
トレーニングデータ vs ライブ検索:AIシステムはどのように情報へアクセスするか
AIのトレーニングデータとライブ検索の違いを理解しましょう。知識カットオフ、RAG、リアルタイムリトリーバルがAIの可視性やコンテンツ戦略にどう影響するかを学びます。...
1 分で読める
トレーニングデータ最適化とリアルタイム検索は、AIモデルに知識を与える根本的に異なるアプローチです。トレーニングデータ最適化は、ドメイン固有データセットでファインチューニングすることで、知識をモデルのパラメータに直接埋め込み、学習完了後も変化しない静的知識を作ります。一方、リアルタイム検索は、知識をモデル外部に保持し、推論時に関連情報を動的に取得することで、リクエストごとに変化する動的情報へのアクセスを可能にします。最大の違いは、知識がモデルに統合される「タイミング」にあり、トレーニングデータ最適化はデプロイ前、リアルタイム検索は各推論ごとに行われます。この基本的な相違は、インフラ要件、精度特性、コンプライアンスまで、実装のあらゆる側面に影響します。この違いを理解することは、自社の利用ケースや制約に最適な戦略選択のために不可欠です。
トレーニングデータ最適化は、ファインチューニングの過程で厳選されたドメイン固有データセットにモデルを繰り返し露出させることで、モデル内部のパラメータを体系的に調整します。モデルが訓練例と何度も出会うことで、学習機構の重みやバイアスが更新され、専門用語やパターン、ドメイン知識を内面化します。このプロセスにより、医療用語や法的枠組み、独自ビジネスロジックなどの専門知識を、直接モデルの重みに組み込むことが可能です。結果として、対象ドメインに高度に特化したモデルが得られ、より大きなモデルに匹敵する性能も実現できます(Snorkel AIの研究では、小型モデルのファインチューニングで1,400倍規模のモデルと同等の性能を示しました)。主な特徴は以下の通りです:
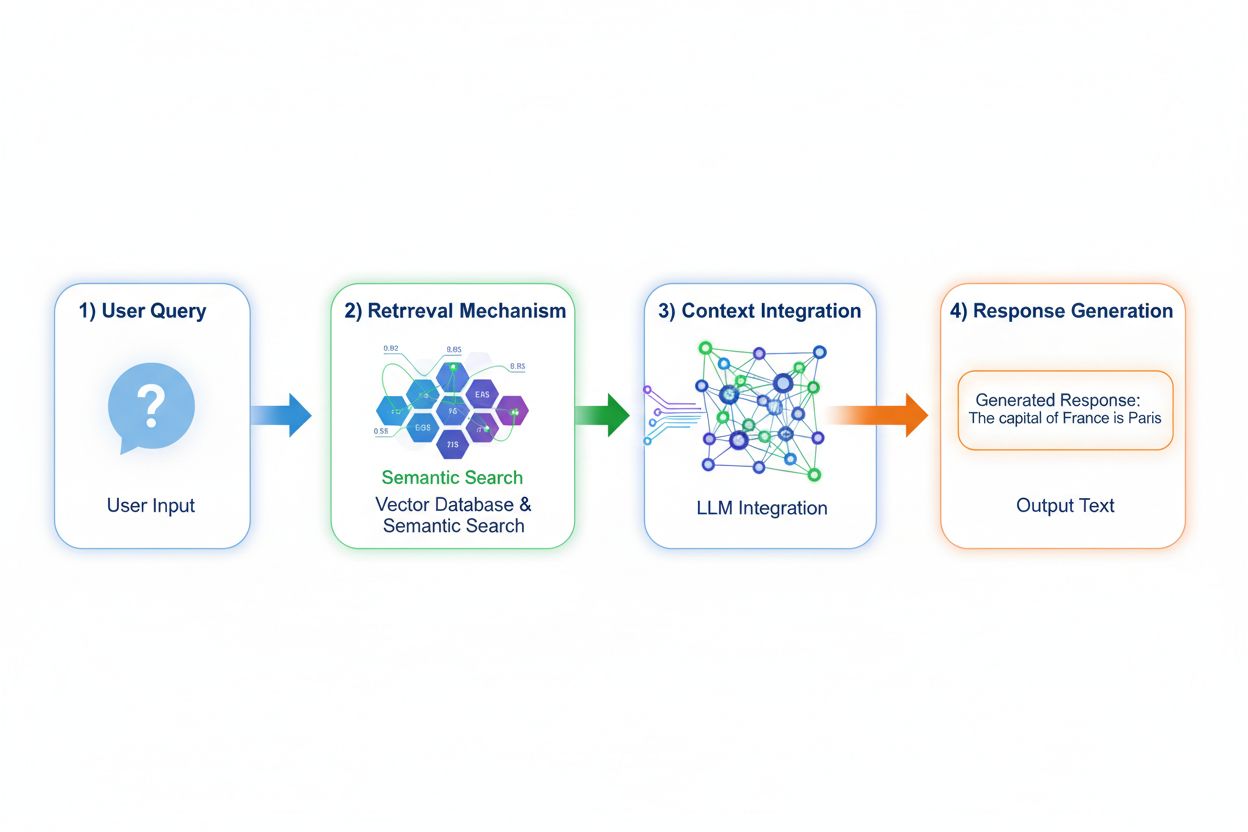
Retrieval Augmented Generation(RAG)は、クエリエンコード、意味検索、コンテキストランキング、出典付き生成の4段階プロセスを通じて、モデルの知識アクセス方法を根本的に変革します。ユーザーのクエリはまず埋め込みモデルで高次元ベクトルに変換され、ベクターデータベースのインデックス化されたドキュメントや知識ソースから検索されます。検索段階では、単なるキーワード一致ではなく意味検索で文脈的に関連するパッセージを抽出し、スコア順にランキング。最終的に、取得した情報を根拠としながら応答を生成し、出典を明示します。この仕組みにより、学習時に存在しなかった情報にもアクセスでき、常に最新データやプロプライエタリな知識が必要な応用に特に有用です。RAGメカニズムは、モデルを静的な知識倉庫から、新データを再学習なしに取り込む動的な知識統合機へと変貌させます。
