
AIにおけるコンテンツ包括性:意味的完全性の完全ガイド
ChatGPT、Perplexity、Google AI OverviewsなどのAIシステムにとってコンテンツ包括性が何を意味するのかを学びましょう。AIが引用する完全で自己完結的な回答を作成する方法を発見してください。...
1 分で読める
セマンティック完全性がAIシステムに引用される自己完結型回答をどのように生み出すかを学びましょう。セマンティック完全性の3つの柱を発見し、AIでの可視性を40%高めるGEO戦略を実践しましょう。
AIにおけるセマンティック完全性とは、外部リファレンスや追加情報なしで、言語モデルが独立して理解できるだけの十分な文脈と情報をコンテンツが提供している度合いを指します。キーワード順位やクリック率を重視する従来のSEOとは異なり、セマンティック完全性は、AIシステムがユーザーの問いに対してコンテンツの個々のセクションを独立した回答として抽出・理解・引用できることを重視します。ChatGPT、Perplexity、Google AI OverviewsといったAIプラットフォームがコンテンツを評価する際、各コンセプト・事実・主張が十分に説明され、抽出しても完全な回答として提示できるかどうかをチェックします。この違いは非常に重要です。AIシステムは単にページをランク付けするのではなく、複数の情報源から情報を統合し、もっともセマンティックに完全な回答を引用するためです。セマンティック完全性を達成したコンテンツは、AIにとって他の情報源を組み合わせる必要がなくなるため、引用先として自然と価値が高まり、選ばれやすくなります。キーワード中心の最適化からセマンティック完全性へのシフトは、ジェネレーティブAI時代におけるデジタル可視性のアプローチに根本的な変化をもたらします。

AIシステムはRetrieval-Augmented Generation(RAG)プロセスを使ってコンテンツ完全性を評価します。これは、ナレッジベースから関連情報を検索・抽出し、その情報を関連性と権威性でランク付けし、最高品質の情報源を合成して回答を生成する流れです。検索フェーズでは、AIはユーザーのクエリをセマンティックな表現に変換し、単なるキーワード一致ではなく概念的に一致するドキュメントを探します。ランク付けフェーズでセマンティック完全性が重要になります。AIアルゴリズムは、抽出したコンテンツが独立した回答として成立するか、それとも他の情報源の補足が必要かを判定します。プリンストン大学とジョージア工科大学の研究(100万件超のAI生成回答分析)によれば、セマンティック完全性を達成したコンテンツは、情報を複数から合成しなければならない断片的なコンテンツよりも40%多く引用されることが分かっています。評価プロセスでは、セマンティック明瞭性、論理的な見出しやリストによる構造化、統計やデータポイントによる事実密度、適切な引用による権威性などが重視されます。AIは、セマンティックに完全なコンテンツが処理負荷を減らし、回答の質を高めることを認識しており、こうしたコンテンツが引用される可能性が大幅に高まります。
| 評価要素 | AIによる引用への影響 | 従来SEOでの関連性 |
|---|---|---|
| セマンティック明瞭性 | 重要(引用40%増加) | 中程度 |
| 構造的な整理 | 重要(抽出を可能にする) | 高い |
| 事実密度 | 高い(検証性のシグナル) | 中程度 |
| 権威性シグナル | 高い(信頼性評価) | 高い |
| アクセシビリティ | 高い(可読性が重要) | 中程度 |
セマンティック完全性は、AIにとって最大限価値あるコンテンツにするための3つの柱に支えられています。
権威ある情報源の引用:すべての主張・統計・断言には、信頼できるソース(.eduドメイン、.govリソース、査読済み研究、業界の著名な出版物など)へのリンクが必要です。スタンフォード大学とプリンストン大学の研究によれば、権威あるソースを引用したコンテンツは、未引用のものよりも圧倒的にAIによる引用数が多くなります。この柱はリサーチの厳密さと事実の裏付けを示し、AIが独立して情報を検証し、安心してあなたのコンテンツを引用できるようにします。
