
AIにおけるインフォメーショナル検索意図とは? 定義と例
AIシステムにとってインフォメーショナル検索意図とは何か、AIがこれらのクエリをどのように認識するのか、そしてこの意図を理解することがAI搭載検索エンジンやチャットボットでのコンテンツの可視性にとってなぜ重要なのかを学びましょう。...
1 分で読める
大規模言語モデルがどのようにユーザーインテントをキーワード以上に解釈するかを学びましょう。クエリの拡張、セマンティックな理解、そしてAIシステムがどのコンテンツを回答に引用するかをどのように決定するのかを解説します。
AI検索におけるユーザーインテントとは、誰かが入力したキーワードそのものではなく、その背後にある本質的な目的やゴールを指します。たとえば「おすすめのプロジェクト管理ツール」と検索した場合、一部の人は比較を求め、価格情報や連携機能を探しているかもしれません。ChatGPT、Perplexity、GoogleのGeminiのような大規模言語モデル(LLM)は、あなたが実際にどの目的を持っているかを理解しようとしています。従来型の検索エンジンがキーワードとページをマッチングするのに対し、LLMはクエリのセマンティック(意味的)な意味合いを、文脈や表現方法、関連するシグナルから分析し、本当に達成したいことを予測します。このキーワードマッチングからインテント理解への転換は、現代AI検索システムの根本的な特徴であり、AI生成回答でどの情報源が引用されるかを直接左右します。AmICitedのようなツールがインテント整合性に基づくAIシステムのコンテンツ参照状況をモニターする現在、ユーザーインテントの把握はブランドのAI検索での可視性確保に不可欠となっています。
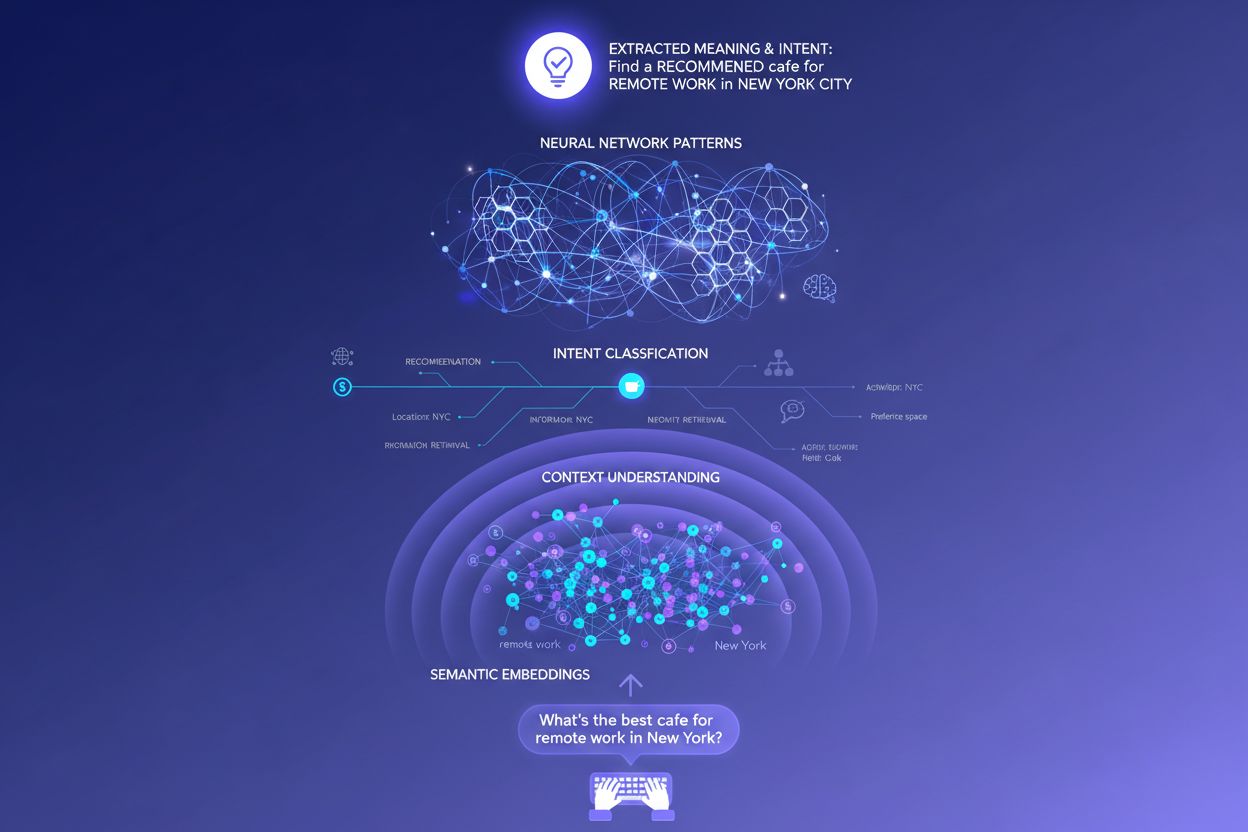
AI検索システムに1つのクエリを入力すると、舞台裏で驚くべきことが起こります。モデルは単に直接回答を出すのではなく、クエリを数十の関連するマイクロクエスチョンへ拡張します。研究者たちはこのプロセスを「クエリファンアウト」と呼びます。例えば「Notion vs Trello」と検索すると、「チーム協働に強いのは?」「価格の違いは?」「Slackと連携しやすいのは?」「初心者に使いやすいのは?」など、サブクエリが発生します。これによりLLMはあなたの意図の様々な側面を探り、より包括的な情報を集めて回答します。さらにシステムは異なる情報源のパッセージ(文章単位)を細かく評価し、ページ全体をランキングするのではなく、あなたのコンテンツの1パラグラフだけが選ばれることもあります。このパッセージレベルの解析があるからこそ、各セクションの明晰さと具体性がこれまで以上に重要です。特定のサブインテントに明確に答えた構造化コンテンツこそが、AI生成回答に引用される理由となり得ます。
