

サンセット・プラットフォームとAI可視性:移行管理の戦略
AIプラットフォームのサンセット時に、どのように移行管理し、引用の可視性を維持するかを学びましょう。ChatGPT、Perplexity、Google AIなどの廃止プラットフォームの管理と引用追跡のための戦略ガイド。...
1 分で読める
2026年のOpenAI GPT-4o APIの廃止は、AIプラットフォーム上に構築されたビジネスにとって分岐点となる出来事です――もはや理論上の心配事ではなく、戦略的な対応が即座に求められる現実となりました。従来のソフトウェア廃止のように長期のサポート期間が設けられるケースとは異なり、AIプラットフォームの変更は比較的短期間で発生し、組織は自社の技術スタックに関する迅速な意思決定を迫られます。プラットフォーム側がモデルを廃止する理由は様々です。安全性への懸念(旧システムが最新基準を満たさない)、責任回避(誤用や有害な出力へのリスク)、新たなビジネスモデルによる新サービス優先、そして最先端研究へのリソース集中などが挙げられます。特定モデルを業務に深く組み込んでいる場合(顧客向けアプリ、社内分析、意思決定システムなど)、API廃止の発表はすぐに移行・テスト・代替策の検証というプレッシャーを生み出します。経済的影響は単なるエンジニアリングコストにとどまらず、移行期間中の生産性低下、サービス障害、代替モデルが元の性能に及ばなかった場合のパフォーマンス低下リスクなども含まれます。準備を怠った組織は、慌ててサポート期間延長を交渉したり、明確な移行戦略がないまま妥協的な代替手段を受け入れてしまいがちです。重要なポイントは、プラットフォーム廃止がもはや稀な例外ではなく、AIの現場では予測可能な常態であり、積極的な計画が求められるということです。
従来の事業継続フレームワーク(例:ISO 22301)は、インフラ障害を想定して設計されています――システムがダウンし、バックアップやフェイルオーバーから復旧する、という流れです。これらは**RTO(復旧時間目標)やRPO(復旧時点目標)といった指標で、サービス復旧の速さや許容可能なデータ損失量を測ります。しかし、AIの障害は本質的に異なります。この違いが極めて重要です。AIシステムは稼働を続け、出力を生み、ユーザーにもサービスを提供し続けながら、密かに誤った判断をしはじめます。例えば不正検知モデルが不正取引を見逃したり、価格決定AIが商品を過小評価したり、ローン審査AIが特定属性を不当に排除するバイアスを持つようになっても、「正常稼働」に見えてしまいます。従来型BCPは、精度低下やバイアス発生を監視する仕組みがなく、システム停止やデータ損失のみを想定しています。これからはRAO(復旧精度目標)やRFO(復旧公平性目標)**といった新たな指標が必要です。たとえば金融機関がクレジット審査AIを使っていて、モデルがドリフトして特定属性の申請を一律否決しはじめても、従来BCP上は問題なし――ですが、実際には規制違反や評判失墜、法的リスクが発生します。
| 項目 | 従来インフラ障害 | AIモデル障害 |
|---|---|---|
| 検知 | 即時(システムダウン) | 遅延(表面上は正常出力) |
| 影響の見え方 | 明確・測定可能 | 精度指標に隠れる |
| 復旧指標 | RTO/RPO | RAO/RFOが必要 |
| 主因 | ハード/ネットワーク障害 | ドリフト・バイアス・データ変化 |
| ユーザー体験 | サービス利用不可 | サービス利用可だが誤った出力 |
| コンプライアンスリスク | データ損失・ダウンタイム | 差別・法的責任 |
