTBot"とパスを入力するとブロック・許可状況が分かる)。Merkle Robots.txt Testerも、個別クローラーの動作解説が充実した便利なツールです。TechnicalSEO.comもGoogleのオープンソースパーサーを使い、正確な検証が可能です。さらにKnowatoa AI Search Consoleでは、AIクローラー24種以上に対する設定の検証や、AIクローラーの実際の動きを監視できます。検証ワークフローとしては、まずステージング環境でrobots.txtをアップロードし、公開したい重要ページがブロックされていないか、意図したAIボットが正しく除外されているか、サーバーログでクローラー動作に異常がないかを確認しましょう。Sitemap参照の正当性や検索エンジンの通常アクセスも併せてチェックします。AI学習クローラーだけをブロックし、正当な検索トラフィックは確保することが理想です。十分なテスト後に本番環境へ公開し、公開後も最初の1週間はログ監視を続けましょう。
テストツール:
robots.txtは有効な第一防衛線ですが、基本的に「善意のボットのみが守る紳士協定」であることを理解しておきましょう。悪意ある、または設計不良なクローラーはrobots.txtを無視してアクセスしてきます。業界データでは、robots.txtは不要なクローラーの約40〜60%をブロックできる一方、残り40〜60%は無視または回避設計されています。より強固な保護が必要な場合は追加対策が必須です。CloudflareのWeb Application Firewall(WAF)は、ユーザーエージェントやIPアドレス、行動パターンによるブロックができ、robots.txtを無視するボットにも対応します。Apacheサーバーの.htaccessやNginxの設定でも、特定ユーザーエージェントやIPレンジをサーバーレベルで遮断可能です。IPブロックは特定クローラーのIPレンジを把握できれば有効ですが、クローラーインフラの変化に伴い継続的な管理が求められます。Fail2banなどの自動ツールは、不自然な速度やパスへのアクセスを検知し自動遮断できます。ただし、これら追加対策は慎重な設定が必要です。過剰なブロックは正規ユーザー(VPN利用や企業プロキシ経由)が巻き込まれる危険もあります。robots.txtによる「要請」、サーバーレベルのユーザーエージェント遮断、不審行動の監視という多層防御が推奨されます。各層を段階的に実装し、正当なトラフィックを妨げていないか都度検証しましょう。
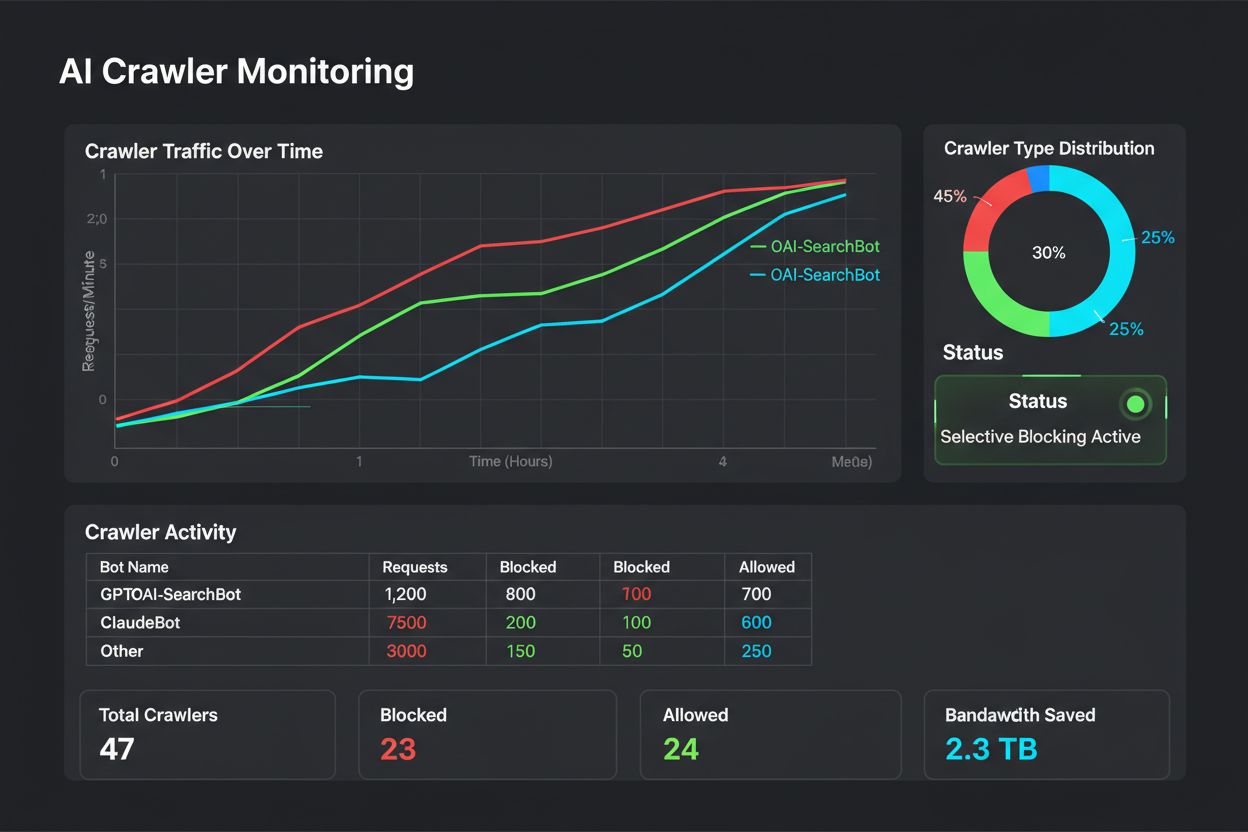
robots.txt設定の有効性を確認し、新規クローラーを特定するためには、実際に何がサイトにアクセスしているかを把握することが不可欠です。サーバーログ分析がその主な方法です。ApacheやNginxなどのアクセスログには、ユーザーエージェント、IPアドレス、タイムスタンプ、リクエストリソースすべてが記録されています。コマンドラインのgrepを使えば、特定ユーザーエージェントのリクエストだけ抽出できます(例:“grep ‘GPTBot’ /var/log/apache2/access.log”)。さらに進んだ分析では、各ボットのクロール頻度やアクセスページ、robots.txt遵守状況まで把握できます。自動監視システムを導入すれば、新規や異常なクローラーが現れた際に即時アラートを受け取れます。複数サーバー環境ではELK StackやSplunkなどのログ集約サービスを使い、ボット活動を一元管理するパブリッシャーも珍しくありません。AIクローラーの世界は日々変化しているため、監視も一度きりではなく、定期的(週次・月次)なログレビューをルーティン化し、変化に先回りしてrobots.txtを調整しましょう。
