
トークン
言語モデルにおけるトークンの意味を解説します。トークンはAIシステムにおけるテキスト処理の基本単位であり、単語・サブワード・文字を数値として表現します。AIのコストや性能を理解するために不可欠な要素です。...
1 分で読める

トークン制限がAIのパフォーマンスに与える影響を探り、RAG、チャンク分割、要約技術などを含むコンテンツ最適化の実践的戦略を学びましょう。
トークンは、AIモデルが情報を処理・理解するための基本的な構成要素です。大規模言語モデルは、完全な単語や文ではなく、トークンと呼ばれる小さな単位(個々の文字、サブワード、または単語)にテキストを分解します。各トークンには、モデルが内部で計算に利用する一意の数値識別子が割り当てられます。このトークナイゼーション処理は、AIシステムが可変長の入力を効率的に扱い、様々な種類のコンテンツで一貫した処理を実現するために不可欠です。トークンの仕組みを理解することは、AIシステムを扱うすべての人にとって重要であり、パフォーマンスやコスト、そして得られる成果の品質に直接影響します。
AIモデルごとに大きく異なるトークン制限は、1回のリクエストで処理可能な情報量の上限を定めています。この数年で大きく進化し、新しいモデルでははるかに大きなコンテキストウィンドウがサポートされています。トークン制限は、入力トークン(プロンプトやデータ)と出力トークン(モデルの応答)の両方を含みます。つまり、共有された予算をどのように管理するかが重要です。この制限を理解することは、用途に合ったモデル選択やアプリケーション設計の計画に不可欠です。
| モデル | トークン制限 | 主な用途 | コストレベル |
|---|---|---|---|
| GPT-3.5 Turbo | 4,096 | 短い会話、簡単なタスク | 低 |
| GPT-4 | 8,192 | 標準的なアプリケーション、中程度の複雑さ | 中 |
| GPT-4 Turbo | 128,000 | 長文書、複雑な分析 | 高 |
| Claude 3.5 Sonnet | 200,000 | 長文書、包括的な分析 | 高 |
| Gemini 1.5 Pro | 1,000,000 | 大規模データセット、全書籍、動画分析 | 非常に高い |
トークン制限を評価する際の主な考慮事項:
トークン制限は、AIアプリケーションの精度や信頼性、コスト効率に直接的な制約をもたらします。モデルのトークン上限を超えると、アプリケーションは完全に失敗します(段階的な劣化や部分的な処理はありません)。制限内でも、単純な切り捨て(トランケーション)など安易な方法では、モデルが正確な応答を生成するために必要な重要なコンテキストが失われ、パフォーマンスが大きく低下します。特に、法的分析、医療研究、ソフトウェア開発などの分野では、重要な詳細が1つでも欠落すると誤った結論につながるおそれがあります。さらに、コンテンツの種類によってトークン消費量が異なる点も複雑さを増しています。たとえば、コードやJSONなどの構造化データは、記号やフォーマットの影響でプレーンテキストよりも多くのトークンを必要とします。