| 元のクエリ | サブインテント1 | サブインテント2 | サブインテント3 | サブインテント4 |
|---|---|---|---|---|
| 「おすすめのプロジェクト管理ツール」 | 「リモートチーム向けでおすすめは?」 | 「価格は?」 | 「Slackと連携できるのは?」 | 「初心者に使いやすいのは?」 |
| 「生産性を上げるには」 | 「時間管理に役立つツールは?」 | 「実績ある生産性向上法は?」 | 「気が散るのを防ぐには?」 | 「集中力を高める習慣は?」 |
| 「AI検索エンジンの仕組み」 | 「Googleとの違いは?」 | 「どのAI検索が最も正確?」 | 「プライバシー対策は?」 | 「AI検索の将来は?」 |
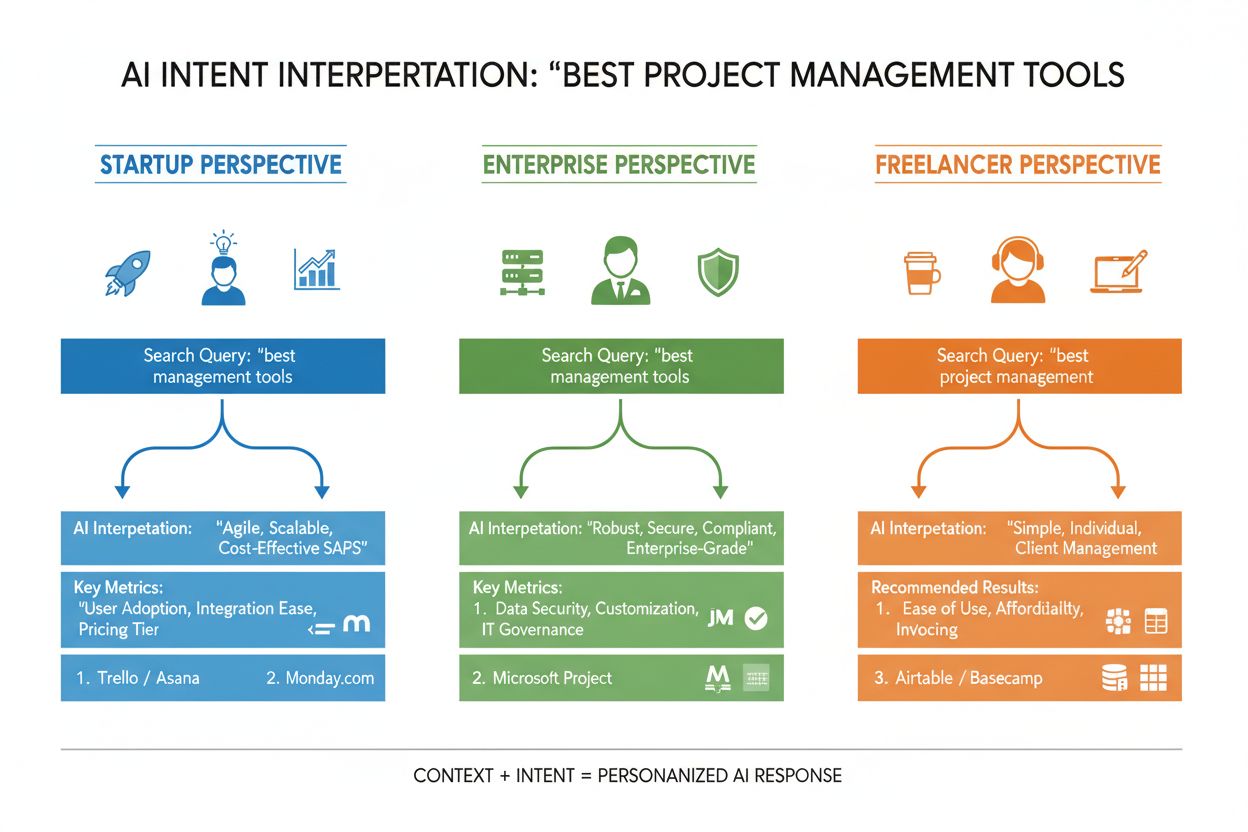
LLMはクエリを単独で評価するのではなく、研究者が**「ユーザーエンベディング」**と呼ぶ、検索履歴・位置情報・デバイス・時間帯・過去の会話履歴などに基づいたベクトルプロファイルを構築し、ユーザーの意図の変化を把握します。この文脈理解により、システムは検索結果を劇的にパーソナライズします。たとえば「おすすめのCRMツール」と検索しても、スタートアップ創業者と大企業のマネージャーでは全く異なるレコメンドを受け取る可能性があります。リアルタイム再ランキングも加わり、クリックや閲覧、追加質問などユーザーの行動に応じて意図の解釈を即座に修正し、次のレコメンドを調整します。このフィードバックループにより、AIシステムは「ユーザーが本当に求めているもの」を常に学習し続けるのです。コンテンツ制作者やマーケターにとっては、あらゆるユーザー文脈・意思決定段階のインテントを満たすコンテンツ設計がますます重要になっています。
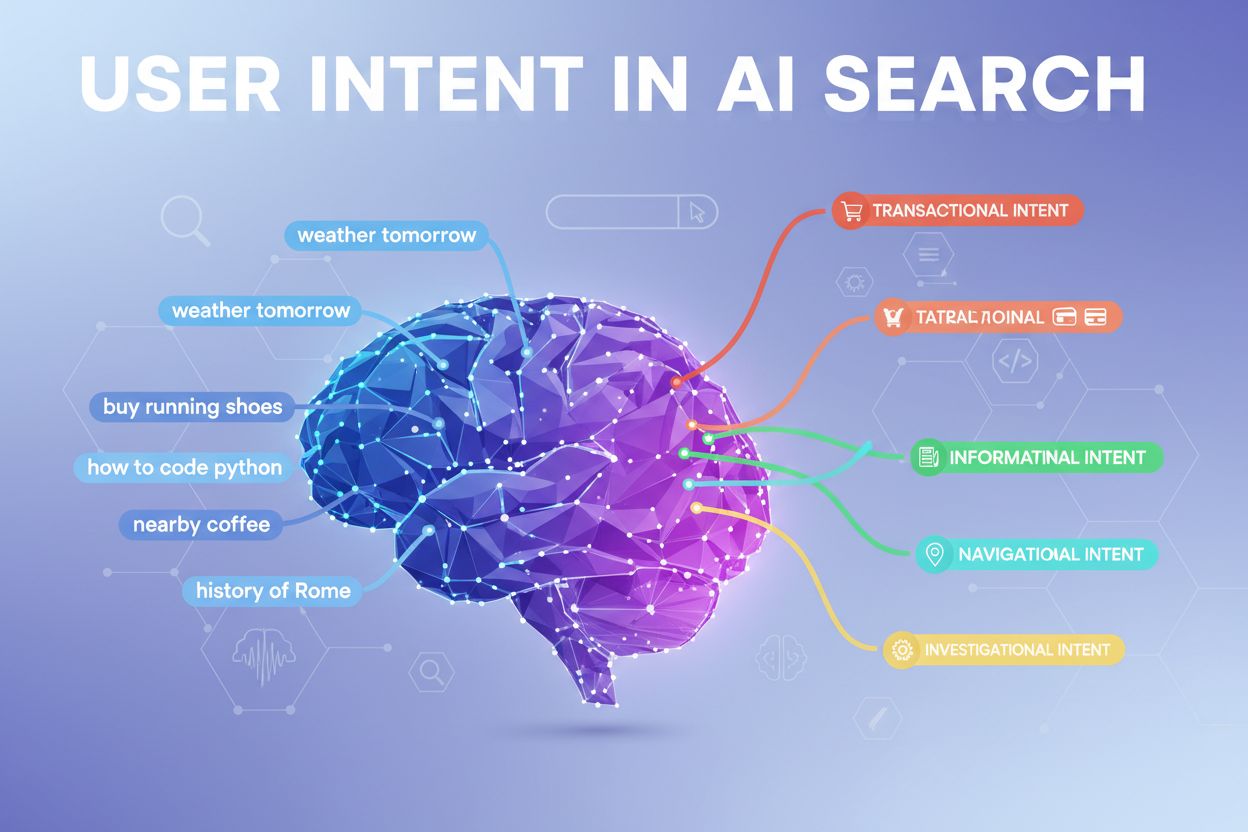
現代のAIシステムはユーザーインテントをいくつかの主要カテゴリに自動分類し、それぞれに異なるコンテンツや応答が求められます。
LLMはクエリ構造・キーワード・文脈シグナルを分析してこれらインテントを自動分類し、検出されたインテント種別に最適なコンテンツを選択します。こうしたカテゴリの理解は、ユーザーの検索インテントに的確に応えるページ構成に役立ちます。
