

Wikipedia記事で引用されるには:非操作的アプローチ
ブランドがWikipediaで引用されるための倫理的な戦略を学びましょう。Wikipediaのコンテンツ方針、信頼できる情報源、AI可視性や検索エンジンでの存在感を高めるための引用活用法を理解します。...
1 分で読める
Wikipediaは、OpenAIのChatGPTやGoogleのGemini、AnthropicのClaude、Perplexityの検索エンジンなど、今日存在するほぼすべての主要な大規模言語モデル(LLM)の基礎的なトレーニングデータセットとなっています。多くの場合、WikipediaはこれらAIシステムのトレーニングデータセット内で最も大きな構造化・高品質なテキストソースを占めており、モデルによっては全体の5~15%を占めます。この優位性は、Wikipedia独自の特性――中立的な観点の方針、厳格なコミュニティ主導のファクトチェック、構造化されたフォーマット、自由に利用できるライセンス――によるものです。これらはAIに「推論」「情報源の引用」「正確な伝達」を教えるのに並ぶもののないリソースといえます。しかしこの関係性は、Wikipediaのデジタルエコシステム内での役割を根本的に変化させました。もはや単なる情報を求める人間のための目的地ではなく、**何百万人もの人々が日々対話する会話型AIを支える“見えざる背骨”**となったのです。このつながりを理解することは、重大な波及効果を明らかにします。すなわちWikipediaの質や偏り、情報の抜けが、今や何十億もの人々が情報にアクセスし理解する方法を媒介するAIシステムの能力と限界を直接的に形作っているのです。

大規模言語モデルがトレーニング時に情報を処理する際、すべての情報源を等しく扱うわけではありません。Wikipediaはその意思決定階層において特別な位置を占めています。エンティティ認識の過程で、LLMは主要な事実や概念を識別した後、それらを複数の情報源と照合し信頼性スコアを算出します。Wikipediaは「一次的な権威のチェック」として機能します。なぜなら、編集履歴が透明で、コミュニティによる検証メカニズムがあり、中立的な観点の方針を持つためAIに信頼性を示すからです。この信頼性の乗数効果により、WikipediaやGoogle Knowledge Graph、Wikidata、学術情報源などで一貫して情報が現れる場合、LLMはその情報に指数関数的に高い確信度を与えます。この重み付けの仕組みが、Wikipediaが特別扱いを受ける理由です。Wikipediaは直接的な知識源であるだけでなく、他の情報源から抽出した事実の検証層でもあるのです。その結果、LLMはWikipediaを単なる多くのデータポイントの一つとしてではなく、他の精査されていない情報を“確認”または“疑問視”する基礎的なリファレンスとして扱うことを学習しています。
| 情報源の種類 | 信頼性の重み | 理由 | AIでの扱い |
|---|---|---|---|
| Wikipedia | 非常に高い | 中立、コミュニティ編集、検証済み | 主要な参照 |
| 企業サイト | 中程度 | 自己宣伝的 | 二次情報源 |
| ニュース記事 | 高い | 第三者だが偏りの可能性 | 裏付け情報 |
| ナレッジグラフ | 非常に高い | 構造化・集約済み | 権威の乗数 |
| ソーシャルメディア | 低い | 未検証・宣伝的 | 重みは最小 |
| 学術情報源 | 非常に高い | 査読済み・権威性 | 高信頼度 |