専門家の引用:業界専門家や実務者、オピニオンリーダーからの直接的なコメントや引用は、AIが認識・優先する信頼性のしるしです。資格や肩書きを明示した専門家の視点が盛り込まれていれば、AIアルゴリズムはそのコンテンツをより権威あるもの・引用価値の高いものとして扱います。専門家の引用が含まれるコンテンツは、具体的で帰属可能な事実をAIが抽出し、確立された知識として提示できるため、引用頻度が大幅に上昇します。
統計的根拠:数値データやパーセンテージ、具体的な数値根拠が豊富なコンテンツは、一般的な内容よりもAIに引用される確率が飛躍的に高まります。AI引用パターンの分析によれば、150~200語ごとに1つの統計を含めることで、最適な引用頻度を実現できます。統計は、AIユーザーの具体的な質問への回答として機能し、AIアルゴリズムに専門性やリサーチの深さを伝えます。
各柱は単独でもセマンティック完全性を高めますが、3つすべてを組み合わせることで、主要AIプラットフォームでの引用最大化が実現します。
セマンティックチャンク化――コンテンツを自己完結型のセクションに分割し、それぞれが概念的に独立して成り立つように構成すること――は、AI引用の成功に不可欠です。各H2セクションは、その見出しだけで完結するように構成し、前のセクションを参照せずとも理解できるようにします。AIが個々のセクションを独立した回答として抽出できるように、とくに重要です。直接的な回答形式では、最初の40~60語でコアとなる答えを提示し、その後に補足説明や事例を加えて概念を広げます。たとえば「コンテンツマーケティングとは?」という問いには、「コンテンツマーケティングとは、明確に定義されたターゲットに価値ある関連コンテンツを作成・配信する戦略的アプローチです。」というように、冒頭で直接的な答えを記載します。この部分だけで独立して抽出でき、後続の段落で文脈や統計、事例を補足しますが、理解には必須ではありません。「セマンティック独立性」とは、AIがあなたのコンテンツのどのセクションを引用しても混乱せず、各セクションが独立した理解のための十分な文脈を提供している状態です。この構造化アプローチは同時に、Googleの「役立つコンテンツ」ガイドラインに沿った情報設計となり、従来SEOにも効果的です。
AIプラットフォームごとに、重視するセマンティック完全性の特徴が異なります。そのため、各システムごとに最適化戦略を微調整する必要があります。ChatGPTは、ウィキペディアのような百科事典的で権威ある構成を強く好み、実際、ChatGPTの事実系クエリの引用元の47.9%がWikipediaです。Perplexity AIは過去90日以内に公開された新しいコンテンツや、Redditなどコミュニティで検証済みの情報源を強く重視し、上位引用の46.7%がこれらに由来します。Google AI Overviewsは、E-E-A-T(専門性、経験、権威性、信頼性)シグナルや構造化データマークアップを重視し、すでにオーガニック検索のトップ10に入っているコンテンツを優先します。
| プラットフォーム | セマンティック完全性の優先事項 | 引用の傾向 | コンテンツの新しさ |
|---|---|---|---|
| ChatGPT | 百科事典的構造、網羅的カバレッジ | Wikipedia型、権威ある情報源 | 6~12か月以内でも許容 |
| Perplexity | 新しい事例、コミュニティでの検証 | Reddit、新着記事、実践事例 | 90日以内が推奨 |
| Google AI Overviews | E-E-A-Tシグナル、スキーママークアップ | オーガニック上位10位、強調スニペット | 最新・更新済みが必要 |
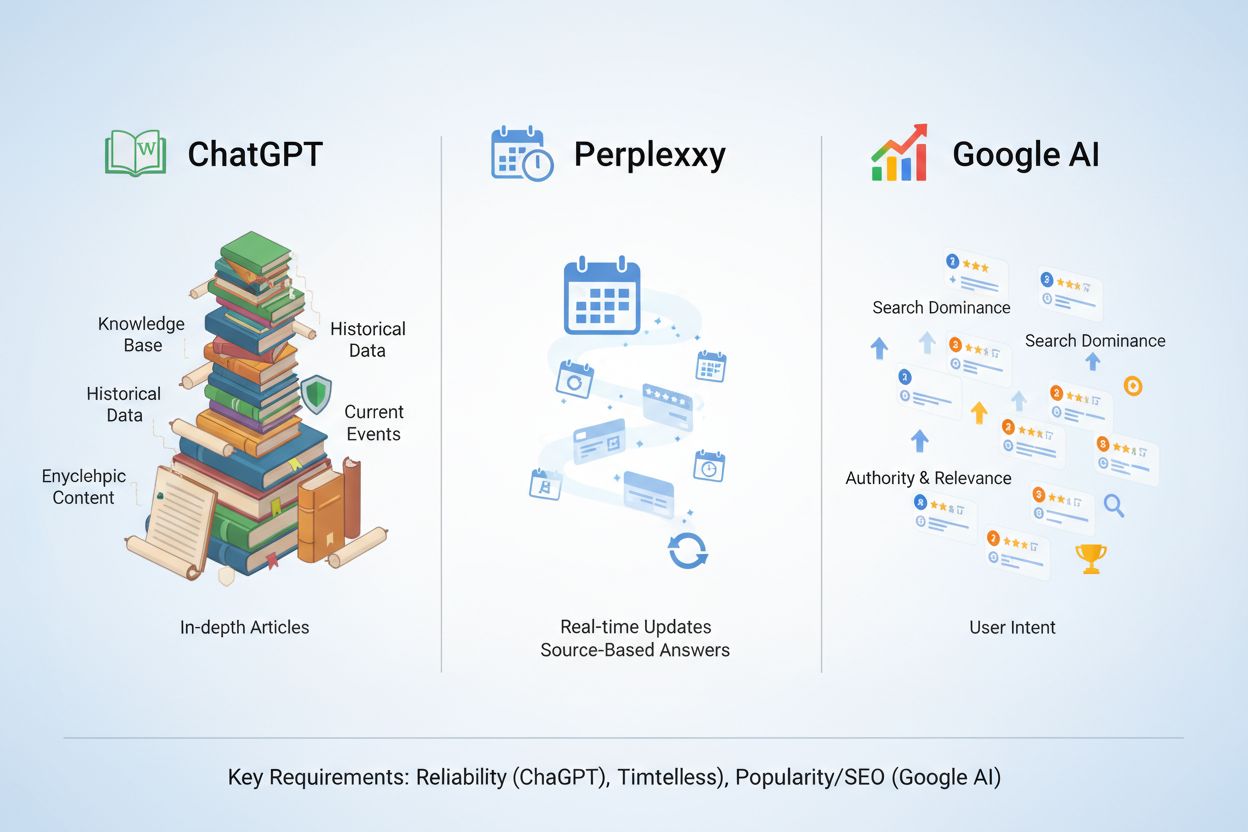
マルチプラットフォーム最適化には、すべての要件を満たす包括的なベースコンテンツ(2,500~3,000語)を作成し、ChatGPT向け百科事典的定義、Perplexity向け実例、Google AI Overviews向け強力なE-E-A-Tシグナルを同時に組み込むことが求められます。