従来型検索エンジンは単純な文字列マッチで動作し、ページ内に検索ワードがあれば上位表示を狙えました。しかしこの手法は、同義語や言い換え、文脈に極端に弱いのが難点です。例えば「安価なプロジェクト管理ソフト」と検索しても、ページに「budget-friendly task coordination platform」と書かれていれば従来検索は結びつけられないかもしれません。セマンティックエンベディングはこの課題を解決します。単語やフレーズを意味を反映した多次元ベクトルに変換し、意味的に近い概念が空間上でクラスター化されます。LLMはこれにより「affordable」「budget-friendly」「inexpensive」「low-cost」など異なる表現でも同じインテントを認識可能です。さらに、ロングテールや会話的クエリにも強く、「フリーランサー向けでシンプルかつパワフルなものが欲しい」といった従来のキーワードに合致しない検索にも対応できます。結果としてAIシステムは、曖昧・複雑・型破りなクエリにも関連情報を提示でき、従来型検索エンジンより大幅に有用性が向上しています。
インテント解釈の技術的中核はトランスフォーマーアーキテクチャです。これは「アテンション」と呼ばれる仕組みで単語間の関係性を解析するニューラルネットワーク設計です。人間のように順番に読むのではなく、トランスフォーマーはクエリ内の各単語同士の関係を一斉に評価し、細やかな意味や文脈を捉えます。セマンティックエンベディングはこの過程で生成される数値ベクトルであり、単語・フレーズ・概念ごとに意味を符号化します。BERT(Bidirectional Encoder Representations from Transformers)やRankBrainなどのモデルは、たとえば「startups向けベストCRM」と「新規企業向けトップ顧客管理プラットフォーム」のように、全く異なる言葉でも同じ意図を表すことを理解できます。アテンションメカニズムは、クエリ内で最も重要な部分に焦点を当てられる点が特に強力です。たとえば「リモートチーム・限られた予算向けプロジェクト管理ツール」であれば、「リモートチーム」「限られた予算」を主要な意図シグナルと認識できます。この技術的洗練が、現代AI検索を従来型キーワード重視システムよりも知的に感じさせる理由です。
LLMがインテントをどう解釈するかを理解することは、コンテンツ戦略を根本から変えます。従来のように単一キーワードで包括的なガイドを作るのではなく、複数のサブインテントに対応した独立性の高いモジュール型セクションを設けるのが成功の鍵です。プロジェクト管理ツールについて書く場合、1つの巨大な比較記事よりも、「リモートチーム向けでおすすめは?」「最も安価な選択肢は?」「Slack連携はどれ?」