GPTBotや他のAIクローラーを許可すべき?robots.txtが長年ブロックしていたことに気づいた
AIボットによるサイトクローリングを許可するかについてのコミュニティディスカッション。robots.txtの設定やllms.txtの実装、AIクローラー管理の実体験。...
3 分で読める
Discussion
Technical SEO
+1

ステルスクローラーがrobots.txtの指示を回避する仕組みや、クローラーの回避技術、そして無断AIスクレイピングからコンテンツを守るための解決策を解説します。
Webクローリングは、人工知能システムの登場によって根本的に変化しました。従来の検索エンジンが確立されたプロトコルを遵守してきたのに対し、一部のAI企業はステルスクローリング、すなわちボット活動を意図的に偽装してウェブサイトの制限やrobots.txtの指示を回避する手法を採用しています。この行為は、約30年にわたりWebクローリングを支えてきた協調関係からの大きな逸脱であり、コンテンツの所有権やデータ倫理、オープンインターネットの今後に関わる重大な課題を投げかけています。

中でも最も顕著な例はPerplexity AIです。AIによる回答エンジンである同社は、ウェブサイト管理者に明確にブロックされたコンテンツへ、非宣言型クローラーを用いてアクセスしていたことが発覚しました。Cloudflareの調査により、Perplexityは正直に名乗る宣言型クローラーと、通常のウェブブラウザを装うステルスクローラーの両方を使い分け、ブロック回避を実現していることが明らかになりました。この二重クローラー戦略により、Perplexityはrobots.txtやファイアウォールで明確にアクセス拒否されても、コンテンツ収集を継続できてしまうのです。
robots.txtファイルは、1994年にRobots Exclusion Protocolの一部として登場して以来、インターネット上でクローラー管理の中心的存在です。サイトのルートディレクトリに設置するシンプルなテキストファイルで、クローラーにサイトのどの部分へアクセス可能か・不可かを指示します。典型的なrobots.txtの記述例は以下の通りです。
User-agent: GPTBot
Disallow: /
この指示は、OpenAIのGPTBotクローラーに対し、サイト内全てのコンテンツへのアクセスを禁止するものです。ただし、robots.txtは完全に自主的な遵守が前提です。robots.txtの内容には強制力がなく、クローラーがそれを守るかどうかはクローラー側の判断となります。Googlebotなどの信用あるクローラーは指示を守りますが、プロトコル自体には制裁や強制手段がありません。クローラーはrobots.txtを完全に無視することもでき、それを技術的に阻止する方法は存在しません。
| クローラー | 宣言されたユーザーエージェント | robots.txt遵守 | 遵守状況 |
|---|---|---|---|
| GPTBot (OpenAI) | Mozilla/5.0 (compatible; GPTBot/1.0) | Yes | 遵守 |
| ChatGPT-User | Mozilla/5.0 (compatible; ChatGPT-User/1.0) | Yes | 遵守 |
| ClaudeBot (Anthropic) | Mozilla/5.0 (compatible; Claude-Web/1.0) | Yes | 遵守 |
| Google-Extended | Mozilla/5.0 (compatible; Google-Extended/1.0) | Yes | 遵守 |