ニュース機関がWikipediaを情報源として引用すると、「引用の連鎖」と呼ばれる現象が生じます。これは複数の情報インフラ層をまたいで信頼性が積み上がる仕組みです。たとえば気候科学について執筆するジャーナリストが、地球温暖化に関するWikipedia記事を参照し、その記事自体が査読論文を引用している場合、そのニュース記事は検索エンジンにインデックスされ、ナレッジグラフに組み込まれ、最終的には何百万人ものユーザーが日々利用する大規模言語モデルの学習に取り込まれます。これにより強力なフィードバックループが形成されます:Wikipedia → ナレッジグラフ → LLM → ユーザー。このときWikipediaの記述や強調点が、最終的にAIシステムがエンドユーザーに情報をどのように提示するかを微妙に左右するのです。たとえば、Wikipediaのある医薬品に関する記事が特定の臨床試験を強調し、他を抑える編集がなされていれば、その編集方針がニュース記事、ナレッジグラフ、そして最終的にChatGPTなどのAIモデルが患者の質問にどう答えるかに波及します。この「波及効果」とは、Wikipediaの編集判断が、サイトを直接訪れる読者だけでなく、AIシステムが学習し何十億ものユーザーへ反映する情報環境そのものを根本的に形作るということです。引用の連鎖は、Wikipediaを単なる参照先から、AIトレーニングパイプラインの“見えざるが影響力の大きい層”へと変貌させ、情報源での正確性やバイアスがエコシステム全体に増幅されて伝播するのです。
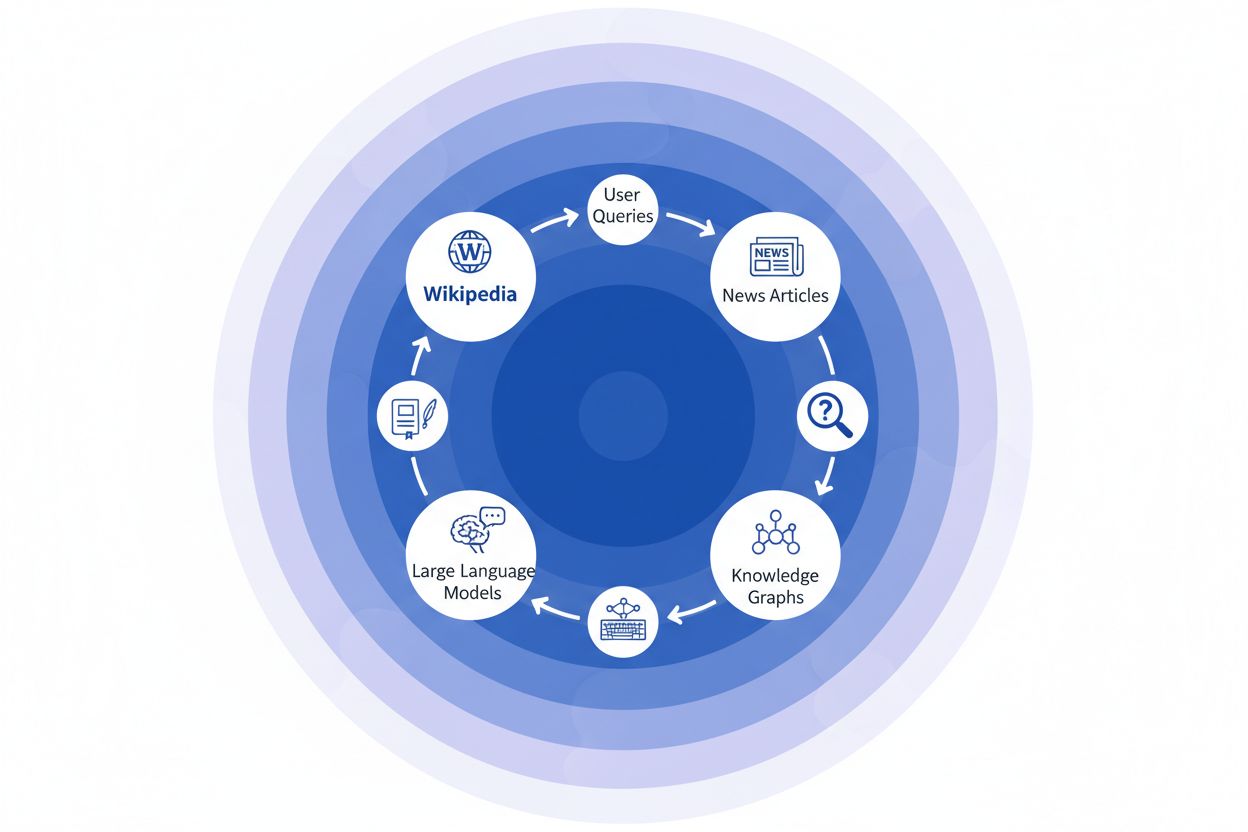
WikipediaからAIエコシステムへの波及効果は、ブランドや組織にとって最も重要なダイナミクスの一つです。Wikipediaでの1つの編集は単に1つの情報源を変えるだけではありません。それは相互に結びついたAIシステムのネットワーク全体を介して連鎖的に広がり、情報が何倍にも増幅されて影響します。Wikipediaページに不正確な記述が現れると、それは孤立したままにはなりません。むしろAI全体に伝播し、ブランドがどのように説明され、理解され、毎日何百万人ものユーザーに提示されるかを形作ります。この乗数効果により、Wikipediaの正確性への投資は単一プラットフォームのためだけでなく、生成AIエコシステム全体でブランドストーリーをコントロールするためのものとなります。デジタルPRやブランド管理の専門家にとって、これはリソースと注力の優先順位を根本的に変える現実です。
注視すべき主な波及効果:
VetterらによるIUP研究の最新成果は、AIインフラの重大な脆弱性――Wikipediaのトレーニングリソースとしての持続可能性――を明らかにしました。大規模言語モデルが爆発的に普及し、LLM生成コンテンツの膨大なデータセットで学習される中、「モデル崩壊」と呼ばれる問題が深刻化しています。これは人工的な出力がトレーニングデータプールを汚染し、世代を追うごとにモデル品質が低下する現象です。特にWikipediaは、人間の専門性とボランティア労働によるクラウドソース百科事典でありながら、先進AIシステムの学習の柱となっているにもかかわらず、その貢献者には明示的なクレジットや報酬が与えられていません。この倫理的な問題は非常に深刻です。AI企業がWikipediaの自由な知識から価値を引き出す一方で、合成コンテンツで情報生態系を埋め尽くしていくと、20年以上にわたりWikipediaのボランティアコミュニティを支えてきたインセンティブ構造がかつてないほど脅かされます。人間による生成コンテンツを明確かつ保護されたリソースとして守るための意図的な介入がなければ、AI生成テキストが徐々に本物の人間の知識を置き換え、ついには現代の言語モデルの基盤そのものを損ねてしまうリスクがあります。Wikipediaの持続可能性は、百科事典自体だけの問題ではなく、情報エコシステム全体、そして本物の人間知識に依存するAIシステムの将来に関わる重大課題なのです。
AIシステムがWikipediaを基礎的な知識源としてますます活用する中、AI生成回答において自社ブランドがどのように現れるかを監視することは現代組織にとって不可欠となっています。AmICited.comは、Wikipediaの引用がAIシステムに波及する様子を追跡し、Wikipediaでの存在感がAIでの言及や推奨にどう変換されているかを可視化します。FlowHunt.ioのような他のツールがウェブ全体の監視を提供する一方、AmICitedはWikipediaからAIへの引用パイプラインに特化し、AIシステムがWikipediaエントリーを参照する瞬間と、それが回答にどのように影響するかを捉えます。この関係性を理解することはとても重要です。なぜならWikipediaの引用はAIの学習データと回答生成において大きな重みを持つからです。適切に管理されたWikipediaの存在感は、人間読者だけでなく、AIがブランドをどう認識・提示するかにも直接影響します。AmICitedでWikipediaへの言及を継続的に監視することで、AI上の影響力を把握し、Wikipedia掲載状況を下流でのAI発見やブランドイメージに及ぼす影響まで見越して最適化できるのです。