トランケーションは、トークン制限に対応する最も単純な方法で、モデルの容量を超えたコンテンツを単純に切り捨てます。実装は簡単ですが、重大なリスクがあります。テキストを切り捨てると、情報が失われ、モデル側では何が削除されたかを知る手段がありません。そのため、分析が不完全になったり、抜けた情報を補うために誤った内容(ハルシネーション)を生成したりする可能性があります。
def truncate_text(text: str, max_tokens: int) -> str:
"""Simple truncation approach - not recommended for production"""
tokens = encode(text)
if len(tokens) > max_tokens:
truncated_tokens = tokens[:max_tokens]
return decode(truncated_tokens)
return text
# 例:4000トークンに切り捨て
long_document = load_document("legal_contract.pdf")
truncated = truncate_text(long_document, 4000)
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": truncated}]
)
より洗練されたトランケーション手法では、必須と任意のコンテンツを区別します。たとえば、現在のユーザーの問いやコアとなる指示などの必須要素を優先し、余裕があれば会話履歴などの任意コンテキストを追加します。こうすることで、重要な情報を残しつつトークン制限も遵守できます。
トランケーションではなく、チャンク分割はコンテンツを小さく扱いやすい単位に分割し、個別または選択的に処理できるようにします。固定サイズのチャンク分割はテキストを均等に区切り、セマンティックチャンク分割はエンベディングを利用して意味的な区切りで分割します。オーバーラップ付きのスライディングウィンドウを用いることで、チャンク間にまたがる重要な情報も保持できます。
階層的チャンク分割では、段落→セクション→章のように、複数レベルの抽象化を作成します。これにより、ドキュメント全体を処理しなくても関連セクションを素早く特定できる高度な検索戦略が可能になります。ベクターデータベースやセマンティック検索と組み合わせることで、大規模なナレッジベースを高い関連性と精度を保ちながら管理できます。
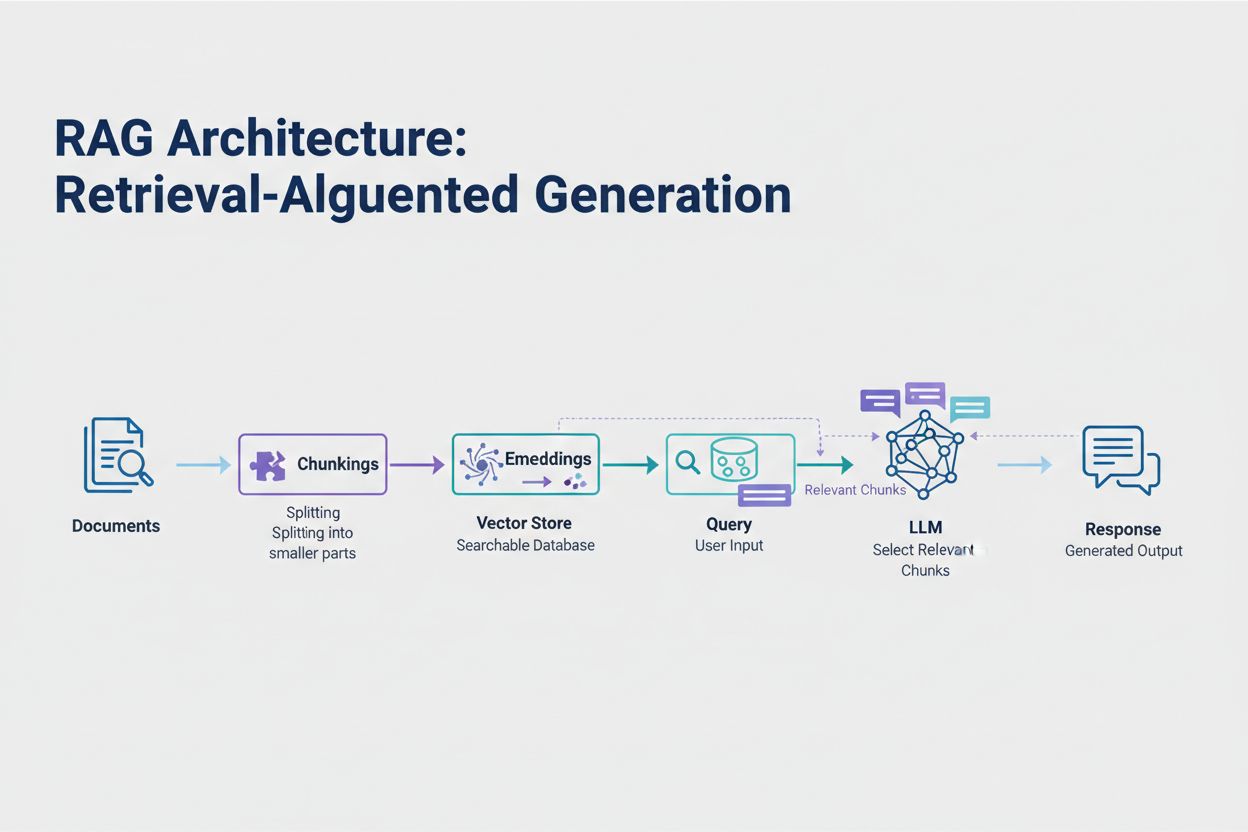
検索拡張生成(Retrieval-Augmented Generation、RAG)は、トークン制限への対処として最も効果的な現代的アプローチです。全データをモデルのコンテキストウィンドウに詰め込むのではなく、RAGはクエリ時に最も関連性の高い情報のみを検索・取得します。まず、ドキュメントを意味を捉えた数値ベクトル(エンベディング)に変換し、ベクターデータベースに保存します。
