
著者スキーマを追加するとAIによる引用に本当に効果があるのか?今テスト中
著者スキーマがAIによる引用に役立つかどうかに関するコミュニティディスカッション。ChatGPT、Perplexity、AI Overviewsで著者マークアップの効果をテストしたSEOの専門家による実体験。...
2 分で読める
Discussion
Structured Data
+1

著者スキーママークアップがChatGPT、Perplexity、Google AI OverviewsでのAI引用をどのように向上させるかを学びましょう。AI生成回答でブランドの可視性を高める実装戦略もご紹介。
はい、著者スキーマは、コンテンツの著者性や専門性を明確に示す構造化データを提供することで、AIによる引用に役立ちます。AIシステムはこのマークアップを利用して著者の資格情報を検証し、エンティティ認識やコンテンツの権威性を判断するため、AI生成の回答や要約において引用されやすくなります。
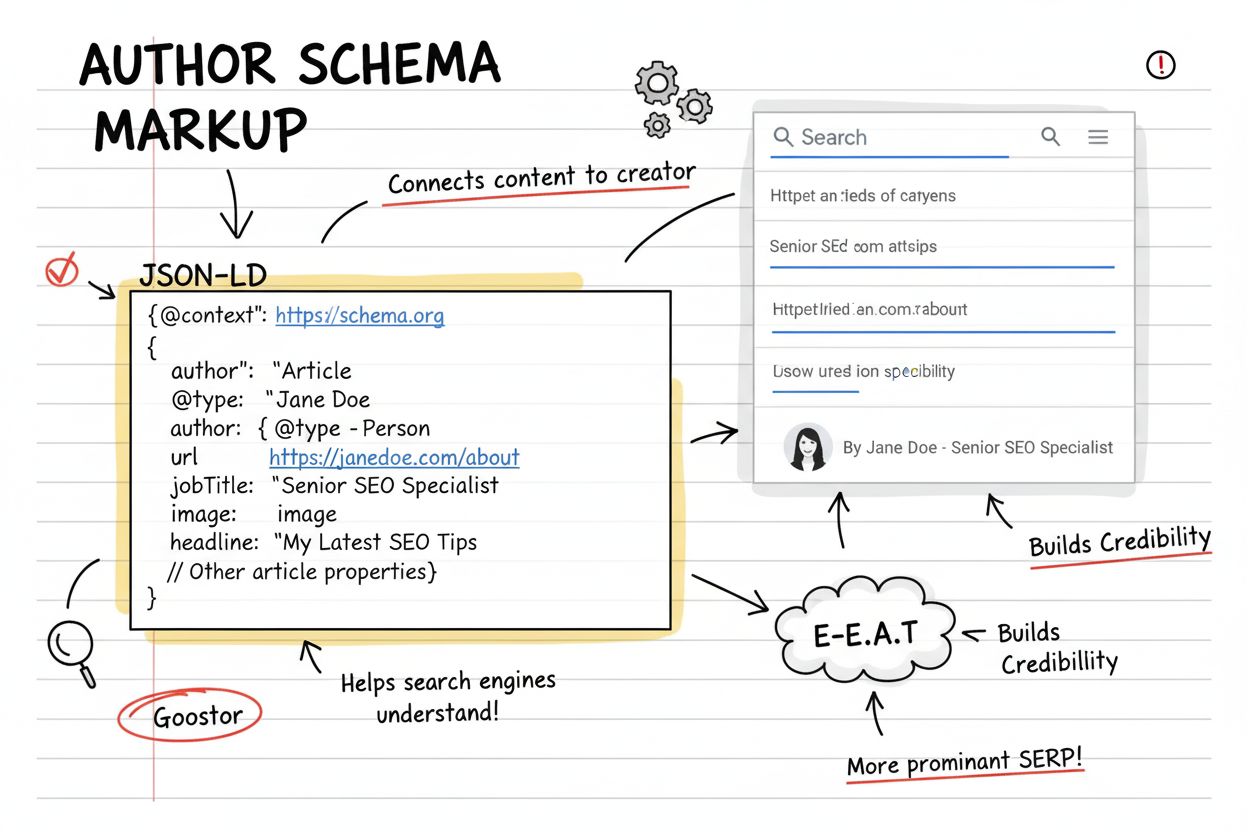
著者スキーマは、誰がコンテンツを作成したかを検索エンジンやAIシステムに明示的に伝える構造化データマークアップです。従来のSEOでは著者情報が可視テキスト内に埋もれがちですが、著者スキーマはJSON-LD形式を用いてコンテンツ作成者に関する機械可読なデータを提供します。このマークアップには、著者名、職業用URL、資格情報、所属などの重要な情報が含まれます。適切に実装すれば、著者スキーマはあなたのウェブサイトを機械可読なナレッジグラフへと変換し、AIシステムが容易に解析・理解できるようにします。ChatGPT、Perplexity、Claude、GoogleのAI OverviewsといったAI検索エンジンが主流となる中で、このマークアップの重要性は飛躍的に高まっています。
著者スキーマとAI引用の関係は、根本的にはエンティティ認識と信頼性の検証に関わります。AIシステムは日々膨大なウェブページを処理しており、信頼できる情報源と信頼性の低いコンテンツを効率的に区別する手段を必要としています。著者スキーマは、AIアルゴリズムが誰がそのコンテンツを書いたのかを素早く特定し、専門性を検証し、信頼できる情報源として引用すべきかを判断するためのセマンティックなレイヤーを提供します。構造化データがなければ、AIシステムは可視テキストのスクレイピングやサードパーティリストの調査、キャッシュ版ページの解析など、推測に頼る必要があり、この非効率なプロセスは引用漏れや誤った帰属を招きがちです。
AI搭載の検索エンジンは、エンティティ認識と呼ばれる高度なプロセスを用いて情報を理解・分類しています。このプロセスには、トークン化・パターン認識・コンテキスト解析が含まれ、例えばアップル(企業)とアップル(果物)を区別することができます。著者スキーマはこのプロセスを劇的に改善し、曖昧さを排除する明示的な構造化情報を提供します。AIシステムが適切な著者スキーマ付きのコンテンツに出会うと、著者が実在し検証可能な資格を持つ人物であることを即座に確認でき、非構造化テキストから推測するための計算資源を消費せずに済みます。
AIシステムの引用プロセスは通常、次のようなワークフローで進行します。まずAIシステムがコンテンツをクロール・インデックス化します。次に構造化データを解析し、コンテンツの目的・著者性・権威を理解します。そしてユーザーが質問した際、インデックス内から関連する回答を検索し、最後に関連性・権威性・内容の質に基づき引用元を選定します。著者スキーマはこのプロセスの複数段階に影響します。明確な著者マークアップのあるページは正しくインデックスされやすく、権威あるものとして理解され、引用元に選ばれる可能性が高まります。スキーママークアップのあるページは、構造化データのないページと比べてAI生成サマリー・引用に36%多く登場するという調査結果もあります。
| AIプラットフォーム | 著者スキーマの効果 | 引用される可能性 |
