
埋め込み
埋め込みとは何か、どのように機能し、なぜAIシステムに不可欠なのかを解説します。テキストが検索、RAG、AIモニタリングのために意味を捉える数値ベクトルへと変換される仕組みを知りましょう。...
1 分で読める

ベクトル埋め込みがAIシステムに意味的な理解をもたらし、コンテンツとクエリのマッチングを可能にする仕組みを学びましょう。意味検索やAIによるコンテンツマッチングの技術を探ります。

ベクトル埋め込みは、現代の人工知能システムを支える数値的基盤であり、生データを機械が理解・処理できる数理的表現に変換します。埋め込みの本質は、テキスト、画像、音声など多様なコンテンツを、それぞれ数十から数千次元の配列に変換し、そのデータの意味や文脈的な関係性を捉えることです。この数値表現は、AIシステムがコンテンツマッチング、意味検索、レコメンデーションなどのタスクを実現するうえで不可欠であり、単なる単語や画像の存在だけでなく、その「意味」を理解することを可能にします。埋め込みがなければ、AIシステムは概念間の微妙な関係を把握できず、現代AIアプリケーションの基盤として不可欠なインフラとなっています。
生データからベクトル埋め込みへの変換は、巨大なデータセットで有意義なパターンや関係性を学習した高度なニューラルネットワークモデルによって実現されます。テキストを埋め込みモデルに入力すると、複数のニューラルネットワーク層を通過しながら意味情報を抽出し、最終的にコンテンツの本質を表す固定サイズのベクトルに変換されます。代表的な埋め込みモデルにはWord2Vec、GloVE、BERTなどがあり、それぞれ異なるアプローチを取ります。Word2Vecは速度重視の浅いニューラルネットワーク、GloVEはグローバルな行列分解と局所的な文脈ウィンドウの組み合わせ、BERTは双方向の文脈理解のためのトランスフォーマーアーキテクチャを活用しています。
| モデル | データタイプ | 次元数 | 主な用途 | 主な利点 |
|---|---|---|---|---|
| Word2Vec | テキスト(単語) | 100-300 | 単語間関係の把握 | 高速・効率的 |
| GloVE | テキスト(単語) | 100-300 | 意味的関係の把握 | グローバルとローカル文脈の融合 |
| BERT | テキスト(文・文書) | 768-1024 | 文脈理解 | 双方向文脈認識 |
| Sentence-BERT | テキスト(文) | 384-768 | 文の類似性 | 意味検索に最適化 |
| Universal Sentence Encoder | テキスト(文) | 512 | クロス言語タスク | 言語非依存 |
これらのモデルは高次元ベクトル(多くは300〜1,536次元)を生成し、各次元が文法的特性から概念的関係まで、異なる意味的側面を捉えます。この数値表現の魅力は、数学的演算が可能な点にあります。ベクトル同士の加減算や比較により、生テキストでは見えない関係性を発見できます。この数学的基盤こそが、意味検索やインテリジェントなコンテンツマッチングを大規模に実現する原動力となっています。
埋め込みの真価が発揮されるのは、意味的類似性を通じて異なる単語やフレーズがベクトル空間上で本質的に同じ意味であると認識できる点にあります。効果的に作られた埋め込みでは、意味的に近い概念が高次元空間上で自然にクラスター化されます。たとえば「king」と「queen」、「car」と「vehicle」など、異なる単語でも近くに配置されます。この類似性を測るため、AIシステムはコサイン類似度(ベクトル間の角度を測定)やドット積(大きさと方向)などの距離尺度を用い、2つの埋め込みがどれほど近いかを数値化します。例えば、「automobile transportation」に関するクエリは、「car travel」に関する文書と高いコサイン類似度を持ち、キーワード一致ではなく意味によるマッチングが可能となります。この意味理解こそが、現代のAI検索と単純なキーワード一致を分けるものであり、ユーザーの意図を理解し、真に関連性の高い結果を提供する要となっています。