ユーザーがクエリを送信すると、システムはクエリもエンベディング化し、ベクトルストアから最も関連性の高いドキュメントチャンクを取得します。これら必要なチャンクだけをユーザーの質問と共にプロンプトに挿入することで、トークン消費を大幅に削減しつつ精度も向上します。たとえば、100ページの契約書分析でも、RAGならプロンプトに必要なのはわずか3~5の主要条項だけで済み、全ドキュメントを含める場合に比べて数千トークンの節約になります。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# ステップ1:ドキュメントの読み込みとチャンク分割
documents = load_documents("knowledge_base/")
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = splitter.split_documents(documents)
# ステップ2:エンベディングとベクトルストアの作成
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(chunks, embeddings)
# ステップ3:RAGチェーンのセットアップ
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
llm = ChatOpenAI(model="gpt-4", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
return_source_documents=True
)
# ステップ4:システムへのクエリ
result = qa_chain.run("What are the key terms of this contract?")
要約は、重要な情報を維持しつつ長文コンテンツを圧縮し、トークン消費を効率的に減らします。抽出型要約は元のテキストから重要な文を選び、抽象型要約は主旨を新たな簡潔な文章で表現します。階層型要約では、まず各セクションを要約し、それらをさらに高次の要約にまとめます。これは、論文や技術レポートなど構造化されたドキュメントによく適しています。
コンテキスト圧縮は、元の表現を保ちながら冗長や不要な内容を除去する方法です。ナレッジグラフ手法では、テキストからエンティティや関係を抽出し、最も関連性の高い事実だけでコンテキストを再構築します。これらの技術により、意味的な正確性を保ちながらトークン量を40~60%削減でき、本番システムのコスト最適化に有効です。
トークン管理は、AIアプリケーションのコストに直結します。推論時に消費する各トークンが課金対象となり、コストはトークン使用量に比例して増加します。トークン消費のモニタリングは、コスト構造の把握や最適化ポイントの特定に不可欠です。多くのAIプラットフォームは、トークンカウントツールやリアルタイムダッシュボードを提供し、どのクエリや機能が最も多くのトークンを消費しているかを可視化します。
有効なモニタリングにより、最適化の機会を発見できます。例えば、特定のクエリが恒常的にトークン制限を超えていたり、特定機能だけが過剰にリソースを消費している場合があります。こうしたパターンを把握することで、最適化戦略の選択が可能になります。大規模リクエストはより高性能(ただし高コスト)なモデルにルーティングしたり、RAGや要約の実装でコストを抑制するなど、実測値に基づく判断が重要です。