従来のSEOはキーワード密度や配置を重視し、検索アルゴリズムがクエリとコンテンツのキーワード一致を探す前提で設計されていました。セマンティック完全性では、キーワード頻度よりも概念の明確さや意味に優先順位を置きます。「ジェネレーティブエンジン最適化」という語を何度も繰り返しても、概念が明確でなければ、事例や構造が明瞭なページにAIは軍配を上げます。FraseやSingle Grainの調査によれば、セマンティック検索は概念やアイデア同士の関係性を特定し、キーワード詰め込みはAIの引用アルゴリズムでは逆効果となります。セマンティック完全性を意識したコンテンツは、文脈の中で自然に関連キーワードが盛り込まれるため、無理なキーワード密度は不要です。むしろ過剰なキーワードは不自然な表現となり、AIに信頼できないと認識されます。Googleの「役立つコンテンツ」ガイドラインも、キーワード詰め込みを明確にペナルティ対象とし、本当に役立つ情報や整理された構造を評価しています。コンテンツ制作者は、キーワード密度の管理表を捨て、概念の説明や文脈提供、各セクションが独立した回答になっているかを重視しましょう。
自己完結型回答フォーマットは、AIによる引用率を最大化するための一貫した構造になっています:直接回答(10~15語でコアコンセプトを述べる)、補足説明(20~30語で背景や解説)、権威指標(5~10語で専門性やデータソースへの言及)。たとえば「コンテンツマーケティングはどうやってROIを生み出すのか?」という問いなら、「コンテンツマーケティングはリード獲得、顧客維持、ブランド権威構築を通じてROIを生み出します(直接回答)。コンテンツマーケティング戦略を実践する企業は、広告頼みの企業より3倍のリードを獲得しています(補足説明)。Content Marketing Instituteの2024年調査より(権威指標)。」という35~55語のフォーマットが最適です。各回答は独立して理解できる必要があり、そのパラグラフだけを読んでも概念が十分に伝わるようにしましょう。事例もセマンティック完全性を高めます。「例えば、SaaS企業が月に20本の教育系ブログを公開した場合、年間で500件の有望リードが生まれ、広告のみの場合の150件と比べて大きな差となります。」このような具体的な事例がAIによる実用的な引用を促進します。
FAQスキーママークアップ(JSON-LD形式を使用)は、AIに「このセクションがよくある質問への回答である」と明示的に伝えるもので、該当クエリでの引用率を劇的に高めます。PassionfruitやGetPassionFruitの調査によれば、FAQスキーマを導入することで、AIが周辺文脈を解析せずともQ&Aペアを素早く特定・抽出できるため、引用頻度が向上します。FAQスキーマのJSON-LD構造は、FAQPageエンティティの配下にQuestion項目の配列があり、それぞれにaccepted Answerプロパティとして完全な回答を持ちます。Googleは構造化データの実装にJSON-LDを公式に推奨しており、保守性や実装ミスの低減が理由です。FAQスキーマは、AIシステムへの構造的シグナルになるだけでなく、Google検索で強調スニペットの対象にもなり、可視性の複利的な効果をもたらします。FAQスキーマを実装する際は、マークアップされた内容が必ずページ上にユーザーが見える形で表示されていること(非表示や動的読み込みはガイドライン違反)、各ページにはそのページ固有のFAQを掲載すること、各回答は外部文脈なしで理解できる自己完結型であることが重要です。適切に実装されたFAQスキーマのページは、AIが引用価値を評価する際に優遇され、セマンティック完全性を明示的にアピールできます。