両アプローチは、現場での運用に直結する精度・幻覚傾向に大きな違いがあります。トレーニングデータ最適化モデルはドメイン理解が深い一方、知識の限界を自覚しにくく、学習範囲外の質問にはもっともらしい誤答を自信満々に生成することがあります。RAGは取得文書に根ざして応答するため、出典に存在しない情報は主張できず、幻覚が大幅に減ります。ただし、検索段階で適切な情報が見つからなかったり、関連性の低い文書が高順位になると、不適切なコンテキストに基づいた応答が生じます。データの鮮度はRAGで特に重要で、トレーニングデータ最適化が学習時点の知識を固定的に反映するのに対し、RAGは常に最新のドキュメント状態を反映します。出典明示も大きな違いで、RAGは根拠や検証が容易ですが、ファインチューニングモデルは知識のソースを特定できず、ファクトチェックやコンプライアンス検証が難しくなります。
両手法は、組織が慎重に見極めるべき異なるコスト構造を生み出します。トレーニングデータ最適化は、モデルのファインチューニングのために高額な計算コスト(GPUクラスターの長時間稼働、ラベル付きデータ作成、MLエンジニアリング)が初期に発生します。学習後は、外部参照不要なため推論時の運用コストは比較的低く済みます。RAGはこの構造が逆転し、初期学習コストは低い一方で、インフラ(ベクターデータベース、埋め込みモデル、検索サービス、ドキュメントインデックス化)の維持費が継続的にかかります。主なコスト要素は以下の通り:
両手法は、規制業界におけるセキュリティとコンプライアンス面で大きく異なります。ファインチューニング済みモデルは、トレーニングデータがモデル重みに埋め込まれるため、何を記憶しているかの抽出や監査が困難です。また、機密データの影響下でモデルが動作することでプライバシー問題が発生し、GDPRなどの規制対応も難しくなります。一方、RAGは知識を外部データソースに保持するため、セキュリティ制御やアクセス制限が容易で、どのドキュメントが参照されたかを監査可能、ソースドキュメントの更新のみで機密情報の削除も迅速です。ただし、ベクターデータベースや埋め込みモデルの保護、取得ドキュメントによる情報漏洩リスクなど新たなセキュリティ課題もあります。HIPAA対応の医療機関やGDPR対象の欧州企業はRAGの透明性・監査性を重視し、ポータビリティやオフライン運用を優先する組織はファインチューニングを選びます。
どちらを選択するかは、組織の制約や利用ケース特性を評価することから始まります。ファインチューニングは、知識が安定的で頻繁に変わらない場合、推論遅延が重要、オフライン/閉域運用が必須、一貫したスタイルやフォーマットが必要な場合に最適です。リアルタイム検索は、知識が頻繁に変化する場合、出典明示や監査性が重要な場合、巨大な知識ベースが必要または更新頻度が高い場合に向いています。具体的な利用例は以下の通り:
ハイブリッドアプローチは、両者の長所を組み合わせ、個々の弱点を補完します。基本知識や表現パターンはファインチューニングで学習し、最新情報や詳細データはRAGで取得することで、「どう考えるか」は学習しつつ、「何を言うか」は動的に検索します。この統合戦略は、専門性と最新性が同時に求められる分野(例:投資原則をファインチューニングした金融アドバイザーボットが、RAGでリアルタイム相場や企業財務を取得)に特に効果的です。実際のハイブリッド実装例は、医療知識とプロトコルでファインチューニングした上で患者データをRAG取得するヘルスケアシステムや、法的推論をファインチューニングしつつ最新判例をRAG参照する法律リサーチプラットフォームなど。相乗効果として、幻覚の抑制(出典に根ざした回答)、ドメイン理解の深化(ファインチューニング)、頻出問い合わせへの高速応答(内部知識キャッシュ)、情報更新の柔軟性などがあります。現実のアプリケーション複雑化に伴い、この最適化アプローチの重要性は増しています。