適切なトークン管理戦略の選択は、用途・パフォーマンス要件・コスト制約によって異なります。出典付き高精度な回答が必要なアプリケーションでは、情報の正確性を保ちつつトークン消費を管理できるRAGが有効です。長時間の会話型アプリケーションでは、会話履歴を要約して重要な決定やコンテキストのみを保持するメモリバッファリングが有効です。法務分析や研究ツールなど文書中心のアプリケーションでは、セマンティックチャンク分割と階層型要約の組み合わせが効果を発揮します。
いずれの戦略も、本番導入前にテストと検証が不可欠です。モデルのトークン制限を超えるテストケースを作成し、各戦略が精度・レイテンシ・コストにどのような影響を与えるかを評価します。回答の関連性、事実の正確性、トークン効率といった指標を測定し、要件を満たしているか確認してください。よくある落とし穴としては、重要な情報を失う過剰な要約、関連情報を見逃す検索システム、意味的に不適切な箇所で分割されたチャンクなどがあります。
モデルの高度化・効率化に伴い、トークン制限は拡大し続けています。スパースアテンションや効率的なトランスフォーマーなどの新技術により、大規模コンテキスト処理の計算コスト削減が期待されています。テキスト・画像・音声・動画を同時に扱うマルチモーダルモデルは、新たなトークナイゼーションの課題と可能性をもたらします。推論トークン(モデルが複雑な問題を「思考」するために使う特別なトークン)は、より高度な問題解決を可能にする一方で、慎重な管理が求められます。
今後の方向性は明らかです。コンテキストウィンドウの拡大やトークン処理の効率化が進む一方で、ボトルネックは単なる容量から、いかに賢く情報を選択・検索するかに移りつつあります。巨大なナレッジベースから最も関連性の高い情報だけを的確に抽出・利用できるシステムが求められ、RAGやセマンティック検索の重要性がますます高まっています。
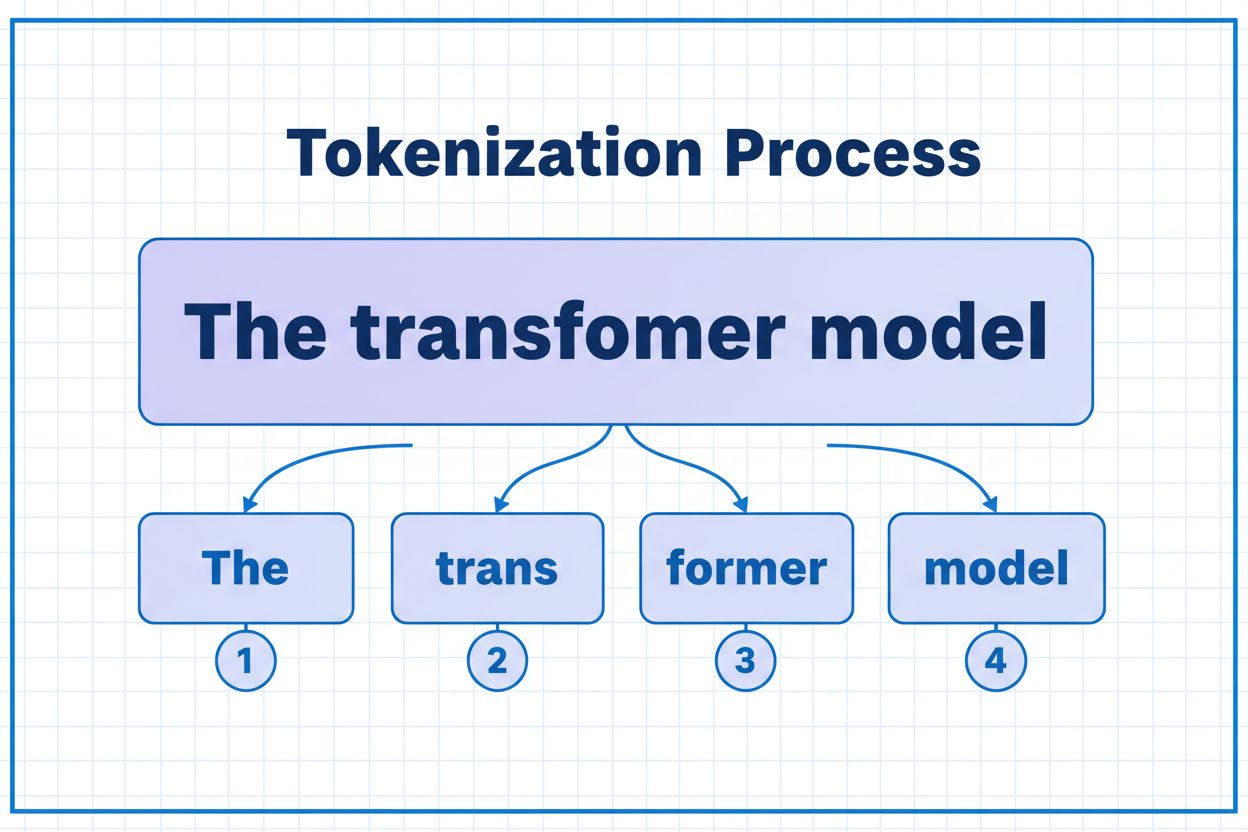
トークンは、AIモデルが処理するデータの最小単位です。トークンは、トークナイゼーションアルゴリズムによって、個々の文字、サブワード、または完全な単語となる場合があります。たとえば、「transformer」という単語は「trans」と「former」に分割され、2つの別々のトークンとなることがあります。それぞれのトークンには、モデルが内部で計算に使用する一意の数値識別子が割り当てられます。
トークン制限は、AIモデルが1回のリクエストで処理できる情報量の上限を定義します。この制限を超えると、アプリケーションは完全に失敗します。制限内であっても、単純な切り捨て(トランケーション)などのアプローチでは重要なコンテキストが削除され、精度が低下します。また、トークン制限はコストにも直接影響し、通常は消費されたトークン数に応じて料金が発生します。
