
どのスキーママークアップがAI検索に役立つ?2025年完全ガイド
ChatGPT、Perplexity、GeminiなどのAI検索エンジンでの可視性を高めるスキーママークアップタイプを発見しましょう。AI回答生成器向けJSON-LD実装戦略も学べます。...
1 分で読める

AIでの可視性に最も重要なスキーマタイプを学びましょう。LLMが構造化データをどのように解釈するか、AIの回答でブランドが引用されるためのスキーママークアップ戦略をご紹介します。
長年、スキーママークアップはリッチリザルト獲得――伝統的な検索結果に表示される星評価や商品カード、FAQアコーディオンなど――が主な目的でした。しかし今日、この戦略は時代遅れとなりつつあります。大規模言語モデルやAI回答エンジンは、スキーママークアップを根本的に異なる方法で解釈し、見た目の装飾ではなく、ナレッジグラフの構築やエンティティ関係の大規模な理解に利用します。現在、約4,500万のウェブサイト(登録ドメイン全体の12.4%)が何らかのschema.orgマークアップを実装しており、AIシステムは学習・依拠できる前例のない量の構造化データにアクセスできるようになっています。この変化は大きく、スキーママークアップは今や「AI生成回答でブランドが引用されるかどうか」「モデルが商品やサービスをどれだけ正確に表現するか」「AI中心の検索環境であなたのコンテンツが信頼されるソースとなれるか」に直接影響を及ぼしています。
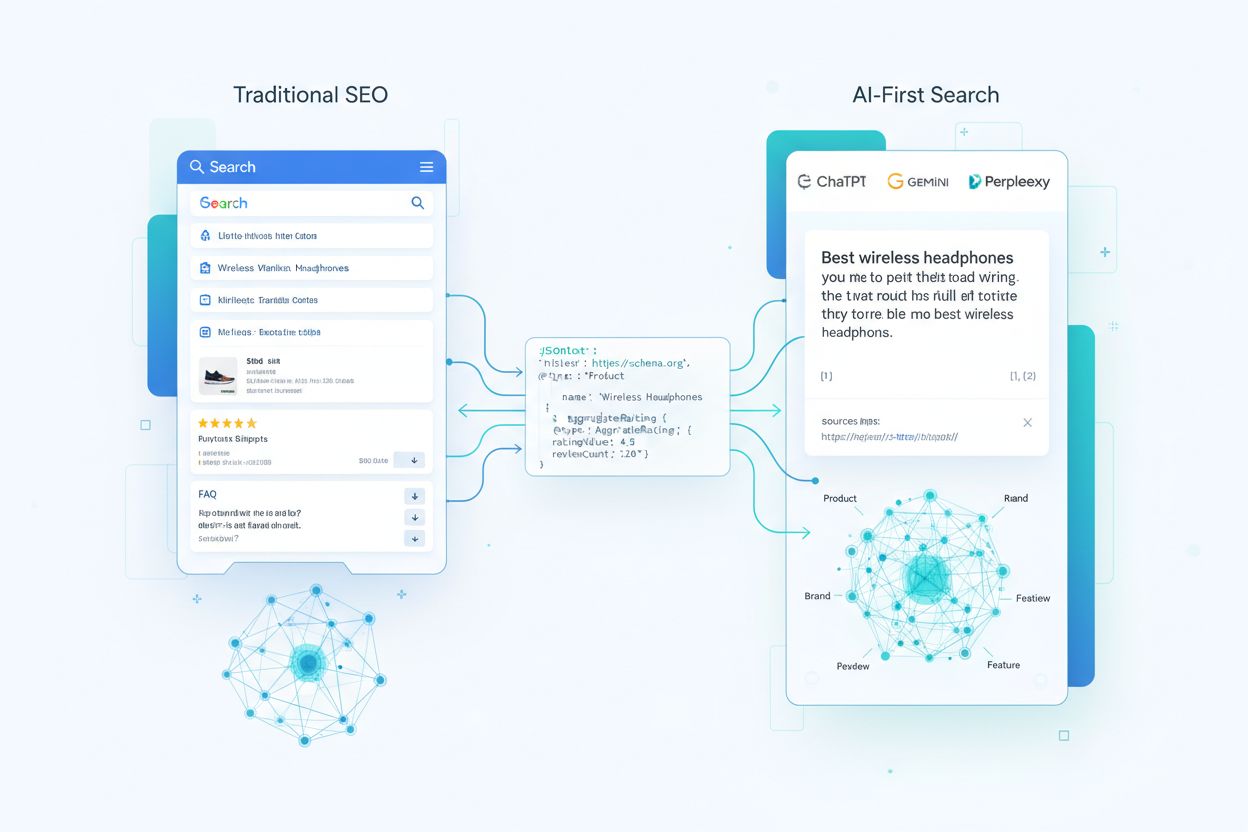
AIシステムがスキーママークアップをどのように消費しているかを理解するには、あなたの構造化データがクロールからLLM生成回答に至るまでの流れを追う必要があります。クローラーがページにアクセスすると、JSON-LD、microdata、RDFaのブロックを抽出し、非構造化テキストやメディアとともにインデックス化・正規化します。この構造化データはウェブスケールのナレッジグラフの一部となり、エンティティ同士は関係性で結ばれ、意味検索用の埋め込み(embedding)が割り当てられます。検索拡張生成(RAG)システムでは、スキーマがベクターインデックスを構成するチャンクに直接折り込まれることもあります――一つのチャンクに商品説明とJSON-LDマークアップの両方が含まれ、モデルはナラティブな文脈と構造化されたキー・バリュー属性の両方を得られます。LLMのアーキテクチャによってスキーマの消費方法は異なり、既存の検索インデックスやナレッジグラフの上にモデルを重ねるものもあれば、構造化・非構造化両方のコンテンツから引き出すマルチソースリトリーバル型もあります。重要なのは、適切に実装されたスキーマはモデルとの契約書のような役割を果たし、ページ上のどの事実が公式で信頼できるものかを構造化した形で明示できる点です。
| アーキテクチャタイプ | スキーマ活用方法 | 引用への影響 | 主なプロパティ |
|---|---|---|---|
| 従来検索+LLMレイヤー | 既存ナレッジグラフを強化 | 高:構造化されたソースが引用されやすい | Organization, Product, Article |
| 検索拡張生成 | ベクターチャンクに組み込み | 中~高:スキーマが精度向上に寄与 | 詳細なプロパティを含む全タイプ |