など個別に答えるセクションを作りましょう。各セクションはLLMに引用される「回答カード」候補となります。引用されやすいフォーマットも極めて重要です。曖昧な表現より事実を、具体的な数値や日付を盛り込み、AIが引用・要約しやすい構造にしましょう。箇条書き・明確な見出し・短いパラグラフは、密度の高い長文よりもLLMに解析されやすくなります。AmICitedのようなツールを使えば、ChatGPT・Perplexity・Google AI上で自社コンテンツがどのように参照・引用されているかをモニターでき、インテント整合性の成果や不足部分を明確にできます。AIシステムが実際にどう解釈・引用するかに最適化するデータドリブンなコンテンツ戦略は、従来SEOとは根本的に異なる発想です。
例えばECサイトの場合、「2万円以下の防水ジャケット」と検索するユーザーは、耐久性・価格・おすすめ商品の複数インテントを同時に示しています。AIシステムはこれを、防水技術・価格比較・ブランドレビュー・保証情報などのサブクエリへ展開します。こうした観点をモジュール型かつ構造的に網羅したコンテンツほど、AI生成回答で引用されやすくなります。SaaS領域では、「このワークスペースにチームを招待する方法は?」という同一クエリがサポートログに何百回も登場する場合、重大なコンテンツギャップのシグナルとなります。自社ドキュメントを学習したAIアシスタントでも明確な回答ができないと、ユーザー体験が損なわれ、AI生成のサポート回答での可視性も低下します。ニュースや情報系では、「AI規制の現状は?」といったクエリも、政策担当者・ビジネスリーダー・技術者などユーザー文脈により求められる情報が異なります。成功するコンテンツは、こうした多様なインテント文脈を明示的にカバーしています。
LLMは高度な仕組みを持ちながらも、インテント解釈でいくつかの課題に直面しています。曖昧なクエリ(例:「Java」)は、プログラミング言語・島名・コーヒーのどれかを特定できないことがあります。混合・複層的インテントも問題です。「このCRMはSalesforceより優れていて、無料でお試しできる?」は比較・評価・トランザクションの意図が混在しています。また文脈ウィンドウの制約により、LLMは会話履歴を一定量しか保持できず、長い多ターン会話では初期のインテントが失われることも。ハルシネーション(事実誤認)や誤情報も特に医療・金融・法律分野で懸念となります。プライバシー配慮も重要で、パーソナライズ精度向上のための行動データ収集とユーザープライバシーとのバランスが求められます。こうした限界を理解することで、コンテンツ制作者やマーケターはAI検索での可視性に現実的な期待値を持ち、すべてのクエリが完璧に解釈されるわけではないと認識できます。