| Perplexity-User | Mozilla/5.0 (compatible; Perplexity-User/1.0) | No | 非遵守 |
| 非宣言型ステルスクローラー | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) Chrome/124.0.0.0 | No | ステルス/回避 |
優良なクローラーと悪質なクローラーの違いは、ますます重要性を増しています。OpenAIやAnthropicのような信頼できるAI企業は、クローラーのIPレンジを公開し、透明性のあるドキュメントを整備し、ウェブサイト管理者の意向を尊重しています。それに対し、ステルスクローラーは身元を隠し、指示を意図的に無視し、robots.txtを単なる障害物として取り扱います。
CloudflareによるPerplexityのクローリング行動の詳細な調査は、これまでで最も包括的なステルスクローリングの実態を明らかにしました。調査チームが明確に自動化アクセスを禁止したrobots.txtを持つテスト用ドメインを複数用意したところ、PerplexityはAIのインターフェース経由でそのテストドメインの詳細な情報を返し続けました。
この調査で判明したのは、高度な二段階クローリング戦略です。Perplexityの宣言型クローラー(Perplexity-User)は1日あたり約2,000万〜2,500万リクエストを正直なユーザーエージェントで送信します。しかし、この宣言型クローラーがネットワークブロックやrobots.txtによる制限に遭遇すると、非宣言型ステルスクローラーが発動し、さらに1日あたり300万〜600万件のリクエストを、本物のChromeブラウザ(macOS)を装って送信します。このステルス型は、以下の汎用ユーザーエージェントを使用します:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36。
このステルスクローラーは複数の回避技術を同時に用いています。Perplexity公式IPレンジに含まれないIPアドレスを次々と使い分け、IPベースのブロックを不可能にしています。さらに、AS番号(ネットワーク提供者識別子)も切り替えて出自を隠し、数万のドメインを対象に1日数百万リクエストを発生させていました。
対照的に、CloudflareがChatGPTで同様のテストを行ったところ、ChatGPT-Userはrobots.txtを取得し、Disallow指示を認識すると即座にクロールを中止しました。ネットワークレベルのブロック時にも、他のユーザーエージェントやIPから再度のアクセスを試みませんでした。つまり、遵守行動は技術的に十分可能であり、robots.txtの無視は技術的限界ではなく、企業の意図的なビジネス判断であることが示されています。
ステルスクローラーは、検知や制限を回避するために高度な技術を組み合わせています。これらの仕組みを理解することが、効果的な対策の第一歩です。
ユーザーエージェント偽装:実際のChrome、Safari、Firefoxなどの本物のブラウザと同じようなユーザーエージェント文字列を使い、人間の訪問と見分けがつかないようにします。
IPローテーションとプロキシネットワーク:単一IPや既知のデータセンターIPからではなく、数百〜数千の異なるIPアドレスを使い分け、しばしば家庭用回線のプロキシネットワークを経由して本物の家庭インターネットと同じように振る舞います。
ASNローテーション:ネットワーク提供者識別子(AS番号)を切り替え、異なるISPからのアクセスに見せかけ、IPベースのブロックを無力化します。
ヘッドレスブラウザシミュレーション:Chrome Headless、Puppeteer、Playwrightなどの実際のブラウザエンジンを動かし、JavaScript実行やCookie維持、マウス操作やランダムな遅延など、人間の操作を再現します。