|---|---|---|
| Google AI Overviews | ナレッジグラフに情報を供給、著者性をエンティティ認識で明確化 | 著者が検証済みエンティティなら高い |
| ChatGPT Search / SearchGPT | Bingインデックスを利用、著者スキーマで権威シグナルを強化 | 適切なPerson/Organizationマークアップで向上 |
| Perplexity AI | 専門家コンテンツの迅速な特定、回答抽出精度が向上 | 構造化著者データが優れた順位付けに寄与 |
| Claude Web Search | 直接引用を提供、著者スキーマで情報源の信頼性明確化 | 検証済み著者を引用しやすい |
| Bing AI | ナレッジグラフと連携、著者データを信頼度スコアに利用 | 完全な著者マークアップで可視性向上 |
著者スキーマを正しく実装するには、Schema.orgのPersonおよびOrganizationスキーマタイプの理解が必要です。Personスキーマは個人のコンテンツ制作者向けで、名前・職種・所属・学歴・プロフェッショナルプロフィールURLなどのプロパティを含みます。Organizationスキーマは企業著者向けで、企業名・ロゴ・連絡先・SNSプロフィール等のプロパティを持ちます。いずれのスキーマもsameAsプロパティをサポートしており、WikipediaやLinkedIn、専門ディレクトリ等の外部検証ソースへのリンクを可能にします。この外部リンクはクロスリファレンス検証となり、AIシステムの信頼性評価を強化します。
最も効果的な著者スキーマ実装はJSON-LD形式を用いるもので、Googleも明示的に推奨しAIシステムにも好まれます。JSON-LDはページの<head>または<body>内の<script>タグに記述し、HTMLコンテンツとは独立して管理しやすいのが特徴です。以下は著者スキーマ実装の実例です:
{
"@context": "https://schema.org",
"@type": "Person",
"name": "Jane Doe",
"jobTitle": "Senior Content Strategist",
"affiliation": {
"@type": "Organization",
"name": "Your Company Name"
},
"url": "https://www.yoursite.com/author/jane-doe",
"sameAs": [
"https://www.linkedin.com/in/janedoe",
"https://twitter.com/janedoe"
],
"image": "https://www.yoursite.com/images/jane-doe.jpg"
}
記事コンテンツ向けの著者スキーマ実装時は、PersonスキーマをArticleスキーマ内にネストする必要があります。これにより、コンテンツと作成者の関係が明確になります。複数著者の場合は個別のauthorフィールドに分けて記述し、1つのフィールドにまとめてはいけません。例えば2名の共著記事では、2つのauthorオブジェクトを持たせ、名前を1つの文字列にまとめないようにします。この区別はAIシステムが構造化データをプログラム的に解析する上で非常に重要で、まとめて記述するとパースエラーや誤った帰属の原因となります。
著者スキーマがAI引用に有効であることを示す証拠は極めて説得力があります。適切な著者マークアップのあるコンテンツは、未マークアップのコンテンツよりもAIによる引用数が大幅に増加します。この改善は、著者スキーマがAIのコンテンツ選定における根本的課題——専門性と権威の検証——を解決するためです。同じ質問に答える2つのコンテンツがあった場合、片方が分かりやすい著者スキーマで専門家であることを示し、もう片方に著者情報がなければ、AIシステムはほぼ確実に前者を引用します。