大規模運用下で、どの最適化戦略がどの利用ケースに有効か把握するには、AI応答のリアルタイイム監視が不可欠です。AIモニタリングシステムは、モデル出力・検索品質・ユーザー満足度を追跡し、ファインチューニングモデルとRAGのどちらが自社用途に適しているかを測定します。引用追跡は両アプローチの違いを明確にし、RAGは自然に出典や引用を生成することで監査証跡が残りますが、ファインチューニングモデルには応答監視や出典明示の仕組みがありません。これはブランドセーフティや競合分析で大きな違いを生み、AIが競合や自社製品をどのように引用し、誰の情報を出典にしているかを可視化できます。AmICited.comのようなツールは、各戦略下でのブランド引用状況や頻度をリアルタイム追跡します。包括的なモニタリングを実装することで、選択した最適化戦略(ファインチューニング、RAG、ハイブリッド)が引用精度や競合に関する幻覚抑制、権威ある出典への適切な帰属に寄与しているかデータで判断可能です。現実の運用データに基づいた継続的な最適化戦略の洗練が可能になります。
業界は、クエリ特性や知識要求に応じて最適化戦略を動的に選択する、より高度なハイブリッド・アダプティブアプローチへ進化しています。最新のベストプラクティスでは、RAGで取得した情報の効果的活用法を学習させる「検索拡張ファインチューニング」や、安定知識はファインチューニングモデル、動的情報はRAGにルーティングするアダプティブシステムが広がっています。トレンドとして、ドメイン特化型埋め込みモデルやベクターデータベースの活用が進み、より精密な意味検索や検索ノイズ低減が実現。継続モデル改善のパターンとして、定期的なファインチューニングとリアルタイムRAG拡張を組み合わせ、知識の鮮度と性能を両立する仕組みも生まれています。最適化戦略の進化は、単一手法で全ての利用ケースに対応できないという業界の認識を反映しており、今後はクエリ文脈・知識安定性・遅延要件・コンプライアンス制約に応じて、ファインチューニング、RAG、ハイブリッドを動的に選択するインテリジェントシステムが主流となるでしょう。これら技術が成熟するにつれ、競争優位性は「どちらか一方の選択」ではなく、各戦略の強みを活かしたアダプティブシステムの巧みな実装にシフトしていきます。
トレーニングデータ最適化は、ファインチューニングによって知識をモデルのパラメータに直接埋め込み、学習後は固定された静的知識を作ります。リアルタイム検索は知識を外部に保持し、推論時に動的に関連情報を取得することで、リクエストごとに変化しうる動的情報へのアクセスを可能にします。最大の違いは知識を統合するタイミングであり、トレーニングデータ最適化はデプロイ前、リアルタイム検索は推論ごとに行われます。
知識が安定して頻繁に変わらない場合、推論の遅延が重要な場合、モデルがオフラインで動作する必要がある場合、または一貫したスタイルやドメイン固有のフォーマットが必須の場合はファインチューニングを推奨します。ファインチューニングは医療診断、法的文書分析、安定した商品情報を扱うカスタマーサービスなどの特化型タスクに最適です。ただし、ファインチューニングには多大な計算リソースが必要で、情報が頻繁に変わる場合は非現実的です。