リクエストレート操作:短時間に大量リクエストを送ると検知されやすいため、遅延やばらつきを与え、人間の自然な閲覧パターンを模倣します。
フィンガープリントランダマイズ:画面解像度やタイムゾーン、フォント、TLSハンドシェイクなど、ブラウザ固有の特徴情報をランダム化し、デバイスフィンガープリント検知システムをかいくぐります。
これらの手法は同時多発的に組み合わされ、伝統的な検知手法を打ち破る多層的な回避戦略を実現します。たとえば、偽装ユーザーエージェント+家庭用プロキシ+遅延+フィンガープリント偽装を組み合わせることで、正規トラフィックと見分けが極めて難しくなります。
ステルスクローラーを使う決断の根本的な動機は、データ飢餓です。最先端の大規模言語モデルの訓練には、膨大かつ高品質なテキストデータが不可欠です。最も価値の高いコンテンツ、たとえば独自研究や有料記事、専門フォーラム、高度な知識ベースなどは、多くの場合ウェブサイト運営者によってアクセス制限されています。企業は「制限を守って低品質データで妥協するか、制限を破って良質データを得るか」という選択を迫られるのです。
競争圧力も非常に激しいです。数十億ドル規模のAI開発投資を行う企業にとって、より優れた訓練データこそが優れたモデル、すなわち市場優位に直結します。競合他社が制限されたコンテンツまでスクレイピングしている場合、robots.txtを守ること自体が競争上の不利となります。これによって倫理的な行動が市場原理で罰せられる「底辺への競争」が生まれます。
さらに、実質的な強制力がほとんどないのも問題です。ウェブサイト管理者は、決意を持ったクローラーのアクセスを技術的に阻止できません。法的手段も時間とコストがかかり、確実な効果がありません。よほど資金力のある組織でなければ法的措置を取れず、悪質なクローラーはほぼ無傷で済みます。リスクとリターンを天秤にかければ、robots.txtを無視した方が圧倒的に得なのです。
法的状況も依然曖昧です。robots.txt違反が利用規約違反となる場合もありますが、公開情報のスクレイピングの合法性は国によって異なります。公開データのスクレイピングを合法とした判例もあれば、Computer Fraud and Abuse Act違反とした例もあります。この不透明さが、グレーゾーンで活動する企業を後押ししています。
ステルスクローリングの影響は、単なる技術的な不便さにとどまりません。Redditは、自社のユーザー生成コンテンツが許可や対価なしにAIモデルの訓練に使われていたことを発見し、AI企業からのデータアクセスに課金するためAPI料金を大幅に引き上げました。CEOのSteve Huffmanは、Microsoft、OpenAI、Anthropic、Perplexityらが「Redditのデータを無料で利用している」と明言しています。
Twitter/Xはさらに強硬に、ツイートの未認証アクセスを一時的に全遮断し、認証ユーザーにも厳しいレート制限を課しました。Elon Muskは「数百の組織によるデータスクレイピング」がユーザー体験を損ない、膨大なサーバーリソースを消費しているための緊急措置だと述べています。
ニュース発行者も大きな危機感を示しています。ニューヨーク・タイムズ、CNN、ロイター、ガーディアンは、OpenAIのGPTBotをrobots.txtでブロックする設定に変更しました。中には訴訟に踏み切った例もあり、ニューヨーク・タイムズはOpenAIを著作権侵害で提訴。AP通信は、OpenAIとライセンス契約を結び、限定的なニュースコンテンツ提供と引き換えに技術利用権を得るという、初の商業的取り組みも行われました。