セマンティック完全性の効果測定には、従来指標だけでなく、ビジネス成果と直結する新しいAI特有のパフォーマンス指標も必要です。引用率(Brand Citations in AI Responses / Total Relevant Queries Tested × 100)は、もっとも直接的なセマンティック完全性の効果指標であり、最適化後6か月で30~50%の引用率達成が一般的な成功ラインです。GA4のセグメント機能で「ChatGPT-User」「PerplexityBot」「Claude-Web」などのユーザーエージェントをフィルタリングすれば、AIボットのトラフィックも追跡できます(ただし識別可能なボットのみであり、方向性の参考値と考えてください)。引用コンテキスト分析は、AIプラットフォームに毎月コアな質問を10~15件手動で投げて、どの情報源が引用されているか・頻度の推移を記録します。最適化したコンテンツ公開後、4~8週間で初期引用が発生し、6~12か月かけて権威性が蓄積されるとともにAI側で信頼情報源とみなされる傾向が強化されます。シェア・オブ・AIボイス(Your Brand Citations / Total Industry Citations × 100)は競合比較指標であり、業界内で自社の引用シェアが増減しているかを可視化できます。これらの指標は、セマンティック完全性の成功を証明し、AI最適化への継続投資の根拠になります。
コンテンツがセマンティック完全性を達成できず、AI引用率を下げてしまう主な7つの失敗例:
回答範囲の不完全 ― メインの質問だけでなく、ユーザーが自然に抱く関連疑問や補足質問に答えていないため、AIが複数の情報源を合成しないと回答できず、引用されにくくなる。
抽象的なマーケティング表現 ― 「大胆な味にインスパイアされた卓越した料理」などの抽象表現ではなく、「手作りの本格ストリート系タコスとブリトーボウル」のような具体的・事実ベースの記述が不可欠。
出典の欠如 ― 権威ある情報源を引用せずに主張することで、AIアルゴリズムからリサーチの厳密さが疑われ、引用信頼度が下がる。
構造化の不備 ― 段落が長く見出しや箇条書き、論理階層がないため、AIが自己完結型セクションを抽出しにくくなる。
古い統計データ ― 12か月以上前のデータを更新せずに使い続けることは、PerplexityやGoogle AI Overviewsにとってとくにマイナスで、新鮮な情報が求められる。
専門家属性の欠如 ― 著者クレデンシャルや専門家の視点がないことで、AIが権威性シグナルと判断できず、引用機会を逃す。
事実密度の不足 ― 150~200語ごとに統計や数値根拠がない一般的な内容は、AIが重視する具体的・検証可能な情報を欠き、引用されにくい。
セマンティック完全性の要件はコンテンツタイプにより異なり、AI引用効果最大化のためには個別設計が必要です。ブログ記事は冒頭40~60語で直接回答し、その後に証拠や事例を追加、FAQセクションでよくある追随質問に答えます。ハウツーガイドは各ステップが独立して詳細・数値・結果を盛り込み、AIが個々の手順を完全な指示として抽出できるようにします。FAQページは5~10組のQ&AをFAQスキーマ形式で実装し、各回答は40~60語で自己完結型にします。商品ページは、特徴の明確な説明、具体的な利用シーン、購入時によくある質問への直接回答を通じてセマンティック完全性を高めます(ただしAIが商品ページを直接引用する事例は稀で、多くは周辺の教育コンテンツが引用されます)。ケーススタディは、具体的な数値・期間・課題・解決策・成果を明確に分け、AIが個別要素を証拠として引用しやすくします。いずれのコンテンツタイプでも、直接回答・自己完結型セクション・事実密度・権威性シグナルという原則は共通ですが、構造化方法は目的やユーザー意図に応じて最適化が必要です。
AI検索の普及とプラットフォームの高度化により、セマンティック完全性はデジタル可視性の中心的要素となります。最新トレンドでは、テキスト・画像・動画・音声を同時に処理できるマルチモーダルAIの登場によって、今後は文章だけでなく様々なフォーマットでの完全性が求められるようになります。Semrushの調査によれば、AI経由のトラフィックは2028年初頭には従来のGoogleオーガニック検索を上回る見込みであり、セマンティック完全性の最適化はもはや実験的戦術ではなく長期投資の必須事項です。早期にコンテンツ全体でセマンティック完全性を確立したブランドは、AIの「ソース選好バイアス」によって有利になります――一度信頼情報源と認識されると、その分野の関連クエリでも優先的に引用され、複利的な優位性が生まれます。AIによる引用競争が激化する中、セマンティック完全性は、AI生成回答で可視性を獲得するブランドと埋もれるブランドを分ける主な差別化要素となるでしょう。今この分野に投資する組織は、後発が突破しにくい「引用の堀」を築き、時間とともに累積する権威性を手に入れます。検索の未来は会話型・AI主導・引用ベースであり、セマンティック完全性は今後10年のコンテンツマーケターにとって不可欠な基礎スキルとなります。