AIクローラー向けrobots.txt設定は本質的に「収益判断」であり、他の重大なビジネス意思決定と同等の重みをもって検討すべきです。学習クローラーに無制限でアクセスを許すということは、あなたのコンテンツがAIモデルの学習に使われ、それが将来的にあなたのトラフィックや収益と競合することを意味します。特にダイレクトトラフィックや広告収益に依存するビジネスモデルでは、競合製品のために無償で学習素材を提供してしまうことになります。一方、すべてのAIクローラーをブロックすれば、AI検索やAIアシスタント経由の新たな流入も失うことになります。最適な戦略はビジネスモデル次第です。広告型パブリッシャーなら検索クローラーのみ許可し、学習クローラーはブロックすることでトラフィックと広告収益を維持。サブスクリプション型なら、AIによる要約や転載を防ぐためより強くブロックするのが有効でしょう。ブランド認知やリーダーシップ重視ならAI検索への掲載自体を重視することもあります。重要なのは、何も設定しない=暗黙のうちに全ボットを許可してしまい、意図せずAI学習に貢献しているパブリッシャーが多いという点です。また、AIシステムにコンテンツが使われた際に正しい帰属がなされるよう、schemaマークアップの導入も検討しましょう。robots.txtは、定期的に見直し・更新し、AI業界や自社優先度の変化に合わせて戦略的に管理すべきです。
AIクローラーの世界は未曾有のスピードで変化しています。新規参入企業の登場、新しいクローラーの投入、ユーザーエージェント名の変更や拡張は日常茶飯事です。robots.txtは「設定して終わり」ではなく、最低でも四半期ごとに見直す「生きたファイル」として運用しましょう。新クローラーの業界発表を定期的にチェックし、関連ニュースレターやブログを購読、サーバーログで未知のユーザーエージェントを見つけたら、ボットの目的やビジネスモデルを調査し、必要に応じてrobots.txtを更新してください。加えて、クローラーのトラフィック量やクロール・ユーザー比率、検索可視性やAI検索経由の流入変化なども定期的にモニターしましょう。実際のデータによって最適戦略は変化します。特定クローラーのブロックが想定外の結果をもたらしたり、逆に許可することで新しい価値が得られることもあります。仮説ではなく実績データで戦略を柔軟にアップデートしましょう。また、robots.txt方針はSEO、コンテンツ、経営陣など社内関係者にも説明し、全社的に整合性のある運用を心がけてください。こうした日常的な管理と意思疎通こそが、AI時代のコンテンツ保護とビジネス目標の両立に繋がります。
いいえ。GPTBot、ClaudeBot、CCBotなどのAI学習クローラーをブロックしても、GoogleやBingの検索順位には影響しません。従来の検索エンジンは独立したクローラー(Googlebot、Bingbotなど)を使用しており、これらをブロックしない限り、検索結果から完全に消えることはありません。