入力トークンは、プロンプトやデータなど、モデルに送信するトークンです。一方、出力トークンは、モデルがレスポンスとして生成するトークンです。これらはモデルのコンテキストウィンドウによって定義された共通の予算を共有しています。たとえば、128Kトークンウィンドウの90%を入力で使用すると、出力用には残り10%しかありません。
トランケーションは実装が簡単ですがリスクがあります。どの情報が削除されたかわからず、分析が不完全になったり、モデルが誤った情報(ハルシネーション)を生成することがあります。最後の手段としては有用ですが、RAGやチャンク分割、要約などのより良いアプローチの方が、トークン消費を効果的に管理しつつ情報の正確性を保つことができます。
検索拡張生成(RAG)は、全ドキュメントを含めるのではなく、クエリ時に最も関連性の高い情報のみを取得します。ドキュメントはエンベディングに変換され、ベクターデータベースに保存されます。ユーザーがクエリを送信すると、システムは関連するチャンクのみを取得し、プロンプトに挿入します。これにより、トークン消費を劇的に削減し、精度も向上します。
ほとんどのAIプラットフォームはトークンカウントツールやリアルタイムダッシュボードを提供し、使用パターンを追跡できます。どのクエリや機能が最も多くのトークンを消費しているかを監視し、ドキュメント中心のアプリケーションではRAG、長い会話では要約、複雑なタスクではより大きなモデルへのルーティングなどの最適化戦略を実装してください。実際のパフォーマンスとコストを測定し、選択を検証しましょう。
AIサービスは通常、消費したトークン数に応じて課金されます。コストはトークン使用量に比例して増加するため、トークン最適化は直接的に費用削減につながります。トークン消費を20%削減すれば、コストも20%削減できます。トークン効率を理解することで、予算制約に合った最適な最適化戦略を選択できます。
モデルが高度になるにつれ、トークン制限も拡大し続けています。スパースアテンション機構などの新技術により、大規模コンテキストの処理コストが削減されることが期待されています。今後は、単なる処理能力よりも、インテリジェントなコンテンツ選択や検索が重視され、RAGのような技術がスケーラブルなAIアプリケーションにますます重要になります。
トークン効率を理解し、AmICitedの包括的なAI引用監視プラットフォームでAIモデルがあなたのブランドをどのように引用しているかを追跡しましょう。
言語モデルにおけるトークンの意味を解説します。トークンはAIシステムにおけるテキスト処理の基本単位であり、単語・サブワード・文字を数値として表現します。AIのコストや性能を理解するために不可欠な要素です。...

AIモデルがトークン化、埋め込み、トランスフォーマーブロック、ニューラルネットワークを通じてテキストをどのように処理するかを学びます。入力から出力までの完全なパイプラインを理解しましょう。...

会話型コンテキストウィンドウとは何か、それがAIの応答にどう影響するのか、そして効果的なAIとのやり取りになぜ重要なのかを学びましょう。トークン、制限、実践的な応用について理解できます。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.