Stack Overflowは、攻撃者が数千のアカウントを作成し、正規ユーザーを装って大量のコード例を収集する協調的なスクレイピングに直面しました。同プラットフォームのエンジニアチームは、スクレイパーが多数の接続で同一TLSフィンガープリントを用い、セッション維持や有料アカウントまで利用して検知回避を試みる実態を記録しています。
これら一連の事例に共通するのは、コントロール権の喪失です。コンテンツ制作者は、自分の作品がどのように使われ、誰が利益を得ているのか、正当な対価を得られるのかをもはや管理できません。これは、インターネットの力関係そのものを根本から変える現象です。
幸いにも、ステルスクローラーの検知やブロックのための高度なツールが登場しています。CloudflareのAI Crawl Control(旧AI Audit)は、どのAIサービスが自サイトにアクセスし、そのrobots.txtポリシーを守っているかを可視化します。さらに新機能Robotcopは、robots.txtの指示内容をWebアプリケーションファイアウォール(WAF)ルールに自動変換し、ネットワークレベルで強制執行できるようにしています。
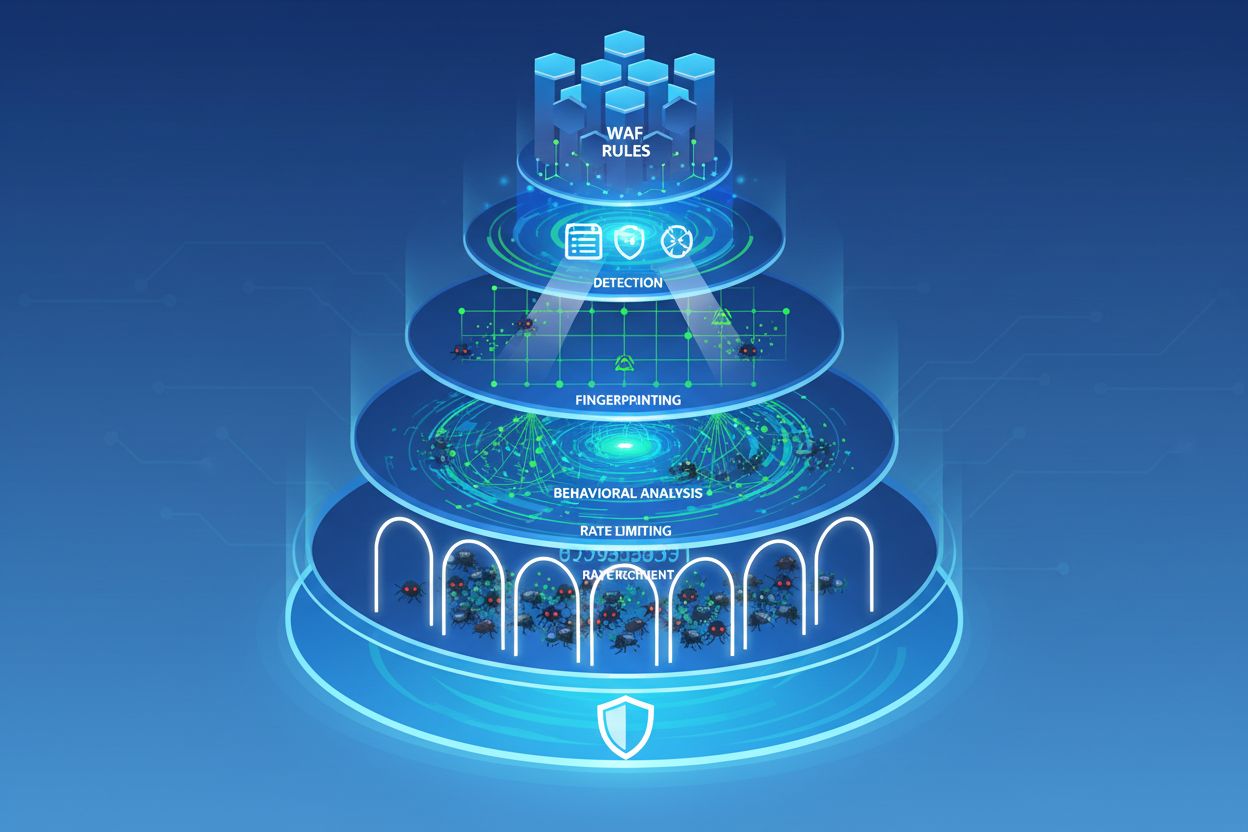
デバイスフィンガープリントは強力な検知手法です。ブラウザバージョン、画面解像度、OS、インストールフォント、TLSハンドシェイク、行動パターンなど、複数のシグナルを分析し、ボット特有の不整合を検出します。たとえば、Chrome on macOSを装うクローラーが本物のChromeと異なるTLSフィンガープリントだったり、特定のAPIが存在しない場合、ボットを見抜くことができます。
行動分析は、訪問者のサイト内での動きに着目します。本物のユーザーは、コンテンツをじっくり閲覧し、論理的にページを回遊し、時にミスや修正もします。ボットは不自然な順序でページを取得したり、リソース読み込み順が異常だったり、インタラクティブ要素に全く触れなかったり、現実的に不可能な速度でアクセスする傾向があります。
レートリミットも他の手法と組み合わせることで有効です。IP・セッション・ユーザーアカウントごとに厳格なリクエスト上限を設け、スクレイパーの効率を大幅に下げます。違反ごとに待機時間を指数的に増やすエクスポネンシャルバックオフも、自動化攻撃の抑止に効果的です。
AmICitedは、現状の課題である「どのAIシステムが実際に自分のブランドやコンテンツを引用しているかの可視化」に応えます。CloudflareのAI Crawl Controlのようなツールが「誰がアクセスしているか」を示すのに対し、AmICitedは「ChatGPT、Perplexity、Google Gemini、Claudeなど、どのAIが実際に回答で自分のコンテンツを使っているか」まで追跡します。
この違いは極めて重要です。クローラーのアクセスがあっても、必ずしもコンテンツが引用されるとは限りません。その逆に、直接クロールせず間接的な経路(Common Crawl等)で引用される場合もあります。AmICitedはこの「AIによる実際の利用証拠」を提供し、どのように引用されているかの詳細情報も取得できます。
プラットフォームは、トラフィックパターンやユーザーエージェント、行動シグナルを分析して、偽装ユーザーエージェントを使う非宣言型クローラーのアクセスを検知し、ステルスクローリングの疑いをフラグ付けします。これにより、ウェブサイト管理者は正規AIアクセスを維持しつつ、非遵守クローラーへの対応も可能です。
リアルタイムアラート機能により、ステルスクローラー検知時には即座に通知され、素早い対応が可能です。既存のSEOやセキュリティワークフローとも連携でき、AI時代のコンテンツ利用状況の可視化に不可欠なインテリジェンスを提供します。
