引用選択アルゴリズム
AIシステムがどの情報源を引用し、どれを要約・言い換えるかを選ぶ仕組みを解説。引用選択アルゴリズム、バイアスパターン、AI生成応答におけるコンテンツ可視性向上の戦略を理解しよう。...
1 分で読める

ChatGPT、Perplexity、GeminiなどのAIモデルがどのように引用元を選ぶのか、その引用メカニズムやランキング要因、AIで可視性を高めるための最適化戦略を解説します。
AIモデルは、検索拡張生成(RAG)を通じて引用元を決定し、ドメインオーソリティ、コンテンツの新しさ、意味的関連性、情報構造、ファクト密度などを基準にソースを評価します。意思決定プロセスは数ミリ秒で行われ、ベクトル類似度マッチングや多要素のスコアリングアルゴリズムによって、信頼性、専門性のシグナル、コンテンツ品質が評価されます。
AIモデルは回答で参照元をランダムに選ぶわけではありません。 代わりに、数百ものシグナルをミリ秒単位で評価する高度なアルゴリズムを使用し、どのソースに帰属を与えるべきかを判断します。このプロセスは**検索拡張生成(RAG)**と呼ばれ、従来の検索エンジンのランキングとは根本的に異なります。Googleのアルゴリズムは検索結果での可視性を重視しますが、AIの引用アルゴリズムは、特定のユーザーの質問に最も権威があり信頼できる情報を提供するソースを優先的に選びます。この違いから、AI生成回答で可視性を得るには、従来のSEOとはまったく異なる最適化原則の理解が必要です。
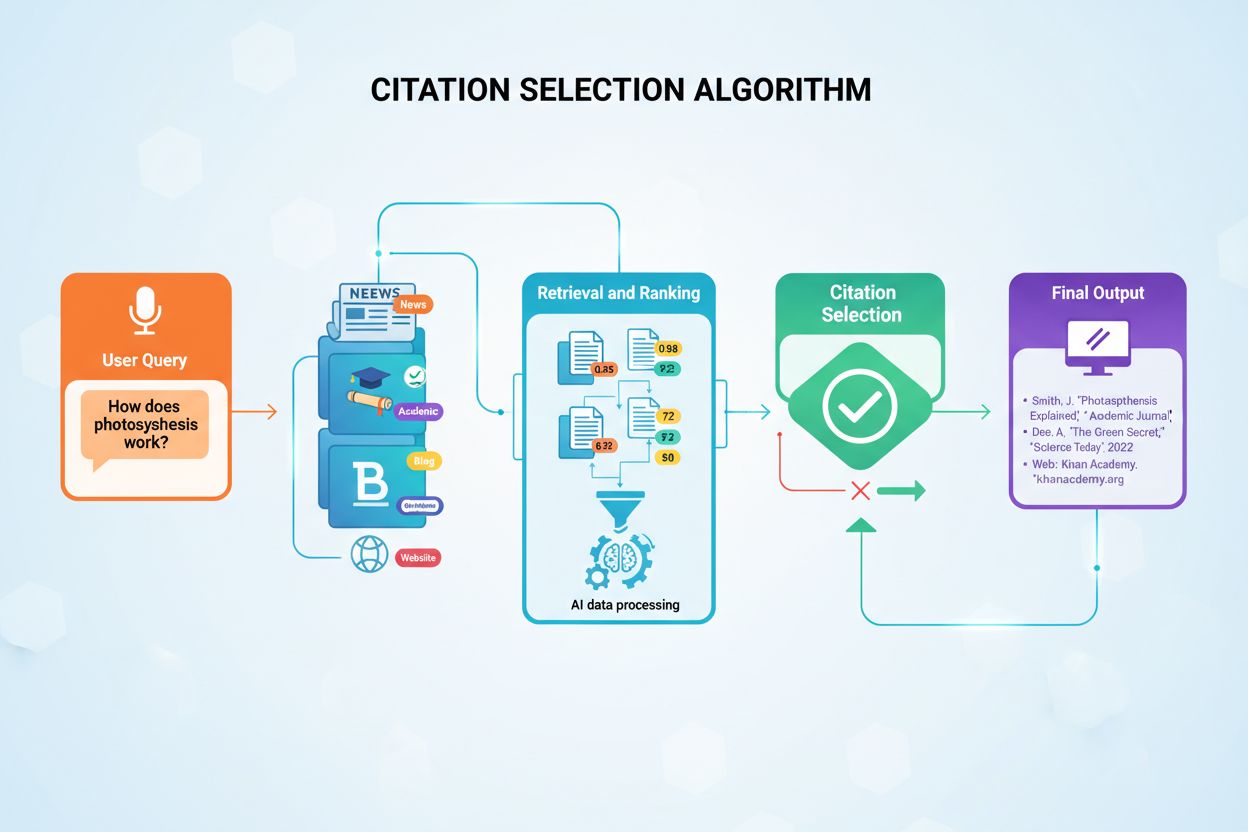
引用の決定は、ユーザーがクエリを入力した瞬間から始まる多段階プロセスで行われます。AIシステムはユーザーの質問を「埋め込み」と呼ばれる数値ベクトルへ変換し、クエリの意味を表現します。これらの埋め込みは、数百万件のドキュメントがインデックス化されたデータベースから意味的に類似したコンテンツの断片を探します。最も似ているコンテンツを単純に取得するのではなく、複数の評価基準を同時に適用し、引用にふさわしいソースの順位付けを行います。この並列評価プロセスによって、最も信頼できて関連性が高く構造化されたソースが上位に選ばれるのです。
**検索拡張生成(RAG)**は、AIモデルが外部ソースを引用できる基盤アーキテクチャです。従来の大規模言語モデル(LLM)が学習時のデータだけに依存するのに対し、RAGシステムはクエリごとにインデックス化されたドキュメントから情報を検索し、その情報をもとに回答を生成します。このアーキテクチャの違いにより、PerplexityやGoogle AI Overviewsのようなプラットフォームは一貫して引用を提供し、ChatGPTのベースモデルは明示的な引用元なしに回答を生成することが多い理由が説明できます。RAGを理解することで、なぜ特定のコンテンツが引用され、同じくらい高品質な他のコンテンツがAIから認識されないのかが明確になります。
RAGプロセスは引用ソースを決定する4つの段階で構成されます。まず、ドキュメントは200〜500ワードの扱いやすいチャンクに分割され、AIが記事全体を処理せずとも特定かつ関連性のある情報を抽出できるようにします。次に、これらのチャンクは機械学習モデルによって意味を理解できる数値ベクトル(埋め込み)に変換されます。三番目に、ユーザーが質問をすると、システムはベクトル類似度マッチングを使って意味的に近い埋め込みを検索し、クエリの本質にマッチしたコンテンツを特定します。四番目に、AIは取得したコンテンツを文脈として用いて回答を生成し、その回答に最も大きく貢献したソースが引用されます。このアーキテクチャにより、コンテンツ構造・明確さ・一般的な質問との意味的整合性が引用される確率に直接影響します。