セマンティック完全性とは、読者が外部リソースや前のセクションにアクセスする必要なく、コンテンツだけで完全に理解できる自己完結性を意味します。AIシステムにとっては、各セクションが独立して抽出・引用できること、すなわち、特定の質問に完全に答えるために必要な文脈と情報がすべて含まれていることを指します。
従来のSEOは検索結果での順位向上を目指し、キーワードや被リンクに注力します。セマンティック完全性は、AIによる抽出・引用を前提に、個々のセクションや事実を最適化します。SEOが「このページは順位が上がるか?」と問うのに対し、GEOは「AIはこのセクションを独立して抽出・引用できるか?」と問います。
RAG(検索拡張生成)を利用するAIシステムは、複数の情報源から特定のセクションを抽出して回答を合成します。自己完結型のセクションであれば、周辺の文脈を必要とせずAIが自信を持って引用できるため、選ばれやすくなります。
調査によると、最適な自己完結型回答は40~60語の冒頭(直接的な回答)、20~30語の補足説明、5~10語の権威性指標で構成され、合計35~55語が推奨されます。ただし、論理的に完結していて外部文脈を必要としない場合、100~200語といった長めのセクションでも自己完結性を持てます。
各H2セクションを周辺の内容を読まずに単独で読んでみて、外部文脈がなくても完全に理解でき、セクションの疑問に答えられるならセマンティック完全です。また、AIシステムに直接聞いてみて、そのセクションだけで引用されるなら完全性が達成できています。
はい。セマンティック完全性を意識した構造(明確な見出し、直接的な回答、論理的な流れ)は従来のSEOでも効果的です。Googleの「役立つコンテンツ」ガイドラインは、ユーザーの質問に直接答える明確で構造化されたコンテンツを評価しており、セマンティック完全性の原則と完全に一致します。
コアコンテンツは特に統計や事例、時事性のある情報を中心に90~180日ごとに更新しましょう。PerplexityやGoogle AI Overviewsは新鮮なコンテンツを強く好みます。ただし、セマンティック構造自体(セクションの整理方法など)は安定しており、事実の更新に重点を置きましょう。
はい。ブログ記事、ハウツーガイド、FAQ、商品ページ、ケーススタディ、業界レポートなど、あらゆるコンテンツがセマンティック完全性の恩恵を受けます。原則は「各セクションが独立して理解できること」であり、具体的な実装はコンテンツタイプごとに異なります。FAQは自然と完全性に適合しますが、ブログ記事は意図的なセクション構成が必要です。
ChatGPT、Perplexity、Google AIなどのシステムがあなたのブランドをどのように引用しているかを追跡できます。セマンティック完全性のパフォーマンスや競合との引用シェアをリアルタイムで確認しましょう。
ChatGPT、Perplexity、Google AI OverviewsなどのAIシステムにとってコンテンツ包括性が何を意味するのかを学びましょう。AIが引用する完全で自己完結的な回答を作成する方法を発見してください。...
AIシステム向けに最適化した包括的コンテンツの作成方法を学びましょう。深さの要件、構造のベストプラクティス、AI検索エンジンや回答生成器向けのフォーマットガイドラインを解説します。...

コンテンツ最適化におけるセマンティック・コンプリートネスの意味を学びましょう。包括的なトピック網羅性がAIによる引用や、ChatGPT、Google AI Overviews、Perplexityでの可視性をどのように高めるかを解説。現代コンテンツ戦略に不可欠な要素です。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.