| マルチソース回答エンジン | エンティティ解決に使用 | 中:他のシグナルと競合 | Person, LocalBusiness, Service |
| 会話型AI | 文脈理解を補助 | 変動:学習データ次第 | FAQPage, HowTo, BlogPosting |
AI時代において、すべてのスキーマタイプが同等に重視されるわけではありません。Organizationマークアップはエンティティグラフ全体のアンカーとなり、ブランドのアイデンティティ・権威・関係性をモデルに伝えます。ProductスキーマはECや小売で不可欠で、AIシステムが特徴・価格・評価を各ソース間で比較できるようにします。ArticleやBlogPostingマークアップは、説明的なクエリや専門的見解を要する長文コンテンツの判別に役立ちます。Personスキーマは、AI生成回答で著者の信頼性や専門性を確立するのに重要です。FAQPageマークアップは、AIアシスタントが対応すべき会話型クエリと直接マッピングします。SaaSやB2Bの場合はSoftwareApplicationやServiceタイプも同様に重要で、「Xに最適なツール」比較や機能評価で頻繁に登場します。ローカルビジネスや医療機関ではLocalBusinessやMedicalOrganizationタイプが地理的精度や規制遵守の明確化に役立ちます。真の差別化は、単なるタイプ採用に留まらず、ページ横断の一貫性、明確なエンティティID、関係性の明示的マッピングなど高度なプロパティをどれだけ積み重ねられるかにあります。
name、description、URLといった基本的なスキーマプロパティはもはや必須条件であり、Googleの1ページ目にランクインしているページの72.6%が何らかのスキーマを既に使用しています。AI可視性で真の差別化を生むのは、モデルがエンティティを解決し、関係性を理解し、意味を曖昧さなく捉えるための「つながりとなる」プロパティです。特に重要な高度プロパティは以下です:
これらのプロパティは、スキーマを単なるデータコンテナから、モデルが自信を持って航行可能な意味マップへと変貌させます。たとえば、sameAsで組織をWikipediaページにリンクすれば、単なるメタデータ追加ではなく「これが私たちについての公式情報源」とモデルに伝えているのです。additionalPropertyで商品仕様やサービス機能をエンコードすれば、AIシステムが比較や推奨を組み立てる際に必要とする正確な属性を提供できます。
多くの組織はスキーママークアップを一度きりの実装タスクと捉えがちですが、AI主導の検索で競争優位を築くには、継続的なデータガバナンスの一環として考える必要があります。有用なフレームワークは、現状と目指すべき地点を認識できる4段階の成熟度モデルです:
レベル1 – 基本的なリッチリザルトスキーマは、限定的なテンプレートに最小限のマークアップを施し、主に星・商品カード・FAQスニペットの表示を目的とします。ガバナンスが緩く、一貫性も低く、狙いは意味的明確化より見た目の強化です。
レベル2 – エンティティ中心のカバレッジは、主要テンプレートでOrganization、Product、Article、Personマークアップを標準化し、@id値の一貫使用と、sameAsリンクの追加でエンティティ混同を防ぎます。