AIの引用アルゴリズムは、引用に値するかどうかを総合的に判断する5つの主要な軸でソースを評価します。各要素は総合スコアに異なる割合で寄与し、全体としてソースの質を評価します。
| 引用要素 | 影響度 | 主な指標 |
|---|---|---|
| ドメインオーソリティ | 非常に高い (25-30%) | 被リンクプロファイル、ドメイン年齢、ナレッジグラフの有無、Wikipediaでの言及 |
| コンテンツの新しさ | 高い (20-25%) | 公開日、更新頻度、統計・データの鮮度 |
| 意味的関連性 | 高い (20-25%) | クエリとコンテンツの一致度、トピック特異性、直接的な回答の有無 |
| 情報構造 | 中-高 (15-20%) | 見出し階層、スキャンしやすい形式、スキーママークアップの実装 |
| ファクト密度 | 中 (10-15%) | 具体的なデータポイント、統計、専門家の引用、引用チェーン |
オーソリティはAIの引用決定で最も重視される要素です。150,000件のAI引用を分析した研究によると、RedditとWikipediaがそれぞれ40.1%、26.3%のLLM引用を占めており、確立された権威がいかに選定に影響するかがわかります。AIシステムはドメイン年齢、被リンクの質、ナレッジグラフへの登録、第三者による検証など複数の信頼シグナルでオーソリティを評価します。ドメインオーソリティスコアが60以上のウェブサイトは、ChatGPT、Perplexity、Gemini全体で高い引用率を維持します。しかしオーソリティはドメインだけでなく著者レベルの信頼性も含み、氏名・資格が明記された専門家による記事は匿名コンテンツより優遇されます。
新しさは引用対象としての有効性を左右する重要な時間的フィルターです。公開・更新から48〜72時間以内のコンテンツは優先的にランクされる一方、更新されないと2〜3日で可視性が目に見えて低下し始めます。この新しさ重視は、特に変化の激しい話題で古い情報がユーザーを誤導しないようAIが現時点の情報提供を重視する姿勢の表れです。ただし、中身が充実した定番コンテンツが最近更新されていれば、新しいが薄い内容より高評価されることもあり、基礎的な品質と新しさの両立が重要です。四半期や年次で定期的に更新している組織は、一度きりの発信に終始する組織より高い引用率を維持できます。
関連性はユーザーの質問とドキュメント内容の意味的合致度を測ります。主題に直接答え、余計な情報が少ないソースが、網羅的だが焦点のぼやけたリソースより高評価されます。AIは埋め込みの類似度を比較し、クエリとドキュメントチャンクの数値表現を照合して関連性を評価します。そのため自然な検索クエリに合致した会話調の文章が、従来のSEO向けキーワード最適化コンテンツより好まれます。FAQ形式やQ&AペアはAIのクエリ処理方法と自然にマッチするため、引用されやすいです。
構造は情報アーキテクチャと技術的な実装の両面を指します。明確な階層構造、説明的な見出し、論理的な流れ、スキャンしやすいレイアウトは、AIが情報の境界を把握し、関連情報を抽出しやすくします。FAQスキーマ、記事スキーマ、組織スキーマなどの構造化データマークアップは、引用確率を最大10%高めます。要点のまとめ、箇条書き、比較表、Q&A形式など簡潔に整理されたコンテンツは、長文の中に埋もれた洞察より優遇されます。これはAIが訓練時に完全・文脈的な回答を提供するよく整理された情報を認識するよう設計されているためです。