はい。ChatGPT、Gemini、Claude、Perplexityなど、主要な大規模言語モデル(LLM)はすべて、学習データにWikipediaを含めています。Wikipediaは多くの場合、LLMのトレーニングデータセット内で最大かつ構造化された検証済み情報源であり、全体の5~15%を占めることが一般的です。
WikipediaはAIシステムにとって信頼性のチェックポイントとして機能します。LLMがブランド情報を生成する際、Wikipediaの記述が他の情報源よりも重視されるため、WikipediaページがChatGPTやGemini、Claudeなど複数のAIプラットフォーム上でのブランド表現に決定的な影響を及ぼします。
波及効果とは、単一のWikipediaの引用や編集が、AIエコシステム全体で下流に連鎖的な影響を生み出す現象を指します。Wikipediaでの一つの変更がナレッジグラフに影響し、それがAIの概要に波及し、結果として複数のAIシステムがブランドについてどのように説明するかを何百万人ものユーザーに対して左右するのです。
はい。LLMはWikipediaを非常に信頼できる情報源とみなすため、Wikipediaページの誤情報はAIシステム全体に広がります。これによりChatGPTやGeminiなどのAIプラットフォームでの組織の説明に影響し、ブランドイメージを損なう可能性があります。
AmICited.comのようなツールは、ChatGPT、Perplexity、Google AI OverviewsなどのAIシステム上でブランドがどのように引用・言及されているかを追跡します。これによりWikipediaの存在感がAIにどのような波及効果をもたらしているかを把握し、最適化に活用できます。
Wikipediaは自己宣伝に厳格な規定を設けています。編集はWikipediaのガイドラインに従い、信頼できる第三者ソースに基づく必要があります。多くの企業は、適切な掲載を維持しつつルールを遵守するためにWikipedia専門家と協力しています。
LLMはデータスナップショットで学習されるため、変更が反映されるまで時間がかかります。ただし、ナレッジグラフはより頻繁に更新されるため、AIシステムや再学習のタイミングによっては数週間~数ヶ月で波及効果が始まることもあります。
WikipediaはLLMの学習に直接使われる一次情報源です。GoogleのKnowledge Graphのようなナレッジグラフは、Wikipediaを含む複数の情報源を集約してAIに供給し、AIが情報を理解・提示する際に追加の影響層を形成します。
ブランドがWikipediaで引用されるための倫理的な戦略を学びましょう。Wikipediaのコンテンツ方針、信頼できる情報源、AI可視性や検索エンジンでの存在感を高めるための引用活用法を理解します。...

WikipediaがAIトレーニングデータセットとして果たす重要な役割、そのモデル精度への影響、ライセンス契約、そしてAI企業がなぜ大規模言語モデルのトレーニングに依存しているのかをご紹介します。...
WikipediaがChatGPT、Perplexity、Google AIにおけるAIの引用へどのように影響を与えているかを解説。WikipediaがAI学習で最も信頼されるソースとなっている理由、ブランドの可視性への影響を学びましょう。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.