プラットフォーム廃止サイクルは一定のパターンに従うことが多いですが、その期間はプラットフォームの成熟度やユーザー数によって大きく異なります。多くは12~24か月前に廃止予告がなされ、開発者に移行期間が設けられます――ただし、AI分野では進化が速いため、この期間が短いことも珍しくありません。発表があると、すぐに影響評価・代替案検討・移行計画・予算確保・リソース調整――すべて現業を維持しながら進めるプレッシャーが生じます。バージョン管理の複雑化も顕著です。移行期間中は複数モデルを並行運用するため、テスト・監視も二重になり、運用負荷が倍増します。単なるAPIコールの切り替えだけでなく、新しいモデル出力への再学習、特定ユースケースでの性能検証、旧モデル向けに最適化したパラメータの再調整なども必要です。さらに、規制対応のための審査や、契約でモデルバージョンが指定されている場合、レガシーAPIに深く依存したシステムの大規模リファクタが必要になる等、追加制約も発生します。こうしたサイクルを理解することで、緊急対応から計画的な移行へと転換でき、プロダクトロードマップの中に移行計画を組み込めます。
プラットフォーム移行に伴う直接コストはしばしば過小評価されがちで、APIコールや新モデル統合のエンジニアリング工数だけでは済みません。開発工数には、単なるコード修正だけでなく、アーキテクチャ全体の見直しも含まれます――旧モデル特有のレイテンシやスループット、出力形式に最適化されたシステムの場合、新プラットフォームへの大規模リファクタが必要になることも。テスト・検証コストも大きな隠れコストです。特に重要な業務では、モデルを「入れ替えるだけ」で済ませることはできません。あらゆるユースケース・エッジケース・統合ポイントで、新モデルが十分な結果を出すか検証が必要です。モデル間の性能差も無視できません――新モデルは速いが精度が低い、安価だが出力特性が異なる、より高機能だが入力形式が違う、など。規制・監査面での追加負担も発生します。金融・医療・保険などの業界では、移行プロセスの文書化、新モデルの規制要件適合性確認、場合によっては認可取得も必要です。移行作業に割かれるエンジニア資源の機会損失も大きく、開発者は新機能開発や既存システム改善、技術的負債解消などに時間を使えなくなります。新モデルでハイパーパラメータや前処理、監視手法が変わることも多いため、移行期間とコストが延びる要因です。
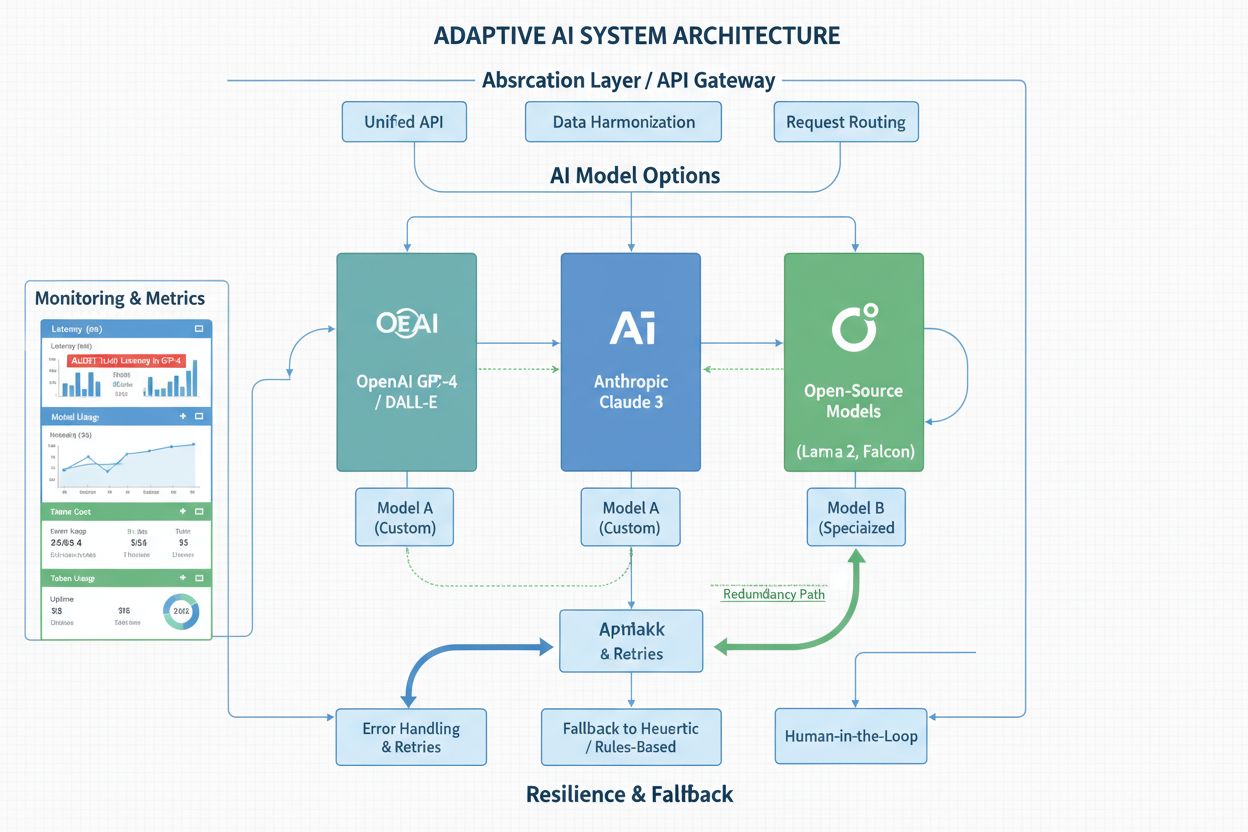
最も柔軟な組織は、プラットフォーム非依存性をAIシステム設計の中核原則としています。今日の最先端モデルも、いずれは廃止されることを前提にしているのです。抽象化レイヤーやAPIラッパーが不可欠です。APIコールをコード全体に散在させるのではなく、統一インターフェースでモデルプロバイダの違いを隠蔽します。これにより、プラットフォーム移行時はラッパー部分だけ修正すれば済み、全システムの統合ポイントを一つ一つ修正する必要がありません。マルチモデル戦略も有効です。重要な意思決定で複数モデルを並列運用し、アンサンブル手法で予測を組み合わせたり、セカンダリモデルをバックアップにしたりします。コスト・複雑性は増しますが、プラットフォーム変更への保険となります――どれか一つが廃止されても、既に他モデルが本番稼働している状態です。フォールバック機構も重要です。主要モデルが使えなくなったり、異常出力を出した場合、完全停止ではなくセカンダリへ自動切り替えできる設計にしましょう。監視・アラート体制が堅牢なら、パフォーマンス低下や精度ドリフト、挙動の変化をユーザー影響前に検知できます。ドキュメントとバージョン管理も必須。どのモデルをいつ導入し、どんな特性があるかを明確に記録しておくことで、短期間での移行判断にも迅速に対応できます。こうした設計パターンに投資した組織は、プラットフォーム変更を危機ではなく「管理可能なイベント」として扱えるようになります。
プラットフォーム発表や廃止通知を確実にキャッチするには、偶然メールで気づくのを期待するのではなく、体系的な監視が必須です。主要なAIプラットフォームの多くは公式ブログやドキュメント、開発者ポータルで廃止スケジュールを公開していますが、頻繁な製品アップデートや新機能リリースの中で埋もれがちです。特定プラットフォーム向けの自動アラート(RSSフィード、メール購読、専用監視サービスなど)を設定すれば、発表直後に確実に通知を受け取れます。公式発表以外でも、本番システムでAIモデルの性能変化に注目することが重要です。