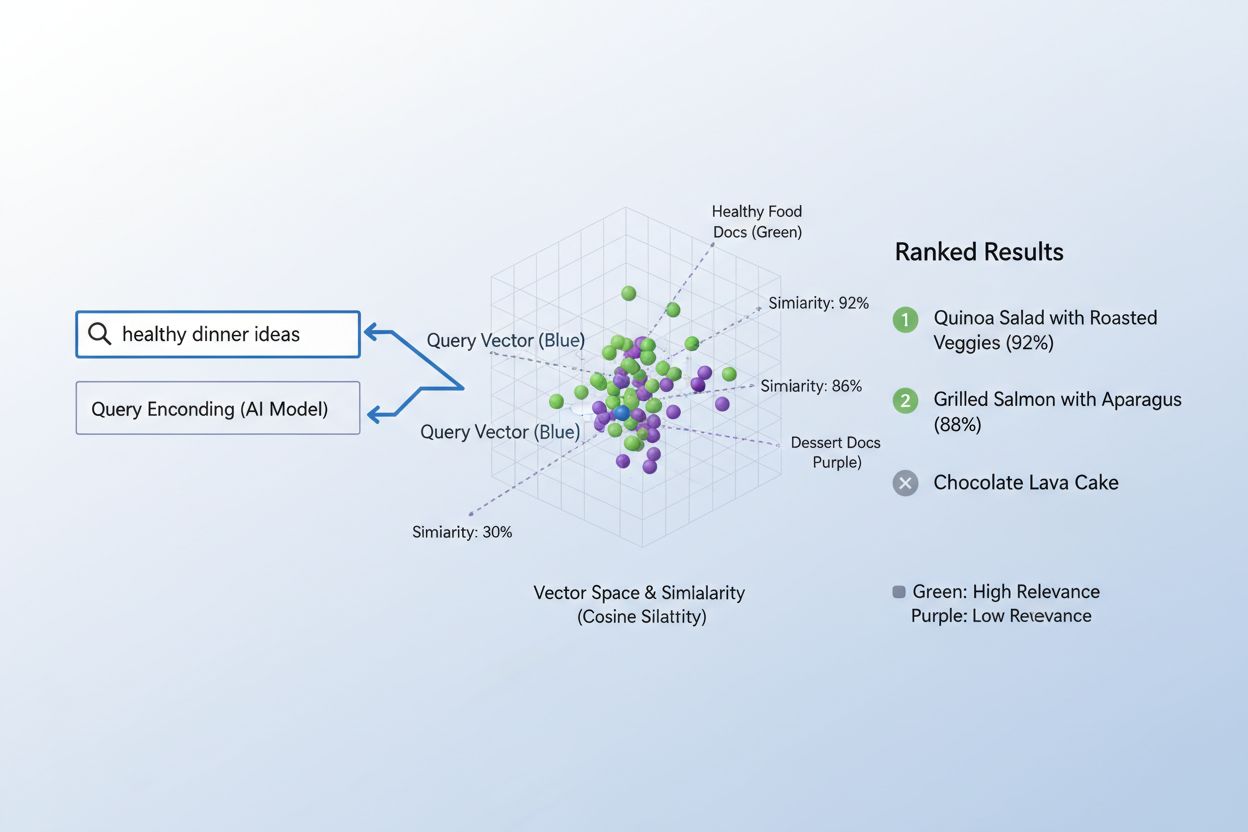
埋め込みを用いたコンテンツとクエリのマッチングは、検索エンジンからレコメンデーションシステムまで支える、洗練された2ステップのワークフローに従っています。まず、ユーザーのクエリと登録済みのコンテンツが同じモデルでそれぞれ埋め込み化されます(例:「機械学習のベストプラクティス」というクエリや、各記事・商品など)。次に、クエリ埋め込みとすべてのコンテンツ埋め込みとの類似度を計算し(通常はコサイン類似度)、各コンテンツの関連度スコアを出します。このスコアでランキングし、もっとも高いものがユーザーに「最も関連性の高い結果」として提示されます。実際の検索エンジンでは、「ニューラルネットワークの訓練方法」で検索すると、クエリが埋め込み化され、何百万もの文書埋め込みと比較され、深層学習や最適化、訓練手法の記事が返されます。これがミリ秒単位で行われるため、何百万人ものユーザーにリアルタイムでサービス提供が可能です。
埋め込みの種類によって用途も異なります。単語埋め込みは単語ごとの意味を捉え、細かな意味理解を要するタスクに適します。一方、文埋め込みや文書埋め込みはより長いテキスト全体の意味を集約し、クエリ全体と文書全体のマッチングに適しています。画像埋め込みはビジュアルコンテンツを数値化して類似画像の検索やテキストとのマッチングを可能にし、ユーザー埋め込みや商品埋め込みは行動パターンや特性を表現し、レコメンドシステムの推論を支えます。これらの選択にはトレードオフがあり、単語埋め込みは計算効率が高いものの文脈を失いがち、文書埋め込みは意味を保つ反面計算コストが高くなります。医療や法務など特化分野でファインチューニングされたドメイン特化型埋め込みは、一般モデルより高い精度を発揮しますが、追加の訓練データや計算資源が必要です。
実際、埋め込みは私たちの日常的なAI体験を支えています。意味検索エンジンはユーザーの意図を把握し、キーワード一致に頼らず関連コンテンツを提示します。Netflix、Amazon、Spotifyなどのレコメンドシステムはユーザーやアイテムの埋め込みを活用して「次に観たい」「買いたい」「聴きたい」を予測します。コンテンツモデレーションではユーザー投稿と既知の違反コンテンツの埋め込みを比較し有害コンテンツを検出、QAシステムはユーザーの質問と知識ベース記事を意味的にマッチングします。パーソナライゼーションエンジンは埋め込みで好みを理解し体験を最適化、異常検知は新データが既存クラスタから外れることを検出します。AmICitedでは、埋め込みを活用してAIシステムの利用状況をインターネット全体でモニタリングし、ユーザーのクエリやコンテンツをマッチングすることで、AI生成・支援コンテンツの出現箇所を追跡し、ブランドのAI上での存在感や帰属の適正を可視化しています。
埋め込みの実装には、パフォーマンスやコストに影響する技術的要素への注意が欠かせません。モデル選択は重要で、BERTのような大規模モデルは高品質な埋め込みを生成しますが、軽量モデルより処理負荷が高くなります。次元数もトレードオフとなり、高次元はより多くの意味を捉えますが、メモリ消費や計算速度に影響します。大規模なマッチングにはFAISSやAnnoyなどのインデックス戦略が用いられ、木構造や局所感度ハッシュによりミリ秒単位の高速探索を実現します。ドメイン特化型のファインチューニングは特定分野の精度向上に効果的ですが、ラベル付きデータや追加の計算コストが必要です。組織はユースケースや制約に応じて、速度と精度、計算コストと意味品質、汎用と特化モデルのバランスを継続的に検討する必要があります。