はい、ハイブリッドアプローチでファインチューニングとRAGの両方の利点を活かせます。基礎知識にはファインチューニング、最新かつ詳細な情報にはRAGを使うことで、専門性と鮮度の両方が求められるアプリケーション(例:金融アドバイザリーボットや医療知識+患者データが必要なヘルスケアシステム)に有効です。
RAGは取得したドキュメントに基づき回答を生成するため、出典にない情報をモデルが主張できず、自然な制約が生まれます。一方でファインチューニング済みモデルは、学習分布外の質問に対してもっともらしいが誤った情報を自信を持って生成することがあります。RAGは出典の明示で検証も容易ですが、ファインチューニング済みモデルは知識のソースを指摘できません。
ファインチューニングは多大な初期コストを要します(GPU稼働:1モデルあたり1万〜10万ドル以上、データアノテーション:1例あたり0.5〜5ドル、エンジニア工数)。学習後の運用コストは比較的低いです。RAGは初期費用は低めですが、ベクターデータベースや埋め込みモデル、検索サービスなどインフラ費用が継続的にかかります。ファインチューニングモデルは推論量に比例してスケールし、RAGは推論量と知識ベース規模の両方に依存します。
RAGシステムは自然に引用や出典を生成するため、どのドキュメントが各回答に影響したかの監査証跡が残せます。これはブランドセーフティや競合分析に不可欠で、AIが競合や自社製品をどのように引用しているか追跡できます。AmICited.comのようなツールは、様々な最適化戦略下でブランド引用状況をリアルタイム監視します。
医療や金融などのコンプライアンス重視業界では、外部かつ監査可能なデータソースに知識を保持するRAGが一般的に好まれます。アクセス制御やセキュリティ管理も容易で、モデルが参照したドキュメントの監査や、機密情報の迅速な削除も可能です。HIPAAやGDPR対象組織ではRAGの透明性・監査性が重視されます。
モデル出力・検索品質・ユーザー満足度などを追跡するAIモニタリングシステムを導入しましょう。RAGでは検索精度や引用品質、ファインチューニングモデルではタスク精度や幻覚率を監視します。AmICited.comのようなツールで引用状況や各戦略の実際の成果を比較し、最適化戦略の効果をデータで把握できます。
GPTs、Perplexity、Google AI Overviews でのリアルタイム引用を追跡。競合がどの最適化戦略を使い、AI回答でどのように言及されているかを把握しましょう。
AIのトレーニングデータとライブ検索の違いを理解しましょう。知識カットオフ、RAG、リアルタイムリトリーバルがAIの可視性やコンテンツ戦略にどう影響するかを学びます。...
AIトレーニングデータへの掲載を目指したコンテンツ最適化の方法を学びましょう。正しいコンテンツ構造、ライセンス設定、オーソリティ構築を通じて、ChatGPT・Gemini・PerplexityなどのAIシステムによるウェブサイト発見性を高めるベストプラクティスを紹介します。...
AIにおけるリアルタイム検索の仕組みや、ユーザーやビジネスにもたらすメリット、従来の検索エンジンや静的なAIモデルとの違いについて解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.