プラットフォーム側で微妙なモデル変更がなされ、公式発表より先に精度低下や挙動変化に気づく場合もあります。AmICitedのようなツールは、AIプラットフォームがあなたのブランドやコンテンツをどのように参照しているかを追跡し、影響を及ぼす可能性のあるプラットフォーム変更やアップデートのインサイトを提供します。競合情報も参考になります。競合他社が特定モデルから移行を始めているなら、そのモデルの廃止が近いシグナルです。プラットフォーム専用ニュースレター購読、開発者コミュニティ参加、アカウントマネージャーとの連携なども早期警戒に有効です。監視インフラへの投資は、廃止発表を早期にキャッチし、数か月の計画猶予を得られるという形で大きなリターンを生みます。
よく構成されたプラットフォーム変更対応計画は、緊急時のカオスを整理されたプロセスへ変えます。影響評価フェーズは、廃止発表を受けた直後に始まり、影響を受ける全システムの洗い出し、移行に必要な工数見積り、規制や契約上の制約確認などを行います。この段階で、対象システムの詳細リスト、重要度、依存関係を整理し、以降の意思決定基盤とします。計画フェーズでは、移行ロードマップを策定し、リソース配分やスケジュール設定、どのシステムから順に移行するかを決めます(多くの場合、まず非クリティカルなシステムから着手し、経験を積んでからミッションクリティカルへ進みます)。テストフェーズが実質的な作業の大半を占め、新モデルが自社ユースケースで十分な性能を発揮するか検証し、性能ギャップや挙動の差異を特定、必要に応じて対策や最適化を講じます。ロールアウトフェーズでは、段階的な移行を実行し、まず一部トラフィックでカナリアリリース、問題なければ順次割合を増やします。移行後監視も重要で、数週間~数か月にわたりパフォーマンス指標、ユーザーの声、システム挙動を追跡し、移行が成功したか、新モデルが期待通りかを確認します。こうした構造的アプローチをとる組織は、想定外のトラブルやユーザー影響を最小化したスムーズな移行を実現しています。
リプレース先のプラットフォームやモデルの選定には、自社の要件や制約に沿った明確な評価基準が必要です。性能特性(精度・レイテンシ・スループット・コスト)は当然ですが、ベンダーの安定性(5年後も継続しているか)、サポート品質、ドキュメントの充実度、コミュニティ規模など見落とされがちな要素も重要です。オープンソース vs. プロプライエタリの選択も慎重に。オープンソースはベンダー依存から解放され、自社インフラでの運用も可能ですが、導入・保守により多くのエンジニアリングが必要です。プロプライエタリは手軽さやアップデート、サポートが魅力な一方、ベンダーロックインのリスク(プラットフォームの存続や価格に依存)がつきまといます。費用対効果分析は、APIコール単価だけでなく、統合や品質低下による追加コストも含めた総コストで比較しましょう。長期的な持続性も重要です。資金力や安定性のあるプラットフォームを選べば廃止リスクは下がりますが、スタートアップや研究プロジェクト由来のモデルは将来の廃止リスクが高まります。リスク分散のため複数プラットフォーム採用をあえて選ぶ組織もあり、複雑性増加と安定性向上をトレードオフします。評価プロセスは文書化し、状況に応じて定期的に見直しましょう。
進化が激しいAI業界で成果を上げる組織は、継続的な学習と適応を運用原則とし、プラットフォーム変更を単なる突発的な出来事ではなく日常的な課題として受け入れています。プラットフォームプロバイダーとの関係構築(アカウント管理、ユーザーアドバイザリーボード参加、プロダクトチームとの定期連絡など)は、将来の変更情報の早期入手や、時には廃止スケジュールに影響を与える機会にも繋がります。新モデルやプラットフォームのベータプログラムに参加すれば、広く公開される前に代替案を評価し、現行プラットフォームが廃止された場合も移行計画を先行できます。業界動向・将来予測にもアンテナを張り、どのモデルやプラットフォームが主流になりそうか、廃れていきそうかを見極めることで、投資すべきプラットフォームの選定が可能です。AIモデルの評価・デプロイ・監視の社内専門性を高めることも必須で、プラットフォーム変更時の重要判断を外部コンサルやベンダーに依存しなくなります。これには、モデル性能の評価方法、ドリフト・バイアスの検知手法、モデル変更に柔軟に対応できる設計、そして不確実性下での健全な技術判断力が含まれます。こうした能力に投資した組織は、プラットフォーム変更を「管理可能な課題」として捉えられ、新しいAI技術やプラットフォームの進化を競争力へと転換できます。