埋め込みの未来は、より高機能・高効率化と、広範なAIシステム統合へと進化し、より強力なコンテンツマッチングと理解力を実現します。マルチモーダル埋め込みはテキスト・画像・音声を同時に扱い、異なるコンテンツ間のマッチングを可能にし、これまでにない発見や理解の可能性を広げています。より少ないパラメータで同等の意味品質を実現する効率的なモデル開発も進み、先進的なAI機能が中小規模組織やエッジデバイスにも普及しつつあります。埋め込みと大規模言語モデルの統合によって、意味マッチングだけでなく文脈・ニュアンス・意図の深い理解を実現するシステムが生まれています。AIの普及に伴い、コンテンツのマッチングや利用状況の透明性・可視化の重要性が増しており、AmICitedのようなプラットフォームは埋め込みを活用してブランドのAI上での存在感や利用パターンを監視し、適切な帰属や利用の保証を支援します。より優れた埋め込み、高効率モデル、洗練されたモニタリングツールの融合によって、AIシステムの透明性・説明責任・人間の価値観への整合が進む未来が拓かれています。
ベクトル埋め込みとは、データ(テキスト、画像、音声など)の意味的な意味や関係性を捉える高次元空間上の数値表現です。抽象的なデータを機械が処理・分析できる数値配列に変換することで、意味を把握できるようにします。
埋め込みは抽象的なデータを機械が処理できる数値に変換し、AIがコンテンツ間のパターンや類似性、関係性を特定できるようにします。この数値表現により、AIは単なるキーワード一致ではなく意味を理解できるようになります。
キーワード一致は厳密な単語の一致を探しますが、意味的類似性は意味を理解します。これにより、たとえば「automobile」と「car」のように異なる単語でも意味的な関係に基づいて関連コンテンツを見つけることができます。
はい、埋め込みはテキスト、画像、音声、ユーザープロフィール、商品など、さまざまなデータを表現できます。テキストにはWord2Vec、画像にはCNN、音声にはスペクトログラムなど、データタイプごとに最適化されたモデルがあります。
AmICitedは埋め込みを活用し、異なるAIプラットフォームや応答においてAIシステムがあなたのブランドを意味的にどのようにマッチ・参照しているかを理解します。これにより、AI生成回答でのコンテンツの存在を追跡し、適切な帰属を保証します。
主な課題には、適切なモデルの選択、計算コストの管理、高次元データの取り扱い、特定分野へのファインチューニング、類似性計算での速度と精度のバランスなどがあります。
埋め込みは意味検索を可能にし、ユーザーの意図を理解して意味に基づく関連結果を返します。これにより、クエリと完全に一致しなくても概念的に関連するコンテンツが見つかるようになります。
大規模言語モデルは内部で埋め込みを使ってテキストを理解・生成しています。埋め込みは、これらのモデルが情報を処理し、コンテンツをマッチさせ、文脈に合った応答を生成するための基盤です。
ベクトル埋め込みはChatGPT、Perplexity、Google AI OverviewsなどのAIシステムを支えています。AmICitedはこれらのシステムがあなたのコンテンツをどのように引用・参照しているかを追跡し、AI生成回答でのブランドの存在感を理解するのに役立ちます。
埋め込みとは何か、どのように機能し、なぜAIシステムに不可欠なのかを解説します。テキストが検索、RAG、AIモニタリングのために意味を捉える数値ベクトルへと変換される仕組みを知りましょう。...

ベクトル検索は、数学的なベクトル表現を用いて意味的な関係を測定することで類似データを見つけます。埋め込み、距離指標、AIシステムがベクトル検索をどのように用いて意味理解を実現するか学びましょう。...

ベクトル検索と、それがAIコンテンツ発見をどのように支えるかについてのコミュニティディスカッション。セマンティックマッチングに向けたコンテンツ最適化を実践するテクニカルマーケターの実体験。...