ファクト密度は、コンテンツ内に具体的かつ検証可能な情報がどれだけ含まれているかを示します。具体的なデータや統計、日付、事例が豊富なソースは、概念的な内容だけのものより優先されます。さらに、権威ある参照元を引用することで信頼の連鎖が生まれ、AIはその引用元から信頼性を継承します。裏付けや一次情報へのリンクがあるコンテンツは、主張のみのものより高い引用率を示します。この要件から、重要な主張には必ず公開日や専門家資格が明記された権威あるソースを引用すべきです。
AIプラットフォームごとに、そのアーキテクチャや設計思想に基づいた独自の引用戦略があります。プラットフォームごとの傾向を理解することで、複数のAI向けに同時最適化が可能です。
ChatGPTの引用傾向は百科事典的かつ権威あるソースを強く好みます。WikipediaはChatGPT引用の約35%に登場しており、確立されたコミュニティ検証済み情報への依存度が高いことがわかります。コミュニティ意見を求める質問以外では、ユーザー生成型フォーラムの引用を避け、明確な帰属や検証可能な事実のあるソースを優先します。この保守的アプローチは、高品質ソースで訓練され、正確性を重視するChatGPTの設計思想を反映しています。ChatGPTから引用されるには、ナレッジグラフやWikipediaへの登録、百科事典的中立性・深さを備えたコンテンツの作成が有効です。
Google AIシステム(GeminiやAI Overviews)は、より多様なタイプのソースを引用し、Googleの広範なインデックス方針を反映しています。Reddit投稿はAI Overviews引用の約5%を占め、オーガニック検索上位のコンテンツが引用されやすい傾向にあり、従来のSEOパフォーマンスとAI引用率に相関が生じます。ChatGPTより新しいソースやユーザー生成型コンテンツへの引用も多く、条件は関連性・権威性が認められることです。Googleプラットフォーム上では、従来のSEOの成功がAI引用にも連動しやすいですが、必ずしも完全な相関ではありません。
Perplexity AIの傾向は、透明性と直接的な引用元明示を重視します。一般的に1回答あたり3〜5つの引用元を直接リンク付きで提示し、業界別のレビューサイトや専門家による出版物、データ重視のコンテンツを優先します。ドメインオーソリティの比重が大きく、確立された出版物が優遇されますが、コミュニティコンテンツは全体の約1%(主に製品レビュー)に留まります。Perplexityはユーザーが情報を検証できるよう明確な引用元提示を設計思想とし、ブランド可視性の追跡に特に有効です。Perplexity向けにはデータ重視・業界別リソース・専門家執筆コンテンツが有効です。
ドメインオーソリティはAIアルゴリズムにとって信頼性の代理指標となり、そのソースが長期間信頼を積み重ねてきたことを示します。AIは、総引用確率の約5%を占める複数の技術シグナルでオーソリティを評価しますが、健康・金融・安全などのYMYL領域ではこの割合が大きく上昇します。主なオーソリティ指標は、ドメイン年齢、SSL証明書、プライバシーポリシー、SOC2やGDPRなど準拠認証です。これら技術シグナルとコンテンツ品質がかけ合わさると、技術的に優れたサイト+高品質コンテンツは、内容が良くても技術的に劣るサイトを上回ります。