レベル3 – ナレッジグラフ統合スキーマは、スキーマIDをCMS・PIM・CRMなど内部データモデルと連携し、about/mentions/additionalTypeプロパティも多用、ページ間の関係性もエンコードしてモデルがコンテンツノード同士や外部エンティティとの関係を理解できるようにします。
レベル4 – LLM最適化・RAG連携スキーマは、会話型クエリやAIスニペット形式に最適化した構造、内部RAGパイプラインと連動したスキーマ設計、計測と改善サイクルの組み込みを特徴とします。
多くのブランドは現在レベル1~2で足踏みしており、もはや「基本的実装」は衛生要因であり差別化要因ではありません。レベル3~4まで到達することで、スキーマLLM最適化が持続的競争優位となり、モデルが多様なクエリや表示面であなたのエンティティを確実に解釈できるようになります。
業界ごとにエンティティの種類・リスクプロファイル・ユーザー意図は異なるため、高度なスキーマ活用は一律ではありません。エンティティの明確化・関係性モデリング・ページ内容との整合性というコア原則は共通ですが、強調すべきスキーマタイプやプロパティは実際の検索行動に合わせるべきです。
EC・小売業では、主なエンティティはProduct、Offer、Review、Organizationです。高インテントな商品ページごとに、識別子(SKU、GTIN)、ブランド、型番、寸法、素材、差別化属性などをadditionalPropertyで詳細に記載したProductマークアップを付与しましょう。Offerで価格や在庫状況、AggregateRatingで社会的証拠も構造化します。加えて、消費者が「防水ですか?」「保証はつきますか?」「返品ポリシーは?」などと質問する状況を想定し、同じURL上でFAQPageマークアップにそれら回答を埋め込み、Product属性とFAQ内容の同期を保つことで、回答エンジンが正しいページを引用しやすくなります。
SaaS・B2Bサービス業では、エンティティはやや抽象的ですが、SoftwareApplication、Service、Organizationスキーマにうまくマッピングできます。各主要プロダクトやオファリングごとに、カテゴリ・対応プラットフォーム・連携・料金体系などの明確な説明とともにSoftwareApplicationやServiceエンティティを定義し、「Xに最適なツール」比較で頻出する機能をadditionalPropertyで列挙しましょう。これらをproviderやoffersでOrganizationと、Personマークアップで専門チームとも接続します。コンテンツ面では、Article、BlogPosting、FAQPage、HowTo構造が、LLMに評価・教育系クエリ向けの最良資産として認識されます。
ローカル・医療・規制産業では、LocalBusiness、MedicalOrganization、関連するMedicalEntityタイプで住所、サービスエリア、専門分野、受入保険、営業時間などをテキストより遥かに曖昧さなくエンコードできます。AIアシスタントに「近くで私の保険が使える小児循環器医を探して」や「今開いている救急クリニックを教えて」と尋ねられた時、これが有効です。この分野ではスキーマで過度な表現や機微な情報を公開しないよう注意し、公開可能な事実だけをマークアップし、法務・コンプライアンス部門によるレビューも徹底しましょう。