OpenAI(GPTBot)、Anthropic(ClaudeBot)、Google(Google-Extended)、Perplexity(PerplexityBot)などの大手クローラーは、robots.txtの指示を守ると公式に表明しています。しかし、小規模または透明性の低いボットは設定を無視する場合もあり、そのため多層的な保護戦略が必要となります。
戦略次第です。学習クローラー(GPTBot、ClaudeBot、CCBot)のみブロックすれば、AIモデルの学習からコンテンツを守りながら、検索向けクローラーによってAI検索結果への掲載は可能です。完全にブロックするとAIエコシステムからも外れます。
最低でも四半期ごとに設定を見直してください。AI企業は定期的に新しいクローラーを導入しています。Anthropicは「anthropic-ai」と「Claude-Web」を「ClaudeBot」に統合し、ルール未更新サイトへの一時的な無制限アクセスを認めていました。
robots.txtはドメインのルートに配置し、すべてのページに一括で適用されます。一方、meta robotsタグは個々のページのHTML内ディレクティブです。robots.txtは最初にチェックされ、クローラーがページにアクセスする前に制御でき、metaタグはページにアクセスされた場合のみ読まれます。包括的なコントロールには両方を活用しましょう。
はい。robots.txtでパスを指定したDisallowルール(例:「Disallow: /premium/」でプレミアムコンテンツのみブロック)や、個別ページにmeta robotsタグを使うことができます。これにより、重要なコンテンツは守り、他のエリアへのクローラーのアクセスは許可できます。
ボットがrobots.txtを無視した場合、.htaccessによるサーバーレベルのブロック、IPブロック、WAFルールなど追加の保護手段が必要になります。robots.txtは望ましくないクローラーの約40〜60%を阻止しますが、多層的な防御が包括的な対策には重要です。
Google Search Consoleのrobots.txtテスター、Merkle Robots.txt Tester、TechnicalSEO.comなどのテストツールで設定を検証できます。また、サーバーログを監視し、ブロックしたボットが除外され、許可したボットがアクセスしていることを確認しましょう。
robots.txtはあくまで第一歩に過ぎません。AmICitedを使って、どのAIシステムがあなたのコンテンツを引用しているか、どのくらいの頻度で参照されているかを追跡し、GPT、Perplexity、Google AI Overviewsなどで適切な帰属表示がなされているかを確認しましょう。
ビジネス目標に基づきAIクローラーを選択的に許可・ブロックする方法を解説。差別的クローラーアクセスを実装し、コンテンツを保護しつつAIシステムでの可視性を維持。GPTBot、ClaudeBotなどAIクローラーを管理するパブリッシャー向けの戦略ガイド。...
AIトレーニングボットからコンテンツを守りつつ、AI検索結果での可視性を維持するための選択的AIクローラーのブロック方法を解説。パブリッシャー向けの技術的戦略。...

GPTBot、PerplexityBot、ClaudeBotなどのAIボットによるサイトクロールの許可方法を解説します。robots.txt・llms.txtの設定やAI向け最適化の方法もわかります。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.