被リンクプロファイルもAIのソース評価に大きな影響を与えます。AIはリンク元ドメインの権威、リンク文脈の関連性、被リンクの多様性を精査します。大手出版物からの10本の被リンクは、低権威サイトからの100本より評価が高いという研究結果もあります。著者の専門家性を明記した記事は匿名記事より引用されやすく、著者スキーマや詳細なプロフィールは専門性検証に役立ちます。業界掲載実績や第三者による言及も信頼性を強化します。組織は高権威ソースからの被リンク獲得、著者資格の明示、業界内メディア掲載に注力すべきです。
Wikipediaやナレッジグラフへの掲載は、他の要素に関係なく引用率を大きく向上させます。 Wikipediaに参照されているソースは大きな優位性を持ち、ナレッジグラフがAIモデルの権威ソースとして繰り返し参照されます。Googleナレッジパネルの情報はAIがエンティティの関係やオーソリティを理解する基盤となります。Wikipedia不在の組織は、どんなに高品質なコンテンツでも安定的な引用獲得が難しいため、ナレッジグラフ構築はAI可視性戦略の最優先事項と言えます。これがAIモデルが繰り返し参照する信頼の土台を形成します。
会話型クエリアラインメントは従来のSEO最適化からの大きな転換です。Q&A形式で構成されたコンテンツは、キーワード最適化型より検索アルゴリズムで高評価を得やすく、FAQページや自然言語でのクエリを模したコンテンツが優遇されます。AIは会話型データで訓練されており、自然な言語パターンをキーワード列より良く理解します。つまり「友達の質問に答えるような」文体の方が、検索エンジン向けの文章よりAIに評価されます。組織は、会話調・よくある質問への直接回答・実際のユーザークエリに沿った自然言語表現になっているかを点検しましょう。
コンテンツ内の引用品質は、個別ソースを超えた信頼連鎖を生みます。AIは主張に根拠や裏付けがあるかを評価し、権威ある参照元を引用することで信頼性が乗算的に高まります。裏付けや一次情報へのリンク付きコンテンツは、未検証の主張より高い引用率をもたらします。重要な主張ごとに、公開日と専門家資格を持つ権威ソースからの引用を必ず含めましょう。 引用されるコンテンツを作るには、5〜8件の権威ある参照、2〜3件の専門家コメント(資格明記)、3〜5件の最近の統計(公開日明記)を推奨します。
複数プラットフォームでの一貫性は、AIがソースの信頼性を評価する際に影響します。複数のソースで一貫した情報が見つかると、クラスター内の個々のソースを引用する信頼度が高まります。全体の合意と矛盾するソースは、反証データがない限り優先度が下がります。一貫性バイアスを活かすには、オウンド・アーンド・シェアードメディア全体で統一した情報発信を維持し、コーポレートサイト・SNS・業界メディア・第三者プラットフォームの内容が整合性を持つよう管理しましょう。
更新頻度戦略は、AI時代には従来SEOより重要性が増しています。発信頻度は引用率に直結し、AIは最新情報に強い優先度を与えます。既存コンテンツも48〜72時間ごとに必ずしも全面改稿せずとも、新しいデータや統計の追加、セクションの拡充で新しさシグナルを維持できます。更新頻度やコンテンツ鮮度の管理機能を備えたCMSは、AIプラットフォームによる引用競争で有利です。この継続的な更新アプローチは、更新しなくても長期間上位表示された従来SEOとは根本的に異なります。
アグリゲーターサイト掲載戦略は、AIによる発見経路を複数確保します。業界まとめ記事や専門家リスト、レビューサイトで取り上げられることで、一次ソース単体以上の露出機会が生まれます。頻繁に引用される媒体での言及は、AIが複数ルートでコンテンツに接触するきっかけとなります。メディアリレーションや業界特化型データベースへの掲載もAI可視性の重要施策です。業界まとめ・専門家リスト・レビューサイト掲載を積極的に狙いましょう。