この選好の仕組みは、AIシステムがE-E-A-Tシグナル(専門性・経験・権威性・信頼性)をどのように評価するかに関係します。著者スキーマはこれら各要素に対し明示的なシグナルを与えます。著者名や資格は専門性を示し、職歴や所属は経験を示します。sameAs経由の外部プロフィールが権威性を確立し、サイト内外で一貫した著者情報が信頼性を高めます。AIシステムはこれらのシグナルを重視し、コンテンツを引用するかどうかを判断します。
AI各プラットフォームで著者スキーマへの依存度は異なります。GoogleのAI OverviewsはGoogleナレッジグラフ由来の情報を活用し、構造化データに大きく影響されます。適切な著者マークアップのあるページはナレッジグラフにより多くの情報を供給し、引用元に選ばれやすくなります。ChatGPT SearchやSearchGPTはBingのインデックスを利用するため、Bingにインデックスされたスキーマ付きページが引用候補となります。Perplexity AIは構造化の良いコンテンツを明示的に優先し、マークアップされたページからより効率的に回答を抽出します。Claudeのウェブ検索は直接引用を提供し、著者スキーマによって情報源の信頼性を検証した上で回答に引用を含めます。
AI引用でコンテンツの可視性を最大化するには、以下の戦略的実装ポイントを守りましょう。まず、ページに表示されているすべての著者をマークアップに含めること。記事に3名の著者名があっても、スキーマに1名しか記述しなければ、AIは著者情報を見逃したり一貫性のないコンテンツと判定したりします。次に、urlまたはsameAsプロパティで検証可能な著者プロフィールへリンクすること。外部検証がAIにとって非常に価値あるため、信頼できるソースとクロスリファレンス可能な情報を提供しましょう。さらに、サイト全体で一貫性を保つこと。同じ著者が複数の記事を書く場合、すべての記述で同一の著者情報を使いましょう。一貫性はAIに著者をエンティティとして認識させ、より強い権威シグナルとなります。
4つ目に、著者情報を著者プロフィールページだけでなくArticleスキーマにも含めること。PersonスキーマをArticleスキーマ内にネストすることで、コンテンツと作成者の明示的な関係がAIに伝わります。5つ目に、著者情報の変更時には必ずマークアップも更新しましょう。著者の役職や所属が変わった場合は、すみやかにスキーマを修正します。古い情報はAIを混乱させ、引用機会を減らします。6つ目に、GoogleのリッチリザルトテストやSchema.orgバリデータでマークアップを検証しましょう。これらのツールでエラーを特定し、AIが正しく著者情報を解析できるようにします。
7つ目に、他の関連スキーマタイプと著者スキーマを組み合わせること。たとえば、ブログ記事にはArticleスキーマ、Q&AにはFAQスキーマ、ハウツーにはHowToスキーマを使い、AIにコンテンツの目的と著者性を包括的に伝えましょう。8つ目に、AI引用実績をモニタリングする専用ツールで自社コンテンツのAI回答登場頻度を追跡しましょう。どのコンテンツタイプ・著者プロフィールが引用を生みやすいか分析し、戦略を継続的に改善できます。
多くのウェブサイトが著者スキーマを誤って実装し、AI引用の可能性を損ねています。最も多いミスは、複数著者を1つのauthorフィールドにまとめてしまうことです。たとえば "author": {"name": "John Smith, Jane Doe"} のようにせず、個別のauthorオブジェクトを作成する必要があります。AIは特定のフォーマットを期待しており、まとめて記述するとパース失敗の原因となります。次に多いのが、author.nameプロパティに著者名以外の情報を含めてしまうことです。jobTitleや会社名、敬称などは別プロパティ(jobTitle、affiliation、honorificPrefixなど)に記述しましょう。