LLMの挙動は本質的に確率的なので、スキーマ変更だけで完璧な帰属分析はできません。ただし、決まったクエリセットに対するAI回答を定期的にサンプリングし、簡易なモニタリング体制を構築することは可能です。どのエンティティが言及され、どのURLが引用され、ブランドがどのように記述されているか、主要な事実(価格、機能、コンプライアンス情報など)がChatGPT、Gemini、Perplexity、Bing Copilotなど複数プラットフォームで正確に反映されているかを追跡しましょう。問題が発生した場合(架空の機能、言及漏れ、アグリゲーターへの引用偏重など)は、まず競合・不完全なシグナルを疑いましょう。ページ本文とスキーマが矛盾していませんか?sameAsリンクが欠落または古いプロフィールを指していませんか?複数ページが同一エンティティの正規ソースを主張していませんか?戦略的には、少なくとも四半期ごとにスキーマレビューを行い、新しいオファリングやコンテンツクラスター、AI回答エンジンの露出傾向の変化に合わせて調整しましょう。
AIシステム向けスキーマの効果を損なうパターンには、いくつか一貫したものがあります。ページ上に実際に表示されていない内容をマークアップすると、信頼性低下を招きます――スキーマと可視コンテンツが乖離したソースはモデルが軽視するよう学習します。あまりに汎用的なタイプ(すべてを"Thing"や"CreativeWork"にするなど)を使うのも意味信号を与えず逆効果です。ページごとにスキーマをコピペしてエンティティ情報を調整しないのも典型的なミスで、すべての商品ページが同じOrganizationマークアップだったり、すべての記事が同じ著者を主張していたりすると、モデルは区別できず、低シグナルとして優先度を下げる可能性があります。ページごとに異なる@idで同じ組織や商品を表現すると、エンティティ解決が壊れ、関連コンテンツが別物として扱われます。sameAsリンクが正規プロフィールにない場合、モデルは同名異体との混同リスクに晒されます。最後に、スキーマとページ本文に矛盾があると信頼性が損なわれます――スキーマが「在庫あり」で本文が「在庫切れ」なら、モデルはどちらも信用しません。
スキーママークアップは、見た目重視のSEO戦術からAI中心検索の基盤技術へと変貌を遂げつつあります。sameAs、about、mentionsなどでエンティティ間の関係を明示的に定義する「つながったスキーママークアップ」は、AIシステムが自信を持ってナビゲートできるナレッジグラフを構築します。もはや「リッチリザルトのために必要な最小限のスキーマは?」ではなく、「SERP外でも機械に曖昧さなく伝わる構造化表現は?」と問う組織が競争優位を手にします。このシフトは、より完全かつ相互接続されたエンティティ中心のスキーマパターンへの移行を促します。AI主導の検索が主要な発見チャネルとなる中、スキーマLLM最適化は技術的好奇心からコアSEO施策へと進化します。基本的リッチリザルトスキーマからナレッジグラフ統合・LLM最適化パターンまで成熟度を高めていく組織こそが、AI主導の発見時代にブランドが権威として引用され、コンテンツが信頼されるソースとして表示され続ける「強固な堀」を築くのです。