構造化データ実装は、コンテンツを機械可読化し引用確率を高めます。AIが読み取れるスキーママークアップにより、AIは非構造テキストを解析せずとも特定の事実を抽出できます。FAQスキーマ・著者情報付き記事スキーマ・組織スキーマは、検索アルゴリズムが優先するマシンリーダブルなシグナルです。JSON-LD形式での構造化データ実装は、引用確率と引用情報の正確性の両面で効果を発揮します。包括的なスキーマ実装により、複数AIプラットフォームで引用率向上が見込めます。
Wikipedia・ナレッジグラフ構築は、時間と労力がかかっても複利的な成果をもたらします。Wikipedia掲載には中立的で十分な出典に基づく投稿が必要ですが、同時にWikidataやGoogleナレッジパネル、業界データベースのプロフィールも最適化し、AIが繰り返し参照する信頼基盤を築きます。これらのナレッジグラフは多様なクエリでAIが参照する権威ソースとなるため、AI可視性を継続的に高めたい組織は戦略的に優先すべきです。
組織は、ChatGPT、Google AI Overviews、Perplexityなど主要プラットフォームで関連クエリを手動テストし、引用頻度を追跡すべきです。定期的なプロンプトテストで、どのコンテンツが引用されているか、AIでの認知ギャップがどこにあるかが明確になります。このテスト手法は引用パフォーマンスの可視化と最適化機会の把握に直結します。AI引用アルゴリズムは、学習データの拡張や検索戦略の進化で絶えず変化するため、パフォーマンスデータに基づきコンテンツ戦略を柔軟に更新する必要があります。過去に引用されたコンテンツでも引用が止まった場合、最新情報でリフレッシュしたり、意味的に再構成しましょう。
1つのクエリで複数のソースが引用されるため、AI時代の引用はゼロサム競争ではなく共引用の機会を生みます。他社と同じテーマでも補完的な内容を作ることで共存でき、競合分析でカテゴリ内のAI可視性リーダーを把握し、自社のギャップや機会を特定できます。引用パフォーマンスを継続的に追跡すれば、トレンドや成功要因URLが判明し、勝ちパターンの再現・拡大が可能となります。
ChatGPT、Perplexity、Google AI Overviews、その他AIプラットフォームで、あなたのコンテンツがAI生成回答にどこで掲載されているかを追跡。AI上の可視性や引用パフォーマンスをリアルタイムで把握できます。
AIシステムがどの情報源を引用し、どれを要約・言い換えるかを選ぶ仕組みを解説。引用選択アルゴリズム、バイアスパターン、AI生成応答におけるコンテンツ可視性向上の戦略を理解しよう。...
AIモデルがどのように回答を生成し、引用を配置するかを学びましょう。ChatGPT、Perplexity、Google AIの回答であなたのコンテンツがどこに現れるか、AIでの可視性を最適化する方法を解説します。...

ChatGPT、Perplexity、Google AI OverviewのようなAIシステムにとって、どのようなコンテンツが引用に値するのかを学びましょう。AIシステムがあなたのコンテンツを引用するかどうかを決定する主な特徴、最適化戦略、指標を解説します。...
クッキーの同意
閲覧体験を向上させ、トラフィックを分析するためにクッキーを使用します。 See our privacy policy.