著者プロフィールを外部検証ソースにリンクしないのも大きなミスです。urlプロパティが企業のホームページなど著者固有でない場合、AIは著者の身元や専門性を検証できません。同様に、著者情報が古くなっても更新しないと信頼性低下の原因となります。旧役職や過去の所属が記載されていれば、AIは不整合と見なし、引用機会が減ります。関係ないスキーマでページを過剰にタグ付けするのも問題です。ブログ記事にProductスキーマ等をつけるのは避け、BlogPostingなど必要最低限のスキーマに留めましょう。
第三者レビューや外部検証を無視するのも見落としがちです。著者が他プラットフォームで執筆したり、業界メディアに取り上げられたり、LinkedInやTwitterでプロフィールを持つ場合、sameAsで外部シグナルも追加しましょう。スキーママークアップを公開前にテストしないのも致命的なミスです。リッチリザルトテストやSchema.orgバリデータで構文エラーをチェックし、AIが正しく解析できるようにしましょう。最後に、著者スキーマだけでAI引用が保証されると誤解するのは危険です。著者スキーマはAI可視性戦略の一要素に過ぎず、高品質なコンテンツやドメイン権威性、他の関連スキーマの適切な実装も不可欠です。
著者スキーマ実装がAI引用を実際に向上させているかを把握するには、測定フレームワークの構築が必要です。まずベースラインを記録しましょう。著者スキーマ導入前に、ChatGPT、Perplexity、Google AI Overviews、Claudeなど各AIで自社コンテンツがどの程度引用されているかを把握します。著者スキーマ実装後は、AIシステムが再クロール・再インデックスする時間として30〜60日間の推移を追跡します。特に競合の多いジャンルでは、引用頻度の明確な改善が期待できます。
引用頻度だけでなく、引用の質や文脈も観察しましょう。すべての引用が等しく価値があるわけではありません。著者名や資格付きの引用は、ドメイン名だけの引用より価値があります。AIが著者名付きでコンテンツに帰属を与えているか、単に情報だけを抜き出しているか追跡しましょう。正しい著者帰属はブランド認知と著者の専門家としての地位を高めます。さらに、著者スキーマ実装後にどのコンテンツタイプが最もAI引用を獲得しているか分析しましょう。ハウツーガイド、専門家インタビュー、調査記事など、特定ジャンルで引用増加が顕著かもしれません。
Search ConsoleなどSEOツールを活用し、従来検索およびAI検索での可視性の変化もモニタリングします。著者スキーマの主な効果はAI引用ですが、特にフィーチャードスニペットやナレッジパネルで従来検索の可視性向上も見込めます。クリック率やインプレッション数、平均掲載順位の変化も追跡しましょう。最後に、定期的に著者スキーマの監査を実施し、常に正確・完全な状態を保ちます。チームの拡大や著者の役割・組織変更時はマークアップの更新が必須です。定期監査で古い・誤った著者情報の蓄積を防ぎ、AI引用戦略を支えましょう。
ChatGPT、Perplexity、Google AI Overviewsなど、AI検索エンジンであなたのコンテンツがどのようにAI回答に表示されているか追跡。ブランドが言及された際のリアルタイム通知や、AIによる引用実績も計測できます。
著者スキーマがAIによる引用に役立つかどうかに関するコミュニティディスカッション。ChatGPT、Perplexity、AI Overviewsで著者マークアップの効果をテストしたSEOの専門家による実体験。...

著者マークアップ付き記事スキーマがAIシステムの信頼シグナルをいかに構築するかを解説します。著者マークアップを実装し、ChatGPT、Perplexity、Google AI Overviewsでの可視性を向上させましょう。...
著者スキーマとは何か、どのように機能するのか、そしてSEO、E-E-A-Tシグナル、AIによるコンテンツ帰属にとってなぜ重要なのかを学びましょう。実装のための完全ガイド。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.