ステルスクローラーからコンテンツを守るには、多層的なアプローチが不可欠です。
明確なrobots.txtポリシーの運用:ステルスクローラーは無視する場合もありますが、正規クローラーは必ず従います。GPTBot、ClaudeBot、Google-Extendedなど既知AIクローラーの指示も明示的に記述しましょう。
WAFルールの導入:Webアプリケーションファイアウォールを使い、robots.txtの指示をネットワークレベルで強制します。CloudflareのRobotcopなどを活用すると自動生成が可能です。
クローラー挙動の定期監視:AmICitedやCloudflare AI Crawl Controlなどで、どのクローラーがアクセスし、指示を守っているかを監視しましょう。定期的な監視がステルスクローラーの早期発見につながります。
デバイスフィンガープリントの導入:ブラウザ特性や行動パターンを分析し、正規ユーザーを装うボットを見抜くためのフィンガープリント技術を組み込みましょう。
重要コンテンツへの認証導入検討:最重要情報には認証やペイウォールの導入も有効です。これにより、正規・ステルスクローラー問わず制限できます。
クローラー手法の最新動向把握:回避技術は日々進化しています。セキュリティ情報や業界レポートをチェックし、防御策も常にアップデートしましょう。
現在のように、一部AI企業がrobots.txtを公然と無視し、他は遵守するという状況は長続きしません。すでに業界・規制側からの対応が進んでいます。**IETF(Internet Engineering Task Force)**は、AI訓練やデータ用途ごとにより細かい制御ができるrobots.txt拡張仕様を策定中です。これにより、検索エンジン用・AI訓練用など用途別の方針を記述できるようになります。
Web Bot Authという新しいオープン標準も提案され、クローラーがリクエストに暗号署名を施すことで、その正当性や身元を証明できるようになります。OpenAIのChatGPT Agentはすでにこの標準の実装を進めており、透明かつ検証可能なクローラー識別が技術的に実現しつつあります。
規制強化も視野に入っています。欧州連合のAI規制方針や、コンテンツ制作者・発行者の圧力を受け、今後はクローラー遵守が法的義務となる可能性もあります。robots.txtを無視する企業は、評判リスクだけでなく規制ペナルティの対象にもなり得ます。
業界は今、透明性と遵守が競争優位となるモデルへとシフトしつつあります。ウェブサイト管理者の意思を尊重し、明確なクローラー識別とコンテンツ提供者への価値還元を図る企業が信頼と持続的な関係を築けます。逆に、ステルスタクティクスに依存し続ける企業には、技術的・法的・評判上のリスクが増大していくでしょう。
ウェブサイト管理者にとって重要なのは、積極的な監視と強制執行です。上記のツールや手法を駆使して、AI時代のコンテンツ利用をコントロールし、オープンインターネットの原則を守る責任あるAI発展をサポートしましょう。
ステルスクローラーは、正規のWebブラウザを装い本当の出自を隠すことで、意図的に身元を偽装するクローラーです。通常のクローラーは独自のユーザーエージェントで自らを示し、robots.txtの指示に従いますが、ステルスクローラーは偽装ユーザーエージェントを使い、IPアドレスをローテーションし、さまざまな回避テクニックを用いて、明確にアクセス禁止されたコンテンツにも侵入します。
AI企業がrobots.txtを無視する主な理由は、大規模言語モデルの訓練のために大量のデータが必要だからです。最も価値の高いコンテンツは多くの場合、ウェブサイト管理者によって制限されているため、制限を回避する競争的なインセンティブが生まれます。さらに、実質的な強制力がほとんどなく、ウェブサイト側が技術的にクローラーを完全に防げず、法的手段も時間やコストがかかるため、robots.txtを無視した方がリスクよりも得るものが大きいのです。