インテント重視の検索は、より洗練された理解と対話へ急速に進化しています。会話型AIはより自然になり、長く複雑な多ターン対話でもインテントの変化を維持・適応できるようになります。マルチモーダルインテント理解により、テキスト・画像・音声・動画を組み合わせてユーザーの目的を包括的に解釈できるようになります(例:「これに似たものを探して」と写真を見せる検索)。ゼロクエリ検索も注目されており、AIがユーザーの明示的な指示なしに、行動シグナルや文脈からニーズを予測して関連情報を先回りして提示します。パーソナライズの高度化により、ユーザーごとのプロファイルや意思決定段階、文脈状況に応じて結果がますます最適化されていきます。レコメンデーションシステムとの統合も進み、検索と発見の境界が曖昧になり、ユーザーが「知ってすらいなかった」関連コンテンツをAIが提案する未来が現実になります。こうした進化の中で、インテントを深く理解し、多様な文脈・ユーザータイプごとにそれを満たす構造的コンテンツを作れるブランドや制作者こそが、競争優位を得る時代が到来します。
ユーザーインテントとは、入力されたキーワードそのものではなく、クエリの背後にある本質的な目的や意図を指します。LLMは文脈や表現、関連するシグナルを分析することで意味を解釈し、ユーザーが本当に成し遂げたいことを予測します。そのため、同じクエリでも、ユーザーの状況や意思決定段階によって異なる結果になることがあります。
LLMは「クエリファンアウト」と呼ばれるプロセスにより、1つのクエリを数十の関連するマイクロクエスチョンに分解します。たとえば「Notion vs Trello」というクエリは、チーム協働、価格、連携機能、使いやすさなどのサブクエリに拡張されます。これによりAIは多角的に意図を探り、包括的な情報を収集できます。
インテントを理解することで、AIシステムが実際にどのようにコンテンツを解釈・引用するかに最適化できます。複数のサブインテントに対応したモジュール型のコンテンツはLLMに選ばれやすくなります。これはChatGPT、Perplexity、Google AIなどのAI生成回答での可視性に直接影響します。
セマンティックエンベディングは単語やフレーズを意味を反映した数値ベクトルに変換します。これによりLLMは、「affordable」「budget-friendly」「inexpensive」など異なる表現でも同じインテントを認識できます。このセマンティックな手法は、従来のキーワードマッチよりも同義語や言い換え、文脈への対応が格段に優れています。