ほとんどのAIプラットフォームは、モデルを廃止する前に12~24か月の通知期間を設けていますが、この期間はプラットフォームによって異なります。重要なのは、締め切り間際まで待たず、発表があった時点ですぐに計画を立て始めることです。早期の計画立案により、代替案を十分にテストする時間が確保でき、性急な移行によるバグやパフォーマンス低下のリスクを避けられます。
プラットフォームの廃止は、通常、モデルやAPIバージョンが今後アップデートされず、最終的には削除されることを意味します。APIのリタイアメントは、最終段階として完全にアクセスが遮断されることです。この違いを理解することで、移行スケジュールの計画に役立ちます。実際のリタイアメントまでに数か月の廃止通知期間が設けられる場合もあります。
はい、多くの組織が重要な用途で複数のプラットフォームを併用しています。複数のモデルを並行稼働させたり、バックアップとしてセカンダリモデルを保持することで、プラットフォームの変更リスクに備えることができます。ただし、この方法は複雑さとコストが増すため、信頼性が最も重要なミッションクリティカルなシステムに限定されることが一般的です。
まず、組織で利用しているすべてのAIモデルとプラットフォーム、そして各システムがどれに依存しているかを文書化しましょう。公式なプラットフォームの発表を監視し、非推奨通知を購読し、監視ツールでプラットフォームの変更を追跡します。AIインフラの定期的な監査も、影響を把握するのに役立ちます。
プラットフォーム変更に適応しないと、アクセス遮断によるサービス中断、代替手段の品質低下によるパフォーマンス劣化、システムが非準拠となることによる規制違反、サービス停止による評判低下などのリスクがあります。積極的な適応により、これら高コストな事態を回避できます。
プラットフォーム固有のコードを分離する抽象化レイヤーを設計し、複数のプラットフォームプロバイダーと関係を築き、オープンソースの選択肢も評価し、アーキテクチャを文書化して容易な移行を可能にしましょう。これらの実践によって特定ベンダーへの依存を減らし、プラットフォーム変更時の柔軟性を高められます。
AmICitedのようなツールは、AIプラットフォームがあなたのブランドをどのように参照しているかや、プラットフォームのアップデートを監視できます。また、公式ニュースレターの購読や、非推奨発表用RSSフィードの設定、開発者コミュニティへの参加、アカウントマネージャーとの連携も、変更の早期察知に有効です。
AIプラットフォーム戦略は最低でも四半期ごと、もしくは重要なプラットフォーム変更を知った時に見直しましょう。業界の変化が早い場合や複数プラットフォームに依存している場合は、毎月の見直しも適しています。定期的なレビューで新たなリスクを把握し、移行計画を前もって立てられます。
AIプラットフォームのサンセット時に、どのように移行管理し、引用の可視性を維持するかを学びましょう。ChatGPT、Perplexity、Google AIなどの廃止プラットフォームの管理と引用追跡のための戦略ガイド。...

AIプラットフォームのアルゴリズム変更に迅速に適応するアジャイル最適化戦略をマスターしましょう。ChatGPT、Perplexity、Google AIのアップデートを監視し、ブランドの可視性を維持する方法を学びます。...

AI検索危機管理についてのコミュニティディスカッション。AIシステムがあなたのブランドについて誤った情報を広めた場合の対処方法。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.