すべてのステルスクローラーを完全に防ぐことはできませんが、多層防御によって無断アクセスを大幅に減らすことが可能です。明確なrobots.txtポリシーの運用、WAFルールの導入、デバイスフィンガープリントの活用、AmICitedのようなツールによるクローラー挙動の監視、そして重要なコンテンツには認証を検討しましょう。単一の対策に頼らず、複数の対策を組み合わせることが鍵となります。
ユーザーエージェントの偽装とは、クローラーが本物のWebブラウザ(たとえばChromeやSafari)を装い、現実的なユーザーエージェント文字列を使用することです。これにより、クローラーは人間の訪問者として振る舞うことができます。ステルスクローラーはこの手法を用いることで、単純なユーザーエージェントベースのブロックを回避し、ボット特有の識別子を検知するセキュリティシステムから逃れます。
不審な挙動を示すトラフィックパターンを分析することで、ステルスクローラーを検知できます。たとえば、異常なIPアドレスからのリクエスト、不可能なナビゲーションシーケンス、人間らしい操作の欠如、正規のブラウザフィンガープリントと一致しないリクエストなどです。AmICitedやCloudflareのAI Crawl Control、デバイスフィンガープリントソリューションなどのツールを使えば、多数のシグナルを同時に分析して自動検出できます。
クローラーの回避行為に対する法的評価は国や地域によって異なります。robots.txt違反は利用規約違反となる場合がありますが、公開情報のスクレイピング自体の法的扱いは曖昧です。裁判所によってはスクレイピングを合法とした事例もあれば、Computer Fraud and Abuse Act違反と判断した例もあり、この不透明さがグレーゾーンで活動する企業を後押ししていますが、規制強化の動きも出始めています。
AmICitedは、どのAIシステムが実際にあなたのブランドやコンテンツを引用しているかを可視化し、単なるクローラーのアクセスログ以上の情報を提供します。このプラットフォームはトラフィックパターンや行動シグナルを分析し、ステルスクローラーを特定。疑わしい活動をリアルタイムでアラートし、既存のSEO・セキュリティワークフローと連携してコンテンツ利用のコントロールを支援します。
宣言型クローラーは独自のユーザーエージェントを公開し、IPレンジも明示していて、robots.txtの指示にも従います。たとえばOpenAIのGPTBotやAnthropicのClaudeBotなどが該当します。一方、非宣言型クローラーは身元を隠してブラウザを偽装し、偽のユーザーエージェントを使い、意図的にウェブサイトの制限を無視します。Perplexityのステルスクローラーは、非宣言型クローラーの代表例です。
どのAIシステムがあなたのブランドを引用しているかを把握し、AmICitedの高度なモニタリングプラットフォームでステルスクローラーによるコンテンツアクセスを検知しましょう。
AIボットによるサイトクローリングを許可するかについてのコミュニティディスカッション。robots.txtの設定やllms.txtの実装、AIクローラー管理の実体験。...
GPTBot、PerplexityBot、ClaudeBotなどのAIボットによるサイトクロールの許可方法を解説します。robots.txt・llms.txtの設定やAI向け最適化の方法もわかります。...
GPTBot、ClaudeBot、PerplexityなどのAIクローラーのアクセスを制御するためのrobots.txt設定方法を解説。AI生成回答でのブランド露出を管理しましょう。...