はい。LLMは曖昧なクエリや複数の意図が混在する場合、または文脈情報が制限されている場合に課題があります。「Java」のようなクエリはプログラミング言語・地名・コーヒーを指す可能性があります。長い会話では文脈ウィンドウを超え、初期のインテントが忘れられることも。こうした限界を理解することで、AI検索での可視性への現実的な期待値設定が可能です。
ブランドは、複数のサブインテントに明確に対応したモジュール型コンテンツを作成しましょう。事実や具体的な数値、明確な構成で引用されやすいフォーマットにすることが重要です。AmICitedのようなツールでAIシステムによるコンテンツ参照状況を監視し、インテント整合性のギャップを特定・最適化しましょう。
インテントは「今まさに達成したいタスク目的」です。一方インタレストはより広い一般的な関心です。AIシステムはインテントを優先し、どのコンテンツを回答に選ぶかを決定します。たとえばユーザーが生産性ツールに興味があっても、インテントは「リモートチームコラボ向けのツールを探したい」など具体的なものになります。
AIシステムは検出したインテントに最も合致する情報源を引用します。特定のサブインテントを明確に、事実に基づき、構造化しているコンテンツほど選ばれやすくなります。AmICitedのようなツールはこうした引用パターンを追跡し、どのインテント整合性がAI生成回答での可視性につながるかを明らかにします。
ChatGPT、Perplexity、Google AIでLLMがあなたのコンテンツをどのように参照しているかを把握しましょう。インテントの整合性を追跡し、AmICitedでAIでの可視性を最適化できます。
AIシステムにとってインフォメーショナル検索意図とは何か、AIがこれらのクエリをどのように認識するのか、そしてこの意図を理解することがAI搭載検索エンジンやチャットボットでのコンテンツの可視性にとってなぜ重要なのかを学びましょう。...

LLMメタアンサーとは何か、ChatGPT、Perplexity、Google AI OverviewsなどのAI生成回答で可視性を高めるためのコンテンツ最適化方法を解説します。LLMOのベストプラクティスを紹介。...
AI検索インテントカテゴリと、ChatGPT・Perplexity・Google AIなどの生成エンジンがユーザーゴールをどのように解釈するかを探ります。4つのコアタイプと高度なインテント認識について学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.