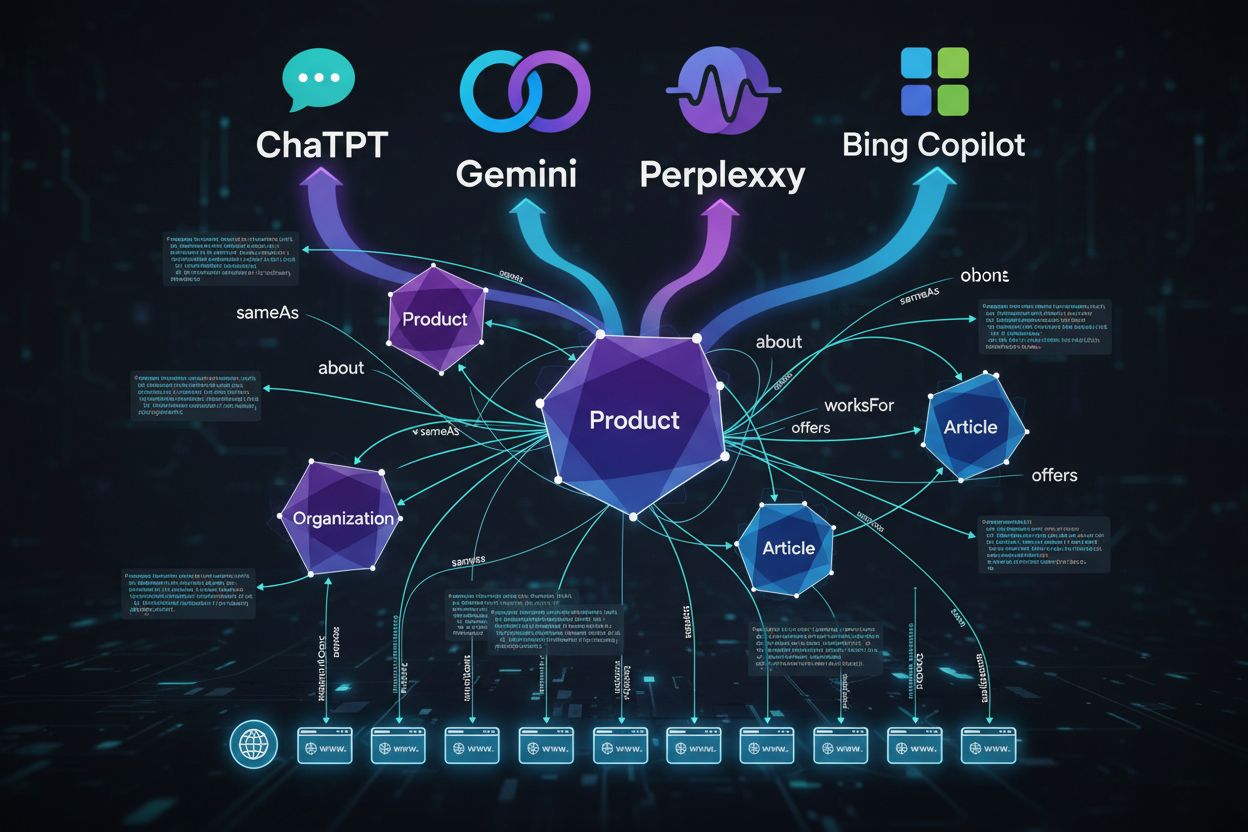
従来のスキーマはリッチリザルト(星やスニペット)獲得が中心でした。AIでは、スキーマはエンティティの明確化、関係性、ナレッジグラフの構築が目的です。AIシステムはスキーマを、見た目だけでなく、あなたのコンテンツが何であるかを意味的に理解するために活用します。
Organization、Product、Article、Person、FAQPageは基盤となります。SaaSならSoftwareApplicationやServiceも追加してください。ローカルやヘルスケアならLocalBusinessやMedicalOrganizationも。重要度は業界やユーザー意図によって異なります。
いいえ。まずはOrganizationと、最も価値の高いページ(商品・サービス・主要記事)から始めましょう。ビジネスモデルやAI回答で価値が高い部分から徐々に拡張していけばOKです。
スキーマの変更は数週間でAIによる引用に影響を与えることがありますが、その関係は確率的です。四半期ごとの見直しと、複数AIプラットフォームでの継続的なモニタリングを計画しましょう。
sameAsはあなたのエンティティをWikipediaやLinkedInなどの正規プロフィールにリンクし、同名異人との混同を防ぎます。about/mentionsはページが何に本当にフォーカスしているかを明確にし、モデルが文脈やニュアンスを理解しやすくします。
いいえ。スキーマは高品質で構造化されたページコンテンツと連動して最大限効果を発揮します。モデルは構造化データだけでなく、ナラティブな文脈も必要とします。
ターゲットクエリでChatGPT、Gemini、Perplexity、Bingなど各プラットフォームのAI回答をモニタリングしましょう。エンティティの言及、URL引用、事実の正確性、ブランド記述を追跡し、数週間・数か月単位で傾向を見ます。
ほとんどの場合、JSON-LDが推奨フォーマットです。実装や保守が容易で、HTMLにも干渉しません。microdataやRDFaは現代の実装ではあまり一般的ではありません。
ChatGPT、Gemini、Perplexity、Google AI Overviewsなどで、AIがどのようにあなたのブランドを引用しているかを追跡しましょう。どのスキーマタイプが可視性を高めているかのインサイトも取得できます。
ChatGPT、Perplexity、GeminiなどのAI検索エンジンでの可視性を高めるスキーママークアップタイプを発見しましょう。AI回答生成器向けJSON-LD実装戦略も学べます。...
スキーママークアップは、検索エンジンがコンテンツを理解するのを助ける標準化コードです。構造化データがSEOを改善し、リッチリザルトを可能にし、ChatGPTやGoogle AI OverviewsなどAI検索プラットフォームをサポートする方法を学びましょう。...
GoogleツールやSchema.orgバリデーター、ベストプラクティスを使ってスキーママークアップや構造化データを検証する方法を学びましょう。JSON-LDが機械可読でリッチリザルトの対象になるようにしましょう。...